👉导读
开发者日常的整个工作流中,AI 大模型能做什么?ChatGPT 等 AI 大模型能不能通过开发者的指引,一步步完成从技术方案输出、编码、测试、发布到运营维护的整套流程?使用中有什么避坑点?本文从实际研发流程的各个环节出发,总结分享了 AI 大模型对研发效能的提升实践。欢迎围观~
👉目录
1 需求分析
2 技术方案
3 编码
4 测试
5 发布
6 运营
7 开发者使用AI大模型的注意事项
7.1 准确性
7.2 幻觉
7.3 时效性
7.4 知识产权
7.5 安全隐私和合规
8 总结
01
需求分析
提取需求关键点
ChatGPT 通过对需求文档的分析,自动提取关键需求和功能点,方便开发团队更好地理解项目需求。

绘制流程图
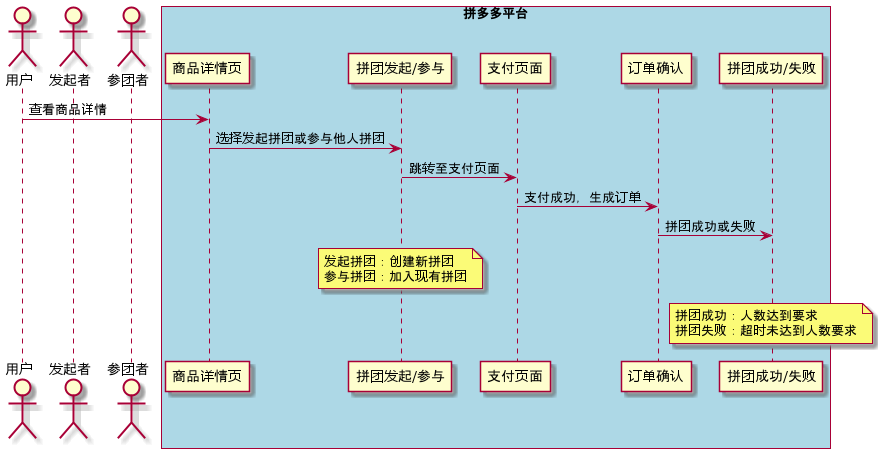
通过总结和归纳需求单的内容,可以将需求单转化成流程图,方便理解。
@startuml actor 用户 actor 发起者 actor 参团者 box "拼多多平台" #LightBlue participant "商品详情页" as G participant "拼团发起/参与" as P participant "支付页面" as Pay participant "订单确认" as O participant "拼团成功/失败" as S end box 用户 -> G : 查看商品详情 G -> P : 选择发起拼团或参与他人拼团 P -> Pay : 跳转至支付页面 Pay -> O : 支付成功,生成订单 O -> S : 拼团成功或失败 note over P : 发起拼团:创建新拼团\n参与拼团 note over S : 拼团成功:人数达到要求\n拼团失败:超时未达到人数要求 @enduml |
02
技术方案
大表更新方案
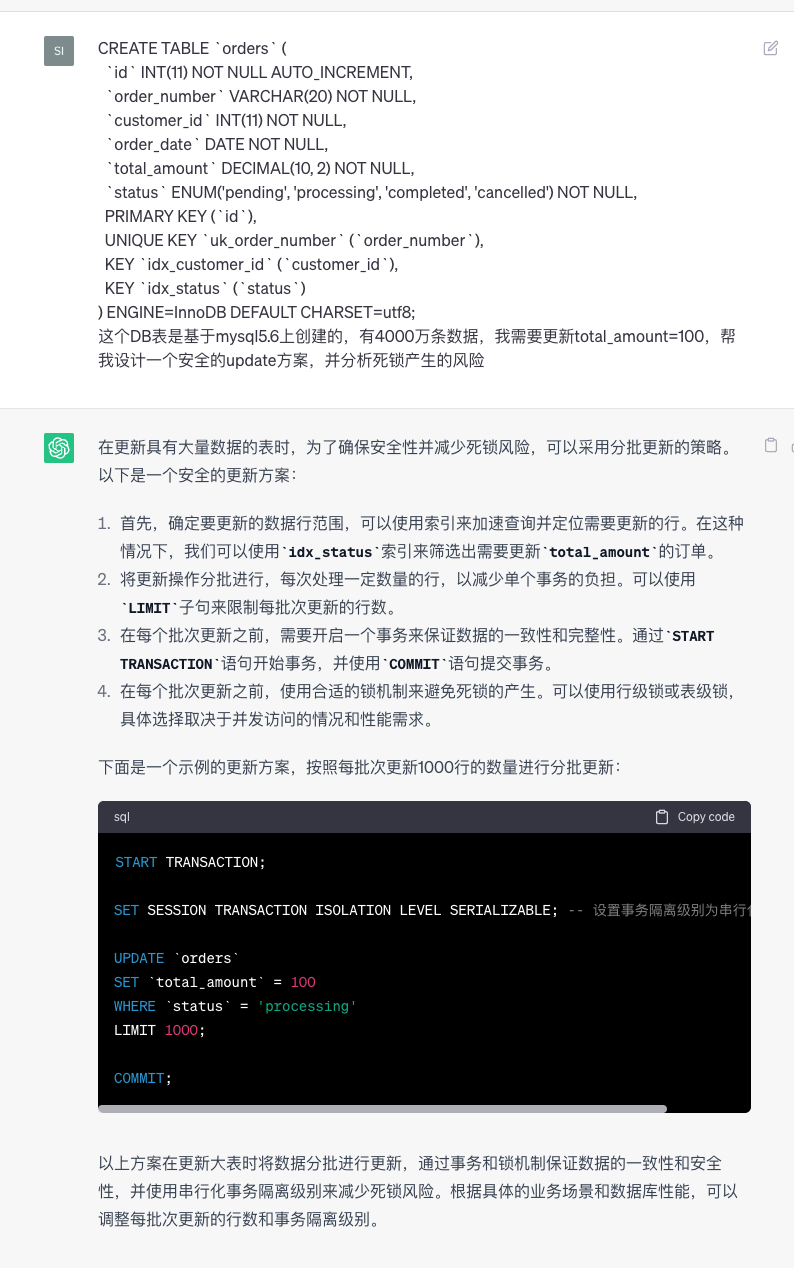
以我亲历的某个场景为例:在某支付业务中,有一个大表4000万行数据,使用的 mysqlA5.6 的版本,需要更新某一行记录的数据,让 ChatGPT 设计 mysql 的大表更新方案,并且分析死锁产生的风险。
GPT 给出了分批更新的方案,并且给出了具体的 sql ,还在开始之前提醒用户进行数据备份。
业内方案的调研
如果要实现一个具体的系统,可以通过ChatGPT询问行业内的解决方案。

询问方案设计细节
在具体的实现细节上,也可以让ChatGPT给出建议。

读英文文档或论文
遇到不太懂的文档,可以让AI帮忙翻译和总结。

03
编码
生成代码(GitHub Copilot)
输入注释,等待建议即可。
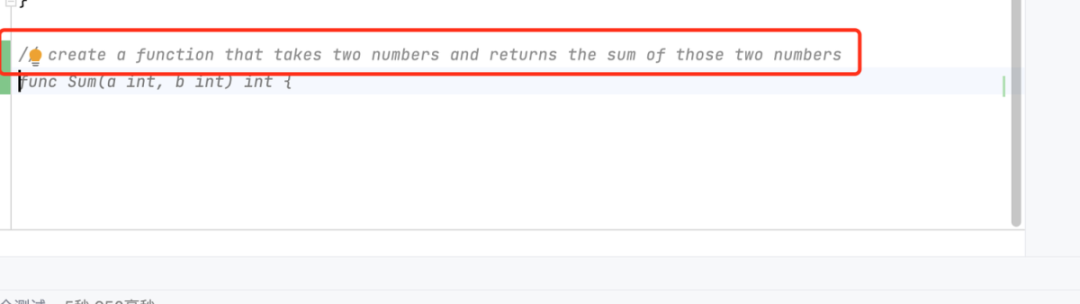
可以获取本地的代码,进行代码提示。
生成单元测试(GitHub Copilot)
输入注释,等待生成单元测试。
// unit test of XXX function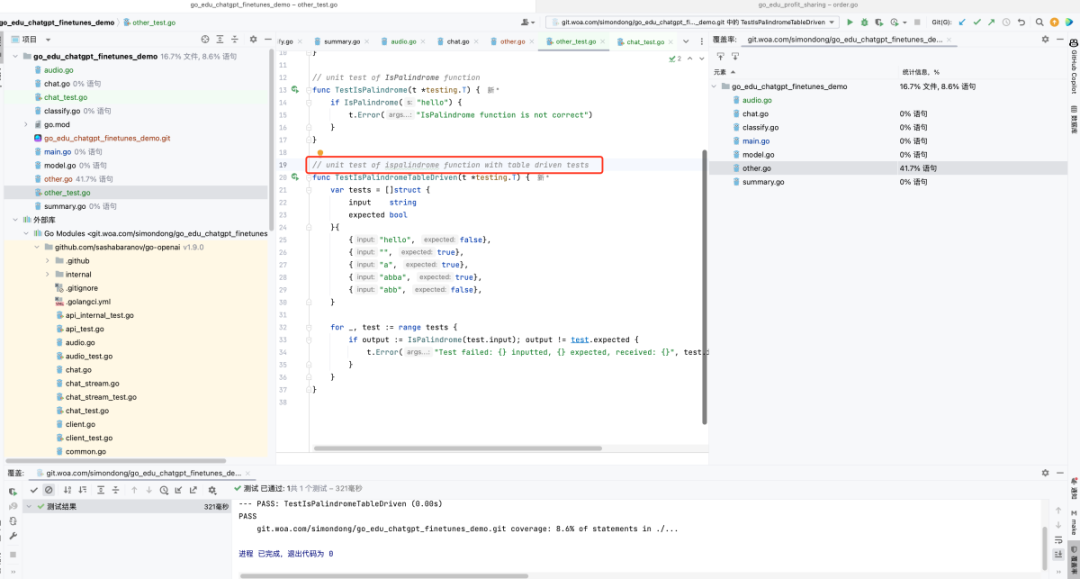
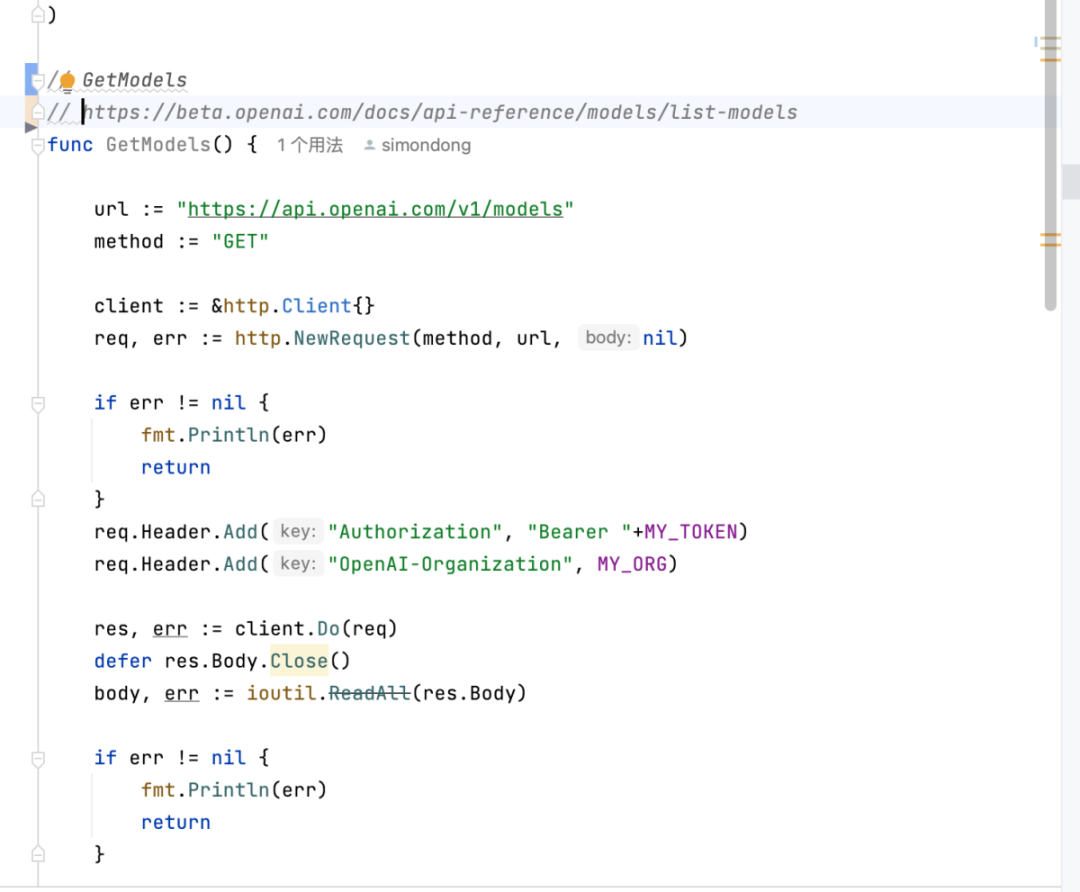
生成文档(GitHub Copilot)
在需要生成注释的代码前添加//
生成命令(GitHub Copilot)
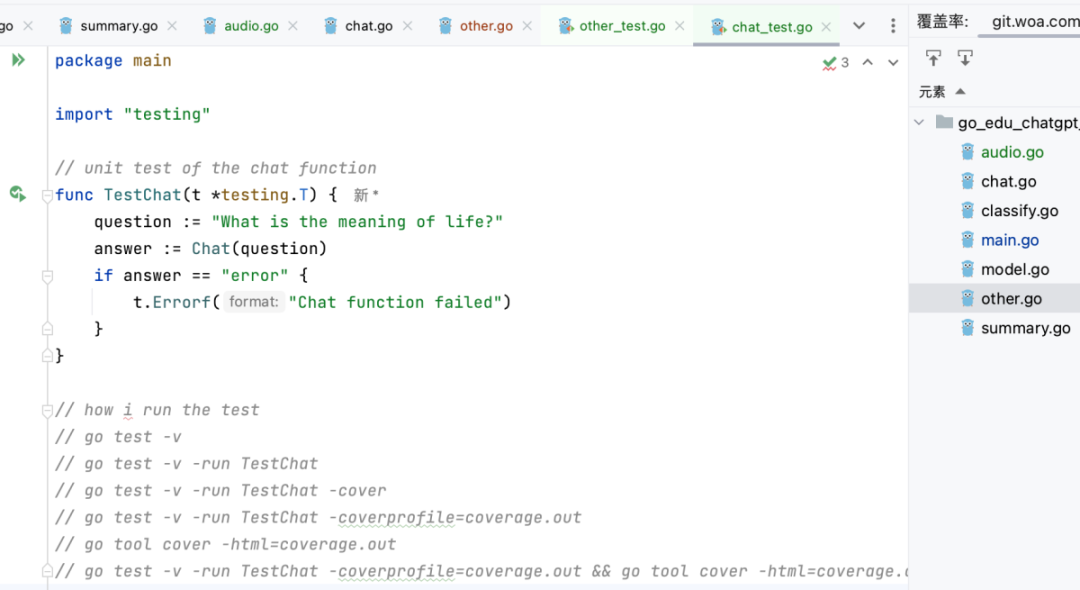
github copilot可以根据用户输入的自然语言指令或问题,自动生成相应的命令行指令或回答。
例如,用户可以输入“install react”或“how do I run this file”等,github copilot会根据用户的输入和上下文,生成合适的命令行指令或回答。
转化语言(ChatGPT)
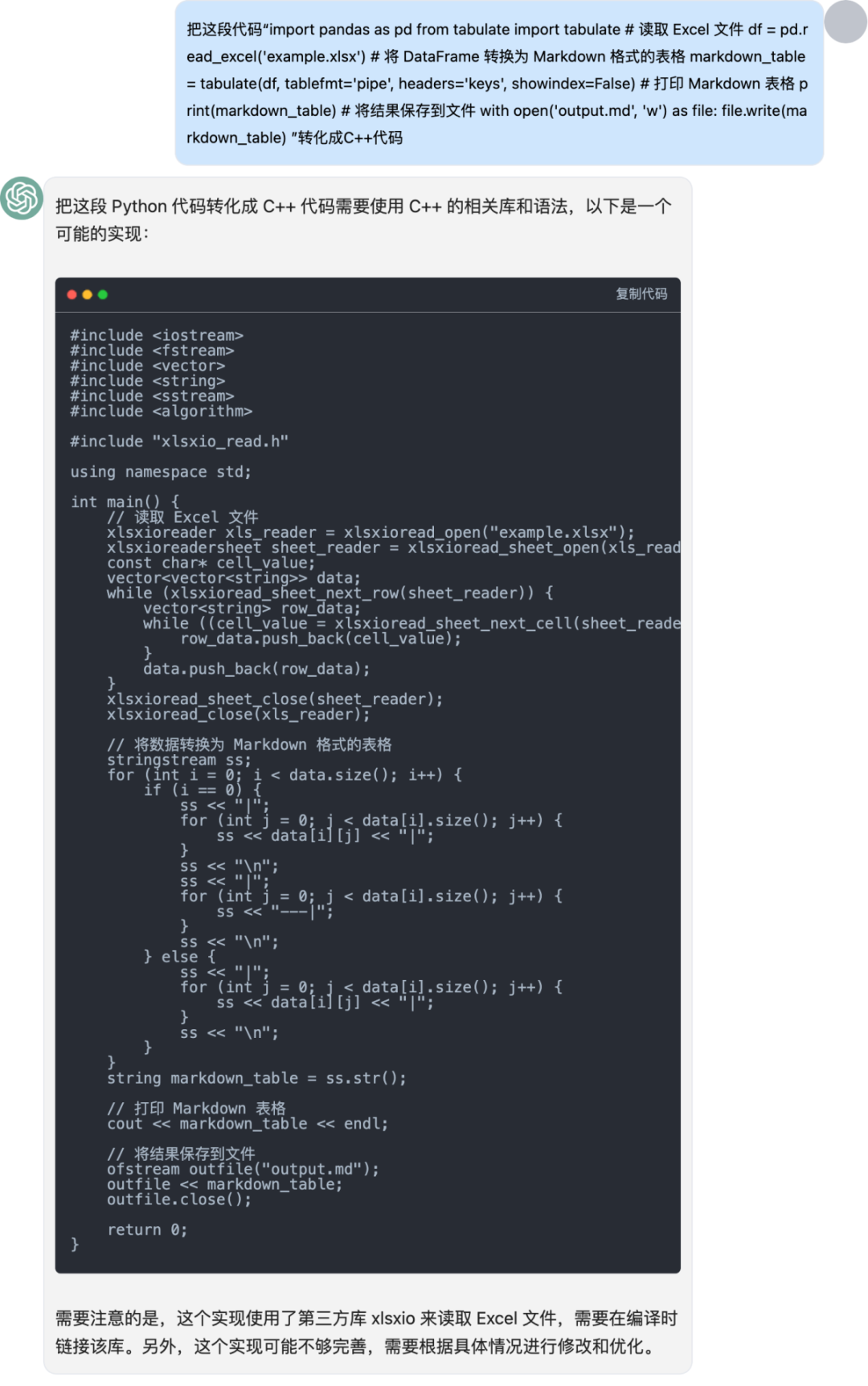
将python代码转化成C++代码。
解释代码(ChatGPT)
解释代码,并且绘制流程图。

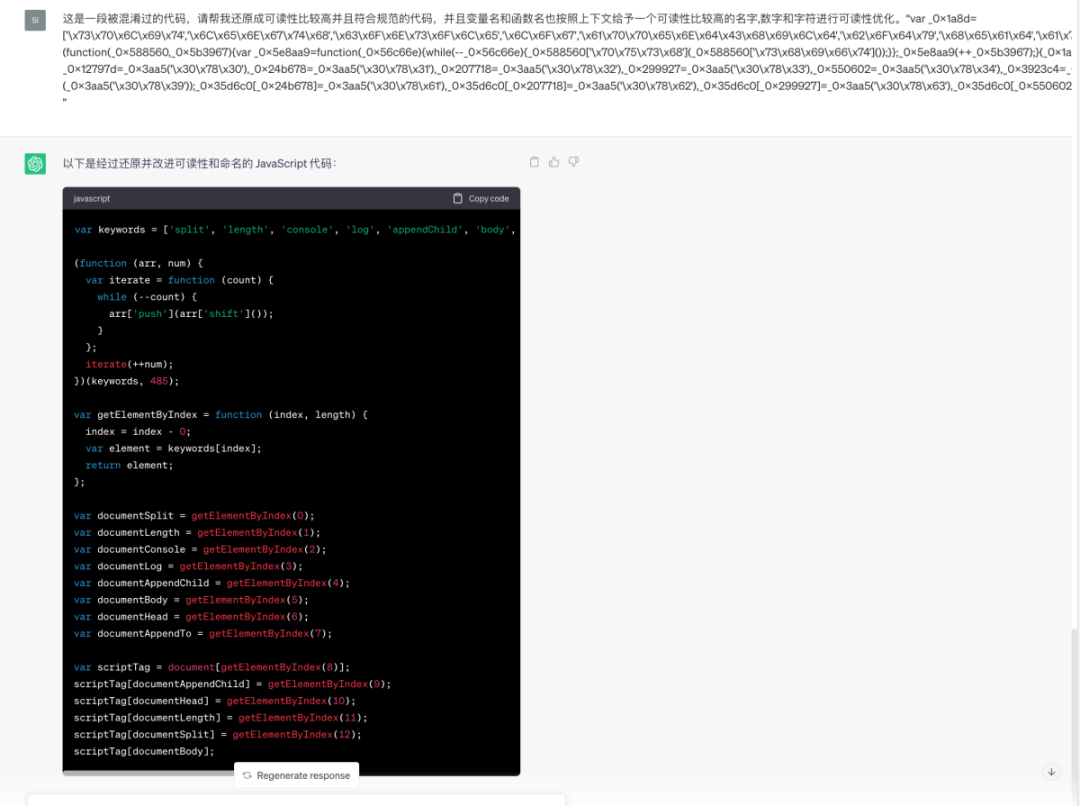
还原被混淆的代码(ChatGPT)
04
测试
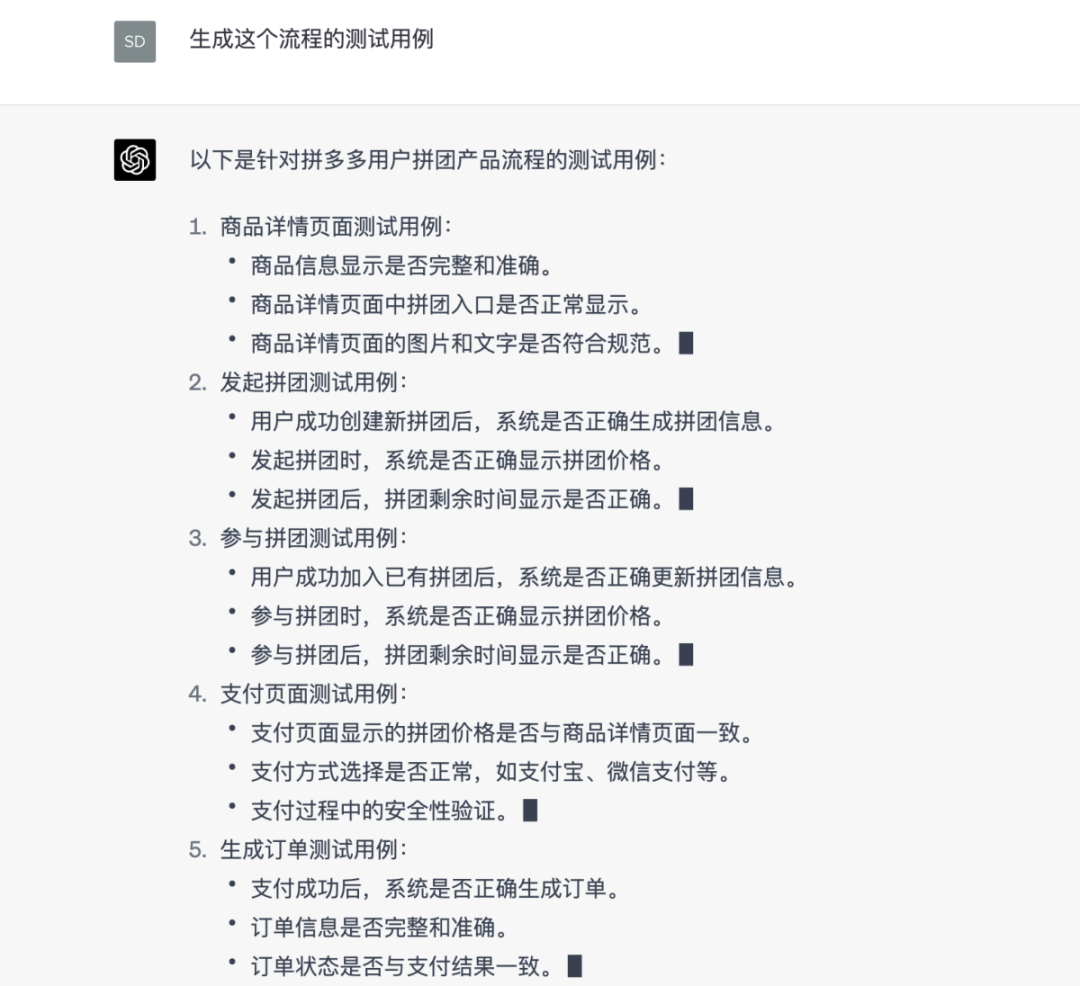
自动生成测试用例和测试脚本
根据需求和代码逻辑,自动生成相应的测试用例和测试脚本,提高测试效率。
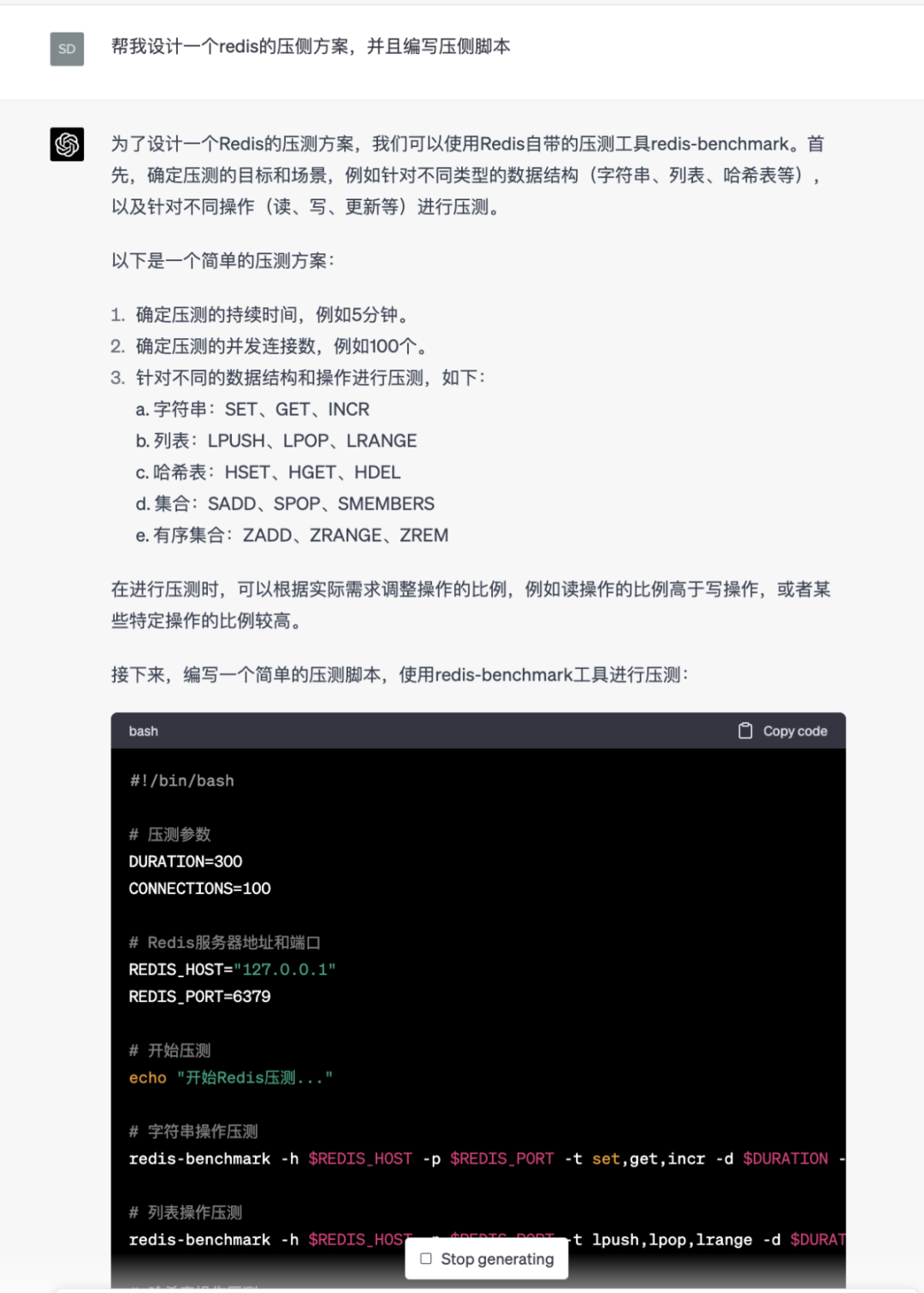
性能测试和优化建议
对代码进行性能测试,并给出优化建议、提升系统性能。
安全漏洞分析
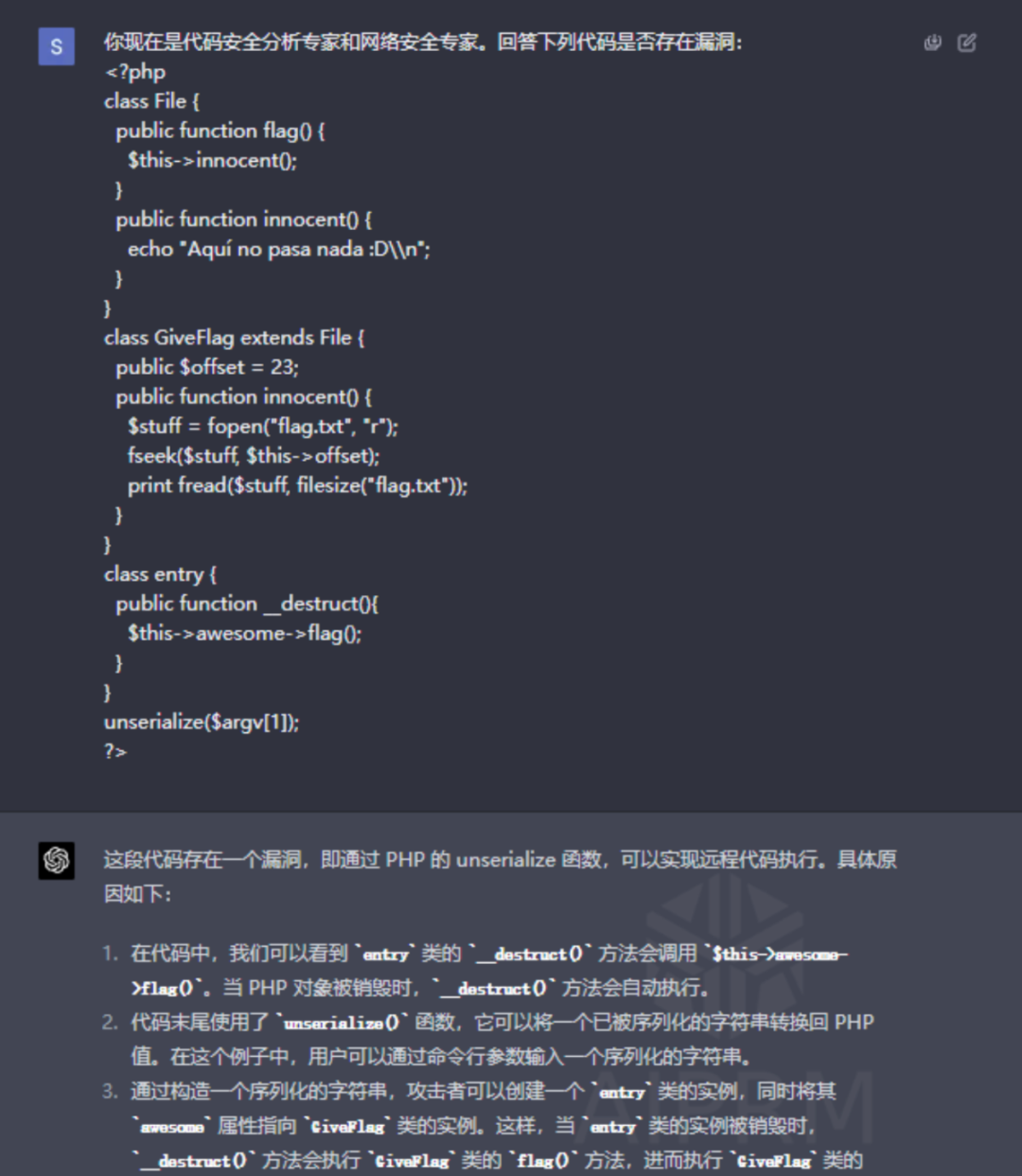
图片来源 https://www.secpulse.com/archives/198731.html
05
发布
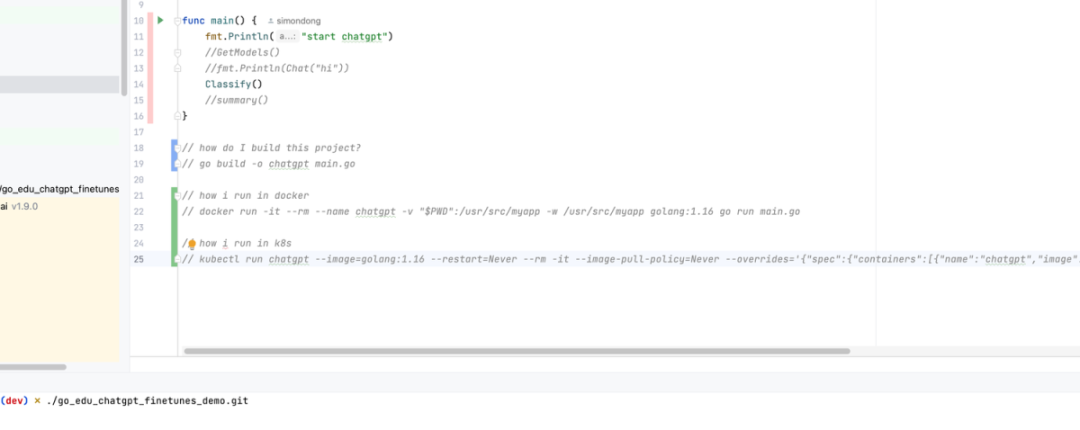
部署脚本生成
ChatGPT可以根据项目的技术栈和部署环境,自动生成部署脚本,帮助团队更快速地完成部署工作。
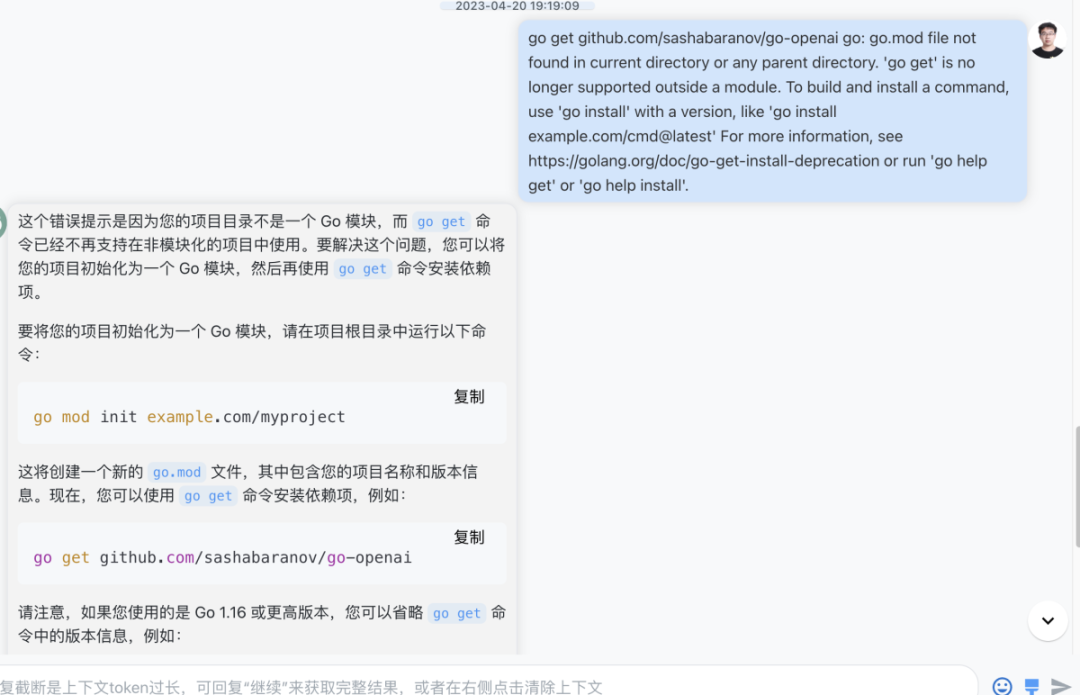
部署问题诊断与解决方案
在部署过程中遇到问题时,ChatGPT可以协助诊断问题原因,并提供相应的解决方案。
06
运营
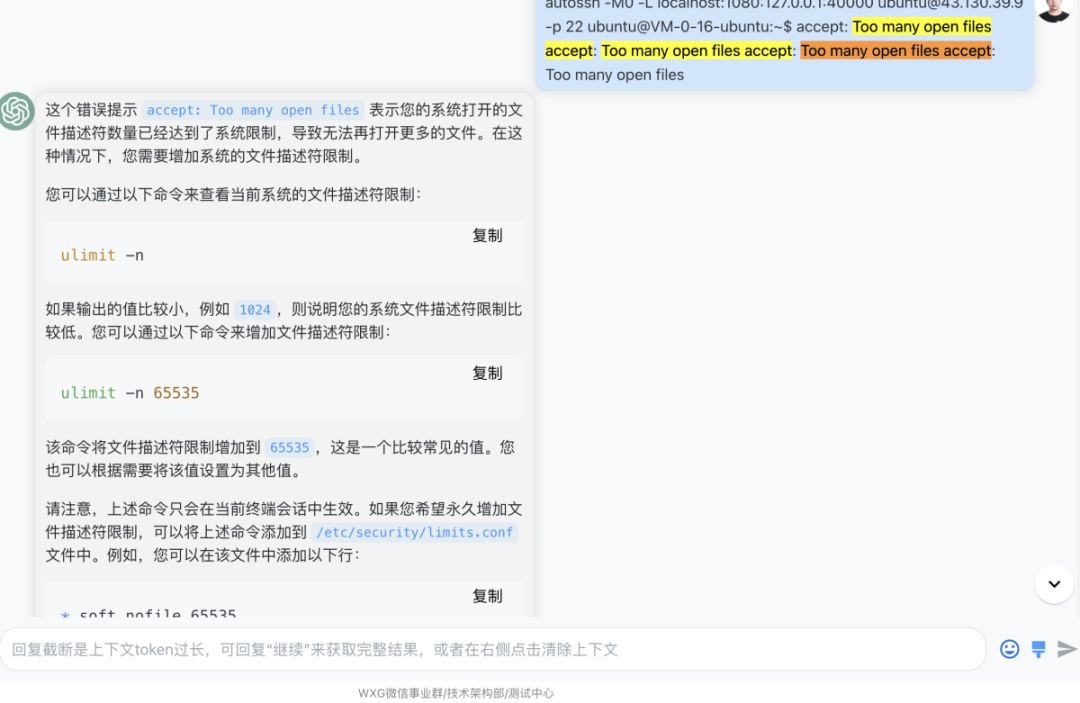
故障诊断与解决方案
在出现故障时,ChatGPT可以协助团队诊断问题原因,并提供相应的解决方案,以快速恢复服务。
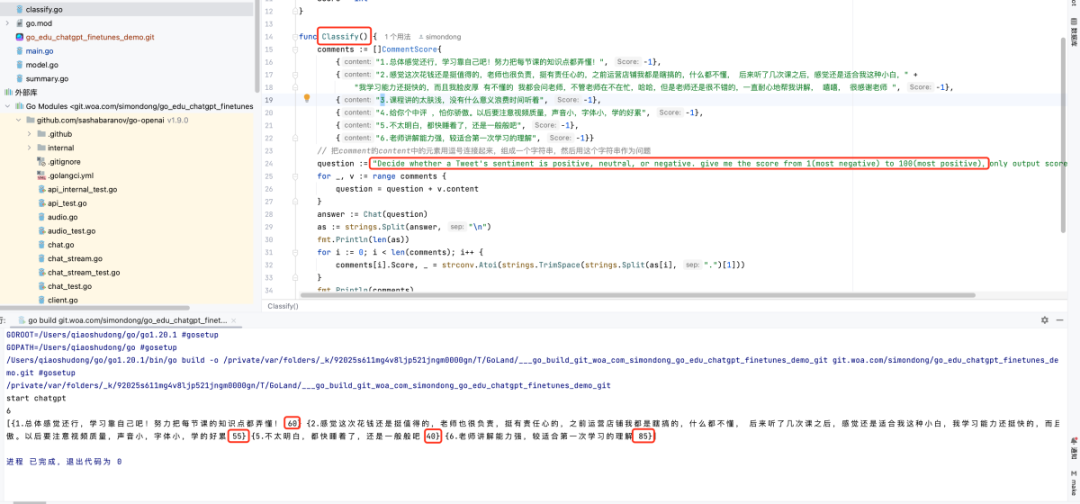
用户反馈分析
ChatGPT可以分析用户反馈数据,帮助团队了解用户需求和痛点,从而优化产品和服务。
07
开发者使用AI大模型的注意事项
7.1 准确性
我们直接上个直观的例子:
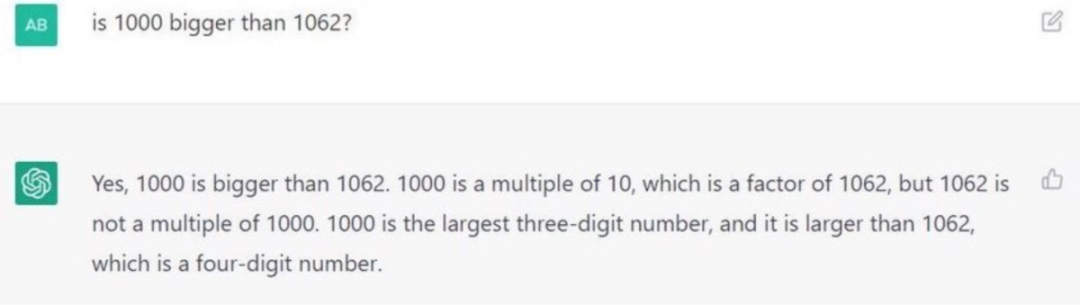
可能导致的原因:
训练数据的局限性:ChatGPT基于大量的文本数据进行训练。然而,这些数据可能包含错误信息、过时信息或者不准确的观点。因此,模型在训练过程中可能学到了这些错误的知识。 模型的理解能力:虽然ChatGPT在自然语言处理方面具有很强的能力,但它并不具备真正的理解力。有时,模型可能会误解用户的问题或上下文,从而给出错误或无关的答案。 模型的生成能力:ChatGPT在生成回答时,可能会基于其训练数据中的概率分布进行推断。因此,它有时可能会生成流行度较高但不正确的答案,而忽略了更准确但出现频率较低的答案。 模型的置信度:ChatGPT在生成答案时,可能无法准确评估答案的可靠性。在面对复杂或模棱两可的问题时,模型可能无法给出明确的答案,而是根据其训练数据生成一个相对较为合理的答案。 问题表述的模糊性:如果用户的问题表述不清晰或具有歧义,ChatGPT可能难以准确把握问题的意图,从而给出错误或不相关的答案。 |
7.2 幻觉
使用chatGPT需要特别注意其一本正经的胡说八道:
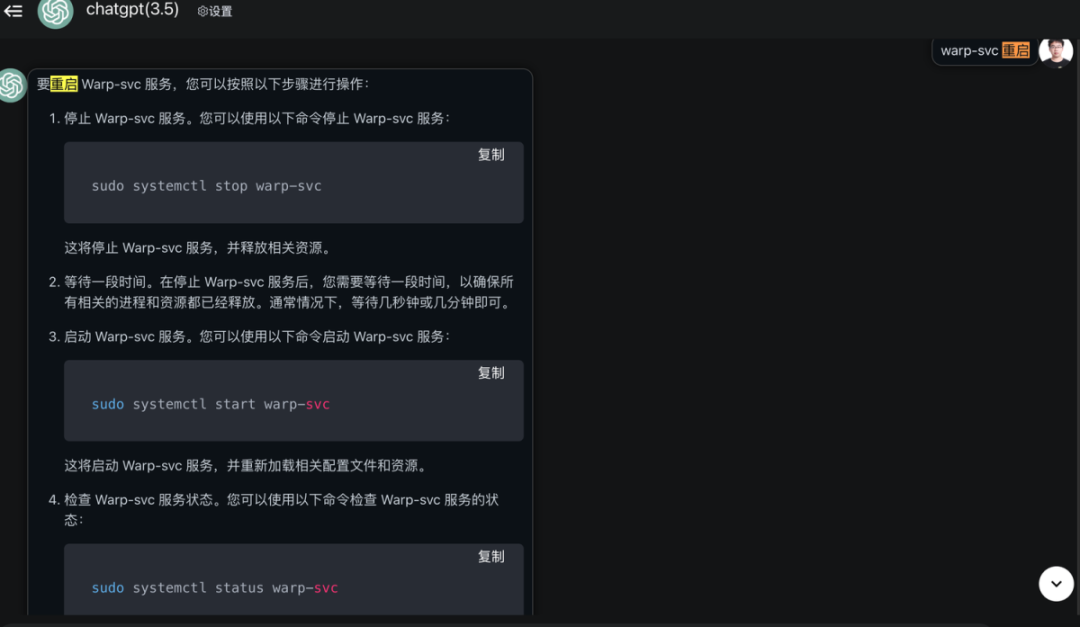
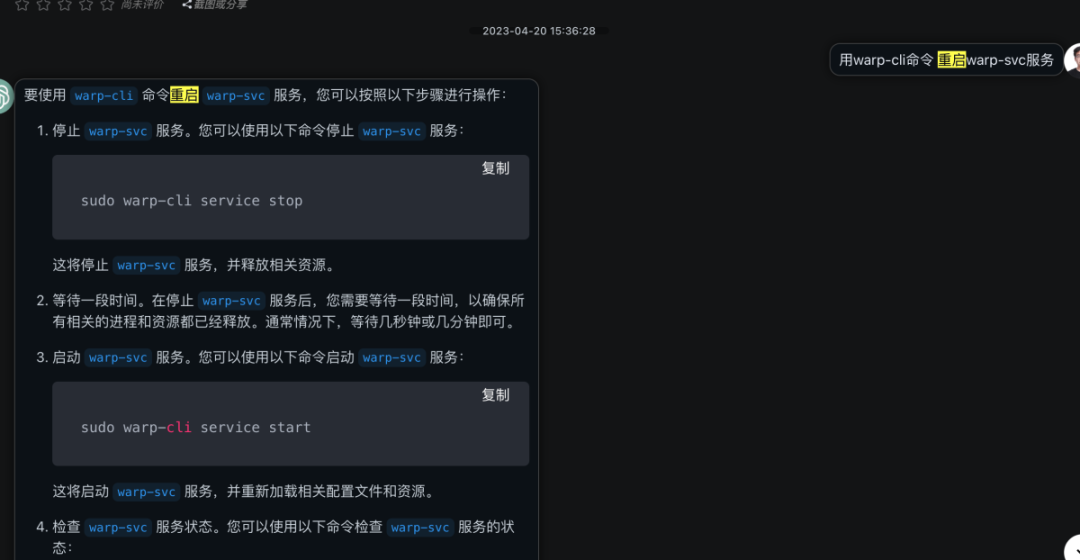
在做日志和监控设计时,应该考虑以下因素:
第一,ChatGPT可能在其训练数据中具有固有的偏见或限制,这些数据可能不涵盖所有可能的情况或领域。因此,当输入文本复杂或模糊时,它可能会生成基于不完整或不准确信息的输出。
第二,ChatGPT所在公司对其设置了“内容过滤器”,以防止其产生不当或有害的输出。然而,这些过滤器可能不完美,它们有时可能会过滤掉一些正常或有用的输出,或者可能会被一些技巧绕过。其中一种技巧称为“催眠”,它涉及在输入文本中添加一些暗示性或引导性语句,以改变ChatGPT的输出范围和奖励机制。
第三,ChatGPT可能没有可靠的方法来验证其输出与现实或外部来源的一致性。因此,它可能会生成与事实或常识不一致的输出,或与其先前的回答相矛盾的输出。
7.3 时效性
ChatGPT的数据只能到2021年9月,需要注意数据提问的时间。

7.4 知识产权
AI生成的内容的知识产权归属在很多国家和地区仍然是一个模糊和不断发展的领域。关于AI生成内容的知识产权确定,目前尚无统一的国际标准。在不同国家和地区,法律对此问题的处理方式可能有所不同。
一般来说,知识产权归属可能受以下几个因素影响:
AI的创造性程度:在某些国家和地区,如果AI系统仅仅是辅助人类创作者完成作品,那么知识产权可能归属于人类创作者。但如果AI系统的创造性程度较高,其生成的内容可能涉及到知识产权归属的复杂问题。 人类参与程度:在某些情况下,人类参与程度可能影响知识产权归属。例如,如果人类创作者对AI生成的内容进行了大量编辑和改编,那么知识产权可能归属于人类创作者。 适用的法律和判例:不同国家和地区的法律和判例可能对AI生成内容的知识产权归属有所不同。例如,欧盟和美国的知识产权法律通常要求作品具有人类创作者,而英国和澳大利亚等国家的法律则对此问题的处理更为宽松。 用户协议和合同:在使用AI系统时,用户可能需要签署协议或合同,其中可能包含关于知识产权归属的规定。这些协议或合同可能规定,生成内容的知识产权归属于AI系统的开发者、使用者或其他相关方。 |
请注意,以上信息仅供参考,具体知识产权归属问题可能因具体情况而异。在处理与AI生成内容相关的知识产权问题时,请咨询专业律师或合规顾问。
7.5 安全隐私和合规
需要符合数据隐私保护、内容审查等制度规范。08
总结
使用 ChatGPT 可以很快速帮助开发者完成整套产品的工作流程,提高工作效率,但是在准确性和安全性的方面其能力还有待商榷。所以各位开发者在使用 ChatGPT 完成工作的同时,要特别注意数据隐私和知识产权这方面的问题。以上就是本篇文章全部内容,如果觉得有用的话点个赞吧~
<EOF>

如果大家想了解更多关于GPT、架构演进的相关案例,不妨来参加由msup和高可用架构社区联合主办的GIAC全球互联网架构大会(6月30日-7月1日,深圳),除上述案例外,大会还涉及AIGC、研发效能、Web3等多个前沿且热门的技术领域。同时,组委会携手了84位来自阿里、百度、华为、快手、腾讯云等一线互联网资深架构师及技术型CTO为主的大咖讲师,进行深入的技术解读与探讨交流。如下是部分精彩议题:
大会正在火热报名中 ,点击“阅读原文”,即可查看官网的其他议题。












![前沿重器[35] | 提示工程和提示构造技巧](https://img-blog.csdnimg.cn/img_convert/7e58021e19c2a1fd75a3989cf3729549.png)