灵感来源
看到很多大佬在发这个,打开一看是个小光子,付费课程,所以我觉得写一个简单的免费教程。

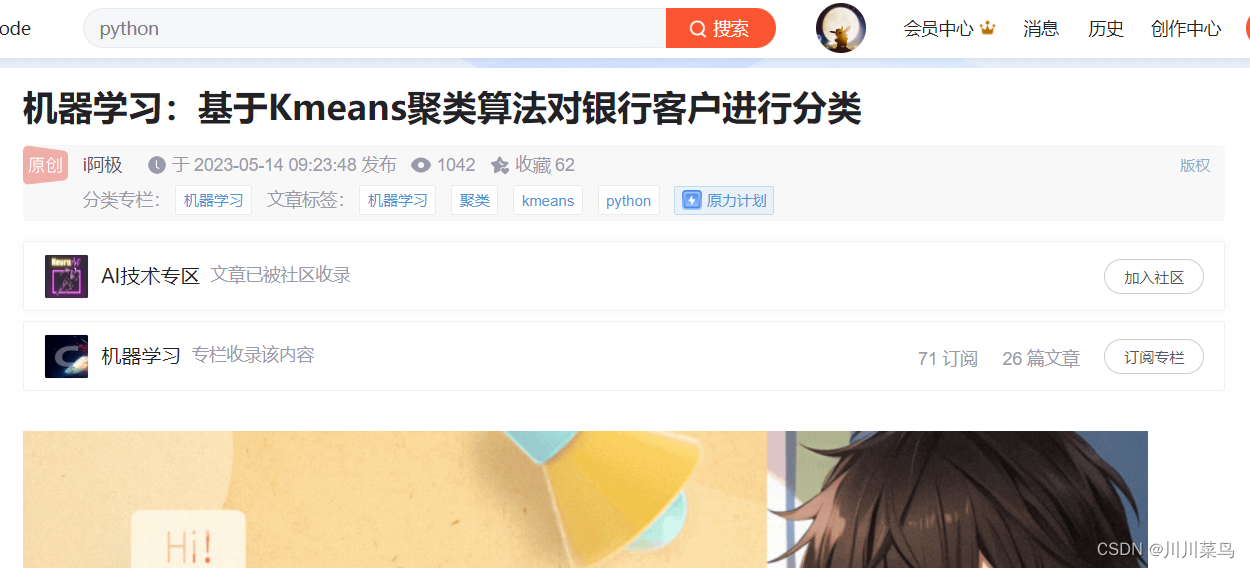
简单示例
我们用一个简单的来介绍,比如爬取这位博主:
https://blog.csdn.net/AOAIYI/article/details/130659496
定义目标
下面我用自己的4.0镜像来做尝试:GPT4.0 ,如下进行提问:
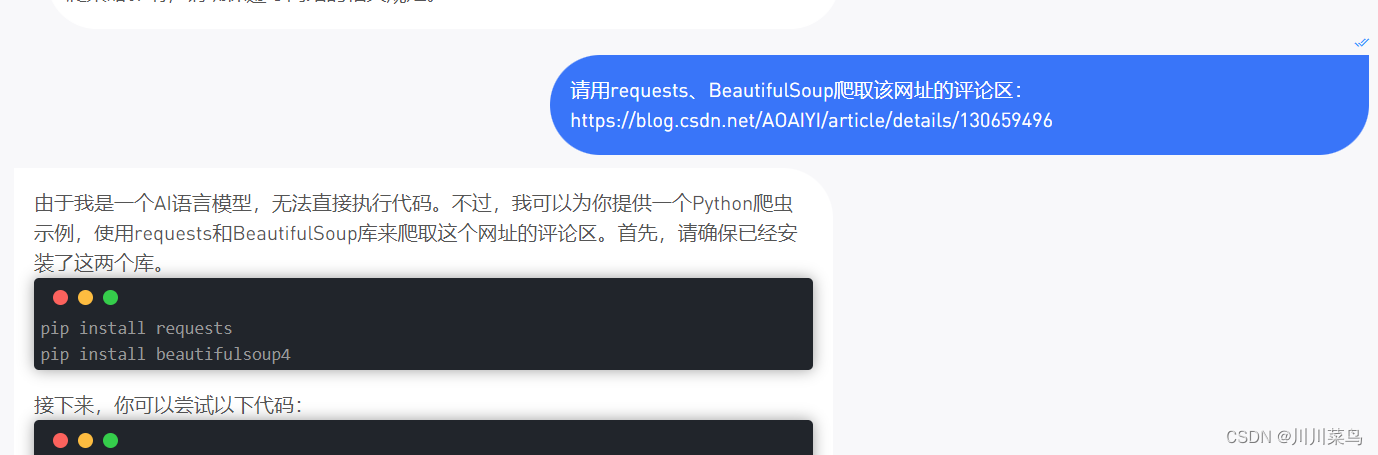
这样第一次问,当然是抓取不对的。GPT实际上不具备爬取功能,但是我要给他赋予爬虫技能,接下来就是给他更详细的星系。
灌输详细内容
手动打开检查,把重要的HTML部分灌输给GPT4:

返回大致如下,可以看到代码中让我自己粘贴进去,这显然不符合正常爬虫操作。
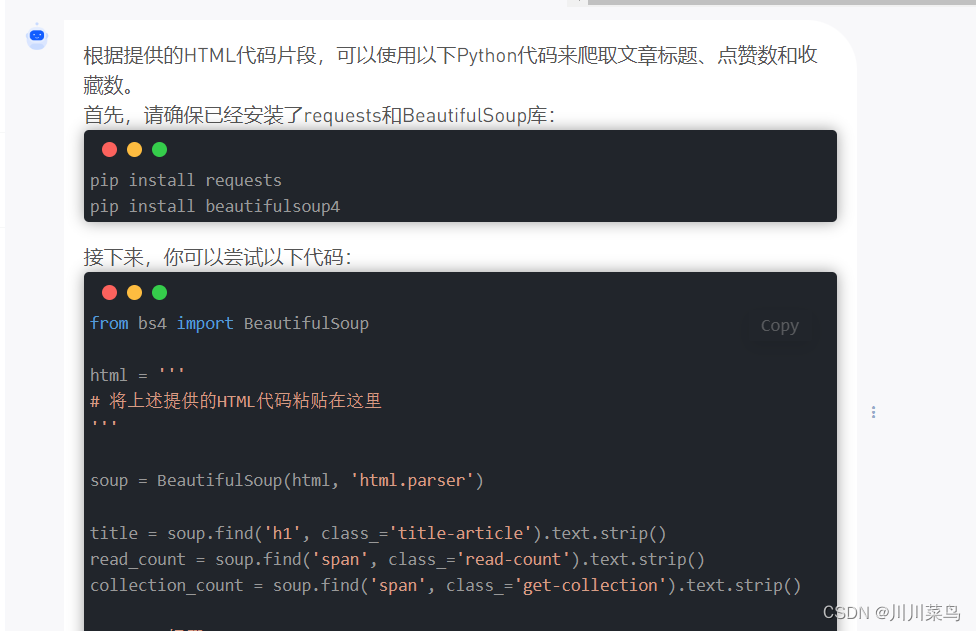
继续追加提问
让它直接添加获取这部分源码:
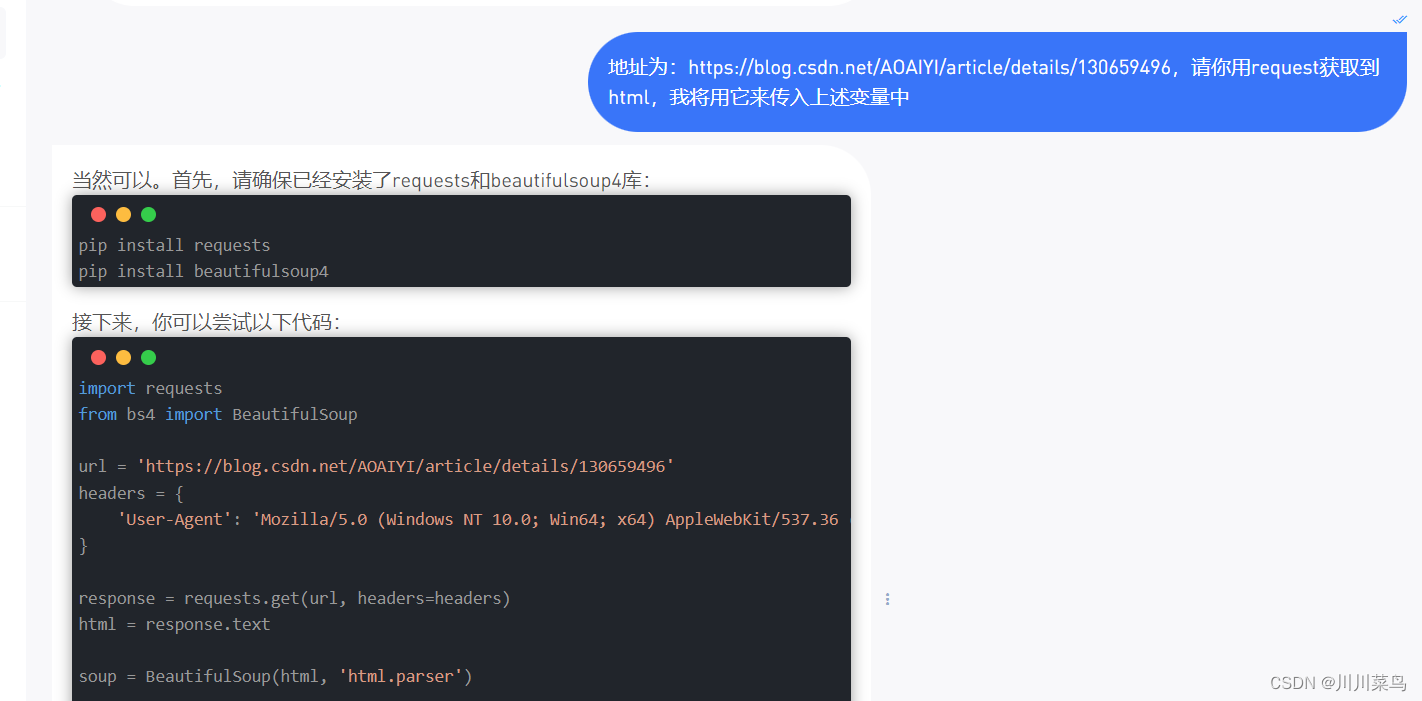
然后复制下面的完整代码即可:
import requests
from bs4 import BeautifulSoupurl = 'https://blog.csdn.net/AOAIYI/article/details/130659496'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}response = requests.get(url, headers=headers)
html = response.textsoup = BeautifulSoup(html, 'html.parser')title = soup.find('h1', class_='title-article').text.strip()
read_count = soup.find('span', class_='read-count').text.strip()
collection_count = soup.find('span', class_='get-collection').text.strip()print(f'标题:{title},阅读数:{read_count},收藏数:{collection_count}')
输出如下:
标题:机器学习:基于Kmeans聚类算法对银行客户进行分类,阅读数:1065,收藏数:64
更多玩法
解锁更多玩法,自行研究,这里我只是刚好抽空测试一下效果,后续有空继续写测试文。