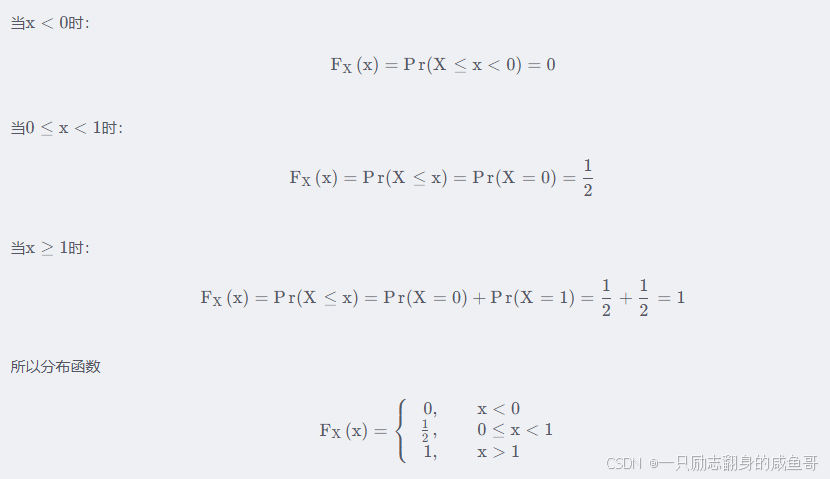我自己的原文哦~ https://blog.51cto.com/whaosoft/12088488
#PDD
西南交大&利兹大学等联合提出金字塔离散扩散模型(PDD),实现了3D户外场景生成的粗到细的策略
本文是对 ECCV 2024 Oral 文章Pyramid Diffusion for Fine 3D Large Scene Generation的介绍。代码已经开源。
代码链接:https://github.com/yuhengliu02/pyramid-discrete-diffusion
论文链接:https://arxiv.org/abs/2311.12085
项目官网:https://yuheng.ink/project-page/pyramid-discrete-diffusion/
使用提出的Pyramid Discrete Diffusion方法生成的无限场景的Demo视频。
Introduction
3D场景生成旨在模拟我们现实世界环境的三维复杂性,从而能够帮助我们更好地理解物理世界。这项技术在自动驾驶,虚拟现实,具身智能中都发挥着至关重要的作用。然而,由于3D场景本身的庞大规模以及缺乏大规模的3D场景数据集,想要生成高质量的3D场景仍然极具挑战性。
尽管生成式扩散模型在生成2D图像或者小型3D物体上也有不错的效果,但是将扩散模型直接应用于3D场景的生成并非易事,特别是3D的户外场景。一方面扩散模型会占用大量资源,并且需要很长的训练时间,另一方面,扩散模型需要大量的训练数据,但目前还十分缺少高质量的3D户外场景数据,这就导致扩散模型难以生成大规模和具备复杂细节的3D户外场景。
为了解决这些问题,现有的工作主要都集中于有条件的扩散模型生成,借助像场景图,2D语义图这样的附加条件对生成式模型进行指导。但是这种条件指导的方式可能会限制了生成式扩散模型的泛化能力。因此,受到图像超分辨率中广泛使用的“粗到细”(Coarse-to-Fine)的启发,作者引入了金字塔离散扩散模型(PDD),这个框架可以在不依赖外部指导条件的情况下逐步生成大规模且精细化的3D户外场景。
Method
作者首先生成小规模的3D场景,并且在这个的基础上逐步增加场景的分辨率及细节。
在每个规模层次上,作者都会单独训练适用于当前规模的扩散模型,而这个模型会使用前一规模生成的场景作为条件(除了第一个生成的场景,第一个生成的场景使用噪声作为模型的输入)来生成更大规模的3D场景。
这种分阶段且多尺度的生成过程将一个具有困难和挑战性的无条件场景生成任务分解为了几个更易于管理的条件生成任务。此外,在最高分辨率的生成中,作者还采用了一种场景细分的技术,将大场景划分为多个较小的子场景,并且使用共享扩散模型进行合成。
这个技术解决了3D户外场景体积庞大而导致的模型过大的问题。并且这种多尺度的生成框架还能够实现跨数据集的转移应用,即在模拟数据集(例如CarlaSC)上预训练好的模型可以直接在现实中采集的数据集(例如SemanticKITTI)上直接进行微调,从而在减少训练资源和时间的基础上还实现了在新数据集上的高质量生成。
最后,作者还进一步提出了一种基于PDD框架的扩展,该拓展可以用于无限3D户外场景的生成。
PDD在创新性方面主要做出了以下贡献:
提出了一个新的适用于3D户外场景生成的金字塔扩散模型,实现了3D户外场景生成的粗到细的策略。
对PDD进行了广泛的实验,证明了在与现有方法相当的计算资源下,该方法能够生成更高质量的3D场景,此外,还引入了新的度量标准,从多个方面评估3D户外场景的生成质量。
展现了PDD方法更广泛的应用:能够从合成数据集生成到真实世界数据的场景生成;可以通过拓展PDD来支持无限场景的生成。

根据上图所示,PDD主要分为两个模块:
- 金字塔离散扩散模型:PDD扩展了标准的离散扩散模型(Discrete Diffusion Model)以此适应3D数据;
- 场景细分:提出了场景细分方法来进一步降低内存需求。并且展示了PDD在特定场景中的两个实际应用。
金字塔离散扩散模型
作者提出了金字塔离散扩散模型(PDD),它在多个尺度(或分辨率)上运行不同的扩散过程。给定3D场景数据,其中分别表示场景的维度,表示one-hot标签的大小。
文章定义了一个包含不同尺度对3D金字塔合集。即,其中较大的表示更大的场景尺度。形式上,设 表示 的维度,且 、、 对 都保持不变。
文章中注意到,这样的金字塔可以通过对 应用不同的下采样操作(例如池化函数)获得。
对于金字塔中的每个尺度,作者构建了一个由参数化的条件离散扩散模型,对于 的第 个模型,其定义为:
其中 和 与 的尺寸相同, 是一个尺度自适应函数(SAF),用于将 上采样到 的大小。例如,SAF可以是依赖于数据的三线性插值函数。此外,作者将第一个模型 作为原始的非条件模型。
在训练过程中,PDD分别在给定数据集中学习了不同尺度的 个去噪模型。由于 本质上是 的有损压缩版本,模型训练可以看作是学习恢复粗略场景的细节。在推理过程中,首先执行去噪模型 ,然后从 到 依次执行其余的PDD模型,通过采样:
其中 是 的去噪结果。
除了生成高质量的场景外,PDD还具有两个优点:
- 由于扩散模型相互独立,PDD中的模型可以并行训练,这使得训练过程中计算资源分配更加灵活。
- 由于其多阶段生成过程,PDD适合从中间过程开始恢复任意粗粒度的场景,从而扩展了该方法的多样性。
场景细分
为了解决生成大规模3D户外场景时的内存限制问题,作者提出了场景细分方法。文章中将一个3D场景 沿 轴分割为 个具有重叠部分的子场景,即 。
以四个子场景为例,设 表示一个子场景,其中 表示重叠比例,第 层金字塔中的共享扩散模型用于重建 的每个子场景。
随后,子场景通过投票融合算法合并为一个完整的场景,以确保3D场景的连续性。
在训练过程中,为了确保在生成子场景时能够感知整个场景的上下文信息,作者通过将其它子场景的重叠区域作为条件进行模型训练。在推理过程中,整个场景以自回归的方式生成。即:
其中 是在第 个场景之前生成的子场景的索引, 是 和 之间的二元掩码,用于表示 上的重叠区域(值为1)和非重叠区域(值为0)。场景细分模块可以减少模型参数,因为扩散模型可以在四个子场景之间共享。
实际应用
除了作为生成模型的主要功能之外,作者还为PDD引入了两个新的应用。首先,跨数据集迁移旨在将一个在源数据集上训练的模型适配到目标数据集。由于输入尺度的灵活性,PDD可以通过在新数据集中重新训练或微调较小尺度的模型,同时保留较大尺度的模型来实现这一目标。利用PDD的策略提高了在不同数据集之间迁移3D场景生成模型的效率。
其次,无限场景生成在自动驾驶和城市建模等需要大规模3D场景的领域中具有重要意义。PDD可以扩展其场景细分技术。通过使用先前生成场景的边缘作为条件,它可以迭代生成更大的场景,理论上可以没有规模限制。
Experiments评估标准
由于用于2D生成的指标(例如FID)无法直接应用于3D户外场景,文章中引入并实现了三种评估生成3D场景质量的指标。
首先,作者通过生成场景上的语义分割结果来评估模型在是否能够生成语义一致的场景方面的效果。具体来说,文章实现了基于Voxel的SparseUNet和基于Points的PointNet++架构来执行分割任务。并且通过计算mIoU和MAs作为评估指标。
另外,作者提出了F3D,一种基于FID在3D中进行改进的评估指标,这个指标使用了带有3D CNN架构的预训练自编码器。文章中计算了在特征域(feature domain)中生成场景和真实场景之间的Fréchet距离。
同时,作者还使用了MMD,一种用于量化生成场景和真实场景分布之间的差异的指标。类似于F3D方法,先通过同样的预训练自编码器提取特征,再计算生成的3D场景和真实场景之间的MMD。
主要结果

作者将文章中提出的方法与两个基线方法进行比较。表1中的结果表明,在无条件和有条件两组实验设置下,文章的方法在所有指标上都有不错的表现,并且在计算资源相当的情况下超越了现有的方法。尤其在分割任务的评估中,PDD的性能表现出了显著的优势,反应了其生成语义一致性场景的能力。
下面图3中展示了使用不同模型的可视化结果,PDD生成的场景在细节和随机性方面表现更佳。

此外,作者还对有条件的3D户外场景生成进行了比较,利用了PDD在输入尺度上的灵活性,分别在除第一阶段的模型上,以第一阶段()的尺度()逐步恢复到第二阶段()的尺度()和最后一个阶段()的尺度()上。表1和下面图5中的结果展示了PDD在条件生成对比中的出色表现。

未过拟合验证
作者利用结构相似性指标(SSIM)来验证生成的场景与训练集中最邻近场景的不同之处。具体来说,作者生成了1K个场景,并使用SSIM指标找到它们在训练集中的最近匹配场景,并且计算了这1K个场景的平均SSIM 的值(见表3)。
另外,作者还将相同的方法应用于验证集,以此建立一个参考的基线。表3中显示,生成的场景与基线结果相当,验证了PDD并未对训练集过拟合。为了进一步支撑这一理论,文章中还使用分布图(见图4)来验证生成场景与训练集的相似性。此外,作者在图中展示了处于不同分布段的三对场景,显示了SSIM分数较低的场景与其在训练集中最近匹配的差异更大。这些实验表明PDD有效捕捉了训练集的分布,而不是简单记忆了训练数据。

实际应用测试

跨数据集迁移
图8和图9展示了PDD在从CarlaSC迁移到SemanticKITTI数据集上执行无条件和有条件场景生成时的表现。通过在SemanticKITTI数据集上进行微调,PDD展现出更高的场景质量,如表6中的结果所示。

8_9
无限场景生成
图7可视化了使用PDD模型生成大规模无限场景的过程和结果。作者先使用小尺度模型快速生成一个粗略的无限3D场景(图7的底部层级)。然后利用更大尺度的模型逐步添加复杂细节(图7的中部和顶部层级),提升了场景的真实感。
该方法使得PDD可以生成高质量、连续的城市景观,而无需额外的输入,克服了传统数据集有限场景的局限性,并且生成的场景可以支持如3D场景分割等下游任务。(更完整的生成的无限场景可以在文章开头的Demo视频查看)

fig7
Conclusion
在这个工作中,文章提出了金字塔离散扩散模型(PDD),展示了一种渐进式的生成方法,从粗略到精细且无缝过渡到高质量的3D户外场景。
与其它方法相比,PDD能够在有限的资源约束下生成高质量的场景,并且不需要引入额外的数据源。文中的大量实验结果表明,PDD在无条件和有条件生成任务中均表现出色,证明其是创建真实且复杂场景的可靠的解决方案。
此外,PDD在将使用合成数据训练的模型适配到现实数据集方面也具有很大的潜力,为解决当前有限现实世界数据不足提供了一种具有前景的解决方案。
#FreqFusion
本文提出了一种名为FreqFusion的新方法,用于改善计算机视觉中的密集图像预测任务,如语义分割、目标检测、实例分割和全景分割。FreqFusion通过自适应低通滤波器、偏移生成器和自适应高通滤波器增强特征图的质量,显著提高了模型的性能。
大家是不是埋头准备 CVPR 2025 的投稿苦于涨点困难?快来看看热气腾腾的新鲜 TPAMI 2024 论文:
论文链接:
https://www.arxiv.org/abs/2408.12879
代码已开源:
https://github.com/Linwei-Chen/FreqFusion
在语义分割、目标检测、实例分割、全景分割上都涨点!
01 这篇论文做了什么?
现有的语义分割、目标检测等高层密集识别模型中,往往需要将低分辨高层特征与高分辨率低层特征融合,例如 FPN:

虽然简单,但这样粗糙的特征融合方式显然不够优秀,一方面特征本身对同一类目标的一致性不够高,会出现融合特征值在对象内部快速变化,导致类别内不一致性,另一方面简单的上采样会导致边界模糊,以及融合特征的边界模糊,缺乏精确的高频细节。

02 提出了什么方法?
FreqFusion 提出: 为了解决这些问题,作者提出了一种名为 Frequency-Aware Feature Fusion(FreqFusion)的方法。FreqFusion 包括:
自适应低通滤波器(ALPF)生成器: 预测空间变化的低通滤波器,以在上采样过程中减少对象内部的高频成分,降低类别内不一致性。
偏移生成器: 通过重采样,用更一致的特征替换大的不一致特征,使得同一类目标特征更稳定一致。
自适应高通滤波器(AHPF)生成器: 增强在下采样过程中丢失的高频细节边界信息。

用特征图进行分析对比,发现 FreqFusion 各个部分都可以显著提高特征的质量!

文中给了大量的分析和详细的说明,具体方法可以看原文~
03 涨点涨了多少?3.1 语义分割semantic segmentation
轻量化语义分割 SegNeXt,在 ADE20K 上 +2.4 mIoU(实际 checkpoint,+2.6mIoU)

强大的 Mask2Former 已经在 ADE20K 上取得很好的结果,FreqFusion 还能狠狠进一步讲 Swin-B 提升 +1.4 mIoU(实际给出的 checkpoint,+1.8 mIoU),即便是重型的 Swin-Large,也能提升高 +0.7 mIoU(实际给出的 checkpoint,+0.9 mIoU)。不得不说论文里汇报的结果还是保守了。

3.2 目标检测object detection
Faster RCNN +1.9 AP(实际公开的 checkpoint,+2.0 AP)

3.3 实例分割instance segmentation
Mask R-CNN,+1.7 box AP,+1.3 mask AP。

3.4 全景分割panoptic segmentation
PanopticFCN,+2.5 PQ。

04 如何使用?
简单来说,示例如下:
m = FreqFusion(hr_channels=64, lr_channels=64)
hr_feat = torch.rand(1, 64, 32, 32)
lr_feat = torch.rand(1, 64, 16, 16)
_, hr_feat, lr_feat = m(hr_feat=hr_feat, lr_feat=lr_feat)FreqFusion 的简洁代码可在此处获得。通过利用它们的频率特性, FreqFusion 能够增强低分辨率和高分辨率特征的质量 (分别称为 和 feat, 假设的大小 是的两倍 Ir_feat )。用法非常简单, 只要模型中存在 这种形式的不同分辨率特征相融合的情况就可以使用 FreqFusion 对模型进行提升涨点。
#Unveiling-Deep-Shadows
2万字长文超全详解!深度学习时代阴影检测、去除与生成在图像与视频中的全面综述
本文对阴影分析进行了深入的综述,涵盖了任务、监督级别和学习范式等各个方面。
论文链接:https://arxiv.org/pdf/2409.02108
Github链接:https://github.com/xw-hu/Unveiling-Deep-Shadows
亮点直击
- 深度学习时代阴影分析的全面综述。本文对阴影分析进行了深入的综述,涵盖了任务、监督级别和学习范式等各个方面。本文的分类旨在增强研究人员对阴影分析及其在深度学习领域应用中的关键特征的理解。
- 现有方法的公平比较。目前,现有方法之间的比较存在输入大小、评估指标、不同数据集和实现平台的不一致性。本文标准化了实验设置,并在同一平台上对各种方法进行了实验,以确保公平比较。此外,实验将在新修正的数据集上进行,其中的噪声标签或真实图像已被纠正。
- 模型大小、速度与性能关系的探索。与以往仅关注最终性能指标的阴影分析研究不同,本文还考察了模型大小和推理速度,强调了这些特征与性能之间的复杂相互作用。
- 跨数据集泛化研究。认识到阴影数据集中的固有偏差,本文对现有数据集进行了跨数据集泛化研究,以评估深度模型在不同数据集上的泛化能力,为这些模型的鲁棒性提供了宝贵的见解。
- 开放问题和未来方向的概述,涉及AIGC和大型模型。本文探讨了阴影分析中的开放问题,重点关注图像和视频感知、编辑以及对AIGC和大型视觉/语言模型的影响。本文的见解建议了未来的研究方向,为阴影分析及其应用的进展提供了路线图。
- 公开可用的结果、训练模型和评估指标。本文提供了在公平比较设置下的结果、训练模型和评估指标,以及新的数据集,以促进未来的研究和该领域的进步。结合这些贡献,本文提供了全面的综述,使其与早期的评审论文有所区别。
阴影是在光线遇到障碍物时形成的,导致照明区域减弱。在计算机视觉中,阴影检测、去除和生成对于增强场景理解、改善图像质量、确保视频编辑中的视觉一致性以及提升虚拟环境至关重要。本文对过去十年中深度学习领域内图像和视频的阴影检测、去除和生成进行了全面的综述,涵盖了任务、深度模型、数据集和评估指标。本文的主要贡献包括对阴影分析的全面综述、实验比较的标准化、模型大小、速度与性能之间关系的探索、跨数据集的泛化研究、未解决问题和未来方向的识别,以及提供公开资源以支持进一步研究。
阴影检测
阴影检测预测二进制 mask,指示输入图像或视频中的阴影区域。定位阴影使得阴影编辑成为可能,并促进阴影区域分析,这对于对象检测和跟踪等高级计算机视觉任务至关重要。本小节提供了针对图像和视频的阴影检测深度模型的全面概述。此外,它还总结了用于评估阴影检测方法的常用数据集和指标。为了评估不同模型在各个方面的有效性,本文进行了实验并呈现了比较结果。
用于图像阴影检测的深度模型
下表1展示了不同方法的基本属性,为理解深度学习领域中图像阴影检测的全貌提供了便利的参考。最初,早期的深度学习方法使用深度卷积神经网络根据输入图像预测阴影特征,包括阴影边界和局部阴影块。随后,研究重点转向专门设计的端到端深度神经网络,这些网络能够直接从阴影图像生成阴影 mask。另一种方法是采用多任务学习,其中模型被训练以同时执行阴影检测和阴影去除。之后,提出了基于半监督、自监督和大型视觉模型的方法,以进一步提高在各种场景下的性能。在接下来的小节中,本文将详细描述每个类别中的方法。
组件学习
早期的方法主要采用卷积神经网络(CNN)来生成阴影特征,然后使用统计建模方法(例如,条件随机场(CRF))来获得最终的阴影 mask。
- CNN-CRF 采用多个CNN在超像素级别和物体边界上学习特征,然后使用CRF模型生成平滑的阴影轮廓。
- SCNN-LinearOpt 使用CNN捕捉阴影边缘的局部结构及相关特征,然后制定最小二乘优化来预测阴影mask。
- Stacked-CNN 使用全卷积神经网络(FCN)输出图像级阴影先验图,随后使用补丁CNN生成局部阴影mask。然后,使用加权平均融合多个预测结果。
- Patched-CNN 首先采用支持向量机与统计特征来获取阴影先验图,然后使用CNN预测补丁的阴影概率图。
使用深度卷积神经网络学习阴影特征仅在早期方法中采用。以下类别中的深度模型均为端到端训练。
单任务学习
随着深度神经网络的发展,方法采用端到端的深度模型进行阴影检测,通过直接从输入的阴影图像预测输出的阴影 mask。
- scGAN 是一种条件生成对抗网络,具有可调的敏感性参数,用于调节预测阴影 mask 中阴影像素的数量。
- DSC 构建了一个方向感知空间上下文(DSC)模块,以方向感知的方式分析图像上下文。该模块在卷积神经网络(CNN)中使用,生成多尺度阴影 mask ,并将其合并为最终的阴影 mask 。
- DC-DSPF 堆叠多个并行融合分支以构建网络,该网络以深度监督的方式进行训练,然后使用密集级联学习方案对预测结果进行递归精炼。
- CPNet 在 U-Net中添加了残差连接来识别阴影区域。
- A+D Net 使用一个衰减器(A-Net)生成具有衰减阴影的真实图像,作为额外的困难训练样本,这些样本与原始训练数据一起用于训练检测器(D-Net)以预测阴影 mask 。值得注意的是,这是一个快速阴影检测器,能够实现实时性能。
- BDRAR 引入了递归注意残差模块,以结合来自相邻 CNN 层的特征,并学习一个注意力图以递归选择和精炼残差上下文特征。此外,它开发了一个双向特征金字塔网络,以聚合来自不同 CNN 层的阴影特征。
- DSDNet 设计了分心感知阴影(DS)模块,通过明确预测假阳性和假阴性来学习分心感知和区分特征。值得注意的是,预测的假阳性和假阴性来自其基础模型和其他阴影检测器。
- CPAdv-Net 在 U-Net 的编码器层和解码器层之间设计了一个跳跃连接中的映射方案。此外,它引入了两个对抗样本生成器,从原始图像生成用于训练的数据。
- DSSDNet 采用编码器-解码器残差结构和深度监督渐进融合模块,以预测航空图像上的阴影 mask 。
- FSDNet 是一个快速阴影检测网络,采用 DSC 模块来聚合全局特征,并构建一个细节增强模块,以在低级特征图中提取阴影细节。它使用 MobileNet V2 作为骨干网络,以实现实时性能。
- ECA 采用多种并行卷积,使用不同的卷积核来增强在适当尺度下的有效物体上下文。
- RCMPNet 提出了相对置信度图回归的方法,利用一个预测网络来评估阴影检测方法的可靠性,并结合基于注意力的长短期记忆(LSTM)子模块以增强置信度图的预测。
- SDCM 采用两个并行分支,分别生成阴影和非阴影 mask ,利用它们的互补特性。在训练过程中,通过使用负激活、身份重建损失和区分性损失来提升阴影检测结果的准确性。
- TransShadow 使用多级特征感知模块,利用 Transformer 来区分阴影和非阴影区域,并结合渐进上采样和跳跃连接以增强特征提取效果。
多任务学习
一些方法采用端到端的深度神经网络,不仅执行 mask 预测任务,还执行其他任务,例如预测无阴影图像以进行阴影去除。这些多任务方法受益于相互之间的改进或对阴影图像的更好理解。
- ST-CGAN 使用两个顺序的条件 GAN,其中第一个网络预测阴影 mask ,第二个网络通过将阴影图像和阴影 mask 作为输入来预测无阴影图像。
- ARGAN 开发了注意力递归生成对抗网络,用于阴影检测和去除。生成器生成阴影注意力图,并通过多个逐步的粗到细的步骤恢复无阴影图像。此外,ARGAN 可以使用未标记的数据以半监督的方式进行训练,利用 GAN 中的对抗损失。
- R2D 通过利用在阴影去除过程中学习到的阴影特征来增强阴影检测性能。所提出的 FCSD-Net 架构集成到 R2D 框架中,重点通过特别设计的检测器模块提取细致的上下文特征。它使用假阳性和假阴性以及 DSDNet中的 DS 模块。
- LRA 和 LDRA 在堆叠范式中优化残差,以同时解决阴影检测和去除的挑战,指导优先重建阴影区域,并对最终的混合/颜色校正做出贡献,同时减少开销并提高各种主干架构的准确性。它生成一个配对数据集,其中包含阴影图像、无阴影图像和阴影 mask ,以进行预训练。
- SDDNet 引入了样式引导的双层解耦网络用于阴影检测,利用特征分离和重组模块通过差异化监督来分离阴影和背景层。同步联合训练确保了分离的可靠性,而阴影样式过滤模块引入了样式约束(由 Gram 矩阵 表示),增强了特征解耦的质量。
- Sun 等人 提出了自适应照明映射 (AIM) 模块,该模块将原始图像转换为具有不同强度的 sRGB 图像,并配合利用多尺度对比信息的阴影检测模块。反馈机制指导 AIM 以阴影感知的方式渲染具有不同照明的 sRGB 图像。
半监督学习
训练深度模型进行阴影检测需要标记的阴影 mask,因此有限的训练数据量会影响深度模型在复杂情况下的性能。因此,提出了半监督阴影检测器,以便在标记和未标记的阴影图像上训练模型。
- ARGAN+SS 如前文所述。
- MTMT-Net 是一种成功的半监督阴影检测方法,它基于教师-学生(mean teacher)架构构建了一个多任务平均教师网络进行半监督学习。教师和学生网络以多任务学习的方式检测阴影区域、阴影边缘和阴影数量。
- SDTR 和 SDTR+ 分别表示半监督和弱监督阴影检测器。新阴影图像的处理过程涉及通过可靠样本选择方案识别不可靠样本。随后,可以选择重新训练可靠样本、重新推断不可靠样本以获得精确的伪 mask,或采用灵活的注释(例如,框、点、涂鸦),并获得见解以提高深度模型的泛化能力。利用 MiT-B2 主干,SDTR 和 SDTR+ 都能实时运行。
自我监督学习
自监督学习利用数据本身作为监督信号来学习深度特征。这个理念可以在现有的训练数据集上实现,也可以使用额外的数据。
- FDRNet 设计了一种特征分解和重加权方案,以减轻深度阴影检测器对强度线索的偏见。它首先采用两个自监督任务,通过使用调整亮度的图像作为监督来学习强度变化和强度不变的特征。然后,它使用累积学习对特征进行重加权。
- SILT 构建了一个阴影感知迭代标签调整框架,具有阴影感知的数据增强、用于 mask 预测的全局-局部融合、阴影感知的过滤,以及整合零标记的无阴影图像以提高非阴影区域的识别能力。它收集了一些互联网图像(暗物体和无阴影图像),进一步帮助训练网络以区分阴影和暗物体。该框架使用了多种基础网络作为主干,包括 U-Net、ResNeXt101、EfficientNet 和 PVT v2。
大型视觉模型
现代大型视觉模型在一般视觉任务中表现出色。例如,“任意分割”模型(SAM)在多种物体类别的图像分割中展现了令人印象深刻的零样本性能。然而,在复杂背景和复杂场景中处理阴影仍然很困难。为了提高SAM在阴影检测方面的性能,许多方法旨在仅微调新添加的或部分结构。
- SAM-Adapter 将SAM作为其骨干网络,通过整合定制信息来增强性能。这涉及在SAM编码器的每一层中集成两个多层感知机(MLP)作为适配器,同时微调适配器和SAM mask 解码器。
- ShadowSAM 在多个SAM编码器层中集成两个MLP和一个GELU激活函数作为提示器。它使用非深度学习方法生成伪 mask ,并通过照明和纹理引导的更新策略来改善这些伪 mask。该方法包括用于增量课程学习的 mask 多样性指标。ShadowSAM支持无监督(使用伪 mask)和监督模式的训练。
- AdapterShadow 将可训练的适配器插入到SAM的冻结图像编码器中进行微调。此外,引入了一种网格采样方法,以自动从预测的粗略阴影 mask 生成密集点提示。请注意,SAM的骨干网络是ViT-H,辅助网络的骨干是EfficientNet-B1。
用于视频阴影检测的深度模型
视频阴影检测处理动态场景,并在视频帧中生成一致的阴影 mask 。学习导向的数据集和视频阴影检测方法由 TVSD-Net 制定。下表 2 总结了所调查论文的基本属性。
- TVSD-Net 作为基于深度学习的视频阴影检测的先驱,TVSD-Net 采用三重并行网络协同工作,以在视频内部和视频间层面获得区分性表示。该网络包括一个双门协同注意模块,用于约束同一视频中相邻帧的特征,并引入辅助相似性损失,以捕捉不同视频之间的语义信息。
- Hu et al. 该方法采用基于光流的扭曲模块对帧之间的特征进行对齐和组合,应用于多个深度网络层,以提取相邻帧的信息,涵盖局部细节和高级语义信息。
- STICT 该方法使用均值教师学习,结合标记图像和未标记视频帧,实现实时阴影检测。它引入时空插值一致性训练,以提高泛化能力和时间一致性。
- SC-Cor 该方法采用对应学习以提高细粒度的像素级相似性,采用像素到集合的方式,精细化帧间阴影区域内的像素对齐。它增强了时间一致性,并无缝地作为现有阴影检测器中的即插即用模块,且没有计算成本。
- STF-Net 该方法使用 Res2Net50 作为骨干网络,在实时视频中高效检测阴影,引入一个简单而有效的时空融合模块,以利用时间和空间信息。
- SCOTCH 和 SODA 这两个框架形成了一个视频阴影检测体系。SCOTCH 使用监督对比损失来增强阴影特征的区分能力,而 SODA 应用时空聚合机制来管理阴影变形。这种组合改善了特征学习和时空动态。
- ShadowSAM 该方法对 SAM进行微调,以使用边界框作为提示检测第一帧中的阴影,并采用以 MobileNetV2 为骨干的长短期网络在视频中传播 mask,利用长短期注意力提升性能。
- RSM-Net 该方法引入了参考视频阴影检测任务,提出了一种参考阴影跟踪记忆网络,利用双轨协同记忆和混合先验阴影注意力,根据描述性自然语言提示在视频中分割特定阴影。
- TBGDiff 这是第一个用于视频阴影检测的扩散模型,通过提取时间引导和边界信息,使用双尺度聚合来处理时间信号,并通过时空编码embedding进行边界上下文提取和时间线时间引导。
- Duan et al. 该方法使用两阶段训练范式,首先使用预训练的图像域模型,并通过时间适应模块和空间适应模块将其调整为视频域,以实现时间一致性,并整合高分辨率局部补丁与全局上下文特征。这两个模块采用类似 ControlNet的结构。
阴影检测数据集
接下来,本文专门讨论用于模型训练和评估的广泛使用的数据集,省略其他用于额外半监督/弱监督训练的数据。
用于阴影检测的图像数据集
早期的数据集,例如UCF和UIUC,是为了使用手工特征训练传统机器学习方法而准备的。UCF包含245张图像,其中117张是在多样的户外环境中拍摄的,包括校园和市区区域。剩余的图像来自现有的数据集。每张图像中的阴影都经过精细的像素级手动标注,并由两个人进行了验证。UIUC有108张阴影图像,带有标记的阴影 mask 和无阴影图像,这是首次能够在几十张图像上进行阴影去除的定量评估。
后来,收集了包含数千张阴影图像的数据集,以训练深度学习模型。
- SBU 和 SBU-Refine: SBU是一个大规模的阴影数据集,包含4,087张训练图像和638张测试图像,使用了一种懒惰标注方法,用户最初粗略地标记阴影和非阴影区域,然后通过优化算法对这些标签进行细化。SBU-Refine手动重新标记测试集,并通过算法细化训练集中的噪声标签。
- ISTD: 提供阴影图像、无阴影图像和阴影 mask,适用于阴影检测和去除任务。包含1,330张训练图像和540张测试图像,以及135个不同的背景场景。
- CUHK-Shadow: 是一个大型数据集,包含10,500张阴影图像,分为7,350张用于训练,1,050张用于验证,2,100张用于测试。它包括五个类别:ShadowADE、ShadowKITTI、Shadow-MAP、ShadowUSR和Shadow-WEB。
- SynShadow: 是一个合成数据集,包含10,000组阴影/无阴影/遮罩图像三元组。利用阴影照明模型和3D模型生成,适用于预训练或零样本学习。
- SARA: 包含7,019张原始图像及其阴影 mask ,分为6,143张用于训练和876张用于测试,涵盖17个类别和11个背景。
用于阴影检测的视频数据集
- ViSha: 包含120个多样化视频,提供像素级阴影标注的二值 mask 。总计11,685帧,390秒的视频,标准化为30帧每秒,训练和测试集按5:7比例划分。
- RVSD: 从ViSha中选择86个视频,重新标注为单独的阴影实例,并添加自然语言描述提示,通过验证确保质量。
- CVSD: 复杂视频阴影数据集,包含196个视频片段,涉及149个类别,具有多样的阴影模式。包括278,504个标注的阴影区域和19,757帧的阴影 mask ,适用于复杂场景。
评估指标图像阴影检测的评估指标
- BER(平衡错误率)是一种常用的评估阴影检测性能的指标。在这种评估中,阴影和非阴影区域的贡献相等,无论它们的相对面积如何。BER的计算公式为:

其中, 、、 和 分别表示真正例、真负例、假正例和假负例。为了计算这些值,首先将预测的阴影 mask 量化为二值 mask。当像素值超过0.5时设为1,否则设为0。然后将此二值 mask 与真实 mask 进行比较。BER值越低,检测结果越有效。有时还会分别提供阴影和非阴影区域的BER值。
- -measure 被提出用于评估阴影 mask 中的非二值预测值。该指标以加权方式计算精准率和召回率, 较高的 值表示更优的结果。
视频阴影检测的评估指标
视频阴影检测中使用深度学习的首篇论文采用平均绝对误差(MAE)、F-测量()、交并比(IoU)和平衡错误率(BER)来评估性能。然而,评估仅限于单个图像(帧级别),未能捕捉时间稳定性。Ding等人引入了时间稳定性指标。
时间稳定性(TS) 计算两个相邻帧的真实标签之间的光流, 记为 和 。虽然ARFlow最初用于光流计算, 但本文采用了RAFT。这是因为阴影的运动在RGB帧中难以捕捉。定义 为 和 之间的光流。然后, 通过光流 对 进行变形得到的重建结果记为 。 是视频帧的数量。接下来, 视频阴影检测的时间稳定性基于相邻帧之间的流变形交并比(IoU)进行测量:

实验结果
在已有方法的原始论文中报告的比较结果在输入尺寸、评估指标、数据集和实现平台上存在不一致。因此,本文标准化实验设置,并在相同平台上对各种方法进行实验,以确保公平比较。此外,本文进一步在多个方面比较这些方法,包括模型的大小和速度,并进行跨数据集评估,以评价其泛化能力。
图像阴影检测
整体性能基准测试结果。本文使用 SBU-Refine和 CUHK-Shadow来评估各种方法的性能。SBU-Refine 通过纠正错误标记的 mask 提高了评估准确性,从而减少了比较方法中的过拟合问题。CUHK-Shadow 是最大的真实数据集,提供了多样化的场景以进行全面测试。比较的方法列在下表 3 中,本文排除了那些没有代码可用的方法。除了 DSC(在 PyTorch 中使用 ResNeXt101 主干实现)外,本文使用原始源代码重新训练了这些方法。所有比较方法都省略了后处理,例如 CRF。先前的方法采用了不同的输入尺寸。在本文中,本文将输入尺寸设置为 和 ,以在两种分辨率下呈现结果。本文采用平衡错误率(BER)作为评估指标,使用 Python 代码计算。报告了阴影区域(BERS)和非阴影区域(BERNS)的 BER。为公平比较,评估时结果被调整到与真实值相同的分辨率。
上表 3 和下图 1 展示了每种方法的准确性、运行时间和参数。本文可以观察到:
- 一些相对较旧的方法比最近的方法表现更好,表明在原始 SBU 数据集上存在过拟合问题;
- FSDNet 是唯一一个开源(提供训练和测试代码)的实时阴影检测器,具有较少的参数和快速的推理速度;
- DSDNet 在其训练过程中结合了 DSC和 BDRAR的结果,并在性能上与最近的方法 SDDNet相当;
- 较大的输入尺寸通常会带来性能提升,但也需要更多时间;
- CUHK-Shadow 比 SBU-Refine 更具挑战性。FDRNet在检测 CUHK-Shadow 中的阴影时对输入分辨率特别敏感,其中包含复杂的阴影或更细的细节,这些在更高分辨率的输入()下更有利。
跨数据集泛化评估。 为了评估阴影检测方法的泛化能力,本文通过使用在 SBU-Refine 训练集上训练的模型,检测 SRD 测试集上的阴影来进行跨数据集评估。由于 SRD 在背景特征的复杂性上与 SBU 相似,因此被使用。请注意,这是首次在大规模数据集上评估泛化能力。
上表 3 中最右边的三列显示了结果,其中性能显著下降,尤其是在阴影区域。这突显了跨数据集评估对于稳健阴影检测的重要性。阴影区域的性能下降表明这些方法在应对 SRD 中存在的不同光照条件和复杂背景纹理时存在困难。未来的工作应着重于提高阴影检测模型的稳健性,以更好地在不同数据集间泛化。
总结 实验结果表明,如何开发一个高效且稳健的模型,以在复杂场景下实现高精度的图像阴影检测,仍然是一个具有挑战性的问题。
视频阴影检测
ViSha 数据集用于评估视频阴影检测方法,输入尺寸为 512×512,参考 [88], [92]。由于 SAM 预训练模型的位置信息embedding,ShadowSAM 使用 1024×1024 的输入尺寸。SC-Cor使用 DSDNet作为基础网络。STICT在训练中使用了额外的 SBU 数据集图像。除了常用的图像级评估指标 BER 和 IoU,本文还采用了通常被忽略的时间稳定性(TS)。结果被调整为 512×512 用于 TS 的光流计算,并调整为真实分辨率用于其他指标。
下表 4 显示了结果,揭示了视频阴影检测方法的显著优势和权衡。SCOTCH 和 SODA 展现了最佳的整体性能,具有最低的 BER 和最高的 AVG,而 ShadowSAM 虽然模型较大,但达到了最高的 IoU。STICT 因其最快的推理速度而突出,尽管 IoU 较低,但非常适合实时应用。SC-Cor 和 TVSD-Net 展示了平衡的性能,BER、IoU 和 TS 得分适中。
总结 实验结果表明,在视频阴影检测中,如何在帧级准确性、时间稳定性、模型复杂性和推理速度之间实现最佳平衡仍然是一个具有挑战性的问题。
实例阴影检测
这一部分介绍了另一个任务,即实例阴影检测,其目标是同时找到阴影及其关联的物体。了解物体与其阴影之间的关系对许多图像/视频编辑应用大有裨益,因为这样可以轻松地同时操作物体及其关联的阴影。这个任务最初在图像层面由[108]提出,随后在视频中由[111]扩展。下表5总结了所调查方法的基本特性。
用于图像实例阴影检测的深度模型
实例阴影检测旨在检测阴影实例及其投射每个阴影的相关物体实例。
- LISA:首先生成可能包含阴影/物体实例及其关联的区域建议。对于每个建议,它预测单个阴影/物体实例的边界框和 mask ,生成阴影-物体关联(对)的边界框,并估计每个阴影-物体关联的光照方向。最后通过将阴影和物体实例与其对应的阴影-物体关联配对来完成过程。
- SSIS:引入了一种单阶段全卷积网络架构,包含一个双向关系学习模块,用于直接端到端学习阴影和物体实例之间的关系。该模块深入研究阴影-物体关联对,学习从每个阴影实例中心到其关联物体实例中心的偏移向量,反之亦然。
- SSISv2:通过新技术扩展了SSIS,包括可变形的MaskIoU头、阴影感知的复制粘贴数据增强策略和边界损失,旨在增强阴影/物体实例和阴影-物体关联的分割效果。
用于视频实例阴影检测的深度模型
视频实例阴影检测不仅涉及在视频帧中识别阴影及其关联的物体,还需要在整个视频序列中持续跟踪每个阴影、物体及其关联,即使在关联中阴影或物体部分暂时消失的情况下也要进行处理。
- ViShadow 是一种半监督框架,训练于标注的图像数据和未标注的视频序列上。初始训练通过中心对比学习在不同图像中配对阴影和物体。随后,利用未标注视频和相关的循环一致性损失来增强跟踪。此外,它通过检索机制解决了物体或阴影实例暂时消失的挑战。
实例阴影检测数据集
- SOBA 是首个用于图像实例阴影检测的数据集,包含1,100张图像和4,293个标注的阴影-物体关联。最初,[108]收集了1,000张图像,[110]又增加了100张具有挑战性的阴影-物体对图像用于专门测试。训练集包括840张图像和2,999个对。阴影实例、物体实例及其关联的标签使用Affinity Photo App和Apple Pencil进行了精细标注。
- SOBA-VID 是为视频实例阴影检测设计的数据集,包含292个视频,共7,045帧。数据集分为232个视频(5,863帧)的训练集和60个视频(1,182帧)的测试集。值得注意的是,测试集为每个阴影和物体实例提供详细的逐帧标注,而训练集每四帧中标注一帧。
评估指标
- SOAP (阴影-物体平均精度)通过计算交并比(IoU)的平均精度(AP)来评估图像实例阴影检测性能。它扩展了真正例的标准,要求预测和真实阴影实例、物体实例以及阴影-物体关联的 IoU 阈值大于或等于 。评估时使用特定的 值 0.5(SOAP50)或 0.75(SOAP75),并在 从 0.5 到 0.95 以 0.05 为增量的范围内计算平均值(SOAP)。
- SOAP-VID 通过将 SOAP 中的 IoU 替换为时空 IoU 来评估视频实例阴影检测。
实验结果图像实例阴影检测评估
整体性能基准结果 使用SOAP作为数据集,SOBA作为评估指标。比较的方法列在下表6中。本文使用其原始代码重新训练这些方法,将输入图像的短边在训练期间调整为六个尺寸之一:640、672、704、736、768或800。在推理过程中,本文将短边调整为800,确保长边不超过1333。
上表6展示了每种方法的准确性、运行时间和参数数量,观察到:(i) SSISv2达到最佳性能,但速度最慢;(ii) 所有方法在处理复杂场景时性能有限;(iii) 复杂场景中的更多实例显著降低推理速度。
跨数据集泛化评估 为评估泛化能力,本文进行了跨数据集评估,将在SOBA训练集上训练的模型应用于SOBA-VID测试集的视频帧中检测图像实例阴影/物体。注意,没有进行时间一致性评估。下表7显示了结果,观察到:(i) 比较方法的趋势与在SOBA测试集上观察到的趋势一致;(ii) 性能没有显著下降,展示了实例阴影检测方法强大的泛化能力。
总结 实验结果表明,如何开发一个高效的模型以准确分割阴影和物体实例仍然是一个具有挑战性的问题。
视频实例阴影检测的评估 在此,本文展示ViShadow [111]在SOBA-VID测试集上的性能指标:SOAP-VID为39.6,关联AP为61.5,实例AP为50.9。20帧的总推理时间为93.63秒,处理速度约为0.21帧每秒,模型参数为66.26M。
阴影去除
阴影去除旨在通过恢复阴影下的颜色生成无阴影的图像或视频帧。除了普通场景,文档和面部阴影去除也是重要的特定应用。本小节全面概述了用于阴影去除的深度模型,并总结了评估阴影去除方法的常用数据集和指标。此外,为了评估各种方法的有效性,本文进行了实验并展示了比较结果。
用于图像阴影去除的深度模型
以下是下表 8 中关于图像阴影去除的论文综述。
按监督级别分类的方法:监督学习。 监督通常基于以下两种情况:
- 无阴影图像
- 无阴影图像和阴影 mask
(i)基于 CNN 的方法:
- CNN-CRF: 使用多个 CNN 学习检测阴影,并构建贝叶斯模型去除阴影。深度网络仅用于检测阴影。
- DeshadowNet: 一种端到端网络,包含三个子网络,从全局视角提取图像特征。
- SP+M-Net: 将阴影图像建模为无阴影图像、阴影参数和阴影哑光的组合,然后使用两个独立的深度网络预测阴影参数和阴影哑光。在测试中,使用预测的阴影 mask 作为额外输入。
- DSC: 引入方向感知空间上下文模块分析具有方向感的图像上下文。使用多个 DSC 模块的 CNN 生成残差,与输入结合生成无阴影图像。
- DHAN+DA: 提出分层聚合注意力模型,结合多重上下文和来自阴影 mask 的注意力损失,使用 Shadow Matting GAN 网络合成阴影图像。
- SP+M+I-Net: 扩展SP+M-Net,通过约束 SP-Net 和 M-Net 的搜索空间,添加半影重构损失帮助 M-Net 关注阴影半影区域,利用 I-Net 进行修复,并引入平滑损失以调节哑光层。可扩展用于基于补丁的弱监督阴影去除。
- Auto: 匹配阴影区域与非阴影区域的颜色生成过曝图像,通过阴影感知的 FusionNet 合并输入,生成自适应内核权重图。最后,边界感知的 RefineNet 减少阴影边界的半影效果。
- CANet: 采用两阶段上下文感知方法:首先采用上下文补丁匹配模块寻找潜在的阴影和非阴影补丁对,促进跨不同尺度的信息传递,并使用编码器-解码器进行细化和最终化。
- EMDNet: 提出基于模型驱动的网络进行阴影去除的迭代优化。每个阶段更新变换图和无阴影图像。
- BMNet: 双射映射网络,集成阴影去除和阴影生成共享参数。具有用于仿射变换的可逆块,并包括利用 U-Net 派生的阴影不变颜色进行颜色恢复的阴影不变颜色指导模块。
- G2C-DeshadowNet: 两阶段阴影去除框架,首先从灰度图像中去除阴影,然后利用修改的自注意力块优化全局图像信息进行上色。
- SG-ShadowNet: 两部分风格引导的阴影去除网络:基于 U-Net 的粗略去阴影网络进行初步阴影处理,风格引导的再去阴影网络精细化结果,采用空间区域感知原型标准化层,将非阴影区域风格渲染到阴影区域。
- MStructNet: 重建输入图像的结构信息以去除阴影,利用无阴影的结构先验进行图像级阴影消除,并结合多级结构洞察。
- DNSR: 基于 U-Net 的架构,具有动态卷积、曝光调整和蒸馏阶段以增强特征图。集成通道注意力和融合池以改善特征融合。
- PES: 使用金字塔输入处理各种阴影大小和形状,以 NAFNet为基础框架。通过三阶段训练过程,改变输入和裁剪大小、损失函数、批量大小和迭代次数,并通过模型汤精炼,在 NTIRE 2023 图像阴影去除挑战赛的 WSRD 中获得最高 PSNR。
- Inpaint4shadow: 通过在修复数据集上进行预训练来减少阴影残留,利用双编码器处理阴影和阴影 mask 图像,使用加权融合模块合并特征,并通过解码器生成无阴影图像。
- LRA&LDRA: 通过优化堆叠框架 中的残差来改进阴影检测和去除。它通过混合和颜色校正重建阴影区域。研究表明,在包含配对阴影图像、无阴影图像和阴影 mask 的大规模合成数据集上进行预训练显著提高了性能。
- SHARDS: 使用两个网络从高分辨率图像中去除阴影:LSRNet 从阴影图像及其 mask 生成低分辨率的无阴影图像,而 DRNet 使用原始高分辨率阴影图像细化细节。由于 LSRNet 在较低分辨率下处理主要的阴影去除工作,这一设计使 DRNet 保持轻量。
- PRNet: 将通过浅层六块 ResNet 的阴影特征提取与通过再集成模块和基于 ConvGRU 的更新 [155] 的渐进阴影去除相结合。再集成模块迭代增强输出,更新模块生成用于预测的阴影衰减特征。
(ii) 基于 GAN 的方法采用生成器预测无阴影图像,判别器进行判断。
- ST-CGAN: 使用一个条件 GAN 检测阴影,并利用另一个条件 GAN 去除阴影。
- AngularGAN: 使用 GAN 端到端预测无阴影图像。该网络在合成配对数据上进行训练。
- ARGAN: 首先开发一个阴影注意力检测器生成注意力图以标记阴影,然后递归恢复较轻或无阴影的图像。注意,它可以使用未标记数据和 GAN 中的对抗损失以半监督方式进行训练。
- RIS-GAN: 在编码器-解码器结构中采用四个生成器和三个判别器来生成负残差图像、中间阴影去除图像、反向光照图和精细化阴影去除图像。
- TBRNet: 是一个具有多任务协作的三分支网络。它由三个专门分支组成:阴影图像重建以保留输入图像细节;阴影遮罩估计以识别阴影位置并调整光照;阴影去除以对齐阴影区域与非阴影区域的光照,从而生成无阴影图像。
(iii) 基于Transformer的方法通过自注意力机制更好地捕获全局上下文信息。
- CRFormer: 是一个混合CNN-Transformer框架,使用不对称的CNN从阴影和非阴影区域提取特征,采用区域感知的交叉注意力机制聚合阴影区域特征,并使用U形网络优化结果。
- CNSNet: 采用双重方法进行阴影去除,集成了面向阴影的自适应归一化以保持阴影和非阴影区域之间的统计一致性,并使用Transformer进行阴影感知聚合以连接阴影和非阴影区域的像素。
- ShadowFormer: 使用通道注意力编码器-解码器框架和阴影交互注意力机制,利用上下文信息分析阴影和非阴影块之间的相关性。
- SpA-Former: 由Transformer层、系列联合傅里叶变换残差块和双轮联合空间注意力组成。双轮联合空间注意力与DSC相同,但使用阴影 mask 进行训练。
- TSRFormer: 是一个两阶段架构,采用不同的Transformer模型进行全局阴影去除和内容细化,有助于抑制残留阴影并优化内容信息。SpA-Former和ShadowFormer是其骨干。
- ShadowMaskFormer: 将Transformer模型与补丁embedding中的阴影 mask 集成,采用0/1和-1/+1二值化以增强阴影区域的像素。
- ShadowRefiner: 使用基于ConvNeXt的U-Net提取空间和频率表示,将受阴影影响的图像映射到无阴影图像。然后,它使用快速傅里叶注意力Transformer确保颜色和结构一致性。
- HomoFormer: 是一个基于局部窗口的Transformer用于阴影去除,均匀化阴影退化。它使用随机打乱操作及其逆操作来重新排列像素,使局部自注意力层能够有效处理阴影并消除归纳偏差。新的深度卷积前馈网络增强了位置建模并利用了图像结构。
(iv) 基于扩散的方法有助于生成更具视觉吸引力的结果。
- ShadowDiffusion(J): 使用分类器驱动的注意力进行阴影检测,使用DINO-ViT特征的结构保留损失进行重建,并使用色度一致性损失确保无阴影区域的颜色均匀。
- ShadowDiffusion(G): 通过退化和扩散生成先验逐步优化输出,并增强阴影 mask 估计的准确性,作为扩散生成器的辅助方面。
- DeS3: 使用自适应注意力和ViT相似性机制去除硬阴影、软阴影和自阴影。它采用DDIM作为生成模型,并利用自适应分类器驱动的注意力强调阴影区域,DINO-ViT损失作为推理过程中的停止准则。
- Recasting: 包含两个阶段:阴影感知分解网络使用自监督正则化分离反射率和照明,双边校正网络使用局部照明校正模块调整阴影区域的照明。然后,使用照明引导的纹理恢复模块逐步恢复退化的纹理细节。
- LFG-Diffusion: 训练一个扩散网络在无阴影图像上,以在潜在特征空间中学习无阴影先验。然后使用这些预训练的权重进行高效的阴影去除,最小化编码的无阴影图像和带有 mask 的阴影图像之间的不变损失,同时增强潜在噪声变量与扩散网络之间的交互。
- Diff-Shadow: 是一个全球引导的扩散模型,具有并行的 U-Nets:一个用于局部噪声估计的分支和一个用于无阴影图像恢复的全局分支。它使用重新加权的交叉注意力和全球引导采样来探索非阴影区域的全局上下文,并确定补丁噪声的融合权重,保持光照一致性。
无监督学习这类方法在训练深度网络时不使用成对的阴影和无阴影图像,因为这些图像难以获取。
- Mask-ShadowGAN: 是第一个无监督阴影去除方法,它自动学习从输入阴影图像中生成阴影 mask ,并利用 mask 通过重新制定的循环一致性约束来指导阴影生成。该框架同时学习生成阴影 mask 和去除阴影。
- PUL: 通过四个附加损失改进了 Mask-ShadowGAN:mask 损失(采样和生成 mask 之间的 差异)、颜色损失(平滑图像之间的均方误差)、内容损失(来自 VGG-16 的特征损失)和风格损失(VGG-16 特征的 Gram 矩阵)。
- DC-ShadowNet: 使用阴影/无阴影域分类器处理阴影区域。它通过熵最小化在对数色度空间中训练一个基于物理的无阴影色度损失,以及使用预训练的 VGG-16 的阴影鲁棒感知特征损失、边界平滑损失和一些类似于 Mask-ShadowGAN 的附加损失。
- LG-ShadowNet: 使用一个亮度引导网络改进了 Mask-ShadowGAN。在 Lab 颜色空间中,CNN 首先调整 L 通道中的亮度,然后另一个 CNN 使用这些特征在所有 Lab 通道中去除阴影。多层连接在双流架构中融合亮度和阴影去除特征。
- SG-GAN+DBRM: 包含两个网络。(i) SG-GAN 基于 Mask-ShadowGAN,产生粗略的阴影去除结果和合成的成对数据,由使用 CLIP的多模态语义提示器引导文本语义。(ii) DBRM 是一个扩散模型,精细化粗略结果,该模型在真实无阴影图像和阴影去除图像上训练,去除前的阴影由 Mask-ShadowGAN 合成。
弱监督学习这类方法仅使用阴影图像和阴影 mask 训练深度网络。阴影 mask 可以通过阴影检测方法预测。
- Param+M+D-Net: 使用阴影分割 mask 作为监督在阴影图像上训练。它将图像划分为补丁,学习从阴影边界补丁到非阴影补丁的映射,并应用基于物理阴影形成模型的约束。
- G2R-ShadowNet: 包含三个子网络:生成、去除和细化阴影。阴影生成网络在非阴影区域创建伪阴影,与非阴影区域形成训练对用于阴影去除网络。细化阶段确保颜色和光照一致性。阴影 mask 引导整个过程。
- BCDiff: 是一个边界感知条件扩散模型。通过迭代维护反射率来增强无条件扩散模型,支持阴影不变的内在分解模型,以保留阴影区域内的结构。它还应用光照一致性约束以实现均匀照明。基础网络使用 Uformer。
单图像自监督学习此任务通过在测试期间对图像本身进行训练来学习去除阴影,消除了对训练数据的需求。然而,阴影 mask 是必需的。
- Self-ShadowGAN: 采用阴影重光网络作为阴影去除的生成器,由两个判别器支持。重光网络使用轻量级 MLPs 根据物理模型预测像素特定的阴影重光系数,参数由快速卷积网络确定。它还包括一个基于直方图的判别器,使用无阴影区域的直方图作为参考来恢复阴影区域的光照,以及一个基于补丁的判别器来提高去阴影区域的纹理质量。
文档阴影去除
去除文档中的阴影可以提高数字副本的视觉质量和可读性。一般的阴影去除方法在处理文档时面临挑战,因为需要大量配对数据集,并且缺乏对特定文档图像属性的考虑。下表9总结了用于此任务的深度模型。
- BEDSR-Net: 是第一个专为文档图像阴影去除设计的深度网络。它由两个子网络组成:
- BE-Net 估计全局背景颜色并生成注意力图。这些结果与输入阴影图像一起被 SR-Net 用来生成无阴影图像。
- BGShadowNet: 利用来自颜色感知背景提取网络的背景进行阴影去除,采用两阶段过程。
- 第一阶段:融合背景和图像特征以生成逼真的初始结果。
- 第二阶段:使用基于背景的注意力模块校正光照和颜色不一致,并通过细节增强模块(受图像直方图均衡化启发)增强低级细节。
- FSENet: 旨在通过首先将图像分割为低频和高频分量来实现高分辨率文档阴影去除。
- 低频部分 使用 Transformer 进行光照调整。
- 高频部分 使用级联聚合和膨胀卷积来增强像素并恢复纹理。
面部阴影去除
面部阴影去除涉及消除外部阴影、柔化面部阴影以及平衡光照。上表9总结了深度模型。这一主题与面部重光照相关,因为准确的阴影处理对实现照片级真实效果至关重要。此外,去除阴影还能提高面部特征点检测的鲁棒性。
- Zhang 等人提出了第一个针对面部图像阴影去除的深度学习方法。该方法使用两个独立的深度模型:一个用于去除外部物体投射的外部阴影,另一个用于柔化面部阴影。这两个模型都基于修改后的GridNet。
- He 等人提出了第一个无监督的面部阴影去除方法,将其框定为图像分解任务。该方法处理单个有阴影的肖像,生成无阴影图像、全阴影图像和阴影 mask ,使用预训练的面部生成器如StyleGAN2和面部分割 mask 。
- GS+C通过将阴影去除分为灰度处理和上色来实现。阴影在灰度中被识别和去除,然后通过修补恢复颜色。为了在视频帧中保持一致性,它包含一个时间共享模块,解决姿势和表情变化。
- Lyu 等人提出了一个两阶段模型,用于去除眼镜及其阴影。第一阶段使用跨域分割模块预测 mask ,第二阶段使用这些 mask 指导去阴影和去眼镜网络。该模型在合成数据上训练,并使用域适应网络处理真实图像。
- GraphFFNet是一个基于图的特征融合网络,用于去除面部图像中的阴影。它使用多尺度编码器提取局部特征,图像翻转器利用面部对称性生成粗略的无阴影图像,并使用基于图的卷积编码器识别全局关系。特征调制模块结合这些全局和局部特征,融合解码器生成无阴影图像。
用于视频阴影去除的深度模型
PSTNet 是一种用于视频阴影去除的方法,结合了物理、空间和时间特征,并通过无阴影图像和 mask 进行监督。它使用物理分支进行自适应曝光和监督注意力,空间和时间分支则用于提高分辨率和连贯性。特征融合模块用于优化输出,S2R策略使得在不重新训练的情况下,将合成数据上训练的模型适应于真实世界的应用。
GS+C 是一种用于视频中面部阴影去除的方法。
阴影去除数据集通用图像阴影去除数据集
- SRD: 是第一个大规模的阴影去除数据集,包含 3,088 对阴影和无阴影的图像。该数据集的多样性涵盖四个维度:光照(硬阴影和软阴影)、广泛的场景(从公园到海滩)、在不同物体上投射阴影的反射率变化,以及使用不同形状的遮挡物产生的多样轮廓和半影宽度。SRD 的阴影 mask 由 Recasting 重新标注。
- ISTD和 ISTD+: 两者都包含阴影图像、无阴影图像和阴影 mask ,具有 1,330 张训练图像和 540 张来自 135 个独特背景场景的测试图像。ISTD 存在阴影和无阴影图像之间的颜色和亮度不一致问题,ISTD+ 通过颜色补偿机制修正了这一问题,以确保在真实图像中像素颜色的一致性。
- GTAV: 是一个合成数据集,包含 5,723 对阴影和无阴影图像。这些场景由 Rockstar 的电子游戏 GTAV 渲染,描绘了两种版本的真实世界场景:有阴影和无阴影。它包括 5,110 个标准日光场景和额外的 613 个室内和夜间场景。
- USR: 旨在用于无配对阴影去除任务,包含 2,511 张带阴影图像和 1,772 张无阴影图像。该数据集涵盖了多种场景,展示了由各种物体投射的阴影。它跨越了超过一千个独特场景,为阴影去除技术的研究提供了丰富的多样性。
- SFHQ: Shadow Food-HQ,包含 14,520 张高分辨率食物图像(12MP),并附有标注的阴影 mask 。它包括在各种光照和视角下的多样场景,分为 14,000 个训练和 520 个测试三元组。
- WSRD:
通用视频阴影去除数据集
- SBU-Timelapse: 是一个视频阴影去除数据集,包含50个静态场景视频,主要特征是只有阴影移动,没有物体移动。每个视频使用“max-min”技术生成一个伪无阴影帧。
- SVSRD-85: 是一个来自 GTAV 的合成视频阴影去除数据集,包含85个视频,共4,250帧。通过切换阴影渲染器收集,涵盖了各种对象类别和运动/光照条件,每帧都配有无阴影图像。
文档阴影去除数据集
- SDSRD:这是一个用 Blender 创建的合成数据集,包含970张文档图像和8,309张在不同光照和遮挡条件下合成的阴影图像。数据集有7,533个训练三元组和776个测试三元组。
- RDSRD:这是一个通过相机捕获的真实数据集,包含540张图像,涉及25个文档,包括阴影图像、无阴影图像和阴影 mask 。该数据集仅用于评估。
- RDD:使用了文档背景如纸张、书籍和小册子。包含4,916对图像,每对图像分别在有阴影和无阴影的情况下拍摄,通过放置和移除遮挡物获得。其中4,371对用于训练,545对用于测试。
- SD7K:包含7,620对高分辨率的真实世界文档图像,有阴影和无阴影版本,并附有标注的阴影 mask 。涵盖各种文档类型(如漫画、纸张、图表),使用了30多种遮挡物和350多份文档,在三种光照条件(冷光、暖光和日光)下拍摄。
Facial Shadow Removal Datasets
- UCB: 包含合成的外部和面部阴影。外部阴影是通过在一个包含5,000张没有外部阴影的人脸数据集上,使用阴影蒙版混合明亮和阴影图像创建的;然而,眼镜阴影被视为固有的。面部阴影是通过对85名受试者进行Light Stage 扫描生成的,涵盖各种表情和姿势,使用加权的一次一光组合。
- SFW: 是为真实环境中的面部阴影去除而组装的,包含来自20名受试者的280个视频,大多数视频以1080p分辨率录制。提供了各种阴影蒙版的标签,如投射阴影、自身阴影、明亮或饱和的面部区域,以及眼镜,共440帧。
- PSE: ,即带眼镜的肖像合成,是通过3D渲染生成的合成数据集。它通过节点注册模拟3D眼镜在面部扫描上的效果,并在各种光照条件下渲染,生成四种带有蒙版的图像类型。在438个身份中,选择了73个,每个都有20个表情扫描,配有五种眼镜样式和四种HDR照明条件,生成了29,200个训练样本。
Evaluation Metrics
- RMSE在LAB色彩空间中计算出地面真实无阴影图像与恢复图像之间的均方根误差,确保局部感知的一致性。
- LPIPS(Learned Perceptual Image Patch Similarity)评估图像块之间的感知距离,得分越高表示相似性越低,反之亦然。本文采用VGG作为LPIPS中的特征提取器。
SSIM(结构相似性指数)和PSNR(峰值信噪比)有时用于评估。
实验结果一般图像阴影去除
整体性能基准测试结果。 采用了两个广泛使用的数据集,SRD 和 ISTD+,来评估阴影去除方法的性能。比较的方法列在下表10中,本文排除了那些代码不可用的方法。使用原始代码重新训练了比较的方法,输入尺寸设置为 和 ,以在两个分辨率下报告结果。
对于 DSC,本文将代码从 Caffe 转换为 PyTorch,并使用 ResNeXt101 作为主干网络。ShadowDiffusion(G)使用了预训练的 Uformer权重进行 ISTD+ 推理。对于需要阴影 mask 作为输入的方法,与之前一些在训练期间使用预测阴影 mask 的方法不同,本文在 SRD 和 ISTD+ 中采用了标注良好的 mask 。与某些依赖于推理期间的真实 mask 的方法不同(可能导致数据泄漏),本文使用由 SDDNet 检测器生成的阴影 mask 。该检测器在分辨率的 SBU 数据集上训练,显示出卓越的泛化能力,如上表3所示。使用的评估指标包括 RMSE、PSNR、SSIM 和 LPIPS。结果被调整为与真实分辨率匹配,以便进行公平比较。一些调整真实图像尺寸的论文是错误的,因为这会扭曲细节,导致对图像质量的评估偏差且不准确。上表10和下图2总结了每种方法的准确性、运行时间和模型复杂性。关键见解包括:
- (i)早期方法如 DSC 和 ST-CGAN 在多个评估指标上优于后来的方法;
- (ii)无监督方法在 SRD 和 ISTD+ 上表现出与有监督方法相当的性能,可能是因为训练集和测试集中的背景纹理相似,其中 Mask-ShadowGAN 在效果和效率之间提供了最佳平衡;
- (iii)较小的模型如 BMNet (0.58M) 提供了具有竞争力的性能,而没有显著增加模型大小;
- (iv)大多数方法在更高分辨率(如 )下显示出改进的结果。
跨数据集泛化评估。 为了评估阴影去除方法的泛化能力,本文使用在 SRD 训练集上训练的模型进行跨数据集评估,以检测 DESOBA训练和测试集上的阴影。两个数据集都包含户外场景,但 SRD 缺乏投射阴影的遮挡物,而 DESOBA 则呈现出更复杂的环境。这标志着首次在如此具有挑战性的数据集上进行的大规模泛化评估。请注意,DESOBA 仅标记投射阴影,本文在评估中将物体上的自阴影设为“不关心”。SSIM 和 LPIPS 被排除,因为 SSIM 依赖于图像窗口,LPIPS 使用网络激活,这两者都与“不关心”政策相冲突。上表10中最右边的两列显示,在像 SRD 和 ISTD+ 这样的受控数据集上表现良好的模型在 DESOBA 的更复杂环境中表现不佳。这是因为 SRD 主要特征是简单、局部场景中的投射阴影,阴影较软且无遮挡物,而 DESOBA 则呈现出更复杂的场景,具有更硬的阴影和遮挡。这突出了需要多样化的训练数据和更能适应处理现实世界阴影场景的模型。
总结 实验结果表明,如何开发一个稳健的模型并准备一个具有代表性的数据集,以在复杂场景中实现高性能的图像阴影去除,仍然是一个具有挑战性的问题。
文档阴影去除
RDD 数据集用于训练和评估文档阴影去除方法,输入尺寸为。结果如下表 11 所示,本文观察到 FSENet 在准确性和效率上显著优于 BEDSR-Net,使其在所有指标上成为更好的方法。
阴影生成
阴影生成主要有三个目的:
- (i)图像合成,涉及为照片中的物体生成投影阴影,以便能够插入或重新定位照片中的物体;
- (ii)数据增强,旨在在图像中创建投影阴影,以生成逼真的图像来支持深度神经网络的训练;
- (iii)素描,专注于为手绘草图生成阴影,以加速绘图过程。
图像阴影生成的深度模型图像合成的阴影生成
- ShadowGAN: 使用生成对抗网络(GAN)为图像中的虚拟物体生成逼真的阴影。它具有一个生成器和双鉴别器,确保阴影的形状和场景的整体光照相协调。
- ARshadowGAN: 是一种GAN模型,在单光源条件下为增强现实中的虚拟物体添加阴影。它使用注意力机制,通过建模虚拟物体阴影与现实世界对手之间的关系来简化阴影生成,无需估计光照或3D几何。
- SSN: 提供了一个实时交互系统,使用二维物体遮罩在照片中创建可控的柔和阴影。它使用动态阴影生成和环境光照图来训练其网络,生成多样化的柔和阴影数据。同时,它预测环境遮挡以增强真实性。
- SSG: 引入了像素高度,一种新的几何表示法,可以在图像合成中精确控制阴影的方向和形状。该方法使用投影几何进行硬阴影计算,并包括一个训练过的U-Net来为阴影添加柔和效果。
- SGRNet: 是一个两阶段网络,首先通过合并前景和背景的生成器创建阴影遮罩,然后预测阴影参数并填充阴影区域,生成具有逼真阴影的图像。
- Liu 等人 通过多尺度特征增强和多层次特征融合来增强图像合成中的阴影生成。该方法提高了遮罩预测的准确性,并在阴影参数预测中最大限度地减少信息损失,从而增强了阴影的形状和范围。
- PixHt-Lab: 将像素高度映射到三维空间,以创建逼真的光照效果,如阴影和反射。它通过重建剪切物体和背景的3D几何,使用3D感知缓冲通道和神经渲染器来克服传统2D限制,提高柔和阴影的质量。
- HAU-Net & IFNet: 由两个组件组成:层次注意力U-Net(HAU-Net)用于推断背景光照并预测前景物体的阴影形状;以及光照感知融合网络(IFNet),使用增强的光照模型融合曝光不足的阴影区域,创造出更自然的阴影。
- Valença 等人通过解决真实地面阴影与投影到虚拟实体的交互来增强照片编辑时的阴影整合。其生成器从虚拟阴影和场景图像创建阴影增益图和阴影遮罩,然后通过光照和相机参数进行后处理,实现无缝整合。
- DMASNet: 是一种两阶段方法,用于生成逼真的阴影。第一阶段将任务分解为盒子和形状预测,以形成初始阴影遮罩,然后进行细化以增强细节。第二阶段专注于填充阴影,调整局部光照变化以与背景无缝融合。
- SGDiffusion: 使用稳定扩散模型,结合自然阴影图像的知识,克服与精确阴影形状和强度生成相关的困难。具体来说,它通过ControlNet适配和强度调制模块增强阴影强度。
用于阴影消除的阴影生成
请参见前文中Mask-ShadowGAN、Shadow Matting GAN和G2R-ShadowNet。
草图的阴影生成
- 郑等人利用指定的光照方向,从手绘草图中创建详细的艺术阴影。他们在潜在空间中构建了一个3D模型,并渲染与草图线条和3D结构对齐的阴影,包括自阴影和边缘光等艺术效果。
- SmartShadow为数字艺术家提供了三个工具来为线条画添加阴影:用于初始放置的阴影笔刷、用于边缘精确控制的阴影边界笔刷,以及用于保持阴影方向一致的全局阴影生成器。通过卷积神经网络(CNN),它可以根据草图输入和用户指导预测全局阴影方向和阴影图。
影子生成数据集用于图像合成的阴影生成数据集
- Shadow-AR: 是一个合成数据集,包含3,000个五元组,每个五元组包括一个带有和不带有渲染阴影的合成图像、一个合成物体的二值 mask 、一个标注的真实世界阴影抠图及其相关的标注遮挡物。
- DESOBA: 是一个基于真实世界图像的合成数据集,源自SOBA。阴影被去除以作为阴影生成的真实值。它包含840张训练图像和2,999对阴影-物体对,以及160张测试图像和624对阴影-物体对。
- RdSOBA: 是使用Unity游戏引擎创建的合成数据集。它包含30个3D场景和800个物体,总计114,350张图像和28,000对阴影-物体对。
- DESOBAv2: 是一个利用实例阴影检测方法和修复方法构建的大型数据集。它包含21,575张图像和28,573个阴影-物体关联。
草图阴影生成数据集
SmartShadow 提供了真实和合成数据,包括:
- 1,670 对由艺术家创作的线条艺术和阴影。
- 25,413 对由渲染引擎合成的阴影。
- 291,951 对从互联网上的数字绘画中提取的阴影。
讨论
不同的方法由于其独特的模型设计和应用,需要特定的训练数据。例如,SGRNet 需要前景阴影 mask 和目标阴影图像用于图像合成。相比之下,Mask-ShadowGAN 只需要未配对的阴影和无阴影图像用于阴影去除。ARShadowGAN 使用真实阴影及其遮挡物的二值图进行训练,以生成增强现实中的虚拟对象阴影。SmartShadow 利用艺术家提供的线条画和阴影对来训练深度网络,以在线条画上生成阴影。由于篇幅限制,本文建议读者探索每个应用的结果,以了解方法的有效性和适用性。然而,目前的阴影生成方法主要集中在图像中的单个对象上,如何为视频中的多个对象生成一致的阴影仍然是一个挑战。此外,除了为缺乏阴影的对象生成阴影之外,通过调整光照方向来编辑各种对象的阴影提供了更多实际应用。
结论 & 未来方向
总结而言,本论文通过调查一百多种方法并标准化实验设置,推进了深度学习时代的阴影检测、去除和生成研究。 本文探索了模型大小、速度和性能之间的关系,并通过跨数据集研究评估了模型的鲁棒性。以下,本文进一步提出了开放问题和未来研究方向,强调AIGC和大模型对该领域学术研究和实际应用的推动作用。
一个集成阴影和物体检测、去除及生成的全能模型是一个有前景的研究方向。 目前大多数方法专注于某一特定任务——阴影的检测、去除或生成。然而,所有与阴影相关的任务本质上是相关的,可以从共享的见解中受益,特别是考虑到物体与其阴影之间的几何关系。开发一个统一的模型可以揭示底层关系,并最大化训练数据的使用,从而增强模型的泛化能力。
在阴影分析中,物体的语义和几何特征仍未被充分探索。 现代大型视觉和视觉语言模型,配备了大量的网络参数和庞大的训练数据集,在分析图像和视频中的语义和几何信息方面表现出色,且具备显著的零样本能力。例如,Segment Anything提供像素级分割标签;Depth Anything估计任何图像输入的深度;ChatGPT-4o预测图像和视频帧的叙述。利用这些语义和几何见解进行阴影感知,可以显著增强阴影分析和编辑,甚至有助于分离重叠阴影。
阴影-物体关系有助于执行各种图像和视频编辑任务。 实例阴影检测生成物体和阴影实例的 mask,促进了如图像修复、实例克隆和阴影修改等编辑任务。例如,通过实例阴影检测分析观察到的物体及其阴影,以估计未观察到物体的布局,实现图像扩展。将这些应用整合到手机中进行照片和视频编辑既简单又有益。鉴于现代手机配备了多个摄像头和高动态范围,探索如何利用这些摄像头进行增强的阴影-物体编辑是一个新颖的研究方向。
阴影是区分AI生成视觉内容与真实内容的有效手段。 AI生成内容(AIGC)的最新进展使得多样化的图像和视频创作成为可能。然而,这些AI生成的内容常常忽视几何方面,导致阴影属性上的差异,破坏了3D感知。实例阴影检测被用于分析物体-阴影关系,当光源对齐和物体几何不一致时,揭示图像的合成性质。AI生成的视频(例如,Sora3)也需要遵循3D几何关系。因此,探索未来研究方向,关注AI生成内容中的阴影一致性,并评估或定位潜在的不一致性,既重要又有趣。此外,阴影是一种自然且隐蔽的对抗攻击,可以破坏机器学习模型。
#MambaClinix
青大附院数字医学实验室提出,医学影像分割任务超越传统SOTA!
MambaClinix通过自适应分阶段设计将多层级CNN的高阶空间交互能力与SSM的全局依赖能力相结合,提供一个灵活的框架,可无缝集成到临床医学图像分割任务中,训练过程最大限度地减少人工干预,增强模型学习的自动化水平。
深度学习技术,尤其是CNN和Transformers,极大推动了3D医学图像分割的发展。然而CNN受制于局部感受野,阻碍其在复杂临床场景中的应用。Transformers能够有效捕捉长距离关联特征,但计算量较大,训练和部署成本高昂。近来,基于状态空间模型(SSM)的Mamba架构被提出,它在维持线性计算复杂度的同时,能够有效建模长距离依赖关系。然而,Mamba在医学图像分割任务中也暴露一些缺陷,特别是在捕捉高敏感的局部特征方面,临床效果并不理想。该研究提出一种MambaClinix模型,它将分层门控卷积网络(HGCN)与Mamba集成在一个自适应的分阶段(stage-wise)U型框架中。这种设计方式利于特征图的高阶空间交互,使模型能有效捕捉医学图像中的近端和远端关系。其中,该研究提出的HGCN网络,利用纯卷积结构来模仿Transformers注意力机制,成功促进了高阶特征的交互计算。此外,该研究引入了一种区域特定的Tversky损失函数,用于强调特定体素区域的学习效果,从而优化模型的决策过程。该研究最终在五个基准数据集上进行消融和比较实验,结果表明所提出的MambaClinix在保持低模型复杂度的同时获得了高分割精度。代码:https://github.com/CYB08/MambaClinix-PyTorch论文:https://arxiv.org/abs/2409.12533数据及预训练模型:https://drive.google.com/drive/folders/111n2yo68O3s7kZFjwo7840B-pdNWkAvG
MedAna3.0为团队自研的医学影像综合分析平台。该平台的核心分割模型即为MambaClinix. MedAna3.0视频简介如下:
Link:https://www.bilibili.com/video/BV1VYbFepEDk/?spm_id_from=333.999.0.0
1 Introduction
医学图像分割能够精确描绘解剖结构,提高临床诊断质量。在该领域,卷积神经网络(CNN)因其固有的平移不变性而成为主流模型。CNN这种能力在医学成像中至关重要,因为与疾病相关的ROI可能出现在不同的方向和位置。然而大量研究表明,CNN的局部感受野制约了它们捕捉全局特征的能力,给更精准的医学图像分割带来了挑战。在医学图像分析中,理解更大的解剖结构,解析临床图像不同部分之间的空间关系,对于分析复杂影像特征,识别大范围病灶至关重要。近年来,Transformer模型由于其独特的自注意力机制,使它在捕捉医学图像长距离特征方面展现出了效果。这种自注意力机制促进了不同距离和复杂度的空间特征相互作用,分割效果超越了标准CNN,产生了令人印象深刻的结果。然而,Transformers计算复杂度较高且需大量样本用于训练,使得它们不太适合轻量级模型部署。尽管如此,Transformers中的自注意力机制为图像分割带来新的启发。一些研究表明,自注意力机制的有效性源于其能够促进图像内高阶特征交互。这种能力是通过动态调整注意力权重和自适应地聚焦于各个空间维度来实现的,这有助于全面分析医学影像中的全局特征关系。以此为动机,我们仿照高阶空间交互特点,开发了一种用于3D医学图像分割的新型分层门控卷积网络(HGCN)。HGCN采用纯卷积结构,以递归方式在多个维度上进行空间特征交互。然而,进一步的实验表明,随着网络的加深,提升HGCN的空间交互阶数以捕获长距离特征的成本效益将逐渐降低。此外,涉及高阶空间交互的计算需要大量的递归和门控卷积过程,这不仅需要大量的GPU资源,还可能增加过拟合的风险。最近,状态空间模型(SSM),尤其是Mamba,在有效捕获长距离依赖关系方面表现出明显的优势。与基于Transformer的模型相比,Mamba卓越的计算效率和硬件加速算法,使其非常适合处理3D医学图像等复杂数据。随后,一些研究探索了将CNN与Mamba相结合,旨在将CNN详细的局部特征提取与Mamba的全局特征表示能力相结合,提高医学图像分割的精度。在该研究中,为了平衡模型在捕捉局部和全局特征方面的能力,我们提出了MambaClinix,一种自适应的分阶段(stage-wise)建模框架,它融合了HGCN和Mamba组块,针对医学图像分割进行了优化。在编码器的较低阶段,使用HGCN来扩展高阶空间交互。为了克服增加HGCN交互阶数带来的收益递减,在较高阶段加入了一个残差Mamba模块来取代HGCN,用于提取长距离依赖特征。HGCN增强了Mamba块的语义特征,丰富了输入质量。这种分阶段方法使模型能够更深入地理解医学图像中的近端和远端关系,这对于临床医学分割任务至关重要。MambaClinix继承了nnU-Net的自配置策略,允许自动调整网络结构以匹配特定的数据集特征。这种自适应配置可确保模型架构经过精细调整以满足不同数据集的独特需求。总体而言,MambaClinix通过自适应分阶段设计将多层级CNN的高阶空间交互能力与SSM的全局依赖能力相结合,提供一个灵活的框架,可无缝集成到临床医学图像分割任务中,训练过程最大限度地减少人工干预,增强模型学习的自动化水平。

2 Method2.1 Framework

该研究提出的MambaClinix架构如图1所示,采用自适应stage-wise设计,组合不同功能组块在一个U形框架中。在编码器的较低阶段,设计了一个分层门控卷积网络(HGCN)块,如图2(b)所示,通过纯卷积结构搭建空间交互网络。在较高阶段,采用残差Mamba块,如图2(a)所示,取代了HGCN,用于增强对长距离依赖关系的捕捉能力。由此,所提出的MambaClinix将编码器分为两部分:第一部分利用HGCN实现高效的空间特征交互,第二部分将这些特征输入残差Mamba块,以确保全面理解更大的空间信息。该架构使网络能够平衡细节特征处理和全局特征集成,优化医学图像分割的深度和广度。MambaClinix采用nnU-Net的自配置方法,可自动调整网络结构以适应每个数据集的特征。此外,所提出的HGCN能够深度集成到这种自适应配置中,允许根据数据集特征动态调整HGCN空间交互阶数。这种灵活性确保HGCN可以自适应地增加阶数以平衡结构复杂性和计算效率。在模型训练期间还应用了区域特定的Tversky损失函数,对3D医学图像的每个子体素进行不同的损失加权。这种方法将模型的注意力引导到更具挑战性的分割区域,改善细节学习并提高整体分割性能。
2.2 Hierarchical Gated Convolutional Network (HGCN)
HGCN嵌入在框架中,用于在早期阶段动态捕获图像特征。其核心处理由高阶门控卷积(hgConv)层实现,该层采用门控卷积机制和递归过程促进高阶空间交互。hgConv通过将交互扩展到多个级别来绕过自注意力机制的复杂计算,增强了CNN捕获医学图像中多级空间依赖关系的能力。此外,hgConv可适应各种临床数据场景,与自适应框架无缝集成。在编码器的第s阶段,具有通道的输入特征首先通过标准残差网络(Res),然后Stem层(Stem)将通道数调整为。Stem能够确保后续hgConv具有稳定的输入结构。经过层归一化(LN)后,数据通过hgConv处理以实现高阶空间交互。然后将生成的特征图映射为输出量,并与残差分量相结合。该过程可以表示为:高阶门控卷积(hgConv) 。给定一个3D输入特征。函数φ涉及两个连续卷积过程,用于将原始通道转为通道扩展并进一步细化的子向量集。输入投影首先将通道数扩展2倍,然后经过深度卷积层,将通道进一步分解为多个子向量组合,该过程可以表示为:
其中,n表示hgConv的空间交互阶数。这种细分策略是通过将通道划分为逐渐减小的子部分来实现的,如下式所示。
然后,每个细分的子向量经历从j到j+1的变换过程,其公式如下:
其中 表示对应于的卷积函数。一个外部参数γ用于调节前一次的输出。此操作促进了不同层之间的信息交互,增强了模型捕捉医学图像中复杂特征的能力。
2.3 Mamba Block
残差Mamba组块利用残差连接和层归一化来增强原始Mamba的空间建模能力。它放置在编码器的较高阶段,以总结HGCN输出的全局特征,捕获医学图像中的长距离依赖关系。在第s个阶段,输入特征首先经过核大小为1×1×1的残差卷积,然后进行批量归一化(BN)和非线性激活函数σ。变换后的输出进行展平、转置、归一化,并通过具有两个并行分支的Mamba块进行处理。一个分支从层归一化特征上的线性函数(LN)开始,经过深度卷积(dwConv)和SiLU函数,再由状态空间模型(SSM)层进行特征增强。对于没有SSM层的另一个分支,它先经过线性函数,然后是SiLU函数。最终,使用Hadamard积将两个分支的特征组合起来,重新整形为原始形状,并通过残差连接重新集成到网络中。这个过程可以写成:
其中,MLP(·)是一个多层感知结构。该架构保留了图像特征流的连续性和完整性,有助于梯度在网络中传播。
2.4 Stage-wise Integration of HGCN and Mamba
随着网络的加深,增加HGCN的计算阶数以捕捉医学图像全局特征的收益逐渐减少。为了解决这个问题,我们在更高阶段引入了残差Mamba块来替代HGCN。这种替代旨在提取长距离依赖关系,同时保持计算效率。HGCN在早期阶段捕获的详细图像特征为Mamba块提供了丰富的信息,提高了其接收输入的质量。给定一个具有s个阶段的编码器,其中H和M分别代表HGCN和残差Mamba组块。编码器的stage-wise设计,可以表示为:
其中,s是总体阶段(stage)数,s能够根据特定数据集特征自适应调整。考虑到计算复杂性和GPU限制,HGCN块计算的空间交互阶数最小为2,最大为6。表示第s//2阶段的HGCN块,代表该阶段计算了(s//2+1)阶的空间交互;表示第s阶段的Mamba块。这种stage-wise设计展现了的可定制功能,是如何与自适应配置策略深度集成的。
2.5 Region-Specific Loss Function
在模型训练过程中,Dice损失函数会优化真阳性(TP),并同等惩罚假阳性(FP)和假阴性(FN)。然而,目标器官和背景之间的图像差异通常会造成数据不平衡,使预测偏向背景,导致FN比FP增加更快。而在临床环境中,高召回率(减少FN)指标是需要重点优化的,以确保能够正确识别到每个可能的疾病区域,即使以牺牲一些FP为代价。例如,肺部CT扫描中遗漏一个小结节可能会延误肺癌治疗,而FP可以通过额外的人工检查来纠正。为了解决这个问题,Tversky损失函数被提出,其定义为:
然而,这种Tversky损失函数关注的是总体三维影像,对目标区域和背景区域的体素进行统一惩罚,却忽略了不同子区域之间的分割难度差异。为了克服这一限制,我们提出了一个区域特定的损失函数,专注于优化三维医学图像中的特定子区域。在训练过程中,该方法会动态调整不同区域的惩罚,以提高整体预测准确性,为更难分割的子区域分配更高的权重。因此,将区域特定的Tversky损失函数改写为:
其中,由N个体素组成的医学图像被划分为k个子体素,表示为。模型聚焦计算这些子体素的损失。并且区域特定损失的梯度仅取决于对这些子区域的评估,而不是整个图像。
3 Experiment and results3.1 Datasets
为了获取反映多样化和真实临床场景的数据,我们在青岛大学附属医院山东省数字医学与计算机辅助手术重点实验室中,进行了一项回顾性研究。本研究从2021年至2023年间,随机采样研究数据,构建三个内部数据集(PCD、LungT和LiverT)。此外,我们还收集了两个公共数据集(ABD [Umamba] 和 BraTs2021)用于实验评估。数据集详细信息如表1所示。MambaClinix继承了nnU-Net的自配置功能,针对不同数据集的网络配置参数如表2所示。(1)肺循环CECT数据集(PCD)。该内部数据集包含547个三维增强CT(CECT)图像,这些图像经过精确注释以分割肺循环系统,并带有支气管、肺动脉和肺静脉的标签。它来自2022年至2023年期间在青岛大学附属医院随机抽样的病例。每个图像都由三名经验丰富的高年资医生手工标注,随后由临床医生审查以确保准确性。该数据集已用于临床环境中的辅助诊断。(2)肺肿瘤CECT数据集(LungT)。该内部数据集包括800个CECT图像,重点聚焦肺肿瘤。它是从2021-2023年期间在青岛大学附属医院随机抽样的病例中收集的。由三名经验丰富的高年资医生精准标注,随后由临床医生完善,以确保在临床诊断和手术规划中的实用性。(3)肝肿瘤CT数据集(LiverT)。该数据集包含292个肝肿瘤样本,并分为两部分。第一部分是内部收集的161张CECT图像,这些图像来自2021年至2023年期间青岛大学附属医院随机选择的病例。这些样本由经验丰富的医生注释并由临床医生验证。第二部分包括来自公开的医学分割十项全能(MSD)挑战赛的131个样本,专门针对CT图像中肝肿瘤分割,每个图像都清晰标记以区分肝脏和肿瘤。(4)腹部CT数据集(ABD)。该数据集源自 MICCAI 2022 FLARE挑战赛,是一个由100例CT影像组成的分割数据集。旨在分割13种不同的腹部器官。该数据集与U-Mamba设置一致,训练集包含来自MSD Pancreas数据集的50个CT影像,注释由AbdomenCT-1K提供。另外50个病例来自多医疗中心作为测试集。此设置可在不同的成像场景中对模型进行稳健评估。(5)脑肿瘤MRI数据集(BraTS)。该数据集来自BraTS2021挑战,专为脑肿瘤分割而设计,包含1,251个3D脑磁共振成像(MRI)。每个样本具有四种成像模式(T1、T1ce、T2 和 Flair)。该数据集包含三种分割区域:整个肿瘤 (WT)、增强肿瘤 (ET) 和肿瘤核心 (TC)。


3.2 Implementation Setup
MambaClinix基于nnU-Net和UMamba框架开发,总体模型在PyTorch 2.0.1上实现。所有实验在四块NVIDIA GeForce RTX 4090 GPU 上进行。优化器采用Adam,初始化学习率为1e-4。使用PolyLRScheduler进行学习率调节。MambaClinix在PCD数据集上训练了300个epoch,在LungT数据集和LiverT数据集上训练了1000个epoch,在ABD数据集和BraTS数据集上训练了500个epoch。
3.3 Benchmark Results
为了评估MambaClinix的效果,本研究比较了医学图像分割领域的几种成熟模型。结果如表3和图3-5所示。所有比较模型根据其基础架构分为三组:基于CNN的模型(nnU-Net 、SegResNet)、基于Transformer的模型(UNETR、SwinUNETR)和基于Mamba的模型(U-Mamba、LightM-Unet和MambaClinix)。使用DSC系数和mIoU等指标评估性能。所有模型均使用nnU-Net框架实现,并进行一致的图像预处理以确保公平比较。
在LungT数据集上,MambaClinix的Dice得分为72.78%,鉴于肺组织的高度变异性和相似的密度,这一结果非常显著,表明其能够准确分割较小的、对比度较低的区域。在包含一系列具有复杂几何形状的腹部器官ABD数据集上,MambaClinix获得了最高的84.69%。值得注意的是,该数据集的训练集和测试集来自不同的数据源,凸显了该模型在全局特征提取和关键特征迁移方面的稳健性。LiverT数据集来自两个不同源的混合,MambaClinix的Dice得分为 71.37%,优于其他模型,并证明了其在处理具有严重结构异常的图像方面是有效的。虽然MambaClinix在PCD和BraTS数据集上没有取得最高分,但它仍然取得了极具竞争力的结果,展示了其在复杂临床场景中的稳健性。


图 3. 在a)PCD数据集和b)ABD数据集上的视觉比较,突出显示具有显著差异的区域。

图 4. 在a)LiverT数据集和b)BraTS数据集上进行视觉比较,突出显示具有显著差异的区域。

图 5. 结果可视化。a)LiverT数据集上肝肿瘤的3D可视化;b)LungT数据集的分割结果,包括肺肿瘤的空间定位。
3.4 Ablation Study
我们进行了消融研究,以评估MambaClinix架构中不同组块的功能性。实验是在BraTS、LiverT和LungT数据集上进行的,结果详见表4。用标准残差块替换MambaClinix中Mamba和HGCN块来建立baseline模型,用作后续消融实验的比较。不同组块被逐步集成或替换到基线配置中。这种方法允许系统地评估每个块对整体分割性能的贡献。更详细的消融比较实验,可以参考作者原文。

3.5 Efficiency of Region Specific Loss
该实验中,作者首先采用交叉熵(CE)和Dice相结合的复合损失函数。进一步将三维图像划分为子体素,应用特定区域的Dice损失来单独优化每个子区域的预测,称为基线(RS)。接下来,加入Tversky损失项(LTRS),FP和FN的固定惩罚系数分别设置为0.3和0.7。最后,引入这些惩罚系数的自适应策略,形成MambaClinix的最终损失函数。结果列于表5中。更详细的消融比较实验,可以参考作者原文。

4 Conclusion
该研究提出了MambaClinix,这是一种新颖的U型架构医学图像分割模型,它将HGCN和Mamba模块集成在一个自适应的stage-wise框架内。该方法进一步结合了区域特定的损失函数来优化模型的决策能力。MambaClinix架构能够自适应配置自身网络结构以适应不同的数据集,同时应用区域特定损失的策略,使其能够应用于多种临床分割任务。跨多个数据集的实验结果表明,与基于Transformer的方法相比,MambaClinix提供了卓越的计算效率,同时分割性能优于其他最先进的分割模型。
#Playground v3
如何用Deep-Fusion实现完美图文对齐?实现超越人类的图形设计能力
实验结果表明,PGv3 在文本提示的准确性、复杂推理和精确的文本渲染方面表现优异。用户偏好研究表明,PGv3 在常见的设计应用 (如贴纸、海报和徽标设计) 中具备超越人类的图形设计能力。
本文提出的 Playground v3 (PGv3) 是 Playground Research 团队于 2024.09 推出的最新 text-to-image (T2I) 模型,在多个测试基准上达到了 SoTA 性能。Playground v3 不像传统依赖 LLM (比如依赖于 T5 或者 CLIP 文本编码器) 的 T2I 模型,它完全整合了 LLM。Playground v3 通过一种新颖的 Deep-Fusion 结构,独立地从 decoder-only LLM 中获取文本条件。此外,为了提升图像字幕的质量,作者开发了一个内部的字幕生成器,能够生成具有不同细节层次的字幕,丰富了文本结构的多样性。作者还引入了一个新的基准 CapsBench,用于评估详细的图像字幕生成性能。实验结果表明,PGv3 在文本提示的准确性、复杂推理和精确的文本渲染方面表现优异。用户偏好研究表明,PGv3 在常见的设计应用 (如贴纸、海报和徽标设计) 中具备超越人类的图形设计能力。此外,PGv3 还引入了新的功能,包括精确的 RGB 颜色控制和强大的多语言理解能力。

图1:来自 Playground v3 的采样结果,包括照片级逼真的人物形象,多样化的场景,精确的文本呈现以及艺术设计作品
1 Playground v3:Deep-Fusion,一个策略实现 T2I 模型更好的图文对齐
论文名称:Playground v3: Improving Text-to-Image Alignment with Deep-Fusion Large Language Models
论文地址:
http://arxiv.org/pdf/2409.10695
1.1 Playground v3 简介
大规模文生图模型的架构从传统的基于 U-Net 的模型[1]转移到基于 Transformer 的模型[2]。这项工作在此基础上开发了一种新的基于 DiT 的扩散模型并将其缩放到 24B 参数。作者进一步提出了一个 Deep-Fusion 架构,以利用现代仅解码器的 LLM[3]的知识来生成文生图的任务。
第 1.2 节中,作者描述了简化的模型架构、噪声调度和新的变分自动编码器 (VAE)。新的 T2I 模型结构的特点是 LLM 的深度集成,充分利用 LLM 的内部提示理解来实现最先进的提示跟随性能。1.3 节讨论了模型训练细节,包括在预训练阶段使用多级字幕和模型合并。1.4 节介绍了我们的内部字幕器和一个新的字幕基准 CapsBench。
第 1.5 节中,作者展示了本文模型在 5 个关键方面的能力的定性示例:照片现实主义、提示跟随、文本渲染、RGB 颜色控制和多语言理解。
1.2 Playground v3 模型架构
文本编码器
Playground-v3 (PGv3) 是一种使用 EDM[4]范式训练的 Latent Diffusion Model (LDM)[5],服务于文生图 (T2I) 任务。与之前的 DALL-E 3, Imagen 2, 和 Stable Diffusion 3。不同的是,它不使用常见的文本编码器 (Text Encoder),比如 T5[6]或者 CLIP[7],而是集成了大语言模型 (LLM),尤其是 LlaMA3-8B[3],以增强其在即时理解和后续方面的能力。
一些研究工作[8][9][10][11]也希望利用 LLM 来提高 T2I 模型的指令对齐的能力,比如使用 LLM 作为文本编码器来替换常用的 T5 和 CLIP,或者使用 LLM 来适配或者修改 Prompts。PGv3 使用的是前一种方法:不使用 T5 或者 CLIP 等文本编码器,紧紧依靠 LLaMA3-8B 为 Diffusion 模型提供 text condition。whaosoft开发板商城测试设备测试
对于预训练的文本模型,作者在使用时采取了一种非常不同的策略。标准的做法是使用 T5 Encoder 或者 CLIP Text Encoder 的最后一层的输出。Transformer 的每一层都有不同的表征[12][13],包含不同级别的单词级和句子级的信息。但是作者发现调节 T2I 模型的最佳层可能很麻烦,尤其是对于 Decoder-only 的 LLM 而言。由于其复杂的内部表征,才使其具有优越的生成能力。
作者认为,信息流在 LLM 中每一层的连续性使其具有了强大的生成能力。换句话讲,LLM 中的知识跨越其所有的层,而不是任何单层的输出可以描述的。受到这一启发,作者设计了 T2I 的模型架构,使其复制 LLM 内的所有 Transformer Block。这种设计允许本文模型将来自 LLM 的每个对应层的 Hidden Embedding 作为输入 T2I 模型每一层的 condition。作者认为这种方法充分利用了 LLM 完整的思考过程,指导 T2I 模型反映 LLM 的推理和生成过程。因此,本文模型在生成图像时实现了很好的 Prompt following 的能力。
模型架构
Playground v3 整体基于 DiT-style[14]架构。在 PGv3 的图像模型中,每个 Transformer Block 被设置为与 LLM (LlaMA3-8B) 中的相应 Block 相同,包括 hidden dimension、attention head 数量和维度等参数。作者只训练了图像模型,保持 LLM 不变。注意在扩散采样过程中,LLM 部分只需要运行一次以生成所需的所有中间 hidden embedding。whao开发板商城测试设备测试
简化版的 PGv3 架构如图 2 所示。每个 Transformer Block 只包含一个 Attention 层和一个 FeedForward 层,反映了 LlaMA3 的结构。与大多数传统的基于 CNN 的扩散模型[5]不同,这些模型通常将图像特征的 Self-Attention 与图像特征之间的 Cross-Attention 分开。但是本文不一样,本文作者使用了一个单一的 Joint Attention 操作:Image Query 关注 Image Key 和 Text Key 的串联,使其能够从 Image 和 Text 值的组合池中提取相关特征。这种 Joint Attention 设计的主要动机是希望降低计算成本和推理时间。

图2:简化版的 PGv3 架构
虽然最终确定了我们的模型设计,并在 SD3[15]发表之前开始训练,但作者观察到,如果把相应的 LLM Block 和 Image Block 视为 PGv3 中的单层时,PGv3 Transformer Block 与 SD3 中提出的 MMDiT 具有相似的设计哲学。这种哲学为,在所有的 Block 中使得图像和文本特征之间的集成和连续交互的思想。而且,本文的设计更简单,更彻底地利用了文本编码器。
有许多研究工作旨在探索更好的模型结构,例如 Hunyuan-DiT[16],Pixart-α[17]。作者对 PGv3 进行了几次结构的调整,但没有观察到大多数存在明显的好处。这里作者报告了这个过程中发现有用的一些设计,并合并到最终模型的设计中。
U-Net Transformer Block 之间的 Skip-connections。 作者在所有 Image Block 上应用 U-Net Skip-connection,如之前在 U-DiT[18]中尝试的那样。
中间层的 Token Downsampling。 在 32 层中,作者将图像 Key 和 Value 的序列长度减少了 4 倍,使整个网络类似于传统的卷积 U-Net,只有一层下采样。这种调整略微加快了训练和推理时间,因此没有观察到任何性能下降。
位置编码。 作者使用了传统的旋转位置编码 (RoPE)[19]。由于使用二维图像特征,作者采用了 RoPE 的 2D 版本。之前的几项工作已经探索了 2D-RoPE 的变体;在本文研究中,作者主要尝试了 2 种类型,称之为 "interpolating-PE" 和 "expand-PE"。
"interpolating-PE" 方法保持开始和结束位置 ID 固定,而不管序列长度如何,并在两者之间插入位置 ID,这也是SD3 等模型采用的想法。而 "expand-PE" 方法以序列长度按比例增加位置 ID,无需应用任何技巧或归一化。
作者发现 "interpolating-PE" 有一个显著的缺点:导致模型在训练分辨率上严重过拟合,无法泛化到看不见的纵横比。相比之下,"expand-PE" 方法表现良好,没有分辨率过拟合的迹象。因此,作者选择最后使用传统的位置编码。
模型 VAE
LDM 中使用的变分自动编码器 (VAE) 在确定模型对细粒度图像质量的上限方面起着至关重要的作用。Emu[20]的作者将 VAE latent channel 从 4 增加到 16,从而提高了合成更精细的细节的能力,特别是对于较小的人脸和单词。按照这种方法,作者用 16 个通道训练了内部 VAE。此外,作者没有仅在 256×256 分辨率下进行训练,而是将训练扩展到 512×512 分辨率,这进一步提高了重建性能。
作者尝试结合 Emu 的 VAE 训练中提出的频率方法,但没有观察到任何性能改进。此外,作者探索了更积极的 VAE 修改,包括使用预训练的 Image Encoder,如 CLIP 的 Image Encoder。但是,尽管这些方法产生了具有相当重建能力的 VAE,但这些预训练的 Image Encoder 生成的 latent space 导致扩散训练不稳定,因此没有进一步探索。
1.3 Playground v3 模型训练
Noise Schedule
尽管 Flow Matching 模型[21][22][23]最近出现的比较多,但 Playground v3 模型继续使用 EDM[4]schedule,与 PGv2.5 保持一致。作者称不使用 Flow Matching 没什么具体的原因,只是使用 EDM schedule 没有遇到任何性能限制。与此同时,作者对 EDM2[24]中提出的动态时间戳加权技术进行了实验,该技术针对 EDM schedule 量身定制。不幸的是,没有观察到任何显着的性能提升。作者怀疑这可能是由于模型大小和数据的差异,因为本文的训练规模远大于 EDM2 中使用的 ImageNet 训练设置。
多 Aspect-Ratio 支持
继之前在 PGv2.5[25]中的工作之后,本文采用了多 Aspect-Ratio 训练策略。作者从 256×256 低分辨率下的正方形图像训练开始,并在更高分辨率的 512×512 和 1024×1024 像素尺度上使用在线桶策略。
图像多级字幕
作者开发了一个内部视觉大语言模型 (VLM) 字幕系统,能够生成高度详细的图像描述,包括小物体、照明、风格和视觉效果。作者在这个内部字幕器 (PG Captioner) 上运行基准。结果表明,本文模型在多个特定于图像的类别中优于其他模型。
本文作者通过生成多级字幕来减少数据集 bias 并防止模型过拟合,进一步改进了这些字幕条件。如图 3 所示,对于每个图像,作者合成了 6 个不同长度的字幕,从细粒度细节到粗略概念。在训练期间,在不同的迭代中为每个图像随机抽取这 6 个字幕之一。

图3:多级字幕示例,从训练集中随机采样

图4:具有简单短提示的 PGv3 图像生成结果
多级字幕可以帮助模型学习更好的语言概念层次结构。这允许模型不仅可以学习单词和图像之间的关系,还可以了解单词之间的语义关系和层次结构。因此,本文模型在响应较短 Prompt 时表现出多样性。而且,当在数据样本较少的数据集上进行训练时,例如在监督微调 (SFT) 阶段,多级字幕有助于防止过拟合,并显着增强了模型的泛化能力,将 SFT 数据集的良好图像属性推广到其他图像域。如图 4 所示,当给定一个简短而简单的 Prompt 时,本文模型可以生成不同的内容,在风格、颜色色调、种族和其他属性上有所不同。
训练稳定性
作者在模型训练后期观察到损失出现了尖峰,具体的表现是训练损失在没有 NaN 值的情况下变得异常大,导致当时的模不能够生成有意义的内容。作者尝试了几种策略来解决这个问题,包括使用梯度裁剪降低 Adam 优化器的 beta,并降低学习率。然而,这些方法最终都被证明是无效的。最终,作者发现下面的方法有助于缓解这个问题。
在训练期间,作者遍历了所有模型参数的梯度,并计算有多少梯度超过了特定的梯度值的阈值。如果这个计数值超过了预定义的计数阈值,就丢弃掉这个 training iteration,也就意味着不使用梯度更新权重。具体来讲,作者观察到,在发生损失的尖峰之前几次 training iteration,大值梯度的数量开始增加,并且在发生损失尖峰时达到了峰值。通过在损失尖峰之前记录多个 iterations 大值梯度的数量,将该值设置为阈值,然后按照这个阈值丢弃这个 training iteration。
这种方法不同于梯度裁剪。梯度裁剪只减少了梯度的大小,但不会改变权重更新的方向。因此,权重仍然可以向崩溃移动。通过丢弃整批梯度,本文这种方法避免了这种风险,并确保模型保持在稳定的训练轨迹。
1.4 图像字幕模型 PG Captioner 和评测框架 CapsBench
PG Captioner
对于字幕模型,作者使用标准的视觉语言架构[26],该架构由视觉编码器、视觉语言 adapter 和 decoder-only 的语言模型组成。作者参考[27]认为高分辨率视觉编码器对于图像的详细字幕非常重要。作者还发现模型大小与训练它到合理质量所需的数据量之间存在负相关:与更大的模型相比,小模型需要更多的数据来产生连贯的长字幕。对于模型训练,作者使用了合成数据生成工作流[28]和迭代自我改进[29]。
CapsBench
字幕评估是一个复杂的问题。字幕评估指标主要有 2 类。第 1 类是有参考的指标:BLEU、CIDEr、METEOR、SPICE。这些指标使用 GT 的字幕或一组字幕来计算相似度作为质量指标。第 2 类是无参考的指标:CLIPScore, InfoMetIC, TIGEr。这些方法使用来自参考图像或图像的多个区域的语义向量来计算所提出的字幕的相似性度量。这些方法的缺点是对于密集图像和长而详细的字幕,语义向量将不具有代表性,因为它们将包含太多概念。
受 DSG[30]和 DPG-bench[31]的启发,作者提出了一种用于图像字幕评估的反转方法。基于图像,作者在 17 个类别中生成 "是-否" 问答对:一般、图像类型、文本、颜色、位置、关系、相对位置、实体、实体大小、实体形状、计数、情感、模糊、图像伪影、专有名词 (世界知识)、调色板和颜色分级。大多数问题的答案是“是”的。在评估过程中,作者使用 LLM 仅根据候选字幕回答问题。可用的答案选项是 "yes","no" 和 "n/a"。然后将答案与参考答案进行比较以计算结果准确性。
本文正在发布 CapsBench[32],200 张图像和 2471 个问题,每张图像平均 12 个问题。图像代表了各种各样的类型:电影场景、卡通场景、电影海报、邀请、广告、休闲摄影、街道摄影、风景摄影和内部摄影。各种问题和图像可以对图像字幕系统进行全面评估。
1.5 图像质量的定性评价结果
图像逼真度评价
图 5,6 和 7 显示了 PGv3 和其他顶级模型的图像生成结果。在图 5 和图 6 的每个面板中,图像安排如下:左上角是 Idegram-2,右上角是 PGv3,左下角是 Flux-pro,右下角是 Prompt。
在放大以检查细节和纹理后,就能够观察到相对显著的差别。Flux-pro 生成的图像皮肤过度平滑,类似于含油或 3D 渲染,而不是逼真的描述。与 Flux-pro 相比,Idegram-2 提供了更真实的皮肤纹理,但在 Prompt 的遵从性方面表现不佳,通常在 Prompt 变长时缺少关键细节。相比之下,PGv3 在提示跟踪和生成逼真的图像方面都表现出色。此外,PGv3 表现出比其他模型更好的电影质量。

图5:定性比较:左上角是 Idegram-2,右上角是 PGv3,左下角是 Flux-pro,右下角是 Prompt

图6:定性比较:左上角是 Idegram-2,右上角是 PGv3,左下角是 Flux-pro,右下角是 Prompt

图7:PGv3 的照片级真实感定性结果
指令遵从评价
图 8 说明了包括 Idegram-2 和 Flux-pro 在内的 3 个例子,突出了与其他模型相比 PGv3 模型优越的指令跟踪能力。在每个 Prompt 中,彩色文本突出了其他模型无法捕获的具体细节,而 PGv3 始终遵从了这些细节。对特定颜色没有特别的含义。随着测试提示变长并且包含更详细的信息,PGv3 的优势变得尤为明显。作者将这个性能的提升归因于集成到模型内部的 LLM 以及先进的 VLM 字幕系统。

图8:Prompt-following定性比较。明亮颜色突出显示的文本表明 Flux-pro 或 Idegram-2 未能遵循提示的实例,而 PGv3 始终遵守 prompt 中的所有细节
文本渲染评价
图 9 展示了 PGv3 的文本渲染能力。它可以生成各种设计类别的图像,包括海报、徽标、贴纸、书籍封面和演示幻灯片。值得注意的是,由于其强大的 Prompt 跟随和文本渲染能力,PGv3 可以通过自定义文本重现流行的主题或者创建新的主题。

图9:文本渲染定性结果。PGv3 可以跨各种类别生成文本丰富的内容,从广告和徽标等专业设计到玩耍创作
RGB 色彩控制
PGv3 在生成的内容中实现了非常细粒度的颜色控制,超过了标准的调色板。PGv3 凭借其强大的 Prompt 跟随能力和专门的训练,使用户能够使用 RGB 值精确地控制图像中每个对象的颜色或区域,使其成为需要精准色彩匹配的专业设计场景的理想选择。如图 10 和图 11 所示,PGv3 接受整体调色板,自动将指定的颜色应用到适当的对象和区域,以及用户定义的特定对象的专用颜色值。

图10:RGB 颜色控制定性结果。由于空间限制,省略了 prompt,每张图像下的颜色条表示提示中指定的项目和颜色

图11:RGB 调色板控制定性结果。PGv3 接受整体调色板,自动将指定的颜色应用于适当的对象和区域
多语言提示输入
由于用作文本编码器的强大 LLM,PGv3 可以理解多种语言并在它们之间形成高度相关的 word representation,PGv3 可以自然地解释多种语言之间的 Prompts,作者发现这种多语言能力完全是通过一个小的多语言文本和图像对数据集实现的,数以千计的图像就足够了。
图 12 说明了模型在不同语言上的性能。在每个面板中,图像是从英语、西班牙语、菲律宾语、法语、葡萄牙语和俄语的提示生成的,从左到右排列。PGv3 始终能够产生符合每个相应语言中 Prompt 的内容。

图13:多语言定性结果。在每个面板中,图像是从英语、西班牙语、菲律宾语、法语、葡萄牙语和俄语的 prompt 生成的,从左到右排列
1.6 图像质量的定量评价结果
ImageNet Benchmark
作者在两个 Benchmark,即:ImageNet 和 MSCOCO 上展示了结果,将 本文的 PGv3 模型的性能与其他最先进的模型进行比较。然而,ImageNet 和 MSCOCO 可能无法有效地捕获大规模文本到图像模型的综合性能,特别是考虑到 PGv3 等模型在提示跟踪方面的提升。
在图 13 中,作者将 PGv3 与之前的模型 PGv2.5 进行比较。作者遵循[15]的方法使用 a photo of a {class} 的格式,把 ImageNet 的类标签转化为 text condition。作者还在相同的设置中比较了 SoTA 方法 EDM2 模型。PGv3 在 FID 和 FD Dinov2 方面表现更好。作者还展示了 SoTA 类条件模型性能作为参考;通常,这些模型以类标签作为条件来实现更好的性能。

图13:ImageNet 图像质量评估。所有样本都以 256×256 分辨率评估
MSCOCO Benchmark

图14:MSCOCO 评估。作者以 256 和 512 的分辨率比较了 PG2.5,以及 1024 分辨率的 SoTA 开源方法。作者与原始标题 (通常很短) 和 PG 标题 (更多细节更长) 进行比较
作者还使用 30k 个 Prompts 在 MSCOCO 验证集中评估本文模型。在图 14 中,作者使用 PG Captioner (长) 和原始 Prompts (短)。作者测量了 FID 和 FD Dinov2 中的模型性能,并发现 FD Dinov2是一个对物体形状更敏感的更好指标。作者在不同的训练阶段测量了本文模型,并与 256 和 512 分辨率的 PGv2.5 模型进行了比较。作者还在 1024×1024 分辨率下比较了其他 SoTA 模型。
从图中,本文模型在短 Prompt 和长 Prompt 中都取得了很好的性能,并且在 FD Dinov2 中显示出显著的改进,这表明几何和对象形状要好得多。作者只与 SoTA 开源模型进行比较,因为此评估需要从 PG Captioner 中采样原始标题和标题的 30k 图像。从结果中可以看到 PGv3 在两个标题集上都取得了最好的 FID 和 FD DINOv2。值得注意的是,使用 PG Captioner 字幕,本文的 1024px 模型显着优于 Flux-dev,表明颜色和形状泛化方面图像质量很强。
VAE 重建结果评估
作者将 VAE latent channel 大小从 4 增加到 16,以从低分辨率到更高分辨率的渐进方式训练 VAE。在图 15 中作者报告了在多个分辨率的验证集上的重建性能。从表中,与 SDXL 的 4 通道的 VAE 相比,本文 VAE 性能显着提高,在分辨率为 1024x1024 时,实现了 33.44 的 PSNR。

图15:VAE 重建结果评估
参考
- ^GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
- ^Scalable Diffusion Models with Transformers
- ^abThe llama 3 herd of models
- ^abElucidating the Design Space of Diffusion-Based Generative Models
- ^abHigh-Resolution Image Synthesis with Latent Diffusion Models
- ^Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- ^Learning Transferable Visual Models From Natural Language Supervision
- ^Mars: Mixture of auto-regressive models for fine-grained text-to-image synthesis
- ^Moma: Multimodal llm adapter for fast personalized image generation
- ^Diffusiongpt: Llm-driven text-to-image generation system
- ^Ella: Equip diffusion models with llm for enhanced semantic alignment
- ^Analyzing Individual Neurons in Pre-trained Language Models
- ^Analyzing Transformers in Embedding Space
- ^Scalable Diffusion Models with Transformers
- ^abScaling Rectified Flow Transformers for High-Resolution Image Synthesis
- ^Hunyuan-dit: A powerful multi-resolution diffusion transformer with fine-grained chinese understanding
- ^Pixart-alpha: Fast training of diffusion transformer for photorealistic text-to-image synthesis
- ^U-dits: Downsample tokens in u-shaped diffusion transformers
- ^RoFormer: Enhanced Transformer with Rotary Position Embedding
- ^Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
- ^Flow Matching for Generative Modeling
- ^Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
- ^Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
- ^Analyzing and Improving the Training Dynamics of Diffusion Models
- ^Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation
- ^Improved Baselines with Visual Instruction Tuning
- ^Paligemma: A versatile 3b vlm for transfer
- ^Synth 2 : Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
- ^Vila2: Vila augmented vila
- ^Davidsonian Scene Graph: Improving Reliability in Fine-grained Evaluation for Text-to-Image Generation
- ^ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
- ^https://huggingface.co/datasets/playgroundai/CapsBench
#CAT-Diffusion
高保真目标修复新SOTA!复旦&智象开源CAT-Diffusion,语义视觉双一致
采用级联的Transformer语义修复器与目标修复扩散模型,提出了新型的Cascaded Transformer-Diffusion(CAT-Diffusion)框架。
文章链接:https://arxiv.org/pdf/2409.08260
Github链接:https://github.com/Nnn-s/CATdiffusion
总结速览
解决的问题:
单一U-Net在所有去噪步骤中对齐文本提示和视觉对象不足以生成期望的对象。
扩散模型的复杂采样空间中无法保证对对象生成的可控性。
提出的方案:
- 语义预修复:在多模态特征空间中推理目标对象的语义特征。
- 高保真度的对象生成:在扩散的潜在空间中基于已修复的语义特征生成目标对象。
应用的技术:
- 采用级联的Transformer语义修复器与目标修复扩散模型,提出了新型的Cascaded Transformer-Diffusion(CAT-Diffusion)框架。
- 语义修复器通过上下文和文本提示条件,预测目标对象的语义特征。语义修复器的输出作为视觉提示,经过参考Adapter层来指导高保真对象生成。
达到的效果:
- 在OpenImages-V6和MSCOCO数据集上的广泛评估表明,CAT-Diffusion在文本引导的目标修复任务中优于现有的最新方法。
方法
首先,在文本引导的物体修复中,需要在由输入图像的二值mask指示的指定区域内生成由文本提示(通常是对象标签)描述的新对象。这个任务要求与图像和文本提示分别具有视觉一致性和语义相关性。本节将深入探讨级联Transformer-Diffusion(CAT-Diffusion),在简要回顾扩散模型后,随后介绍训练细节。
级联Transformer-扩散模型
设 、 和 分别为输入图像、描述新目标的文本提示和指示需要修复区域的二值mask。大多数现有的文本引导物体修复扩散模型仅优化文本提示 和期望目标 在潜在空间中的对齐, 这导致了次优结果。为了进一步改进, 需要解决两个主要问题:
- 依赖单独的U-Net在所有去噪时间步中实现视觉-语义对齐是不够的;
- 在复杂的采样空间中稳定生成高保真度对象是具有挑战性的,而没有额外的语义信息。
为了解决这些挑战,研究者们提出将传统的单阶段流程分解为两个级联阶段:首先进行语义预修复,然后进行对象生成,从而形成CAT-Diffusion。技术上,CAT-Diffusion通过一种新颖的语义修复器在辅助的多模态特征空间(例如CLIP)中进行对象预修复。语义修复器通过知识蒸馏进行训练,以预测目标对象的语义特征,条件是未遮罩的视觉上下文和文本提示。这样,得出的输出自然对齐文本提示和视觉对象,除了U-Net之外,无论去噪时间步如何。语义修复器的输出通过参考Adapter层进一步集成到目标修复扩散模型中,以实现可控的目标修复。CAT-Diffusion的整体框架如下图2所示。
语义修复器为了缓解在整个去噪过程中仅依靠单独的U-Net对齐文本提示和视觉对象的不足,提出通过在U-Net之外,利用经过良好预训练的辅助多模态特征空间对目标对象的语义特征进行预修复,以增强视觉-语义对应关系。其原理在于,预训练的多模态特征空间是通过大规模的跨模态数据进行学习的,用于实现视觉-语义对齐,无论去噪时间步如何。在本工作中,设计了一种有效的知识蒸馏目标,将这种多模态知识从教师模型(CLIP)转移到CAT-Diffusion中的语义修复器。
基于Transformer的语义修复器(SemInpainter)参数化为 ,与CAT-Diffusion中的目标修复扩散模型级联, 如上图2的上部所示。首先, 通过CLIP的图像编码器(ImageEnc)提取被遮罩图像 的视觉特征 ,其中 是局部图像块的特征向量。给定被遮罩图像的损坏特征 和文本提示 的文本特征,SemInpainter 旨在预测语义特征 ,以忠实重建CLIP空间中的目标对象。这样, 视觉-语义对齐在扩散模型的整个去噪过程中自然得到实现。整个过程可以表示为

其中 [] 表示拼接操作, 是可学习的位置嵌入, 是可学习的mask嵌入, 指示视觉特征 是否在图像 中被遮罩。SemInpainter 实现为24层的Transformer结构(类似于 CLIP的图像编码器)。最后, 通过将 和 与二值mask 混合, 得到修复后的特征 ,这些特征将随后被整合到目标修复扩散模型中:
![]()
其中 DownSample 是一个无参数的下采样层,用于降低特征分辨率以提高计算效率。
为了强制预测的对象特征与文本提示 对齐,提出将多模态知识从教师模型(在本文中采用CLIP作为教师模型)转移到SemInpainter。技术上,SemInpainter 的训练任务是遮罩特征预测,以恢复CLIP空间中被遮罩对象的真实语义特征, 条件是未遮罩的视觉上下文和文本提示 。
参考Adapter层由于控制扩散模型以实现高保真度的文本到图像生成仍然具有挑战性, 受到 的启发, 语义特征 被用作额外的条件,称为视觉提示,以引导扩散模型在潜在空间中进行可控的修复。具体来说,在基础目标修复扩散模型中引入了一个新的参考Adapter层(RefAdapter),其形式为Transformer 风格的多头交叉注意力层。所提出的RefAdapter 在U-Net的原始自注意力(SelfAttn)和交叉注意力层 (CrossAttn)之间交替插入,如图2的下部所示。设 为U-Net的中间隐藏状态,其中 随不同层的分辨率变化。 是扩散模型中文本编码器提取的提示 的文本特征。首先定义不同类型注意力层的共享模块原型为:
![]()
因此,升级版U-Net中的一个完整块,包括SelfAttn、RefAdapter和CrossAttn,操作如下:

其中将作为下一块的输入。
目标修复扩散模型通过将目标修复流程分解为两个级联过程, CAT-Diffusion能够生成与文本提示语义对齐的高保真度对象。此外,通过利用额外的语义指导(即修复后的视觉特征 ),进一步增强了填补对象与周围图像上下文之间的视觉一致性。
一般来说,参数化为 的U-Net的修复扩散模型以噪声潜在编码 、指示待修复区域的mask 和被遮罩的潜在编码 作为输入,估计从 中需要去除的噪声,从而得到去噪后的 。数学上, 整体过程可以表示为:
![]()
训练
扩散损失
对于配备参考adapter层的目标修复扩散模型的训练,采用 [35] 中的通用实践,目标函数为:

知识蒸馏损失
此外, 为了强制语义修复器预修复与提示 语义对齐的对象特征, 通过知识蒸馏任务中的真实视觉特征 对语义修复器进行监督。优化目标可以表示为:

其中 是配对图像 和文本提示 的训练数据集, 表示前面提出的SemInpainter的可训练参数。
实验
验证级联Transformer-扩散方法(CAT-Diffusion)在文本指导的目标修复任务中的优点,并与最先进的基于扩散的方法进行了比较。大量实验验证了CAT-Diffusion在修复高保真度对象方面的有效性。
实施细节
在OpenImages-V6的训练集中的本地mask与对应对象标签对上训练CAT-Diffusion。CAT-Diffusion通过Adam优化,学习率为0.00001,使用8个A100 GPU进行约40K次迭代。批量大小设置为128,输入图像分辨率设置为512 × 512。
比较方法和评估指标
比较方法将CAT-Diffusion与几种最先进的基于扩散的方法进行了比较,包括Blended Diffusion、Blended Latent Diffusion、GLIDE、SmartBrush、Stable Diffusion 和 Stable Diffusion Inpainting。具体来说,Blended Diffusion、Blended Latent Diffusion 和 Stable Diffusion 仅利用预训练的基础文本到图像模型,通过在每个去噪步骤中混合生成的对象和背景进行文本指导的目标修复。其他方法则使用文本提示、二值mask和被遮罩图像作为输入来训练修复扩散模型。由于相同的评估设置,所有方法的结果均取自 [45],但 [1] 的结果除外。请注意,已将Blended Latent Diffusion中的文本到图像Stable Diffusion 2.1替换为1.5,以确保公平比较。
评估指标所有上述方法都在OpenImages-V6和 MSCOCO的测试集上进行评估,分别涉及13,400和9,311张测试图像。采用三种广泛使用的指标:Frechet Inception Distance (FID)、Local FID 和 CLIP score。值得一提的是,FID 和 Local FID 分别测量修复对象在全局图像和局部补丁中的真实性和视觉一致性,而 CLIP score 估计修复对象与文本提示之间的语义相关性。此外,还涉及用户研究以评估视觉一致性和文本-对象对齐。由于GLIDE仅支持256 × 256分辨率的图像,将所有结果调整为相似大小以确保公平比较。此外,评估中考虑了分割mask和边界框mask。
性能比较
OpenImages-V6上的定量结果下表1总结了所有方法在OpenImages-V6测试集上的结果。总体而言,所有指标的结果一致地展示了CAT-Diffusion在分割mask或边界框mask下的有效性。具体来说,基于混合的方法(即Blended Latent Diffusion 和 Stable Diffusion)在CLIP分数上表现相当,但FID 和 Local FID 分数远低于CAT-Diffusion。推测这是因为这些方法仅关注修复图像与对象标签之间的视觉-语义对齐,并仅在潜在空间中混合生成的对象和背景。因此,周围未遮罩区域的语义上下文被忽视,导致视觉一致性差。SmartBrush通过将被遮罩图像纳入U-Net以进行上下文学习,并进一步使用形状mask指导扩散模型,展现了更好的性能。然而,SmartBrush的FID和Local FID分数仍低于CAT-Diffusion。结果验证了通过参考Adapter层用语义修复器预修复的对象特征来引导扩散模型的影响。
MSCOCO上的定量结果下表2列出了所有方法在MSCOCO测试集上的结果。值得注意的是,SmartBrush 和CAT-Diffusion 都没有在MSCOCO上进行训练。与OpenImages-V6上的趋势类似,CAT-Diffusion 在大多数指标上优于其他方法。具体来说,CAT-Diffusion 在Local FID(使用边界框mask)上相对于强基线 Stable Diffusion Inpainting 和 SmartBrush 分别提高了42.1% 和 20.7%。结果再次验证了在CAT-Diffusion中将单次修复流程分解为两个级联过程(首先进行语义预修复,然后生成对象)的优点。
定性比较通过案例研究对不同方法进行定性测试。下图3展示了几个示例。如前四个结果所示,CAT-Diffusion生成的图像与输入文本提示的语义对齐程度优于其他方法。此外,在图像中,生成对象与周围环境的视觉一致性更好,修复结果中的对象形状也更准确。结果证明了通过提出的语义修复器预修复对象语义特征的优越性。例如,与其他方法生成的图像相比,第一排的CAT-Diffusion生成的男人在结构上更完整。这得益于通过参考Adapter层用预修复的目标对象语义特征引导扩散模型。尽管没有提供形状mask,CAT-Diffusion仍能根据文本提示和边界框mask生成高保真度的对象(中间两排)。此外,还对具有更具描述性文本提示的目标修复进行了评估,不同方法生成的结果显示在底部两排。类似地,CAT-Diffusion生成了视觉上更令人愉悦的图像。
用户研究研究者们进行了一项用户研究,以检查修复图像是否符合人类偏好。在实验中,从OpenImages-V6测试集中随机抽取了1K张图像进行评估。SmartBrush 尚未发布,因此被排除在外。邀请了10名具有不同教育背景的评估员(5名男性和5名女性):艺术设计(4名)、心理学(2名)、计算机科学(2名)和商业(2名)。向所有评估员展示修复图像和相关提示,并要求他们从两个方面给出评分(0∼5):
- 与周围环境的视觉一致性;
- 与文本提示的对齐程度和对象形状的准确性。
下表3总结了不同方法的平均结果。结果表明,在文本-对象对齐和视觉一致性方面,CAT-Diffusion在所有基线方法中遥遥领先。
分析与讨论
CAT-Diffusion的消融研究研究了CAT-Diffusion中各个组件对整体性能的影响。考虑了每个阶段的一个或多个组件,表4总结了使用分割mask的OpenImages-V6测试集上的结果。请注意,第1行的基线是使用[21]中的对象-文本对进行微调的Stable Inpainting模型。通过结合仅使用mask图像的CLIP特征训练的参考Adapter层,第2行的变体在FID和Local FID分数上分别相较于第1行的基线模型提高了0.91和1.47。这并不令人意外,因为未mask区域的CLIP特征通过参考Adapter层为基础扩散模型提供了更丰富的上下文语义,从而改善了视觉一致性并保留了背景。语义修复器的输出进一步提升了模型,通过引入所需对象的语义,获得了第3行在所有指标上的最佳结果。
语义修复器预测的特征随后分析了提出的语义修复器在提高所需对象语义特征方面的程度。值得注意的是,由于CLIP中的自注意机制,mask区域的CLIP特征本身就包含了来自未mask区域的上下文语义,从而在通过语义修复器之前与真实标签具有非平凡的相似性。特别地,计算了语义修复器输入/输出与对应真实标签之间的余弦相似度,在10K张图像上进行分析。下图4(a)展示了这两个分布。平均余弦相似度从0.47提高到0.65,显示了提出的语义修复器的有效性。尽管语义修复器的输出并不是100%准确,但这些语义特征为CAT-Diffusion生成高保真度对象贡献了更丰富的上下文。
修复结果的多样性为了测试CAT-Diffusion在相同语义特征下生成修复结果的多样性,对不同随机种子下的结果进行了研究。上图4(b)展示了两个示例。可以观察到,CAT-Diffusion能够生成具有准确形状的多样化对象,这由参考Adapter层控制。
推理复杂度在推理阶段,只需要对提出的语义修复器进行一次前向传递,并且修复的特征可以在每个去噪步骤中重复使用,从而带来较小的计算开销。CAT-Diffusion每张图像的平均时间为1.84秒,相较于SD-Inpaint的1.60秒稍长。
结论
本文提出了一种新颖的级联Transformer-扩散(CAT-Diffusion)模型,以增强扩散模型在文本引导目标修复中的视觉-语义对齐和可控性。具体而言,CAT-Diffusion将传统的单阶段管道分解为两个级联过程:首先进行语义预修复,然后进行对象生成。通过在多模态特征空间中预修复所需对象的语义特征,然后通过这些特征引导扩散模型进行对象生成,CAT-Diffusion能够生成与提示语义一致且与背景视觉一致的高保真度对象。
从技术上讲,基于Transformer的语义修复器在给定未mask的上下文和提示的情况下预测所需对象的语义特征。然后,来自语义修复器的修复特征通过参考Adapter层进一步输入到目标修复扩散模型中,以实现受控生成。在OpenImages-V6和MSCOCO上的广泛实验验证了CAT-Diffusion的有效性。
广泛影响最近生成模型(如扩散模型)的进展开启了创造性媒体生成的新领域。然而,这些创新也可能被滥用于生成欺骗性内容。本文的方法可能被利用来在图像中修复有害内容,用于传播虚假信息,对此类行为坚决反对。
#深度学习工厂自动化项目实施入门指南
传统的或“基于规则”的机器视觉技术,能够可靠地检测一致且制造良好的元件,并擅长于解决高精度应用,这些应用包括引导、识别、测量和检测,所有这些应用都能以超快的速度和高精度执行。这类机器视觉对于已知的变量非常有用:元件是存在还是缺失?这个物体与那个物体之间究竟相距多远?这个机器人需要在哪里拾取这个元件?这些任务易于部署在受控环境中的装配线上。
但是,当情况不那么明确时,传统机器视觉就没那么胜任了。这时候,将深度学习技术与传统机器视觉技术结合使用,能带来更好的效果。深度学习技术使用基于示例的训练和神经网络来分析缺陷、定位和分类物体以及读取印刷标识。该技术基于一组带标记的示例教会神经网络什么是合格的图像,考虑到一些预期的变化,它将能够区分合格元件与缺陷元件。
然而,工厂管理者有理由犹豫,不愿意冒险用他们现有的合格流程来换取一项新技术可能带来的潜在回报。如果工厂管理者引进新技术,进而提高效率,公司将会受益;但是如果他们引进了新技术,反而导致生产线速度减慢,负面影响将是巨大的。然而,将深度学习技术成功整合到自动化战略中,不仅可以节省成本、改进内部低效流程,并使采用基于规则的视觉工具无法解决的复杂检测应用实现自动化,还有助于提高生产量。
以下考虑因素可以帮助刚刚接触深度学习技术的工厂和制造商,避免因前期失误而造成高昂的代价和时间浪费,同时获得组织支持以实现该深度学习技术的可观优势。如果实施得当,第一个项目的成功将可以促进在全公司范围内展开更进一步的战略部署。
在部署首个深度学习试点项目之前,需要考虑以下五个方面:
● 设定适当的期望
● 了解投资回报率
● 资源规划和需求
● 从小型试点项目着手
● 采用分阶段项目方法
(1)设定适当的期望
深度学习技术利用神经网络从图像库中对应用程序进行训练,以识别合格元件与不合格元件。深度学习项目可以将像人类一样的判断力优势,与可编程机器视觉应用程序的规模和依赖性结合起来。
然而,与任何新技术一样,深度学习技术也存在考虑因素和权衡取舍。虽然深度学习机器视觉有望解决许多复杂的工厂应用,但它绝不是万能的解决方案。这就是为什么对“深度学习技术可以做些什么”设定适当的期望,对任何项目而言都很重要的原因。事先了解一些权衡取舍是其中的关键。
经过良好训练的深度学习应用程序,需要一组全面的训练图像,这些图像代表一系列缺陷和/或可接受的元件变化,以确保在生产中可靠地执行检测。此外,这些图像需要在有照明和元件演示条件下采集。这对任何深度学习项目的成功至关重要。

图1:采集到的缺陷图像。
此外,在采集图像之后,还需要对图像进行适当分级和标记。换句话说,在任何项目中,质量专家都需要从一开始就参与到项目中。

图2:对图像进行分级和标记。
在图2的示例中,分级是指针对每个元件做出的总体“合格/不合格”决定;而 “标记”则是图像中特定缺陷像素的标识。
最后,在系统开发完成之后,在进入生产环境之前需要对其进行测试。有时,深度学习系统在实验室表现良好,但当部署到生产环境中后却难以发挥作用。通常,用户的挫折感来自于未充分理解深度学习解决方案与基于规则的传统机器视觉系统之间的差异。
论证深度学习视觉解决方案的适用性涉及一个迭代过程,需要将此系统安装到生产线上进行测试。而且,不同于传统机器视觉系统的是,深度学习系统的图像训练和验证必须在开发阶段完成 ,不能等到工厂验收测试环节时进行。深度学习系统需要大量图像样本进行训练,这可能需要时间来采集必要的代表性图像集合,以对深度学习工具进行训练,从而确保工具性能的可靠性。
(2)了解投资回报率
深度学习技术能够为我做些什么?这可能是任何公司或工厂管理者提出的最关键的问题。这个问题的真正含义在于投资回报率将是多少。深度学习系统的成本并不便宜,因此进行这样的投入必须能够带来切实的益处。
通常,我们可以通过降低成本并维持与当前方法相似的成品率、或者显著提高成品率并保持成本不变,来实现实际的项目回报。此外,处理量也是影响投资回报率的因素之一,尤其是在与人工检测流程进行比较时。
另一种考虑投资回报率的方式,是从直接投资回报率和间接投资回报率的角度入手。
直接投资回报率很简单直接,因为您只需要将深度学习解决方案的成本与现有方法的成本进行比较即可。这包括软件和硬件成本、开发时间和成本、图像采集成本、人工成本和训练等所有方面。
除了简单的成本回收分析之外,间接投资回报率还衡量所有额外的益处。即使项目管理者无法确定间接益处所产生的精确货币数字,但它们也是重要的考虑因素。可追溯性、持续改进、上游流程控制和分析,都是目前正在进行的工厂自动化和数字化转变所必需的。
(3)资源规划和需求
对于任何深度学习项目而言,都有四项核心工作需要完成。虽然一名员工可以承担多个角色,但事先了解所需的专家类型将带来更多助力。举例来说,虽然深度学习技术基于神经网络,但在工厂自动化设置中,并不需要真正的神经网络专家。相反,一名对深度学习技术的原理拥有基本了解的机器视觉专家就足够了。
以下是深度学习系统部署所需的必备技能组合:
◆ 视觉开发人员
开发人员负责实施深度学习视觉解决方案以及优化光源和成像。
◆ 质量专家
质量专家负责分析图像并对它们进行分级,这是指确定图像中元件的整体基本事实:通过/未通过、缺陷类型等。我们不能低估图像分级的重要性,因为深度学习系统基于示例的学习方法,依靠清晰且分级一致的图像对系统进行训练。
◆ 图像标记人员
标记是表明图像中的哪些区域定义缺陷或感兴趣特征的交互过程。标记是一个注重细节的精确过程,需要在训练图像集合中的每个图像上准确一致地完成。随着项目累积较大量的图像集合,可能需要在质量专家之外单独分配一名人员来执行此角色。
◆ 数据收集人员
数据收集人员需要记录和组织所有这些信息,包括图像、分级、标记和元数据。深度学习系统的优化将涉及基于这些不同的数据集合对其进行测试。如果目前 采用人工检测程序,则数据收集人员可能还需要记录人工检测员的决策,以将其与某些图像集合相关联。
除了这些角色之外,任何深度学习检测计划都不需要安装基于Windows的强大PC系统及图形处理单元(GPU)。
(4)从小型试点项目着手
在兴奋地应用新技术的过程中,从清单上最具难度的挑战开启应用旅程,对于很多人而言可能非常具有吸引力。许多自动化管理者可能会认为,如果深度学 习系统可以解决这个问题,那么它将可以解决任何问题。然而,这只会导致企业走上挫折和延误的道路,而原因与深度学习技术无关。
最具难度的挑战可能本质上过于复杂或者不稳定;如果项目未能展现出较快的进度和投资回报率,其可能会被取消;或者更糟糕的是,即使其最终取得了成功,它也可能引导企业得出错误的结论。
相反,很重要的一点是必须从小型项目入手。选择一个具有明确回报的项目,该项目无法通过基于规则的传统视觉系统轻松解决,但也并非特别棘手以致难以在生产环境下实施。关注核心需求,培养核心竞争力,并了解深度学习系统在工厂自动化环境中能够做些什么和不能做什么。
深度学习试点项目应当具有两个主要目标:评估其更广泛的实用性,以实现更全面的自动化战略,并使根本无法完成或通过人工完成的检测或验证流程,实现自动化。
那么,如何确定首个合适的项目进行部署呢?当然,这对每家公司而言都是独一无二的。然而,在大多数制造环境中,最合适的两个入门项目通常位于生产线末端以进行最终检测,或者是线上装配验证,以识别制造环节之间的问题。这两个应用适合作为首个试点项目,因为传统机器视觉系统在“需要识别的潜在缺陷范围较大”以及“存在照明、透视和元件外观变化”的情况下,难以解决这些应用。
深度学习技术是经论证能够解决这些变化的唯一视觉系统。通常,这些类型的检测也已经建立了明确的检测标准,从而消除了在实施自动化解决方案之前创建和进一步明确质量指标的需要。
(5)采用分阶段项目方法
深度学习项目可以分为以下四个阶段:
◆ 原型设计
● 了解当前流程,并确定深度学习系统是否是解决该应用的良好选择
● 采集较小的已分级和标记图像数据库
● 建立概念验证系统以测试此 方法
◆ 图像数据收集
● 将相机和光源系统集成到生产线上
● 开始收集和整理图像数据和人工检测结果
● 建立基本事实数据
● 优化并以一致的方式标记图像集合
◆ 优化
● 这将是持续时间最长的阶段:改进深度学习解决方案,直至其实现性能目标
● 将深度学习检测结果与基本事实数据和人工检测结果进行比较
● 调整系统,必要时重新进行训练
◆ 验证和部署
● 论证此解决方案的适用性,并开始将其运用到生产中
● 通过工厂验收测试,并锁定配置
● 集成到生产环境中,并扩展至其他生产线
● 做好应对未来变化的准备,并建立持续监控和改进流程
采用深度学习系统取得成功
通过以明智的分阶段方法实施可管理的小型试点项目,自动化团队可以通过深度学习图像分析技术,使自己和公司为取得长期成功做好准备。虽然基于规则的传统机器视觉应用经验,为深度学习技术的实施提供了坚实的基础,但这两种技术在范围、执行、要求和用例方面存在显著差异。
然而,通过从切合实际的期望着手、积累经验并了解哪些应用更适合通过深度学习系统来解决,制造公司将开始了解深度学习技术能够为工厂自动化战略增添的力量。
#GrootVL
Mamba涨点神器!树形SSM来了!清华和腾讯提出:多功能多模态框架
由清华大学和腾讯提出了一个新型多功能多模态框架GrootVL,通过动态生成树形拓扑结构来优化状态空间模型的特征传播,显著提升了视觉和文本任务的性能。
GrootVL: Tree Topology is All You Need in State Space Model
论文:https://arxiv.org/pdf/2406.02395
代码(已开源):https://github.com/EasonXiao-888/GrootVL
使用递归范式传播特征的状态空间模型展示了与 Transformer 模型相当的强大表征能力和卓越的推理效率。然而,受序列固有几何约束的限制,它在建模远程依赖方面稍显不足。为了解决这个问题,我们提出了 GrootVL 网络,它首先基于空间关系和输入特征动态生成树形拓扑结构。然后,基于该无环图执行特征传播,从而打破原始序列约束以实现更强的表征能力。此外,我们引入了一种线性复杂的度动态规划算法,在不增加计算成本的情况下增强远程交互。GrootVL 是一个多功能的多模态框架,可以应用于视觉和文本任务。大量实验表明,我们的方法在图像分类、目标检测和分割方面明显优于现有的结构化状态空间模型。此外,通过微调大语言模型,我们的方法在较小的训练成本下在多个文本任务中取得了一致的性能提升。
1 回顾状态空间模型
主流基础模型主要基于 CNN和 Transformer 架构,它们在视觉和语言任务中占主导地位。然而,CNN 的小感受野和 Transformer 的高度复杂性给平衡性能和效率带来挑战。状态空间模型(SSM)试图打破这种僵局,它以循环范式对序列进行建模。与之前的循环神经网络不同,这些方法利用结构参数初始化实现稳定的优化和优越的计算性能。然而,它仍然容易受到循环神经网络共有的内在缺陷的影响,即捕获远程依赖的缺陷。
最近,Mamba[1]提出了一种改进的选择机制来减轻SSM遇到的挑战。这种方法在传播过程中引入了权重调制,扩大了有效感受野,并在 NLP 任务中取得了令人印象深刻的效果。此外,许多研究[2][3][4]旨在通过使用各种人工预定义的策略将 2D 图像特征映射到 1D 序列,从而将 Mamba 扩展到计算机视觉中。

图1 视觉和文本信号的不同传播策略的比较。对于视觉任务,之前的策略 (a) 基于固定模式,而我们的方法可以根据输入特征自适应地生成传播拓扑路径。对于文本任务,与之前的方法 (c) 相比,我们的方法 (d) 可以打破文本序列的固有约束,促进远程信息的有效传输。
尽管这些方法成功地将 Mamba 嵌入视觉信号输入,但如图1(a)所示,光栅扫描和局部扫描策略都引入了相邻像素之间的空间不连续,但Mamba中的特征变换依赖于特征关系,因此这种扫描范式会阻碍序列中有效的信息流。此外,连续扫描策略试图通过简单地调整不连续位置的传播方向来缓解这个问题。然而,所有这些方法都依赖于固定的传播轨迹,忽略了固有的空间结构,不能根据输入动态调整拓扑。
2 基于自适应树形拓扑结构的状态空间模型(Tree SSM)
本文试图探索一个新的视角:为状态空间模型中的特征传播引入输入感知的拓扑网络。为了实现这一点,我们开发了一个树状态空间模型如图2所示,并提出了一个称为 GrootVL 的新框架,该框架根据输入特征自适应地生成树拓扑结构,然后在其上执行特征传播。具体来说,我们分别为视觉和语言任务设计了两个子网络 GrootV 和 GrootL,如图 1(b) 和图 1(d) 所示。对于视觉任务,我们首先基于相邻特征之间的差异在四连通平面图上构造一个最小生成树。这个过程可以自适应地将空间和语义信息编码到树结构中。然后,我们迭代地遍历每个像素,将其视为根顶点,并使用 Mamba 的状态转移方式聚合其他像素的特征。直观地说,此操作需要对整个像素集进行两级遍历,导致相对于视觉像素级输入信号不可接受的二次复杂度。然而,鉴于树图是非循环的,我们提出了一种动态规划算法来实现线性复杂度的传播。通过这种输入感知树拓扑,我们的方法能够实现更有效的远程交互,并保持与 Mamba 一致的线性复杂度。此外,我们的方法还可以通过基于标记特征之间的差异构建树结构来应用于语言任务,这克服了文本序列的几何约束。使用与 GrootV 类似的聚合过程,GrootL 可以显着提高预训练大语言模型的语言表征能力。
2.1 树拓扑扫描算法
具体来说,对于输入特征 ,其中 是序列长度(或输入像素的数量)。我们为该特征构建一个无向 连通图 。其中, 是一个超参数,表示邻节点的数量。在视觉任务中 预设为 4 , 表示每个像素都与其四个相邻像素相连。对于语言任务, 我们默认设置 , 表示每个标记都与前三个标记相连。此外,顶点 表示像素(或标记)嵌入集, 表示图的边集。边权重由相邻顶点之间的特征相异性计算得出。此外,顶点之间的距离度量默认使用余弦距离。我们使用收缩Boruvka算法来修剪具有显著差异的边,从而获得一个最小生成树 (MST),其差异权重之和在所有生成树中最小。在传播过程中,我们迭代遍历每个顶点,将其视为根,并聚合剩余顶点的特征。直观地讲,在这样的几何配置中应用状态传播会优先在空间和特征距离较小的顶点之间进行交互。参考Mamba,我们使用与数据相关的转换矩阵进行状态传播。对于顶点 ,我们对其向父节点的转换矩阵表示为 。因此,第 个顶点的状态聚合过程可以表示为:

其中 表示树中所有顶点的索引集。 表示超边 从MST中第 个顶点到第 个顶点的路径权重, 表示此超边上所有顶点的索引集。对于视觉任务, 我们迭代每个顶点, 将其视为生成树的根, 并聚合来自其他顶点的状态, 从而获得变换后的状态 。对于文本任务, 由于大型语言模型中的因果预测范式, 我们仅将最后一个标记作为根, 并从其他标记中进行聚合。为了实现端到端训练, 我们推导出输出隐藏状态 对输入变量 和 的导数, 如下所示:

其中 表示以顶点 为根且为顶点 的子孙节点集合, 顶点为 的父节点。最后, 输出特征 可以表示为:

其中 、 和 分别表示 、 和 代表元素乘法(哈达玛积)。

图2 树状态空间模型示意图。
2.2 适应于视觉和文本信号的高效部署
对于视觉任务, 树扫描算法需要对整个像素集进行两级遍历, 导致相对于像素数量不可接受的二次复杂度 。为了缓解这个问题,我们利用动态规划过程来加速推理和训练过程,如算法1(图 3)所示,其实现了线性复杂度 的传播,从而在保持计算效率的同时,实现更有效的远距离建模以及空间感知。对于文本任务,我们按照语言的因果性质执行单向聚合方法如算法2(图4)所示。此外, 我们为视觉树扫描和语言树扫描过程提供了反向传播过程以进行端到端的训练, 其详细证明见论文附录C。

图3 视觉树拓扑扫描算法

图4 文本树拓扑扫描算法
2.3 子网络架构设计
基于上述基础算子,我们可以将其有效应用于各类视觉和文本任务。
GrootV. 对于一个形状为的输入图像信号,我们的目标是为下游任务获得其高质量的视觉特征。为此,我们提出了一种有效的视觉架构 GrootV 如图5所示,它由Stem module、Basic Block和Downsample Layer组成。我们在三个尺度上开发了GrootV,即GrootV-Tiny、GrootV-Small和GrootV-Base。

图5 GrootV框架示意图。
GrootL. 我们基于树扫描算法提出了一种有效的应用于预训练Mamba的微调范式。具体来说,基于树的拓扑分支与单向滚动通过调制因子来合并。值得注意的是,这种范式不会引入任何额外的训练参数。相反,它利用预训练的状态转换参数通过结合拓扑结构以进行语义聚合。实验结果表明了我们方法的有效性。
3 实验结果与分析
3.1 视觉任务
我们在图像分类,目标检测,实例分割与语义分割下游视觉任务上进行验证。如图6、7、8中结果所示,我们的方法显著优于各类基于状态空间模型的方法,并能与最先进的基于CNN或者Transformer架构的方法相媲美。

图6 ImageNet-1K验证集上的图像分类结果。T、C 和 S 分别表示 Transformer、CNN 和 SSM 的模型类型。所有模型都以的图像尺寸作为输入。

图7 COCO val2017数据集的结果。

图8 ADE20K val数据集结果。输入图片都剪裁为。SS和MS分别表示单尺度和多尺度测试。
3.2 文本任务
我们将130M参数量的 Mamba作为基础模型。为了验证我们的 GrootL 在自然语言理解中的有效性,我们首先用相同的训练设置在Alpaca 数据上分别通过LoRA 和 GrootL对预训练Mamba进行微调。接着在公开lm-evaluation-harness项目中对多个NLP benchmark进行zero-shot验证,结果如图9所示。

图9 文本下游任务验证结果。
3.3 消融实验
我们对树拓扑算法中多个配置进行消融实验。我们首先验证了树拓扑扫描相对于人工预设的光栅扫描和交叉扫描方式的优越性。接着,我们探索了相邻节点间边权重的刻画方式,尝试了曼哈顿距离,欧式距离和余弦距离三种方式。最后,我们仅针对单个节点进行状态聚合进行了实验从而验证了每个节点均需获取来自其余顶点信息的必要性。

图10 消融实验
3.4 定性分析
为了更好地说明我们的扫描策略的优越性,我们可视化了每个输入图像中红色十字标记的不同位置的亲和图。例如,当我们设置天空左上角的锚点,如图11(a)第二行所示。我们的方法可以很容易地识别白色房屋、旗杆和天空,光栅扫描则无法实现。这证明了我们的算法具有保留详细结构信息的能力。更多的对比结果可见于论文的附录D中。

图11 特定位置的Affinity Map,位置由输入信号中的红色十字标记。TP Scan代表树拓扑扫描算法与光栅扫描 (c) 相比,它能准确捕获更详细的结构信息。
#SEED-Voken
codebook从崩溃到高效利用!南大&清华&腾讯联合打造IBQ:自回归生成最强视觉分词器
南京大学、清华大学和腾讯联合研发的IBQ技术,一种用于训练可扩展视觉分词器的向量量化方法。文章详细阐述了IBQ如何通过全代码更新策略解决传统向量量化方法在扩展性上的困难,并展示了IBQ在重建和自回归视觉生成方面的优异性能。
论文链接:https://arxiv.org/pdf/2412.02692
github链接:https://github.com/TencentARC/SEED-Voken
亮点直击
- 提出了一种简单而有效的向量量化方法,称为索引反向传播量化(Index Backpropagation Quantization,IBQ),用于训练可扩展的视觉分词器。
- 通过增加码本大小、编码维度和模型规模来研究IBQ的扩展特性。IBQ首次训练了一个超大码本(),具有大维度(256)和高使用率,实现了最先进的重建性能。
- 展示了一系列从300M到2.1B的基础自回归图像生成模型,显著超越了竞争方法,例如LlamaGen和 Open-MAGVIT2。
总结速览解决的问题
现有的向量量化(VQ)方法在可扩展性方面存在困难,主要由于训练过程中仅部分更新的码本的不稳定性。随着利用率的降低,码本容易崩溃,因为未激活代码与视觉特征之间的分布差距逐渐扩大。
提出的方案
提出了一种新的向量量化方法,称为索引反向传播量化(Index Backpropagation Quantization,IBQ),用于码本embedding和视觉编码器的联合优化。通过在编码特征与码本之间的单热编码分类分布上应用直通估计器,确保所有代码都是可微的,并与视觉编码器保持一致的潜空间。
应用的技术
- 使用直通估计器在单热编码分类分布上进行优化,使得所有代码可微。
- 通过IBQ实现码本embedding和视觉编码器的联合优化。
- 研究了IBQ在增加码本大小、编码维度和模型规模方面的扩展特性。
达到的效果
- IBQ使得视觉分词器的可扩展训练成为可能,首次实现了大规模码本()的高维度(256)和高利用率。
- 在标准ImageNet基准上的实验表明,IBQ在重建(1.00 rFID)和自回归视觉生成方面取得了具有竞争力的结果。
- 展示了一系列从300M到2.1B的基础自回归图像生成模型,显著超越了竞争方法,如LlamaGen和Open-MAGVIT2。
效果展示
- 下图的上半部分展示了在1024×1024分辨率下,IBQ分词器在Unsplash数据集上的测试结果。下半部分则展示了IBQ分词器在256×256分辨率下,针对Imagenet数据集的测试结果。(a)表示原始图像,(b)表示重建图像。
- Imagenet上256×256类条件生成样本效果:
方法
我们的框架由两个阶段组成。第一阶段是通过索引反向传播量化学习一个具有高码本利用率的可扩展视觉分词器。在第二阶段,我们使用自回归变换器通过下一个标记预测进行视觉生成。
Preliminary
向量量化 ( VQ 将连续的视觉信号映射为具有固定大小码本 的离散标记, 其中 是码本的大小, 是代码维度。给定一张图像 首先利用编码器将图像投影到特征图 , 其中 是下采样比例。然后, 特征图被量化为 , 作为码本的离散表示。最后, 解码器根据量化后的特征重建图像。
对于量化,以往的方法通常计算每个视觉特征 与码本中所有代码的欧几里得距离,然后选择最近的代码作为其离散表示。由于量化中的 操作是不可微的, 他们在选定的代码上应用直通估计器, 以从解码器复制梯度, 从而同时优化编码器。量化过程如下:
其中,是停止梯度操作。
这些方法采用的部分更新策略(即仅优化选定的代码)逐渐扩大了视觉特征与未激活代码之间的分布差距。这会导致训练期间的不稳定性,因为码本崩溃会阻碍视觉分词器的可扩展性。
索引反向传播量化
量化。 为了确保在训练过程中码本与编码特征之间的一致分布,我们引入了一种全代码更新方法,即索引反向传播量化(Index Backpropagation Quantization, IBQ)。IBQ的核心在于将梯度反向传播到码本的所有代码,而不仅仅是选定的代码。算法1提供了IBQ的伪代码。
具体来说,我们首先对给定的视觉特征与所有代码embedding进行点积运算作为logits,并通过softmax函数获得概率(soft one-hot)。
然后我们将soft one-hot 类别分布的梯度复制到hard one-hot索引上:

给定索引,量化后的特征通过以下方式获得:

通过这种方式,我们可以通过索引将梯度传递到码本的所有代码上。通过索引反向传播量化,整个码本和编码特征的分布在整个训练过程中保持一致,从而获得较高的码本利用率。
训练损失。 与 VQGAN类似,分词器的优化由多种损失的组合完成:
![]()
其中, 是图像像素的重建损失, 是选定的代码embedding与编码特征之间的量化损失, 是来自 LPIPS 的感知损失, 是使用 PatchGAN 判别器 [10] 增强图像质量的对抗损失, 是鼓励码本利用的熵惩罚。我们进一步引入双重量化损失, 以迫使选定的代码embedding和给定的编码视觉特征相互靠近。
与其他 VQ 方法的讨论。 向量量化(VQ)将连续的视觉特征离散化为具有固定大小码本的量化代码。朴素的 VQ 选择与给定视觉特征具有最近欧氏距离的代码。由于操作是不可微的,梯度流回到编码器时被截断,只有解码器的参数和选定的代码可以被更新。受直通梯度估计器的启发,VQ-VAE 和 VQGAN 将梯度从解码器复制到编码器进行梯度近似。它们还采用量化损失来优化选定代码以接近编码特征。因此,VQ 模型可以以端到端的方式进行训练。尽管已经取得了进展,这些 VQ 方法在扩展分词器以提高表示能力方面仍然存在困难。
如下图 3 所示,现有的 VQ 方法在每次反向过程中仅优化有限数量的代码以接近编码特征。这逐渐扩大了未激活代码和编码特征之间的分布差距,最终导致码本崩溃。随着代码维度和码本大小的增加,这种情况变得更加严重。我们不是直接将直通估计器 [1] 应用于选定的代码,而是将这种参数化方法应用于视觉特征和所有码本embedding之间的分类分布,以使梯度能够反向传播到所有代码。通过这种方式,整个码本和编码特征之间的分布在整个训练过程中保持一致。因此,IBQ 实现了具有高代码维度和利用率的极大码本。
自回归Transformer
在经过分词后, 视觉特征被量化为离散表示, 并随后以光栅扫描的方式展平以进行视觉生成。给定离散的token索引序列 , 其中 ,我们利用自回归transformer通过下一个token预测来建模序列依赖性。具体来说, 优化过程是最大化对数似然:

其中, 是条件, 例如类别标签。请注意, 由于我们专注于视觉分词器, 因此我们采用类似于 Llama 的自回归transformer的基础架构,并使用 AdaLN 进行视觉生成。
实验
数据集和指标
视觉分词器和自回归transformer的训练均在256×256的ImageNet上进行。对于视觉重建,采用重建-FID(记为rFID)、码本利用率和LPIPS在ImageNet 50k验证集上来衡量重建图像的质量。对于视觉生成,我们通过常用的指标FID、IS和Precision/Recall来衡量图像生成的质量。
实验细节
视觉重建设置。 我们采用了VQGAN中提出的相同模型架构。视觉分词器的训练设置如下:初始学习率为 , 采用 0.01 的多步衰减机制, 使用Adam优化器, 其参数为 , 总批量大小为 256,共330个epoch,训练过程中结合了重建损失、GAN损失、感知损失、承诺损失、摘损失、双量化损失,以及LeCAM正则化以确保训练稳定性。未特别说明时,我们默认使用 16,384 的码本大小、256的代码维度和 4 个ResBlock作为我们的分词器默认设置。
视觉生成设置。 预期简单的自回归视觉生成方法可以很好地展示我们视觉分词器设计的有效性。具体而言,我们采用基于Llama的架构,其中结合了RoPE、SwiGLU和RMSNorm 技术。我们进一步引入 AdaLN以提升视觉合成质量。类别embedding同时作为起始标记和AdaLN的条件。IBQ的宽度 、深度 和头数 遵循[24,25]中提出的缩放规则, 其公式为:

所有模型的训练设置相似:基础学习率为 , 针对每 256 的批量大小, 使用AdamW优化器 [15], 其参数为 , 权重衰减为 , 总批量大小为 768 , 训练 300 到 450 个epoch, 具体取决于模型大小,梯度裁剪为 1.0 ,输入embedding、FFN模块和条件embedding的dropout率为 0.1 。
主要结果
视觉重建。 下表1展示了IBQ与常见视觉分词器的定量重建比较。可以看到,当码本规模扩大时,现有VQ方法的码本使用率显著下降(例如,VQGAN 在1024码本规模下的使用率为44%,而在16,384码本规模下的使用率为5.9%),以及代码维度(例如,LlamaGen 在8维代码下的使用率为97%,而在256维代码下的使用率为0.29%)。因此,实际的表示能力受到码本崩溃的限制。
相比之下,对所有码本embedding和视觉编码器的联合优化确保了它们之间的一致分布,有助于稳定训练具有高利用率的大规模码本和embedding视觉分词器。具体来说,IBQ在16,384码本规模和256代码维度下实现了1.37的rFID,超过了在相同下采样率和码本规模下的其他VQ方法。通过将码本规模增加到262,144,IBQ超越了Open-MAGVIT2,实现了最先进的重建性能(1.00 rFID)。我们还在下图4中与几种具有代表性的VQ方法进行了定性比较。IBQ在复杂场景如面部和字符上表现出更好的视觉合理性。
视觉生成。 在下表7中,我们将IBQ与其他生成模型进行比较,包括扩散模型、AR模型以及AR模型的变体(VAR和MAR)在类别条件图像生成任务上的表现。借助IBQ强大的视觉分词器,我们的模型在扩大模型规模时(从300M到2.1B)表现出持续的改进,并在不同规模的模型下超越了所有之前的基础自回归模型。此外,IBQ优于基于扩散的模型DiT,并在AR模型变体中取得了可比的结果。这些AR模型变体专注于第二阶段transformer的架构设计,而我们的工作则致力于第一阶段更好的视觉分词器。因此,我们相信,借助我们更强大的分词器,AR模型及其变体可以进一步提升。
扩大 IBQ
现有的 VQ 方法在扩展时因码本崩溃而遇到困难。例如,当将 LlamaGen的代码维度从 8 增加到 256 时,其使用率和 rFID 显著下降(97% → 0.29%,2.19 rFID → 9.21 rFID),如上表 1 所示。这是由于训练期间的部分更新逐渐扩大了未激活代码与编码特征之间的分布差距。IBQ 在三个方面显示出有希望的扩展能力:
- 码本大小:如下表 4 所示,随着码本大小从 1024 扩大到 16,384,重建质量显著提高。此外,IBQ 即使在使用 262,144 个代码进行训练时,也能实现高码本利用率和视觉效果的一致提升。
- 模型大小:下表 6 显示,通过在编码器和解码器中扩展 ResBlock 的数量,可以保证重建性能的提升。
- 代码维度:有趣的是,观察到在扩展代码维度时,码本使用率显著增加。我们假设低维代码辨别力较弱,类似的代码往往会聚集在一起。这表明在我们的全局更新策略下,具有代表性的代码更有可能被选择。相比之下,高维embedding的代码在表示空间中是高度信息化的,因为它们在表示空间中是相互稀疏的。因此,这些代码在训练过程中可以被均匀选择,从而确保高利用率和更好的性能。通过以上因素,我们实现了一个拥有 262,144 个码本大小和 256 维度的超大码本,并且具有高码本使用率(84%),实现了最先进的重建性能(1.00 rFID)。为了更好地说明扩展特性,我们还在下图 5 中提供了可视化。
消融实验
关键设计。 为了验证我们方法的有效性,对几个关键设计进行了消融研究,如下表2所示。重新实现的VQGAN性能为3.98 rFID,码本利用率为5.3%。与之前的方法不同,将VQ替换为IBQ后,通过使所有代码可微分,实现了编码特征与整个码本之间的一致分布,从而显著提高了码本的使用率(从5.3%提高到98%)和重建质量(从3.98 rFID提高到1.67 rFID)。通过引入双重量化损失来迫使选择的代码embedding和编码视觉特征相互靠近,IBQ保证了更精确的量化。按照MAGVIT-v2 的做法,我们扩大了模型规模以提高紧凑性,重建性能也相应得到了改善。
与LFQ的比较。 为了进行公平的比较,采用了具有16,384个代码的LFQ,并用我们的基础Transformer架构替换了其不对称的token分解。我们在下表5中比较了LFQ在重建和生成方面的表现,我们提出的IBQ表现更好,这表明增加代码维度可以提高视觉tokenizer的重建能力,并进一步提升视觉生成。
结论
在本文中,我们识别出了当前向量量化(VQ)方法中部分更新策略导致的tokenizer扩展瓶颈,这种策略逐渐加大了编码特征与未激活代码之间的分布差距,最终导致码本崩溃。为了解决这一挑战,提出了一种简单而有效的向量量化方法,称为索引反向传播量化(IBQ),用于可扩展的tokenizer训练。该方法通过在视觉特征与所有码本embedding之间的分类分布上应用直通估计器来更新所有代码,从而保持整个码本与编码特征之间的一致分布。ImageNet上的实验表明,IBQ实现了高利用率的大规模视觉tokenizer,在重建(1.00 rFID)和生成(2.05 gFID)方面的性能有所提高,验证了我们方法的可扩展性和有效性。