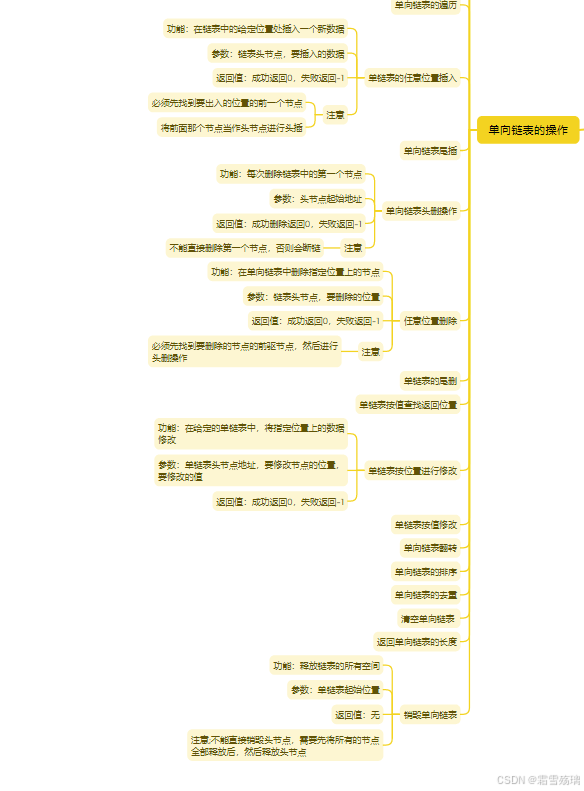
1、用户通过kubectl或其他api客户端提交pod spec给apiserver, 然后会进行认证、鉴权、变更、校验等一系列过程2、apiserver将pod对象的相关信息最终存入etcd中, 待写入操作执行完成, apiserver会返回确认信息给客户端3、apiserver开始反应etcd的状态变化4、controller-manager组件使用watch接口来跟踪检查apiserver上的相关变动。有以下两个过程 : 1)、先是deployment controller监听到deployment的创建事件, 然后进行相关的处理, 最后创建replicas2)、然后 replicaset controller 监听到 replicaset 的创建事件,进行相关处理后,最后创建 pod5、kube- scheduler通过其watch接口察觉到apiserver创建了新的pod对象但尚未绑定至任何工作节点6、kube- scheduler为pod对象挑选一个工作节点并将结果信息更新至apiserver7、调度结果信息由apiserver更新到etcd中, 同时apiserver开始反映pod对象的调度结果8、pod被调度到目标工作节点上的kubelet尝试在当前节点上执行以下步骤(grpc协议) : 1)、调用CNI容器网络接口给pod分配ip地址创建网络, 2)、调用CRI容器运行时接口去拉取镜像、创建并启动容器, 3)、调用CSI容器存储接口, 负责与外部存储提供者通信, 进行存储卷的挂载, 并将容器状态结果返回给apiserver9、apiserver将pod状态信息存入etcd中10、在etcd确认写入操作成功完成后, apiserver将确认信息发给相关的kubelet来调动docker创建容器
用户提交请求后系统即会进行强制删除操作的宽限期倒计时,并将TERM信号发送给Pod对象中每个容器的主进程。宽限期倒计时结束后,这些进程将收到强制终止的KILL信号,Pod对象也随即由APIServer删除。如果在等待进程终止的过程中kubelet或容器管理器发生了重启,则终止操作会重新获得一个满额的删除宽限期并重新执行删除操作
1、用户发出删除pod命令2、api服务器中的pod对象会随着时间的推移而更新3、将pod标记为terminating状态4、kubelet在监控到pod对象转为terminating状态的同时启动pod关闭过程5、端点控制器监控到pod对象的关闭行为时将其从所有匹配到此端点的service资源的端点(endpoint)列表中移除6、如果pod定义了prestop钩子处理器, 则其标记为terminating后会以同步的方式启动执行;若宽限期结束后, prestop仍未结束, 则第二步会被重新执行并额外获取一个时长2s的小宽限期7、pod对象中的容器进程收到TERM信号8、宽限期结束后, 若存在任何一个仍在运行的进程, 那么pod对象即会收到sigkill信号9、kubelet请求apiserver将此pod资源的宽限期设置为0从而完成删除操作。











![[CTF/网络安全] 攻防世界 upload1 解题详析](https://img-blog.csdnimg.cn/e6a6d77b2eac4d02992580ff5a836d0e.png#pic_center)