SQL语言
sql语言分类
| SQL类别 | 主要动作 |
|---|---|
| DQL(Data Query Language) | SELECT(通常与FROM、WHERE、GROUP BY、HAVING、ORDER BY等组合使用),用作数据chaxun |
| DML | INSERT、UPDATE和DELETE,用作定义数据库记录(数据) |
| TCL | COMMIT、ROLLBACK、SAVEPOINT、SET TRANSACTION,事务控制 |
| DCL | GRANT、REVOKE,定义访问权限和安全级别 |
| DDL | CREATE、ALTER、DROP、TRUNACTE,定义数据库对象,如库、表、列等 |
| CCL | DECLARE CURSOR、FETCH INTO和UPDATE WHERE CURRENT,指针控制 |
DQL语法
通过元命令我们可以查看关于select的帮助
test=# \h select
命令:SELECT
说明: 从数据表或视图中读取数据
语法:
[ WITH [ RECURSIVE ] with查询语句(with_query) [, ...] ]
SELECT [ ALL | DISTINCT [ ON ( 表达式 [, ...] ) ] ][ * | 表达式 [ [ AS ] 输出名称 ] [, ...] ][ FROM from列表中项 [, ...] ][ WHERE 条件 ][ GROUP BY grouping_element [, ...] ][ HAVING 条件 [, ...] ][ WINDOW 窗口名称 AS ( 窗口定义 ) [, ...] ][ { UNION | INTERSECT | EXCEPT } [ ALL | DISTINCT ] 查询 ][ ORDER BY 表达式 [ ASC | DESC | USING 运算子 ] [ NULLS { FIRST | LAST } ] [, ...] ][ LIMIT { 查询所用返回记录的最大数量 | ALL } ][ OFFSET 起始值 [ ROW | ROWS ] ][ FETCH { FIRST | NEXT } [ 查询所用返回记录的最大数量 ] { ROW | ROWS } ONLY ][ FOR { UPDATE | NO KEY UPDATE | SHARE | KEY SHARE } [ OF 表名 [, ...] ] [ NOWAIT | SKIP LOCKED ] [...] ]from 列表中的项可以是下列内容之一[ ONLY ] 表名 [ * ] [ [ AS ] 别名 [ ( 列的别名 [, ...] ) ] ][ TABLESAMPLE sampling_method ( 参数 [, ...] ) [ REPEATABLE ( 种子 ) ] ][ LATERAL ] ( 查询 ) [ AS ] 别名 [ ( 列的别名 [, ...] ) ]WITH查询语句名称(with_query_name) [ [ AS ] 别名 [ ( 列的别名 [, ...] ) ] ][ LATERAL ] 函数名称 ( [ 参数 [, ...] ] )[ WITH ORDINALITY ] [ [ AS ] 别名 [ ( 列的别名 [, ...] ) ] ][ LATERAL ] 函数名称 ( [ 参数 [, ...] ] ) [ AS ] 别名 ( 列定义 [, ...] )[ LATERAL ] 函数名称 ( [ 参数 [, ...] ] ) AS ( 列定义 [, ...] )[ LATERAL ] ROWS FROM( 函数名称 ( [ 参数 [, ...] ] ) [ AS ( 列定义 [, ...] ) ] [, ...] )[ WITH ORDINALITY ] [ [ AS ] 别名 [ ( 列的别名 [, ...] ) ] ]from列表中项 [ NATURAL ] 连接操作的类型 from列表中项 [ ON 用连接操作的条件 | USING ( 用于连接操作的列 [, ...] ) ]并且grouping_element可以是下列之一:( )表达式( 表达式 [, ...] )ROLLUP ( { 表达式 | ( 表达式 [, ...] ) } [, ...] )CUBE ( { 表达式 | ( 表达式 [, ...] ) } [, ...] )GROUPING SETS ( grouping_element [, ...] )with查询语句是:WITH查询语句名称(with_query_name) [ ( 列名称 [, ...] ) ] AS [ [ NOT ] MATERIALIZED ] ( 查询 | 值 | insert | update | delete )TABLE [ ONLY ] 表名 [ * ]
| 参数 | 简介 |
|---|---|
| SELECT | 主动作关键字,可以对表执行投影和选择操作 |
| DISTINCT | 用于对结果集去掉重复记录 |
| * | 代表查询表中的所有列 |
| WHERE | 指定查询条件,只会返回条件为true的记录 |
| GROUP BY | 用于对满足条件的记录按指定列执行分组聚合运算 |
| HAVING | 用于对分组聚合后的结果集进行筛选,只返回条件为true的记录 |
| ORDER BY | 用于对结果集进行排序,ASC为升序,DESC为降序 |
| LIMIT | 用于限制查询返回的结果 |
| OFFSET…FETCH | 用于进行分页查询 |
| FOR | 用于独占方式查询表 |
实验1:SELECT子句
查询所有行和所有列
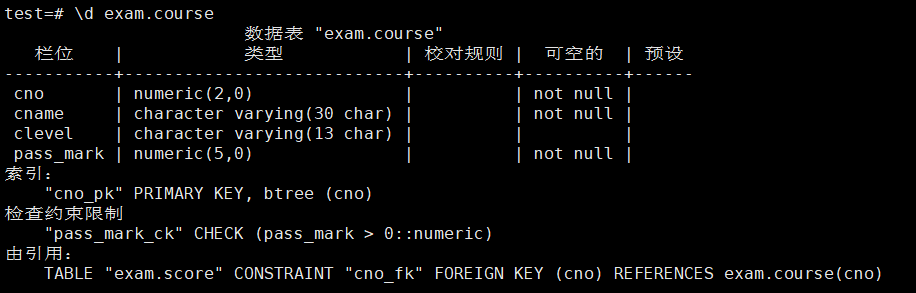
1、查看course表的结构
test=# \d exam.course
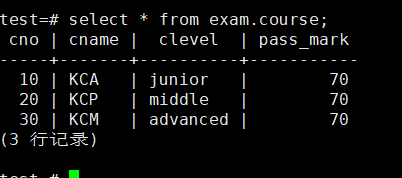
2、使用"select *"查看表中所有的数据
test=# select * from exam.course;
查询部分列
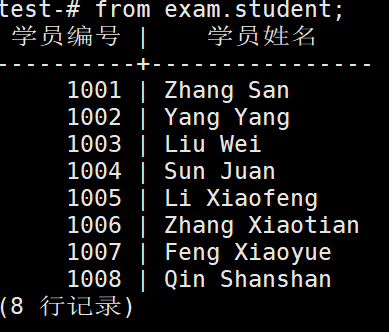
当我们想让输出的字段有意义,可以在查询的时候设置字段的别名。使用as关键字来表示别名
test=# select sno as "学员编号",sname as "学员姓名"
test-# from exam.student;
单引号和双引号
注:dual是KES中的一个虚拟表,可以理解为想要输出什么就输出什么
1、有空格、特殊字符或者以数字开头的字段别名必须加双引号
test=# select 1+1 as "1+1=?" from dual;1+1=?
-------2
(1 行记录)
2、针对标量字符串表达式必须用加单引号
test=# select 'Hello,Kingbase' as Hello from dual;hello
----------------Hello,Kingbase
(1 行记录)
连接运算
使用"||"来进行拼接
1、字符串的拼接运算
SELECT还支持将多列拼接成一个长的字符串
test=# select iname ||'的职称是'||title as "讲师信息" from exam.instructor;

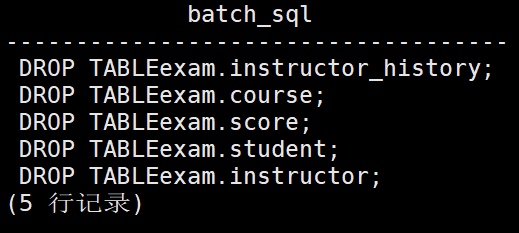
2、字符串拼接经常用于生成SQL脚本
如,要删除exam模式下所有的表,可以通过拼接生成如下批量的sql
test=# select 'DROP TABLE'||schemaname||'.'||tablename||';' as "batch_sql" from sys_tables where schemaname='exam';
算术运算符
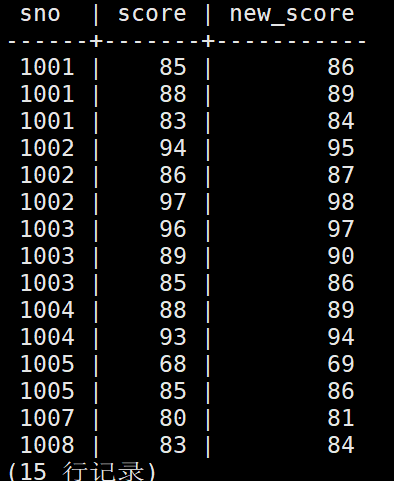
1、数值的算术运算
在查询字段处,使用算术运算符,直接进行对字段进行的运算即可
在exam.score中查询sno、score、score+1的值,并且将score+1命名为new_score
test=# select sno,score,score+1 as new_score from exam.score;
2、日期的运算符
test=# select '当前日期是'||current_date()+7 as "当前日期" from dual;当前日期
----------------------当前日期是2024-11-21
(1 行记录)
使用条件表达式
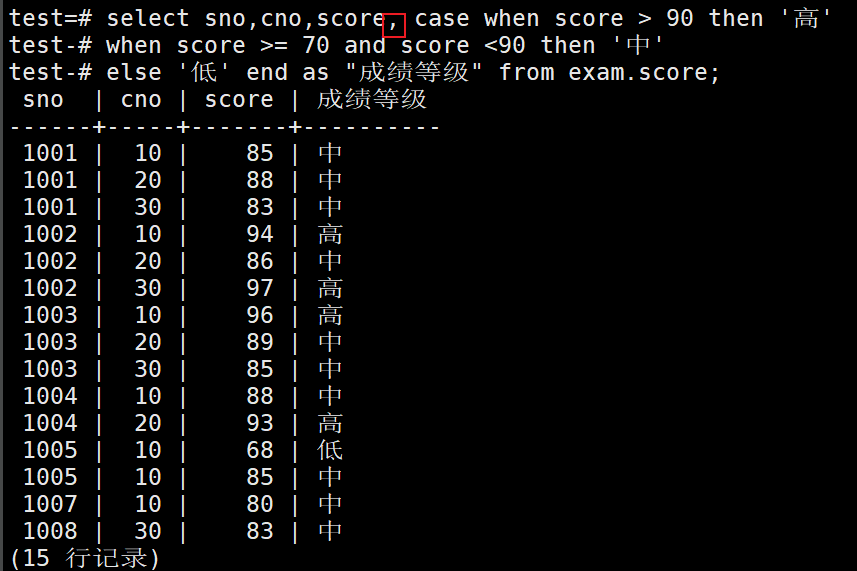
1、输出exam.score表的成绩信息(sno,cno,score),要求成绩大于等于90时输出"高",成绩大于等于70并且小于90时输出"中",其它的输出"低",可以使用条件表达式case when…then…else…end来实现
test=# select sno,cno,score, case when score > 90 then '高'
test-# when score >= 70 and score <90 then '中'
test-# else '低' end as "成绩等级" from exam.score;
实验2:where子句
在进行各种查询之前,我们要知道,查询都是基于**“where+条件”**来执行的,换句话说,这里的查询都需要有where出现
等值查询
1、数值型字段条件匹配
主要是使用where来进行条件匹配
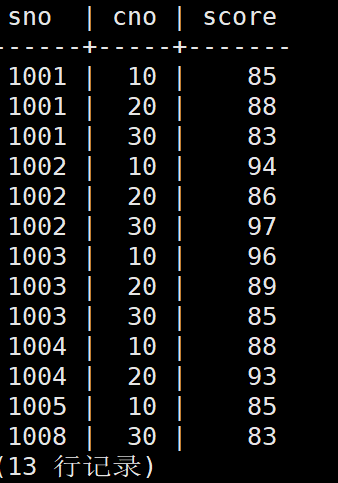
如,在exam.score表中查询分数大于80学员信息,查询字段为sno、cno、score
test=# select sno,cno,score from exam.score where score>80;
2、字符型字段条件匹配(等值匹配)
使用"字段=条件"来进行等值匹配
如,查看exam.student表中学员所在城市为Beijing的学员,查询字段为sno、sname、city
test=# select sno,sname,city from exam.student where city='Beijing';sno | sname | city
------+-----------+---------1002 | Yang Yang | Beijing1003 | Liu Wei | Beijing
(2 行记录)
3、字符型字段条件匹配(列表匹配)
使用in(条件,条件)来进行列表匹配
如,查看exam.student表中学员所在城市为Beijing或者Chongqing的学员,查询字段为sno、sname、city
test=# select sno,sname,city from exam.student where city in ('Beijing','Chongqing');sno | sname | city
------+-----------+-----------1001 | Zhang San | Chongqing1002 | Yang Yang | Beijing1003 | Liu Wei | Beijing1004 | Sun Juan | Chongqing
(4 行记录)
多条件匹配
使用关键字and来进行多条件查询
如,exam.student表中,查找所在城市为Beijing,工作岗位是Database Engineer的学员信息,查询字段为sno、sname、city、job
test=# select sno,sname,city,job from exam.student where city='Beijing' and job='Database Engineer';sno | sname | city | job
------+-----------+---------+-------------------1002 | Yang Yang | Beijing | Database Engineer1003 | Liu Wei | Beijing | Database Engineer
(2 行记录)
逻辑运算符
逻辑运算符包含"与、或、非",分别使用逻辑运算符AND、OR、NOT表示
1、逻辑运算符的优先级为NOT>AND>OR
①证明AND优先级高于OR的优先级
该查询语句表示只要where条件为真,就输出"2"
输出为2,则表示先计算"1=0 and 1=0"的结果1=0条件为假,在通过计算"1=1 or 1=0"结果为条件为真,就输出"2"
test=# select 2 from dual where 1=1 or 1=0 and 1=0; ?column?
----------2
(1 行记录)
②证明NOT优先级高于AND优先级
没有输出"1",则表示where的条件为假,而where在这里的条件是先计算"not 1=0"的条件为真,在去计算"1=0 and 1=0"的条件为假
test=# select 1 from dual where not 1=0 and 1=0;?column?
----------
(0 行记录)
2、使用括号改变优先级
和我们的运算相似,小括号可以提升括号内运算符的优先级
以下使用有小括号和没小括号来进行对比
如下,第一句是先计算"0=1 or 1=1"计算结果为真,再进行"0=9 and 1=1"的计算,很明显结果为假
第二句是先计算"0=9 and 0=1"计算结果为假,再计算"or 1=1"很明显计算结果为真
test=# select 1 from dual where 0=9 and (0=1 or 1=1);?column?
----------
(0 行记录)test=# select 1 from dual where 0=9 and 0=1 or 1=1;?column?
----------1
(1 行记录)
模糊查询
模糊查询就是使用我们的通配符搭配进行查询,借此来查询无法确认的值
模糊查询主要是使用关键字like来进行的,通配符则是有%和_两种来表示任意字符,其中"%“表示任意多个字符,”_"一个字符
不要错误地使用"="来进行模糊查询,这一点不能搞混淆了
1、在exam.student表中,查询姓名以S开头的学员信息,查询字段为sno、sname、city
test=# select sno,sname,city from exam.student where sname like 'S%'; sno | sname | city
------+----------+-----------1004 | Sun Juan | Chongqing
(1 行记录)
2、在exam.student表中,查询姓名以g字符结尾的学员信息,查询字段为sno、sname、city
test=# select sno,sname,city from exam.student where sname like '%g';sno | sname | city
------+-------------+-----------1002 | Yang Yang | Beijing1005 | Li Xiaofeng | Guangzhou
(2 行记录)
3、在exam.student表中,查找姓名中第二个字符必须为i的学员信息,查询字段为sno、sname、city
注意第二个字符为i的学员的条件不只是"_i",还有一些同学除了第二字符为i,后面还有字符的名字,所以在i的后面还需要在加一个%的通配符,即’_i%’
test=# select sno,sname,city from exam.student where sname like '_i%';sno | sname | city
------+--------------+-----------1003 | Liu Wei | Beijing1005 | Li Xiaofeng | Guangzhou1008 | Qin Shanshan | Xian
(3 行记录)
范围查询
在exam.student中,查询在2021年7月1日到9月1日参加培训的学员信息,查询字段为sno、sname、reg_date
在范围查找中,我们可以使用BETWEEN…AND…的条件关键字进行查询
test=# select sno,sname,reg_date from exam.student where reg_date between '2021-07-01' and '2021-09-01';sno | sname | reg_date
------+-------------+---------------------1003 | Liu Wei | 2021-07-10 00:00:001005 | Li Xiaofeng | 2021-09-01 00:00:00
(2 行记录)
空值查询
在exam.student表中,查询工作单位为空的学员信息,查询字段为sno、sname、company
查询空值可以使用"字段 IS null"作为查询的条件进行查询
test=# select sno,sname,company from exam.student where company is null;sno | sname | company
------+--------------+---------1007 | Feng Xiaoyue |
(1 行记录)
实验3:ORDER BY子句
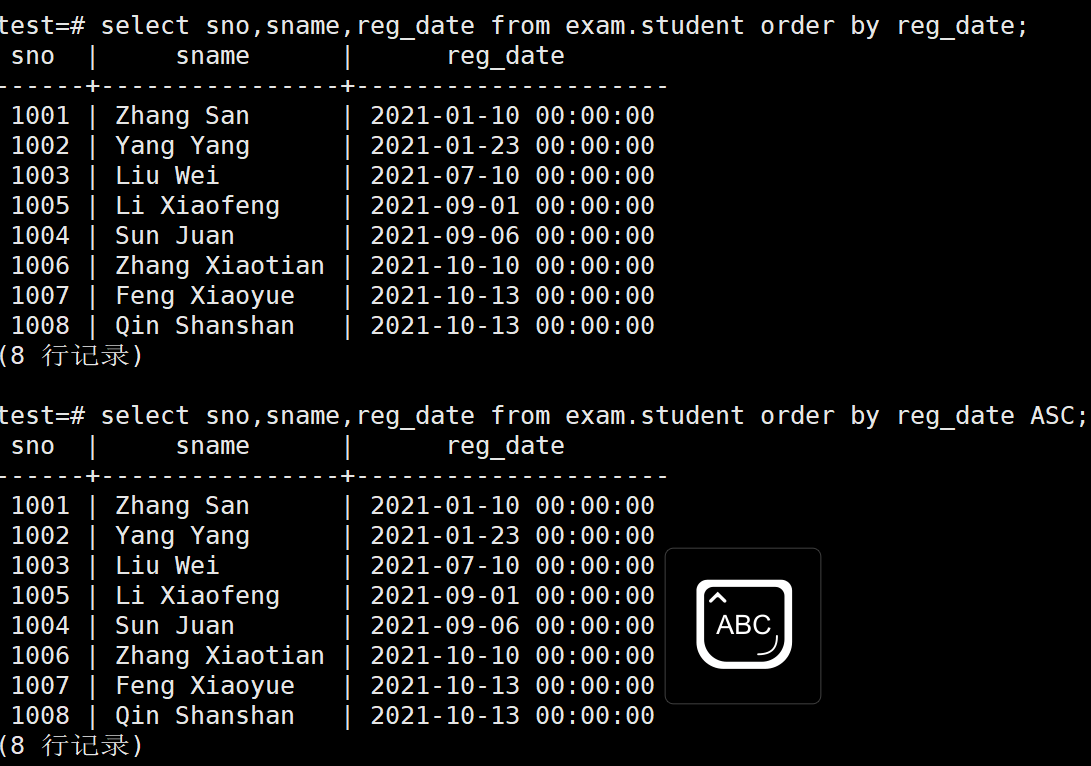
ORDER BY可以对特定字段的输出结果进行升序或者降序的排序
升序排列使用ASC
当我们使用ORDER BY的时候,默认就使用ASC选项,如下,使用ASC选项和不使用ASC选项的结果都是一致的
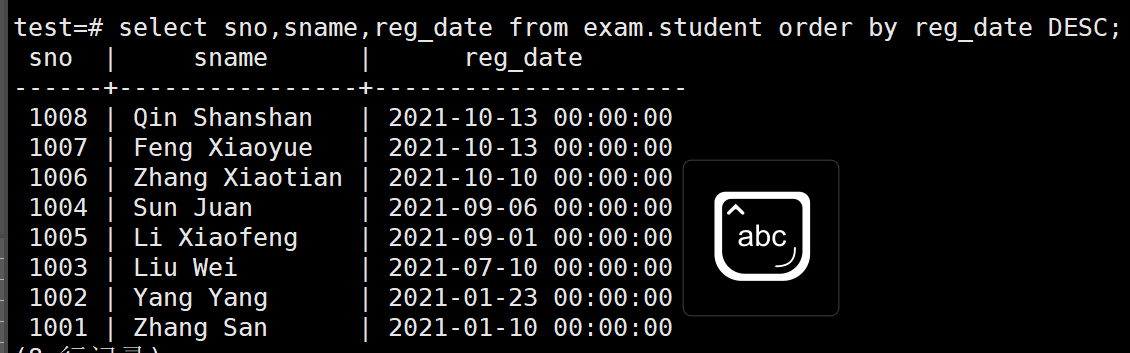
降序排列使用DESC
除了升序,当然还有降序排列的输出,就是使用DESC关键字
引用字段别名排序
按姓名排序
在exam.student表中查询sname、gender、phone,并将sname设置别名为name,将姓名进行升序排序
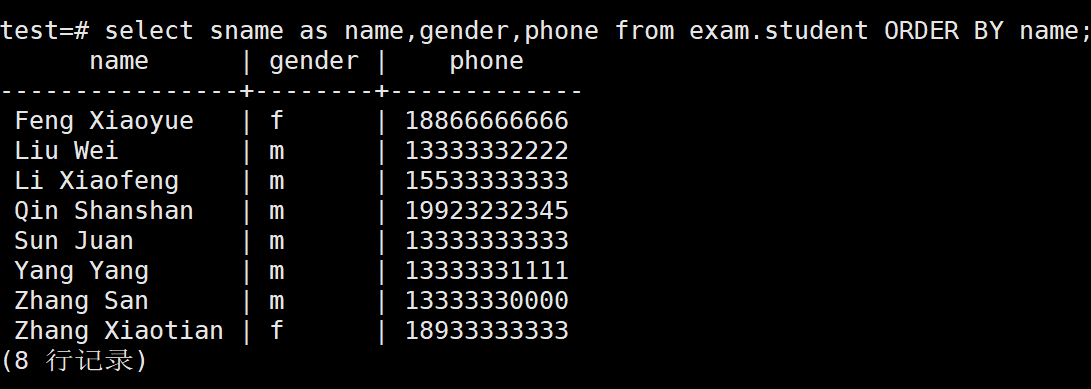
如下所示,我们在进行排序的时候,也是可以使用别名来代替我们的字段进行在ORDER BY中的排序的
test=# select sname as name,gender,phone from exam.student ORDER BY name;
引用字段顺序号排序
按照注册日期升序排列
如下,我们进行排序时,为了少一点输入,可以直接输入字段在查询时的顺序
例如这里的ORDER BY 3,就是对查询字段顺序中第三进行排序的,即reg_date
test=# select sno,sname,reg_date from exam.student order by 3;sno | sname | reg_date
------+----------------+---------------------1001 | Zhang San | 2021-01-10 00:00:001002 | Yang Yang | 2021-01-23 00:00:001003 | Liu Wei | 2021-07-10 00:00:001005 | Li Xiaofeng | 2021-09-01 00:00:001004 | Sun Juan | 2021-09-06 00:00:001006 | Zhang Xiaotian | 2021-10-10 00:00:001007 | Feng Xiaoyue | 2021-10-13 00:00:001008 | Qin Shanshan | 2021-10-13 00:00:00
(8 行记录)
多列组合排序
面对不同的输出需求,我么可以先对一个字段进行排序(升序/降序),然后再对另一个字段进行排序(升序/降序)
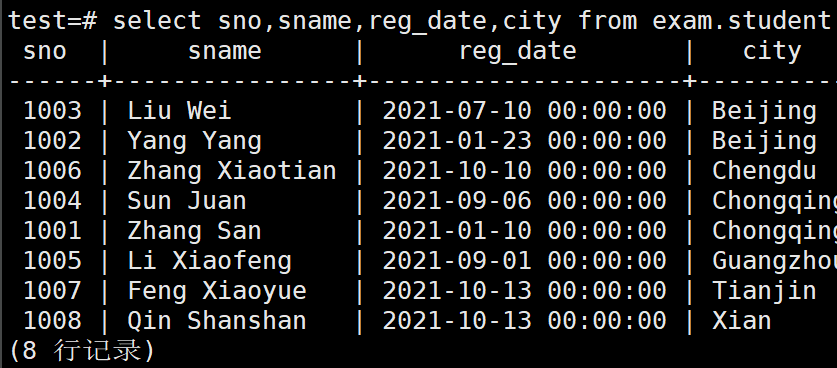
例如,先在所在城市升序排列,接着在同一个城市中再按日期降序排列
test=# select sno,sname,reg_date,city from exam.student order by city,reg_date DESC;
小结和扩充
限制返回的行数
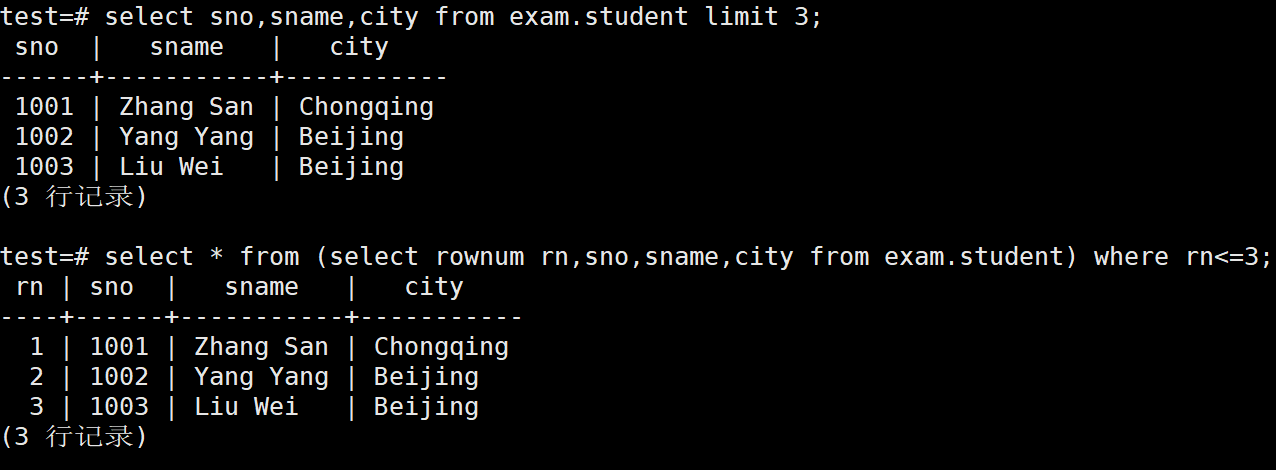
1、使用limit子句来限制返回的行数
limit是限制行的输出
test=# select sno,sname,city from exam.student limit 3;
2、使用子查询来限制返回的行数
test=# select * from (select rownum rn,sno,sname,city from exam.student) where rn<=3;
分页查询
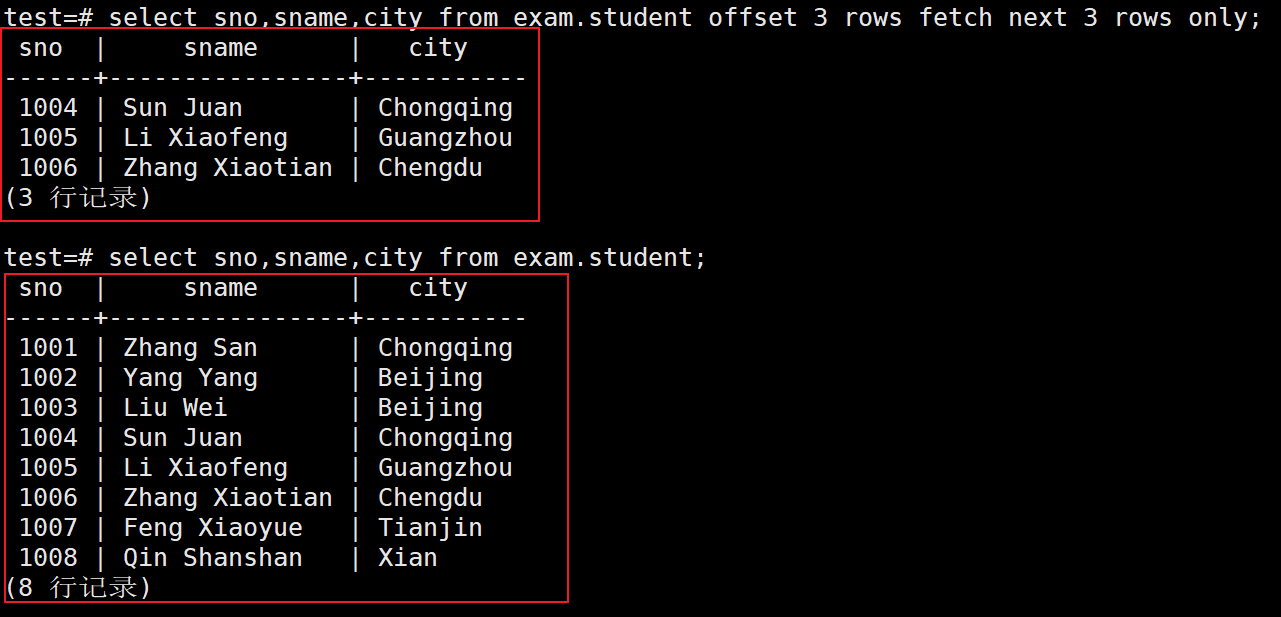
当我们面对庞大的数据量,却又不想直接输出的结果太多时,可以是使用SQL语句中的分页查询
使用关键词offset fetch来进行查询,用法offset “从第几行开始” fetch “需要输出几行”
如下,“offset 3 rows fetch next 3 rows”,表示排除掉前三行,从第四行开始输出,输出3行后停止
test=# select sno,sname,city from exam.student offset 3 rows fetch next 3 rows only;
如下是不使用分页查询和使用分页查询的区别
| 关键字 | 说明 |
|---|---|
| offset | 表示排除结果集前面的N行记录,即从N+1行开始返回 |
| fetch | 表示从N+1行开始总共要返回的记录数 |
| next/first | 两者没有实际差异,都表示返回的行数 |
| row/rows | 两者没有实际差异,只是为了构建更清晰的语法而已 |
DISTINCT关键字去重复值
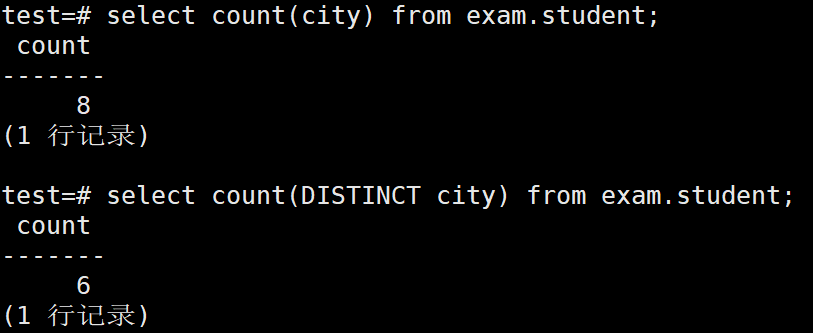
1、查看student表中城市的数量(含重复值),使用count()函数来计算
test=# select count(city) from exam.student;
2、查看student表中城市的数量(去掉重复值)
test=# select count(DISTINCT city) from exam.student;