神经网络在项目实践中遇到的一大问题是数据不足。任何人工智能项目,在数据不足面前都会巧妇难为无米之炊,算法再精巧,只要数据量不足,最后的效果都不尽如人意,我们目前正在做的图像识别就是如此,要想让网络准确的识别猫狗图片,没有几万张图片以上是做不到的。
君子擅假于物,我们没有图片对模型进行训练,但如果别人有足够的图片,并且已经训练好了相应网络,我们能不能直接拿过来就用呢?答案是肯定的。有一些机构使用大量图片训练网络后,并把训练好的网络分享出来,假设别人用几万张猫狗图片训练出了网络,我们直接拿过来用于识别自己的猫狗图片,那显然效率和准确率比我们自己构造一个网络要高的多。
有很多机构,构造了自己的网络后,将ImageNet上海量的图片输入到网络中训练,最后得到了识别率很高的网络,而且他们愿意把劳动成果分享出来,由此我们可以不客气的直接借用。后面我们将使用一个大型卷积网络,它经过了大量数据的严格训练,这些图片数据来源于ImageNet,该网站包含140万张图片资源,这些图片大多涉及我们日常生活的物品以及常见动物,显然很多不同种类的猫和狗必然包含在内。
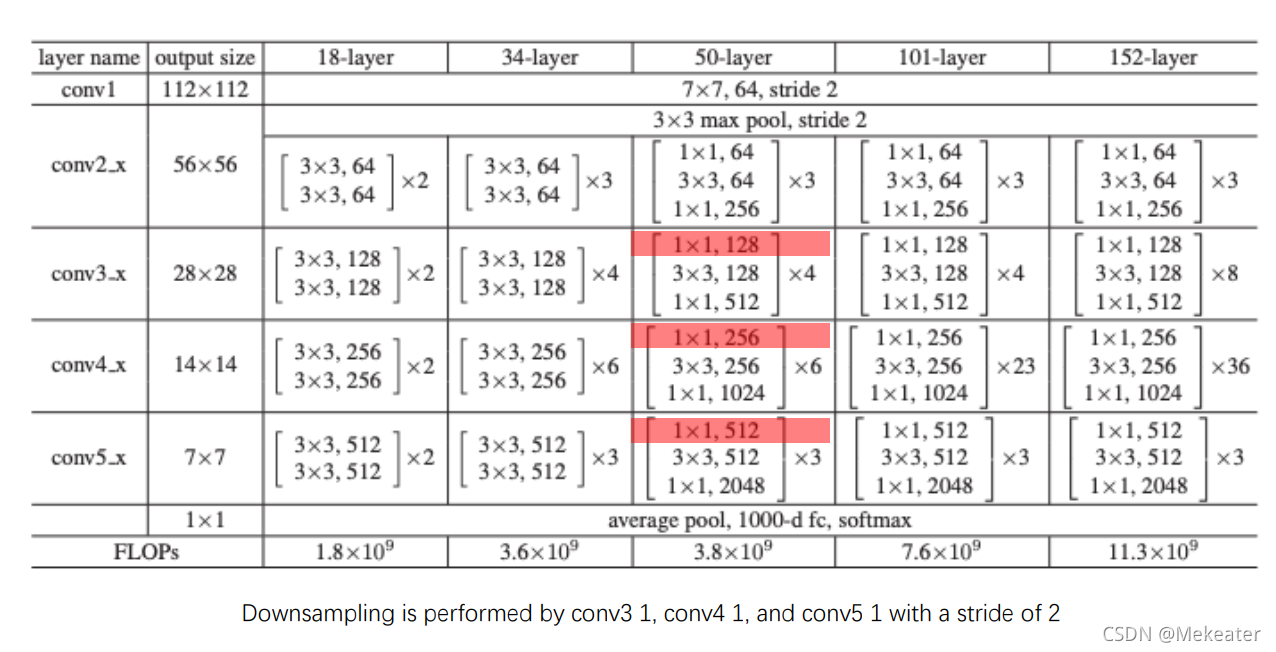
我们将使用一个训练好的神经网络叫VGG16,后面我们还会遇到一系列稀奇古怪的公开网络,例如ResNet, Inception, Xception等等,这些网络很像程序开发中的开源库,别人做好后分享给别人直接用。由于别人做出的网络肯定跟我们自己面对的应用场景有所区别,所以在使用时,我们必须对其进行相应改造,常用的方法有特征抽取和参数调优,我们分别就这两种方法进行深入讨论。
我们先看所谓的特征抽取。在我们构造卷积网络时,一开始先是好几层卷积层和Max Pooling层,然后会调用Flatten()把他们输出的多维向量压扁后,传入到普通层,下面代码就是我们前几节做过的卷积网络,它的结构正如我们刚才描述的那样:
from keras import layers
from keras import models
from keras import optimizersmodel = models.Sequential()
#输入图片大小是150*150 3表示图片像素用(R,G,B)表示
model.add(layers.Conv2D(32, (3,3), activation='relu', input_shape=(150 , 150, 3)))
model.add(layers.MaxPooling2D((2,2)))model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4),metrics=['acc'])model.summary()我们现在要借用的的VGG16网络,其结构与上面差不多,只不过它的Conv2D和MaxPooling层要比我们上面做的多得多而已。在我们借用别人训练好的网络时,往往要去掉Flatten()后面的网络层,因为那些网络层与别人构造网络时的具体应用场景相关,他们的应用场景与我们肯定不同,我们要借用的是Flatten上面那些由卷积层和Max Pooling层输出的结果,这些结果蕴含着对训练图片本质的认知,这才是我们想要的,去掉Flatten后面的神经层,换上我们自己的神经层,这个行为就叫特征抽取,具体流程如下图:

VGG16网络早已包含在keras框架中,我们可以方便的直接引用,我们通过如下代码来初始化一个VGG16网络实例:
from keras.applications import VGG16conv_base = VGG16(weights = 'imagenet', include_top = False, input_shape=(150, 150, 3))conv_base.summary()weight参数告诉程序将网络的卷积层和max pooling层对应的参数传递过来,并将它们初始化成对应的网络层次。include_top表示是否也要把Flatten()后面的网络层也下载过来,VGG16对应的这层网络用来将图片划分到1000个不同类别中,由于我们只用来区分猫狗两个类别,因此我们去掉它这一层。input_shape告诉网络,我们输入图片的大小是150*150像素,每个像素由[R, G, B]三个值表示。上面代码执行后结果如下:

从上面输出结果看出,VGG16的网络结构与我们前面做的网络差不多,只不过它的层次要比我们多不少。最后的(None, 4, 4, 512)表示它将输出4*4的矩阵,而这些矩阵有512层,或者你也可以看成它将输出一个4*4的矩阵,而矩阵每个元素是包含512个值的向量。
接下来我们将把自己的图片读进来,把图片喂给上面网络,让它把图片的隐含信息给抽取出来:
import os
import numpy as np
from keras.preprocessing.image import ImageDataGeneratorbase_dir = '/Users/chenyi/Documents/人工智能/all/cats_and_dogs_small'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')datagen = ImageDataGenerator(rescale = 1. / 255)
batch_size = 20def extract_features(directory, sample_count):features = np.zeros(shape = (sample_count, 4, 4, 512))labels = np.zeros(shape = (sample_count))generator = datagen.flow_from_directory(directory, target_size = (150, 150), batch_size = batch_size,class_mode = 'binary')i = 0for inputs_batch, labels_batch in generator:#把图片输入VGG16卷积层,让它把图片信息抽取出来features_batch = conv_base.predict(inputs_batch)#feature_batch 是 4*4*512结构features[i * batch_size : (i + 1)*batch_size] = features_batchlabels[i * batch_size : (i+1)*batch_size] = labels_batchi += 1if i * batch_size >= sample_count :#for in 在generator上的循环是无止境的,因此我们必须主动break掉breakreturn features , labels#extract_features 返回数据格式为(samples, 4, 4, 512)
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)上面代码利用VGG16的卷积层把图片的特征抽取出来,接下来我们就可以吧抽取的特征输入到我们自己的神经层中进行分类,代码如下:
train_features = np.reshape(train_features, (2000, 4 * 4 * 512))
validation_features = np.reshape(validation_features, (1000, 4 * 4 * 512))
test_features = np.reshape(test_features, (1000, 4 * 4* 512))from keras import models
from keras import layers
from keras import optimizers#构造我们自己的网络层对输出数据进行分类
model = models.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim = 4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation = 'sigmoid'))model.compile(optimizer=optimizers.RMSprop(lr = 2e-5), loss = 'binary_crossentropy', metrics = ['acc'])
history = model.fit(train_features, train_labels, epochs = 30, batch_size = 20, validation_data = (validation_features, validation_labels))由于我们不需要训练卷积层,因此上面代码运行会很快,我们把训练结果和校验结果画出来看看:
import matplotlib.pyplot as pltacc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']epochs = range(1, len(acc) + 1)plt.plot(epochs, acc, 'bo', label = 'Train_acc')
plt.plot(epochs, val_acc, 'b', label = 'Validation acc')
plt.title('Trainning and validation accuracy')
plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label = 'Training loss')
plt.plot(epochs, val_loss, 'b', label = 'Validation loss')
plt.title('Training and validation loss')
plt.legend()plt.show()上面代码运行后结果如下:

从上面可以看出,经过一百多万张图片训练的网络,其识别效果就要比我们用4000张图片训练的网络要好很多,网络对图片的校验正确率达到了99%以上,同时对训练数据和校验数据的损失估计完全是一模一样的。
上面的方法叫特征提取,还有一种方法叫参数调优。特征提取时,我们把图片输入VGG16的卷积层,让他直接帮我们把图片中的特征提取出来,我们并没有通过自己的图片去训练更改VGG16的卷积层,参数调优的做法在于,我们会有限度的通过自己的数据去训练VGG16提供的卷积层,于是让其能从我们的图片中学习到相关信息。我们从VGG16模型中获取了它六层卷积层,我们在调优时,让这六层卷积层中的最高2层也去学习我们的图片,于是最高两层的链路权重参数会根据我们的图片性质而更改,基本情况如下:

上图就是我们从VGG16拿到的卷积层,我们用自己的图片去训练修改它最高的两层,其他层次不做修改,这种只影响模型一部分的方法就叫参数调优。调优必须只对VGG16的卷积层做小范围修改,因为它的模型是经过大数据,反复训练得到的,如果我们对它进行大范围修改,就会破坏它原来训练的结果,这样人家辛苦做出来的工作成果就会被我们毁于一旦。所以参数调优的步骤如下:
1,将我们自己的网络层添加到VGG16的卷积层之上。
2,固定VGG16的卷积层保持不变。
3,用数据训练我们自己添加的网络层
4,将VGG16的卷积层最高两层放开
5,用数据同时训练放开的那两层卷积层和我们自己添加的网络层
我们看看代码就明白上面步骤所要描述的意思:
model = models.Sequential()
#将VGG16的卷积层直接添加到我们的网络
model.add(conv_base)
#添加我们自己的网络层
model.add(layers.Flatten())
model.add(layers.Dense(256, activation = 'relu'))
model.add(layers.Dense(1, activation = 'sigmoid'))
model.summary()上面代码运行后结果如下:

从上面输出结果看,VGG16的卷积层已经有一千多万个参数了!用个人电脑单个CPU是不可能对这个模型进行训练的!但我们可以训练它的其中一部分,我们把它最高三层与我们自己的网络层结合在一起训练,同时冻结最低四层。下面的代码将会把卷积层进行部分冻结:
conv_base.trainable = True
set_trainable = False
#一旦读取到'block5_conv1'时,意味着来到卷积网络的最高三层
#可以使用conv_base.summary()来查看卷积层的信息
for layer in conv_base.layers:if layer.name == 'block5_conv1':set_trainable = Trueif set_trainable:#当trainable == True 意味着该网络层可以更改,要不然该网络层会被冻结,不能修改layer.trainable = Trueelse:layer.trainable = False然后我们把数据传入网络,训练给定的卷积层和我们自己的网络层:
#把图片数据读取进来
test_datagen = ImageDataGenerator(rescale = 1. / 255)
train_generator = test_datagen.flow_from_directory(train_dir, target_size = (150, 150), batch_size = 20,class_mode = 'binary')
validation_generator = test_datagen.flow_from_directory(validation_dir, target_size = (150,150),batch_size = 20,class_mode = 'binary')
model.compile(loss = 'binary_crossentropy', optimizer = optimizers.RMSprop(2e-5),metrics = ['acc'])history = model.fit_generator(train_generator, steps_per_epoch = 100, epochs = 30, validation_data = validation_generator,validation_steps = 50)由于我的电脑运行上面代码时太慢,因此这里我没有把训练结果显示出来,有兴趣的读者可以自己尝试一下。
更详细的讲解和代码调试演示过程,请点击链接
更多技术信息,包括操作系统,编译器,面试算法,机器学习,人工智能,请关照我的公众号: