文章目录
前言
一、精准营销简介
二、大数据精准营销过程
三、大数据精准营销方式
四、项目目标
五、项目流程
六、数据的处理
数据的预览
数据的读取
数据的解析
数据预处理
异常值处理
缺失值处理
时间格式和时区转换
量纲转化
重复数据处理
总结
前言
随着大数据时代的不断发展,大数据在生活方面的应用这门技术也越来越重要,很多人都开启了学学习大数据及家属,本文就介绍了大数据在精准营销方面的应用。
一、精准营销简介
精准营销是指企业通过定量和定性相结合的方法,对目标市场的不同消费者进行细致分析,并根据他们不同的消费心理和行为特征,采用有针对性的现代技术、方法和指向明确的策略,从而实现对目标市场不同消费者群体强有效性、高投资回报的营销沟通。
精准营销最大的优点在于“精准”,即在市场细分的基础上,对不同消费者进行细致分析,确定目标对象。
精准营销的主要特点有以下几点:
1)精准的客户定位是营销策略的基础。
2)精准营销能提供高效、投资高回报的个性化沟通。过去营销活动面对的是大众,目标不够明确,沟通效果不明显。精准营销是在确定目标对象后,划分客户生命周期的各个阶段,抓住消费者的心理,进行细致、有效的沟通。
3)精准营销为客户提供增值服务,为客户细致分析,量身定做,避免了用户对商品的挑选,节约了客户的时间成本和精力,同时满足客户的个性化需求,增加了顾客让渡价值。
4)发达的信息技术有益于企业实现精准化营销,“大数据”和“互联网+”时代的到来,意味着人们可以利用数字中的镜像世界映射出现实世界的个性特征。
二、大数据精准营销过程
传统的营销理念是根据顾客的基本属性,如顾客的性别、年龄、职业和收入等来判断顾客的购买力和产品需求,从而进行市场细分,以及制定相应的产品营销策略,这是一种静态的营销方式。 大数据精准营销不仅记录了人们的行为轨迹,还记录了人们的情感与生活习惯,能够精准预测顾客的需求,从而实现以客户生命周期为基准的精准化营销,这是一个动态的营销过程。
1)助力客户信息收集与处理
2)客户细分与市场定位
3)辅助营销决策与营销战略设计
4)精准的营销服务
5)营销方案设计
6)营销结果反馈
三、大数据精准营销方式
在大数据的背景下,百度等公司掌握了大量的调研对象的数据资源,这些用户的前后行为将能够被精准地关联起来。具体方式包括以下几点
1)实时竞价(RTB)
2)交叉销售
3)点告
4)窄告
5)定向广告推送
四、项目目标
1.通过对海量交易流水数据的深度分析和挖掘,构建全方位的客户标签体系。
2.基于客户标签体系,从基本信息、消费能力、行为习惯等多个维度对客户进行精准画像。
3.计算客户商品兴趣度排行榜,支持精准目标客户筛选。
五、项目流程
先找到符合要求的数据集,导入MySQL数据库,使用pymsql将数据源提取到python,再进行数据预处理,再进行客户交易行为的分析,客户标签体系的构建最后进行精准营销的应用。

六、数据的处理
数据的预览
数据来源于sql文件数据。
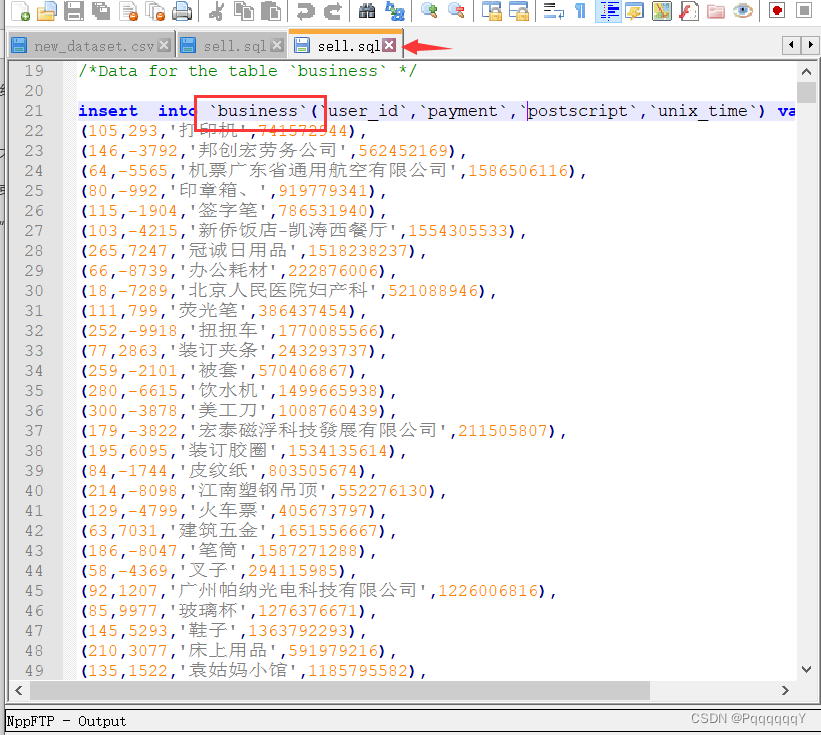
其中包含本项目包含客户在某平台的367万脱敏交易流水数据,交易时间跨度为5年。每条交易记录包含客户ID、交易时间、交易金额和交易附言四个字段,如下表所示︰
数据的读取
主要包括以下三个步骤︰
数据描述︰字段中英文、取值范围和备注信息·
数据调用:MySQL数据库的连接和数据提取·
数据解析︰将数据格式转换为DataFrame
主要涉及PyMySQL、Pandas等模块的基本使用
首先创建数据库sell

再将sql文件导入到数据库中

创建表business
再使用source语句导入sql文件
查看导入的数据:
数据的解析
选择使用python来进行数据解析
Python对于数据预处理和数据再加工非常的友好,但是缺少了一些数据预处理和清洗部分。Pandas使得可以只使用Python完成完整的数据清洗流程,并且不用依靠其他的特定领域的语言·使用非常广泛,功能强大,得到很多公司和个人的认可
使用python中的pymysql库来连接MySQL数据库
从数据库中读入全部数据(select * from business),并将其命名为sql。但目前的数据是以嵌套的形式存储的,所以需要将其转化为Pandas内置的DataFrame对象,再进行后续操作。

db为数据库的database
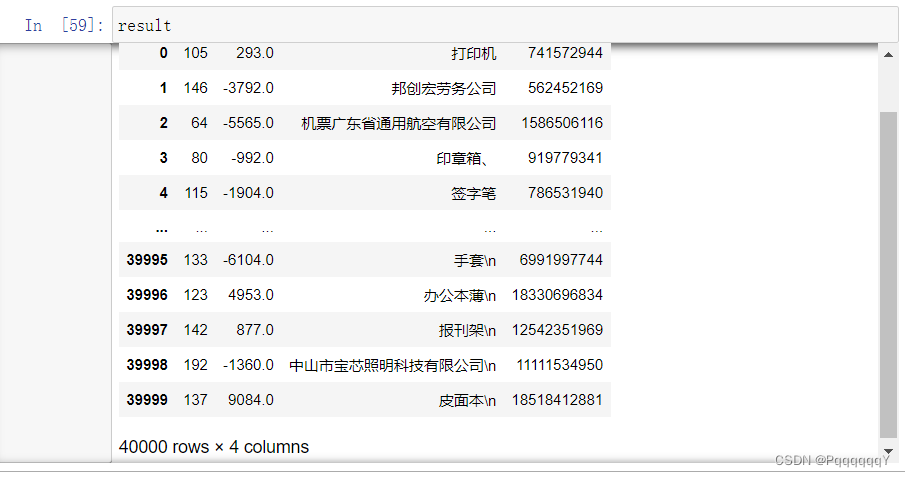
查看导入的result,有40000行数据,说明导入成功!
再将列名进行处理修改成MySQL数据库中相对应的表名:
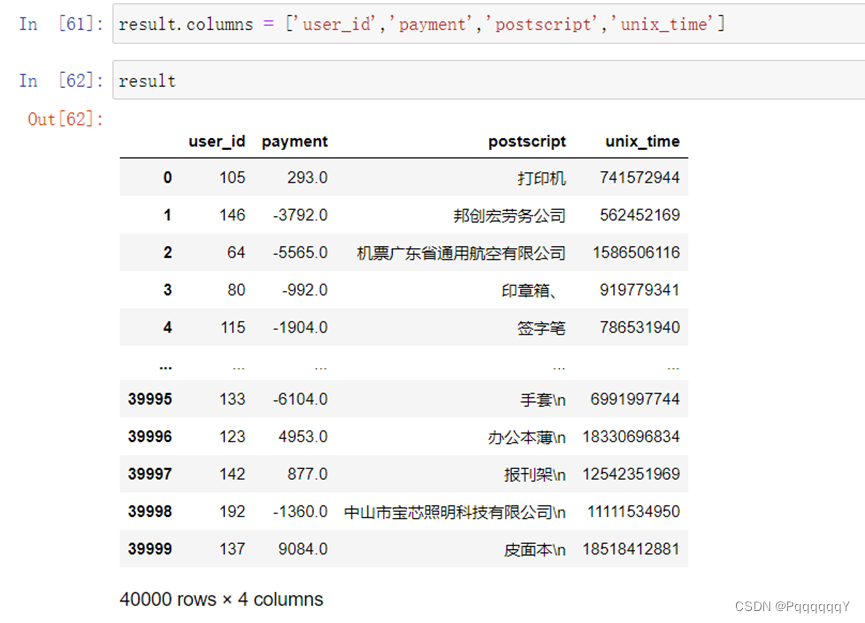
数据预处理
由于原始数据存在一些质量问题,为了便于后续的数据分析,我们需要进行数据预处理。利用Pandas提供的便利工具和函数,对交易数据进行预处理的流程如下图所示∶

数据预处理主要包括以下五个步骤:
1) 统计分析:对数据进行统计分析,初步了解数据特点。
2) 异常值处理:对交易时间等字段中出现的异常数据进行诊断,并确定异常值处理方法。
3) 缺失值处理∶对于存在缺失值的交易金额和交易附言字段,诊断缺失值产生的原因,确定缺失值处理方法。
4) 数据格式转换∶为了便于后续分析,对于金额字段的量纲、交易时间字段的时间格式进行转换。
5) 重复数据过滤︰检测交易数据中存在的重复交易记录,并删除重复的记录。
主要涉及NumPy、Pandas等模块的基本使用
查看导入的数据:

客户交易流水记录中正值为金额流出,负值为金额流入
交易附言信息为中文描述,该列数据之后可能要进行文本处理·
交易时间列为unix时间戳,转换为标准北京时间更易处理。
发现其中的一些多余的符号需要去除。
查看result数据的总列数和总行数,分别在变量rows和cols中

查看数据的前五行,将结果保存到变量head中。

查看数据的基本情况:
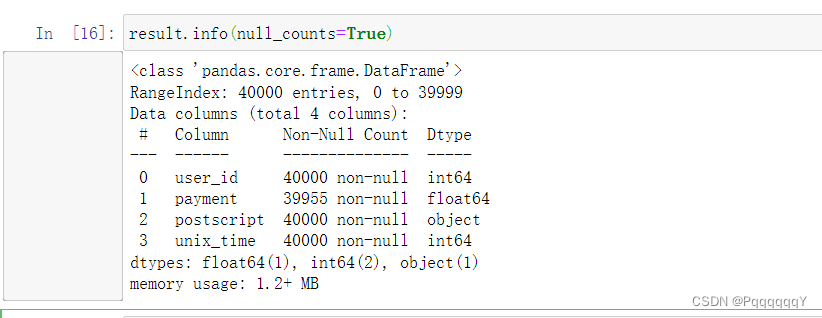
查看客户总数,将客户数保存在数值变量user_num中

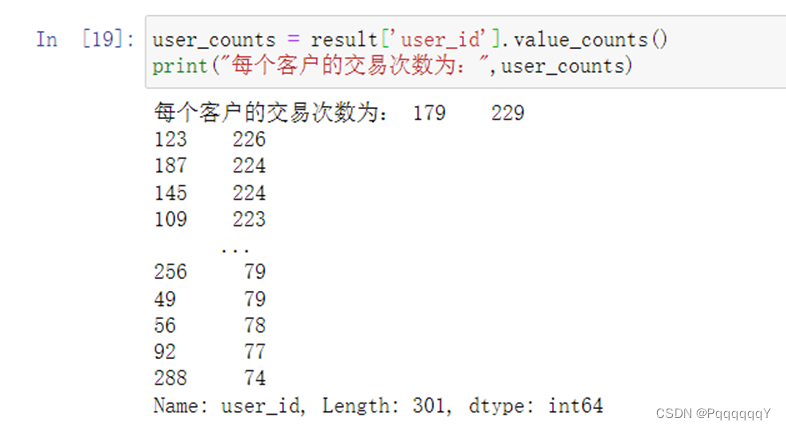
计算交易次数,保存在变量user_counts中
异常值处理
Unix时间戳是指格林尼治时间1970年01月01日00时00分00秒起至现在的总秒数。我们已经知道交易时间(unix_time )字段无缺失值,还需要检测数据中是否有异常的情况。Unix时间戳为10位数字(如果精确到毫秒为13位),我们使用正则表达式对数据进行匹配,检测是否存在位数异常的值。

发现数据中没有空缺数值的异常值,通常时间戳为10位,数据中出现了9位和11位的时间戳视为异常值处理,处理方法是将这些九位的数据在第一位加1.11位的时间戳删除其最后一位。
处理完之后查看数据

再次使用正则表达式查找异常值发现无异常值,说明异常值处理成功
缺失值处理
查看交易时间是否存在缺失值

结果为0不存在缺失值
查看交易附言是否存在缺失值

结果为0不存在缺失值
查看交易金额是否存在缺失值

可以看出payment这一列含有45个缺失值,应该将其删除,删除缺失值以后再次查询缺失值的数据为0条
查看result数据
删除了45条缺失值以后还有39955条正常的数据
时间格式和时区转换
将时间戳转换为“年-月-日 时:分:秒”

查看结果:
 时区转化:将林格威治时间转换为北京时间并查看最后五条数据
时区转化:将林格威治时间转换为北京时间并查看最后五条数据

量纲转化
在以上处理的过程中,我们会观察到 payment全部为整型数值。在这里,我们将其转换为更符合我们观察的形式,将其小数点向左平移两位,形式为'元.角分'。

重复数据处理
接下来对数据进一步分析,检测是否存在重复交易记录,并进行处理。DataFrame的duplicated()函数可以判断数据中的行是否有重复,返回值为一个Series对象。其中无重复值的行标记为False ,有重复值的行标记为True 。

可以发现重复数据有0行
总结
至此,数据的处理已经完成,下一步将进行客户交易行为的分析。