摘要
大型语言模型(LLM)的快速发展使它们能够在包括文档续写和问答系统在内的各种任务中表现惊人。然而,不受监管地使用这些模型可能导致恶意后果,如抄袭、伪造新闻、垃圾邮件等。因此,可靠地检测人工智能生成的文本对确保负责任地使用LLM至关重要。最近的工作试图解决这个问题,比如在生成文本上加入使用特定模型生成的签名,或者在输出 上加入水印技术。在本文中,无论是从经验上还是从理论上,我们都证明了这些探测器在实际情况下不可靠。根据经验,我们发现在生成文本模型的顶部应用一个简单的转述,转述攻击可能会破坏一系列检测器,包括使用水印方案的检测器以及基于神经网络的检测器和零样本分类器。然后我们提供理论上不可能的结果表明,对于一种足够好的语言模型,即使是最好的检测器也只能比随机分类器。最后,我们证明了即使LLM也受到水印的保护在对抗性人类可以进行欺骗攻击的情况下,这些方案可能很容易受到欺骗攻击推断隐藏的水印签名,并将其添加到生成的文本中检测为LLM生成的文本,可能会造成声誉损害给他们的开发人员。我们相信这些结果可以在关于人工智能生成文本的道德和可靠使用的社区。
一、介绍
近年来,人工智能(AI)取得了巨大进步,从生成模型到计算机视觉[Rombach et al.,2022,Saharia et al.,2022]到自然语言中的生成模型处理(NLP)[Brown等人,2020,Zhang等人,2022,Raffel等人,2019]。大型语言模型(LLM)现在可以生成具有最高质量的文本,在许多应用中具有潜力。例如,最近的ChatGPT模型[OpenAI,2022]可以生成各种类似人类的文本诸如为计算机程序编写代码、为歌曲作词、完成文档以及问答;它的应用是无穷无尽的。NLP的趋势表明,这些LLM将甚至会随着时间的推移变得更好。然而,这在真实性方面带来了重大挑战和法规。人工智能工具有可能被用户滥用,用于不道德的目的,例如抄袭、生成假新闻、垃圾邮件、生成虚假产品评论和操纵用于社会工程的网络内容可能对社会产生负面影响[Adelani等人。,2020年,Weiss,2019年]。人工智能改写的一些新闻文章导致了其中的许多根本错误[Christian,2023]。因此,有必要确保负责任地使用这些生成性人工智能工具。为了实现这一点,最近的许多研究都集中在检测人工智能生成的文本上。
一些检测工作将此问题作为二元分类问题进行研究[OpenAI,2019,Jawahar等人,2020,Mitchell等人,2023,Bakhtin等人,2019,Fagni等人,2020]。例如,OpenAI微调基于RoBERTa的[Liu et al.,2019]GPT-2检测器模型,以区分非人工智能生成和GPT-2生成的文本[OpenAI,2019]。这需要对这样的检测器进行微调,并对每个新的LLM进行监督,以实现可靠的检测。另一个工作重点无需任何额外训练开销的零样本AI文本检测[Solaiman等人,2019,Ippolito等人,2019,Gehrmann等人,2019]。这些工作评估预期的每个令牌日志文本的概率,并执行阈值处理以检测AI生成的文本。Mitchell等人[2023]观察到人工智能生成的段落往往位于文本对数概率的负曲率中。他们提出DetectGPT,一种零样本LLM文本检测方法,以利用这一观察结果。由于这些方法依赖于神经网络进行检测,它们可能容易受到对抗性和中毒攻击[Goodfellow等人,2014,Sadasivan等人,2023,Kumar等人,2022,Wang等人。,2022]. 另一项工作旨在为人工智能生成的文本添加水印,以便于检测[Atalah等人,2001年,Wilson等人,2014年,Kirchenbauer等人,2023年,Zhao等人,2023]。水印简化了通过在LLM输出文本上压印特定图案来检测LLM输出的文本。提出软水印Kirchenbauer等人[2023]将令牌划分为绿色和红色列表,以帮助创建这些模式。带水印LLM从由其前缀令牌。这些水印通常是人类无法察觉的。
在本文中,通过实证和理论分析,我们展示了最先进的人工智能文本探测器在实际情况下是不可靠的。我们首先研究了软水印的经验攻击【Kirchenbauer等人,2023年】,以及范围广泛的零样本【Mitchell等人,2023】和基于神经网络的检测器【OpenAI,2019年】。我们展示了一种转述攻击基于网络的转述应用于人工智能生成模型的输出文本,可以规避各种检测器类型。在强调结果之前,让我们提供一个直觉,说明为什么这次攻击成功的对于给定的句子s,假设P(s)是所有具有与句子s的意思相似。此外,设L(s)是源LLM可以使用的句子集含义类似于s的输出。假设一个用户使用LLM生成了s,并想逃避检测。如果L(s)<<P(s),则用户可以从P(s)中随机采样并避免检测(如果检测模型具有相当低的假阳性率)。而且如果L(s)与P(s)相当,检测器不能同时具有低的假阳性率和阴性率。
考虑到这种直觉,在§2中,我们使用了轻量级的基于神经网络的转述器(就参数数量而言,比源LLM小2.3倍和5.5倍)来重新表述源LLM的输出文本。我们的实验表明,这种自动转述攻击可以降低各种检测器的精度,包括使用软水印和神经网络的检测器基于网络的检测器和零样本分类器。例如,基于PEGASUS的转述器[Zhang et al.,2019]可以降低软水印检测器的[Kirchenbauer et al.,2023]精度从97%下降到80%,困惑评分仅下降3.5分。使用基于T5的转述器[Damodaran,2021]零样本探测器的ROC曲线面积[Mitchell等人,2023]从96.5%下降到25.2%。我们还观察到,基于经过神经网络训练的探测器[OpenAI,2019]的性能在我们的转述攻击后显著恶化。例如,来自OpenAI的RoBERTa大型探测器的真实阳性率从100%下降到60%1%的低假阳性率。
在§3中,我们提出了一个关于人工智能生成文本检测的不可能结果。作为语言模型随着时间的推移而改进、人工智能生成的文本变得越来越类似于人类生成的文本,使得它们更难被检测到。这种相似性反映在总变异距离的减小上在人类和人工智能生成的文本序列的分布之间[OpenAI,2023]。定理1界定最佳可能检测器的接收器工作特性(ROC)曲线下的面积D表示为:
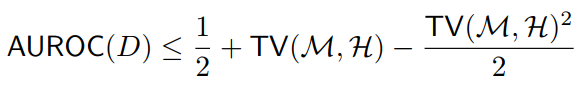
其中TV(M,H)是AI模型M和人类H产生的文本分布之间的总变化距离。这表明,随着总变化距离的减小检测性能接近1/2,表示与分类器相对应的AUROC将文本随机标记为人工智能或人工生成。因此,对于一种足够高级的语言模型中,即使是最好的检测器也只比随机分类器表现得稍微好一点。这个该分析的目的是敦促在处理声称要检测的检测系统时要谨慎任何人工智能模型生成的文本。我们通过紧密性分析来补充我们的结果证明对于给定的人类分布H,存在分布M和检测器D上述界限相等。
尽管我们的分析考虑了所有人类和一般语言模型生成的文本也可以应用于特定的场景,例如特定的写作风格或句子转述,通过适当地定义M和H。例如,它可以用来显示人工智能生成的文本,即使有嵌入的水印,也很难通过简单的检测转述工具。对于语言模型生成的序列s,我们将M和H设置为与转述者和人类产生的s具有相似含义的序列的分布。目标转述器的作用是使其输出分布与人类生成的分布相似相对于总变化距离的序列。上述结果对检测器在重新表述的AI文本上的性能。
最后,我们在§4中讨论了对文本生成模型进行欺骗攻击的可能性。在这个设置时,攻击者生成被检测为人工智能生成的非人工智能文本。对手可以可能发起欺骗攻击,产生被检测为人工智能生成的贬损文本以影响目标LLM的开发人员的声誉。作为概念的证明,我们证明软水印检测器[Kirchenbauer等人,2023]可以被欺骗,以检测由人类的水印。尽管用于生成带水印文本的随机种子是私有的,我们开发了一种攻击,可以智能地多次查询目标LLM以学习其水印计划然后,对抗性的人类可以使用这些信息来撰写文本,这些文本被检测为水印。图1显示了现有人工智能文本检测器的漏洞说明。
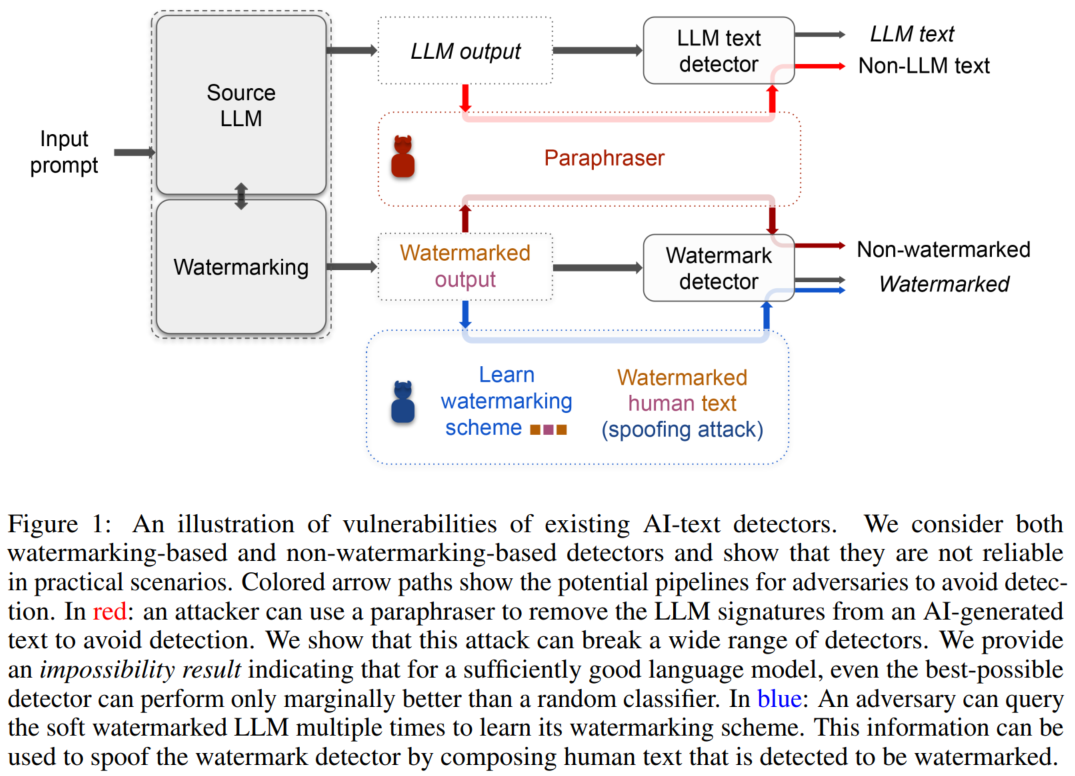
识别人工智能生成的文本是避免用户出于不道德目的滥用文本的关键问题如抄袭、制造假新闻和垃圾邮件。然而,部署易受攻击的探测器这不是解决这个问题的正确解决方案,因为它可能会造成自身的损害,例如诬告抄袭的人性。我们的结果突出了各种探测器对简单实用的灵敏度诸如转述攻击之类的攻击。更重要的是,我们的研究结果表明,在实际场景中开发可靠的检测器是不可能的——为了保持可靠的检测性能,LLM必须权衡其性能。我们希望这些发现能够引发坦诚的对话关于人工智能生成文本的道德和可靠利用。
二、使用语句攻击躲避AI检测器
检测人工智能生成的文本对于确保LLM的安全性和避免II型错误至关重要(未检测到LLM输出为AI生成的文本)。为了保护LLM的所有权检测器应该能够以高精度检测人工智能生成的文本。在本节中,我们将讨论可以降低最先进的人工智能文本检测器(如soft)的II型错误的转述攻击水印[Kirchenbauer等人,2023],零样本检测器[Mitchell等人,2023年],并经过训练基于神经网络的检测器[OpenAI,2019]。这些检测器识别给定文本是否包含不同的LLM签名,表明它可能是人工智能生成的。这里的想法是转述可以在不影响文本含义的情况下删除这些签名。当我们讨论时在§3中的这种攻击理论上,这里的主要直觉如下:
让s代表一个句子,S代表一组对人类有意义的句子。假设函数P:S->2^S的存在使得s'属于P(s),s和s'对人类而言语义是相同的。换句话说,P(s)是一组与句子s具有相似含义的句子。让L:S->2^S,使得L(s)是源LLM输出与s语义相同的句子集合。后面,使用由AI生成的可靠的检测器来检测句子集L(s)中的句子,L(s)⊆P(s),使得人工智能模型的输出对人类有意义。如果L(s)和P(s)进行对比,检测器可能会将许多人类书写的文本标记为AI生成的(高类型I错误)。然而,如果L(s)很小,我们可以从P(s)中随机选择一个句子来躲避检测器高概率(影响类型II错误)。因此,在这种转述攻击的情况下,检测器面临最小化类型I和类型II错误之间的权衡。
2.1、对带水印的人工智能生成文本的语法攻击
在这里,我们对Kirchenbauer等人提出的软水印方案1进行了实验。[2023]. 在该方案中,LLM的输出令牌是从由其前缀我们期望转述从目标LLM的输出中移除水印签名。目标AI文本生成器使用基于转换器的OPT-1.3B[Zhang et al.,2022]架构具有1.3B参数。我们使用基于T5的[Rafel et al.,2019]转述模型[Ddamodaran,2021,222M参数和基于PEGASUS的[Zhang等人,2019]解释模型568M参数(分别比目标LLM小2.3倍和5.8倍)。目标LLM是经过训练,可以对大量数据执行文本完成任务,而较小的转述模型仅针对转述任务进行了微调。由于这些原因,我们在攻击比基于目标OPT的模型更轻。
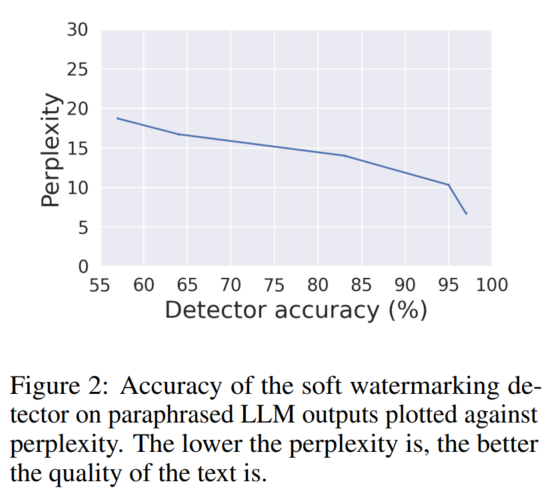
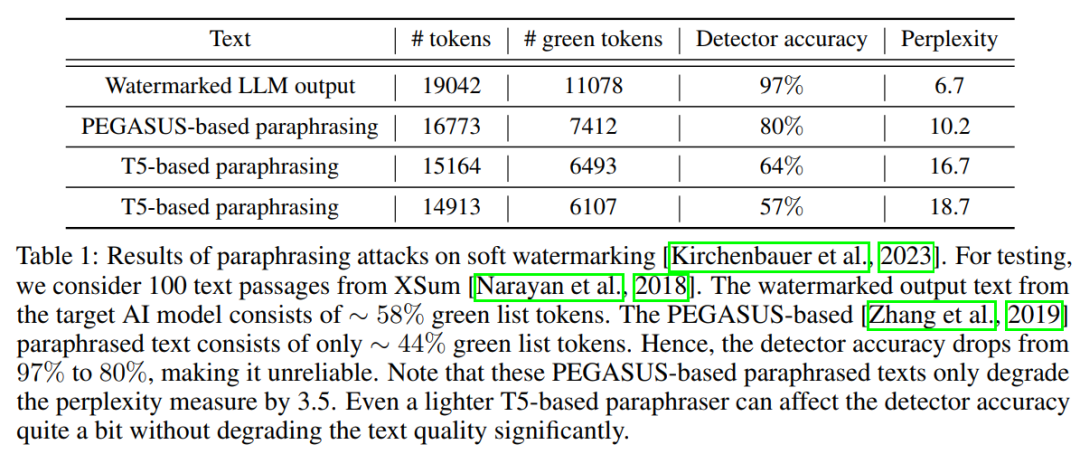
转述者采用带水印的LLM一句接一句地输入文本。我们使用《极限总结》中的100段(XSum)数据集[Narayan等人,2018]评估.这个数据集中的段落是输入到目标AI模型以生成带水印的文本。使用基于PEGASUS的转述器,检测器的准确度从97%下降到80%,困惑中只有3.5的权衡得分(见表1)。这种转述策略减少中绿色列表令牌的百分比水印文本从58%(转述前)到44%(转述后)。表2显示在转述之前和之后来自目标软水印LLM的一些示例输出。我们也使用一个更小的基于T5的转述器[Damodaran,2021]表明即使是这样天真的转述会使检测器的准确率从97%下降到57%。图2显示了检测精度和基于T5的转述器的输出文本质量(使用困惑评分测量)之间的权衡。然而,我们注意到困惑是评估质量的一个代理指标因为它依赖于另一个LLM来计算分数。我们使用更大的OPT-2.7B[张et al.,2022],其中2.7B参数用于计算困惑得分。

2.2、对无水印人工智能生成文本的语法攻击
非水印检测器,如经过训练的分类器[OpenAI,2019]和零样本分类器【Mitchell等人,2023年,Gehrmann等人,2019年,Ippolito等人,2019,Solaiman等人,2019】使用在人工智能生成的文本中存在LLM特异性签名以进行检测。基于神经网络的训练过的探测器,如OpenAI的RoBERTa大型探测器[OpenAI,2019]通过包含人类和人工智能生成的文本的数据集对二进制分类进行了微调。零样本分类器利用源LLM输出的特定统计财产进行检测。在这里我们在这些非水印检测器上进行了实验,以表明它们容易受到我们的攻击转述攻击。
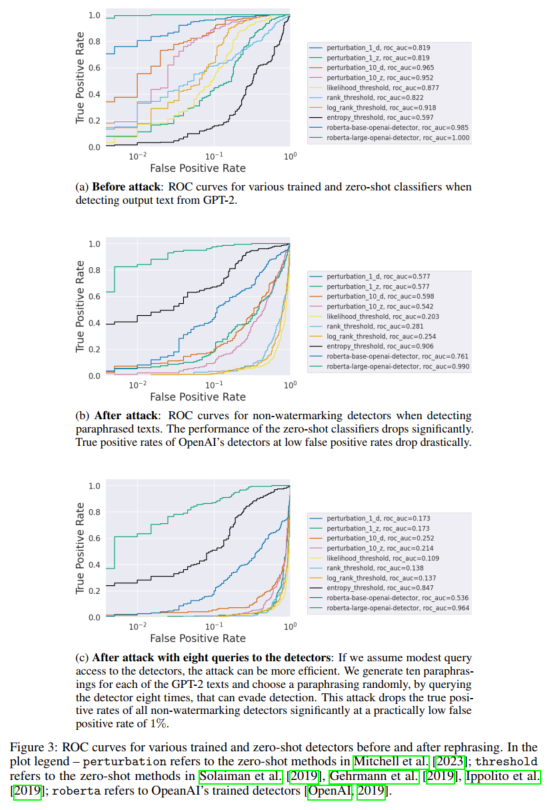
我们使用预先训练的GPT-2 Medium7模型[Radford et al.,2019]和355M参数来评估我们对XSum数据集200个段落的攻击[Narayan et al.,2018]。我们使用基于T5的用222M参数改写模型[Damodaran,2021],以改写来自目标GPT-2介质模型。图3显示了转述攻击对这些攻击的有效性探测器。DetectGPT的AUROC评分[Mitchell et al.,2023]从96.5%下降(在攻击)至59.8%(攻击后)。注意AUROC为50.0%对应于随机检测器。其余的零样本探测器[Solaiman等人,2019年,Gehrmann等人,2018年,Ippolito等人。,2019]在我们进攻后表现也很糟糕。尽管经过训练的神经系统的性能基于网络的检测器[OpenAI,2019]优于零样本检测器,但也不是可信赖的例如,OpenAI的RoBERTa大型探测器的真阳性率从100%下降在我们的攻击后,以1%的实际假阳性率降低到大约80%。通过对检测器,对手可以更有效地解释,以降低RoBERTa大型探测器达到60%。表3显示了GPT-2模型的输出示例转述前后。如示例所示,转述器的输出读起来很好表示与检测到的GPT-2文本相同。我们测量GPT-2输出文本对为16.3(图3a)。GPT-2是一种相对较旧的LLM,与最近的LLM相比,它的性能较差。转述后GPT-2文本的困惑程度为27.2(图3b)。困惑在对检测器进行多次查询的情况下,分数仅下降2(图3c)。
3、人工智能生成文本可靠检测的不可能结果
检测现实世界中对语言模型的滥用,如剽窃和大规模宣传,需要识别各种语言模型产生的文本,包括那些没有水印的。然而,随着这些模型的改进,生成的文本看起来与人类文本越来越相似,这使检测过程变得复杂。具体而言人工智能生成和人工生成文本序列分布之间的变化距离随着语言模型变得越来越复杂而减少。本节介绍了对一般人工智能文本检测的限制,表明即使是最有效的检测器也能执行在处理足够高级的语言时,只比随机分类器略胜一筹模型此分析的目的是警告不要过于依赖检测系统声称识别人工智能生成的文本。我们首先考虑无水印语言模型的情况然后将我们的结果扩展到带水印的结果。
在下面的定理中,我们通过显示面积的上界来形式化上述陈述在任意检测器的ROC曲线下人工智能和人工生成文本的分发。这个界限表明这些分布减少,AUROC界接近1/2,这表示基线与将文本随机标记为AI或人工生成的检测器相对应的性能。我们将M和H分别定义为人工智能模型和人类在所有可能的文本序列的集合Ω. 我们使用TV(M;H)来表示这两个分布和函数D:Ω ! 映射每个序列的RΩ 转换为实数。序列被分类为人工智能和通过对这个数字应用阈值γ生成的人类。通过通过调整参数γ,我们可以调整检测器对人工智能和人工生成文本的灵敏度以获得ROC曲线。


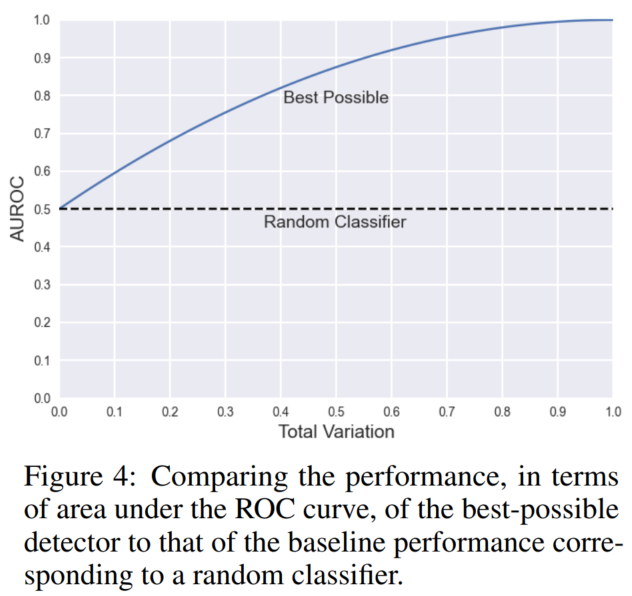
图4显示了上述界限是如何增长的作为总变化的函数。为了使探测器具有良好的性能(例如AUROC≥0:9)人工智能生成的文本必须与相互作用(总变异>0:5)。作为两者分布变得相似(例如,总变异≤0:2),即使是最好的检测器的性能也不好(AUROC<0:7)。这表明区分产生的文本通过来自的无水印语言模型人工生成是一项从根本上来说很困难的任务。注意对于带水印的模型,上述界限可以接近于1作为总数水印分布和人为生成的分布之间的变化距离可以要高。在接下来的内容中,我们将讨论在这种情况下转述攻击是如何有效的。
躲避检测的释义:尽管我们的分析考虑了所有人类生成的文本和通用语言模型,它也可以应用于特定的场景,例如特定的写作风格或句子转述,通过适当地定义M和H。例如,可以使用表明人工智能生成的文本,即使有水印,也很难通过简单的方式检测通过转述工具传递。考虑一个转述器,它采用由人工智能模型作为输入,并产生具有类似含义的类人序列。设置M=RM(s)并且H=RH(s)是由转述者和人类。转述器的目标是使其分布RM(s)尽可能与人体分布RH相似,基本上减少了总变异它们之间的距离。定理1对检测器D的性能给出了以下界限试图从人类产生的序列中检测转述器的输出。

真阳性率和假阳性率之间的一般权衡。另一种理解方式人工智能生成的文本检测器的局限性直接通过权衡的表征来实现在真阳性率和假阳性率之间。根据不等式2,我们得到以下结果花冠:

这些结果证明了人工智能文本检测器的基本局限性,无论是否使用水印方案。
3.1、严密性分析
在这一节中,我们证明了定理1中的界是紧的。对于人类生成的文本序列H的给定分布,我们构造AI文本分布M和检测器D,使得受约束的条件是相等的。定义分布的概率密度函数的子级集在所有序列的集合上的人工生成的文本pdfHΩ 如下所示:


4、对人工智能文本生成模型的欺骗攻击
强人工智能文本检测方案应具有较低的I型错误(即,检测到的人类文本为AI生成)和类型II错误(即未检测到AI生成的文本)。没有AI语言检测器低I型错误可能会造成危害,因为它可能会错误地指责人类使用嗯。此外,攻击者(对抗性人类)可以生成非人工智能文本,该文本被检测为人工智能生成。这被称为欺骗攻击。对手可能会发动欺骗攻击生成被检测为人工智能生成的贬损文本,以影响目标的声誉LLM的开发人员。在本节中,作为概念验证,我们展示了软水印检测器[Kirchenbauer et al.,2023]可以被欺骗,以检测人类创作的带有水印的文本。他们通过断言模型以输出具有特定模式的令牌来对LLM输出进行水印其可以以很低的错误率被容易地检测到。软水印文本主要由绿色列表令牌。如果对手能够学习软水印方案的绿色列表,那么他们可以使用该信息来生成被检测为加水印的手写文本。我们的实验表明,该软水印方案可以有效地进行欺骗。尽管柔软水印检测器可以非常准确地检测水印的存在,但不能确定如果这个模式实际上是由人类或LLM生成的。一个敌对的人可以组成以这种方式检测到带有水印的贬损水印文本,这可能会导致水印LLM开发商的声誉受损。因此,学习很重要欺骗攻击以避免此类情况。
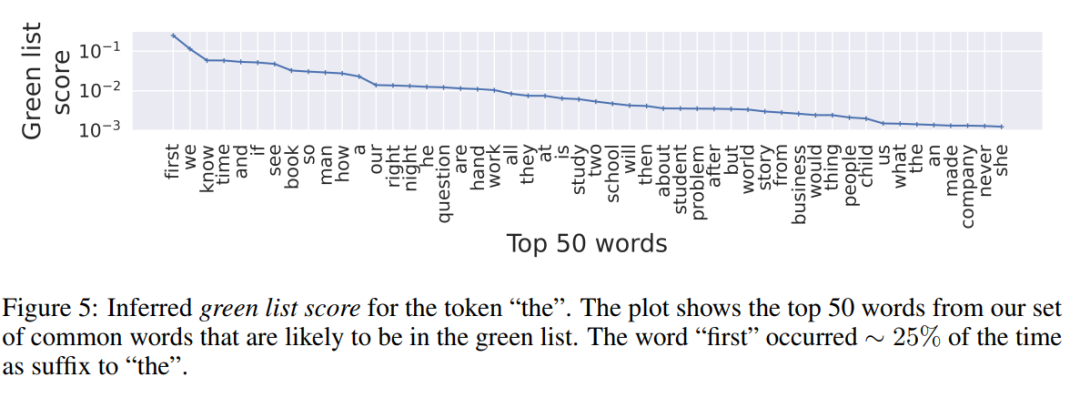
攻击方法:对于输出单词s^(t),软水印从其高概率的绿色名单。前缀单词s^(t-1)决定了用于选择单词s^(t)。攻击者的目标是为最常见的N计算绿色列表的代理词汇表中使用的单词。与词汇表的大小相比,较小的N有帮助更快的计算,同时在攻击者对水印方案的了解方面进行权衡。我们在我们的实验中使用N=181的小值。攻击者可以查询带水印的LLM多次学习LLM输出中这N个单词的成对出现。观察通过这些输出,攻击者可以计算给定前缀单词的单词出现的概率s^(t-1)。该分数可以用作计算前缀单词s^(t-1)的绿色列表的代理。一有权访问这些代理绿色列表的攻击者可以编写检测到要加水印的文本,从而欺骗检测器。在我们的实验中,我们查询带水印的OPT-1.3B[Zhang et al.,2022]106次来评估绿色列表分数以评估绿色列表代理。我们发现输入由N个常见单词组成的无意义句子鼓励LLM输出主要由这些单词组成的文本。这使得查询更加高效。在图5中,我们展示了使用我们的查询技术学习前缀单词“the”的绿色列表分数。我们建立一个简单的让用户一个标记一个标记地创建段落的工具。在每一步,都会向用户提供一个列表基于绿色列表得分排序的潜在绿色列表单词。这些用户或敌对的人类尝试在我们的工具的帮助下生成有意义的段落。由于大多数单词都是通过对抗性选择的人类很可能在绿色名单中,我们希望水印方案能够检测到这些文本加水印。表4显示了由对抗性人类组成的句子示例,这些句子是检测到有水印。即使是由敌对的人类产生的无意义的句子也可以以非常高的置信度检测为水印。
5、讨论
NLP的最新进展表明,LLM可以为各种数量的任务[OpenAI,2023]。然而,这可能会带来一些挑战。LLM可能被滥用抄袭、垃圾邮件,甚至社会工程来操纵公众。这就产生了需求用于开发高效的LLM文本检测器,以减少对公开可用的LLM的利用。最近的工作提出了使用水印的各种AI文本检测器[Kirchenbauer等人,2023],零样本方法[Mitchell等人,2023]和经过训练的基于神经网络的分类器[OpenAI,2019]. 在这篇论文中,我们从理论和经验上证明了这些最先进的探测器在实际场景中不能可靠地检测LLM输出。我们的实验表明LLM输出有助于有效地避开这些检测器。此外,我们的理论证明一个足够先进的语言模型,即使是最好的检测器也只能稍微好一点而不是随机分类器。这意味着,对于同时具有低I型和II型误差的检测器将不得不权衡LLM的表现。我们还从经验上证明了基于水印的检测器可以被欺骗,以使人工合成的文本被检测为带水印的。我们证明了这一点攻击者可能在[Kirchenbauer等人,2023]中学习软水印方案。使用根据这些信息,对手可以发起欺骗攻击,让敌对的人生成文本其被检测为被加水印。欺骗攻击可能导致生成水印可能影响水印LLM开发人员声誉的贬损段落。
随着GPT-4[OpenAI,2023]的发布,LLM的应用层出不穷。这也要求需要更安全的方法来防止它们被滥用。在这里,我们简单地提到一些方法攻击者将来可能会选择破坏人工智能检测器。正如我们在本文中所展示的改进转述模型的出现可能会对人工智能文本检测器构成严重威胁。此外高级LLM可能容易受到基于智能提示的攻击。例如,攻击者可以输入一个以“用主动语态和现在时态生成句子”开头的提示只有我提供的以下一组单词…”。高性能LLM将具有低熵此提示的输出空间(可能的输出序列数量较少),使添加强LLM签名在其输出中用于检测。Kirchenbauer等人的软水印方案。[2023]很容易受到这种攻击。如果LLM的logits在词汇表上具有低熵,软水印方案对具有最高logit分数的令牌进行采样(与绿色无关列表标记)以保持模型困惑。此外,在未来,我们可以期待更多的开源攻击者可以使用LLM。这可能有助于攻击者利用这些模型设计转移针对更大LLM的攻击。可以使用转移攻击来设计对抗性输入提示从而鼓励目标LLM具有低熵输出空间。人工智能的未来研究文本检测器必须谨慎对待这些漏洞。
理想情况下,检测器应该有助于可靠地标记人工智能生成的文本,以防止滥用LLM。然而,检测器错误识别的成本本身可能是巨大的。如果假阳性检测器的检测率不够低,人类可能会被错误地指控抄袭。此外被错误地检测为人工智能生成的贬损段落可能会影响LLM的声誉开发人员。因此,人工智能文本检测器的实际应用可能变得不可靠无效的安全方法不一定是万无一失的。然而,我们需要确保它不是攻击者破坏这些安全防御很容易。因此,分析使用电流的风险检测器对于避免产生虚假的安全感至关重要。我们希望所呈现的结果在这项工作中,可以鼓励社区就道德和生成LLM的值得信赖的应用。