作者: du拉松 原文来源: https://tidb.net/blog/3f1ada39
一、前言
tidb是mysql协议的,所以在使用过程中使用tidb的相关工具连接即可。因为jmeter是java开发的相关工具,直接使用mysql的jdbc驱动包即可。
二、linux下安装jmeter
jmeter需要jdk环境,且安装jmeter需要java8以上环境。
(一)、安装jdk
下载地址: https://www.oracle.com/technetwork/java/javase/downloads/index.html
这里我下载的jdk17
解压压缩包到/usr/local/java/下:
配置jmeter环境变量:编辑/etc/profile文件 vi /etc/profile
在文件上部加上如下配置:
# 这里的JAVA_HOME填写linux系统的路径
export JAVA_HOME=/usr/local/java/jdk17.0.12
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
生效环境变量配置:
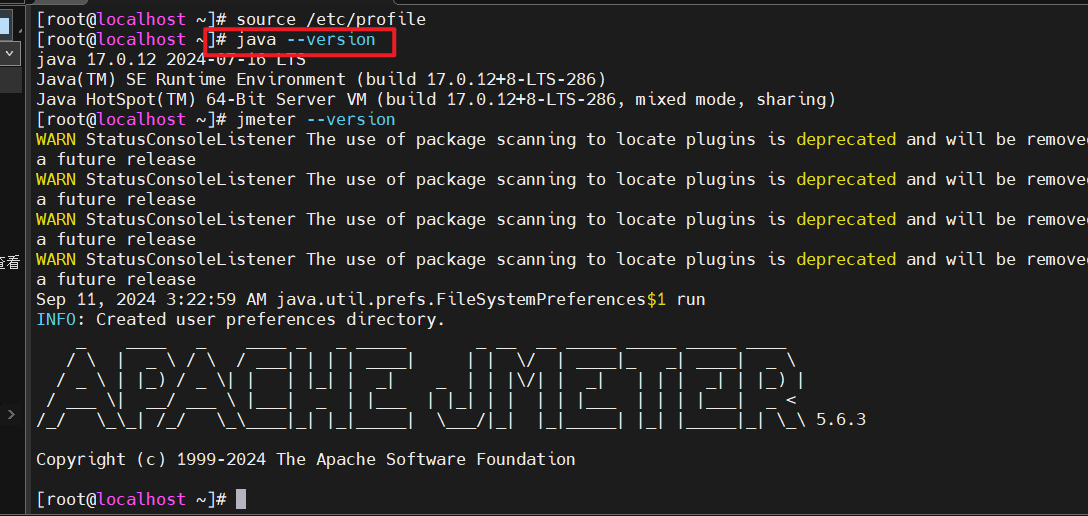
source /etc/profile
验证java是否已经安装成功: java -version,出现版本号即安装成功
(二)、linux下安装jmeter
下载地址: https://jmeter.apache.org/download_jmeter.cgi
在/usr/local目录下创建jmeter文件夹
配置jmeter环境变量:在/etc/profile文件上部添加配置信息:
export JMETER_HOME=/usr/local/jmeter/apache-jmeter-5.6.3
export CLASSPATH=$JMETER_HOME/lib/ext/ApacheJMeter_core.jar:$JMETER_HOME/lib/jorphan.jar:$CLASSPATH
export PATH=$JMETER_HOME/bin:$PATH
生效jmeter环境变量:source /etc/profile
验证jmeter是否安装成功:jmeter --version
三、前置准备
如果使用linux环境执行jmeter压测。可以先在windows下使用可视化页面编辑jmx配置文件后,上传到linux使用命令压测。
(一)、配置jdbc
准备压测tidb数据库,所以需要先下载jdbc驱动包。
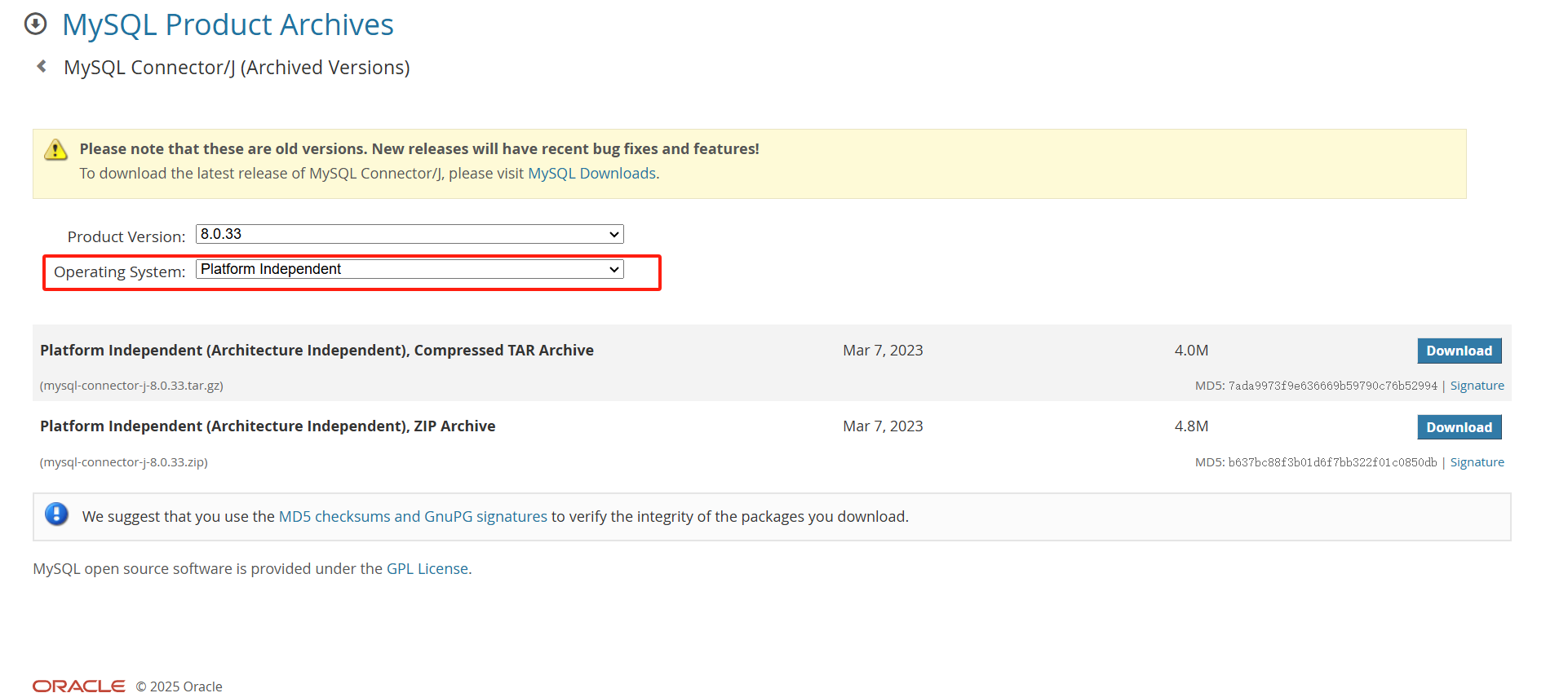
tidb jdbc驱动包下载地址: https://downloads.tidb.com/archives/c-j/
选择要下载的版本,Operating system选择platform independent,选择zip格式的包下载。
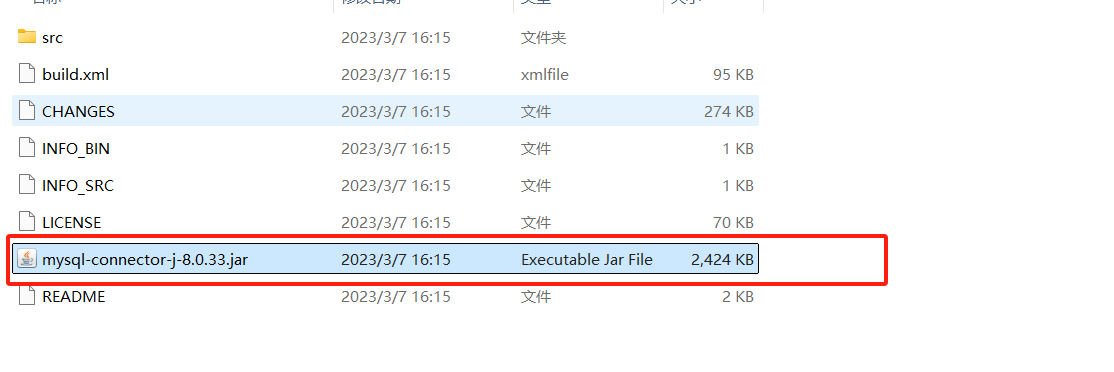
下载后解压压缩包,把下面tidb-connerctor-j-8.0.33.jar放到jmeter目录下的lib下:
(二)、在windows下打开jmeter
下载jmeter后,解压压缩包。进入jmeter文件夹下的bin目录下:
双击jmeter.bat后会打开可视化页面。
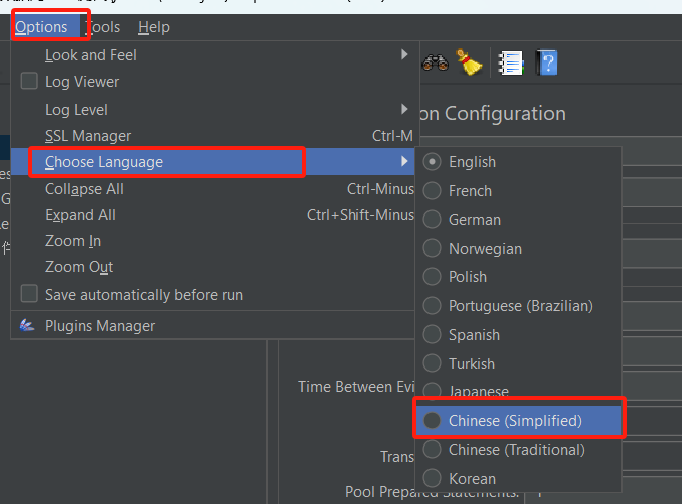
(三)、jmeter汉化
- 短暂的可视化页面汉化。点击options --> choose language --> chinese(Simplified)
这种方式设置后,下次再打开还是会还原成英文。
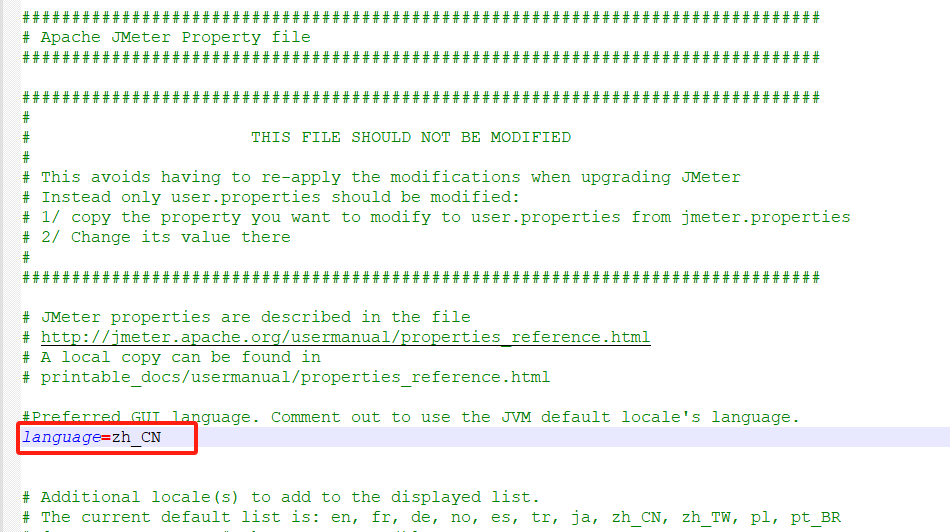
- 永久的可视化页面汉化,在jmeter的bin目录下,找到jmeter.properties文件,打开后找到language,放开注释,维护类型为zh_CN
四、jmeter压测脚本编辑
(一)、执行一个查询
场景:
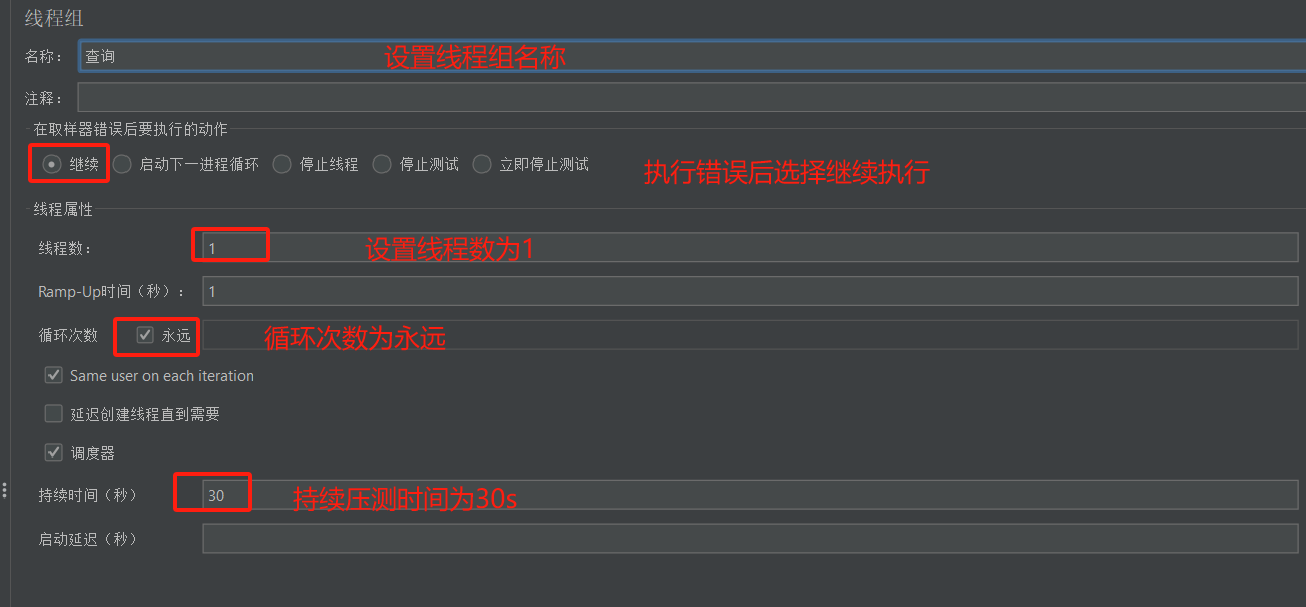
连接tidb数据库127.0.0.1 端口3306,账户:root,密码:3306
开启一个线程执行select * from test where id = '?' 该sql,参数动态从csv中获取,持续运行30s。
- 创建一个线程组
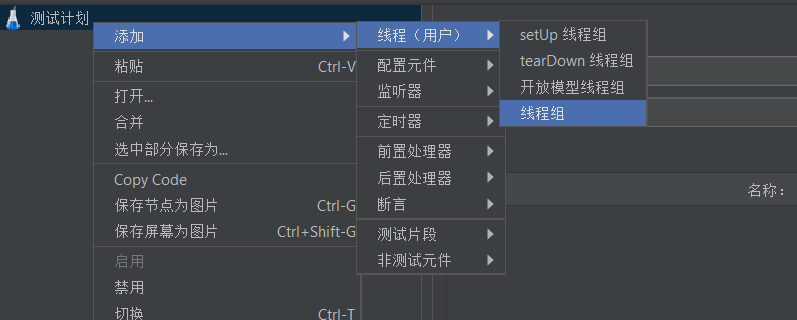
- 配置线程组如下
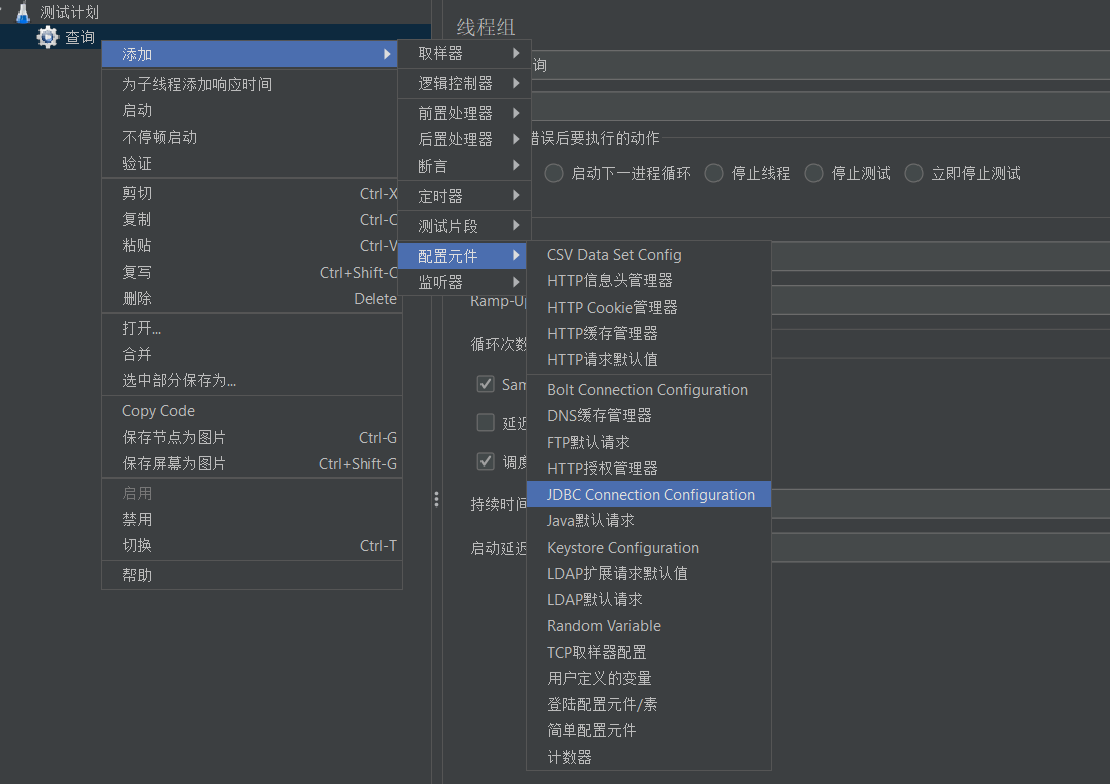
- 创建jdbc配置信息
右击线程组“查询”,添加-->配置元件-->JDBC Connection Configuration
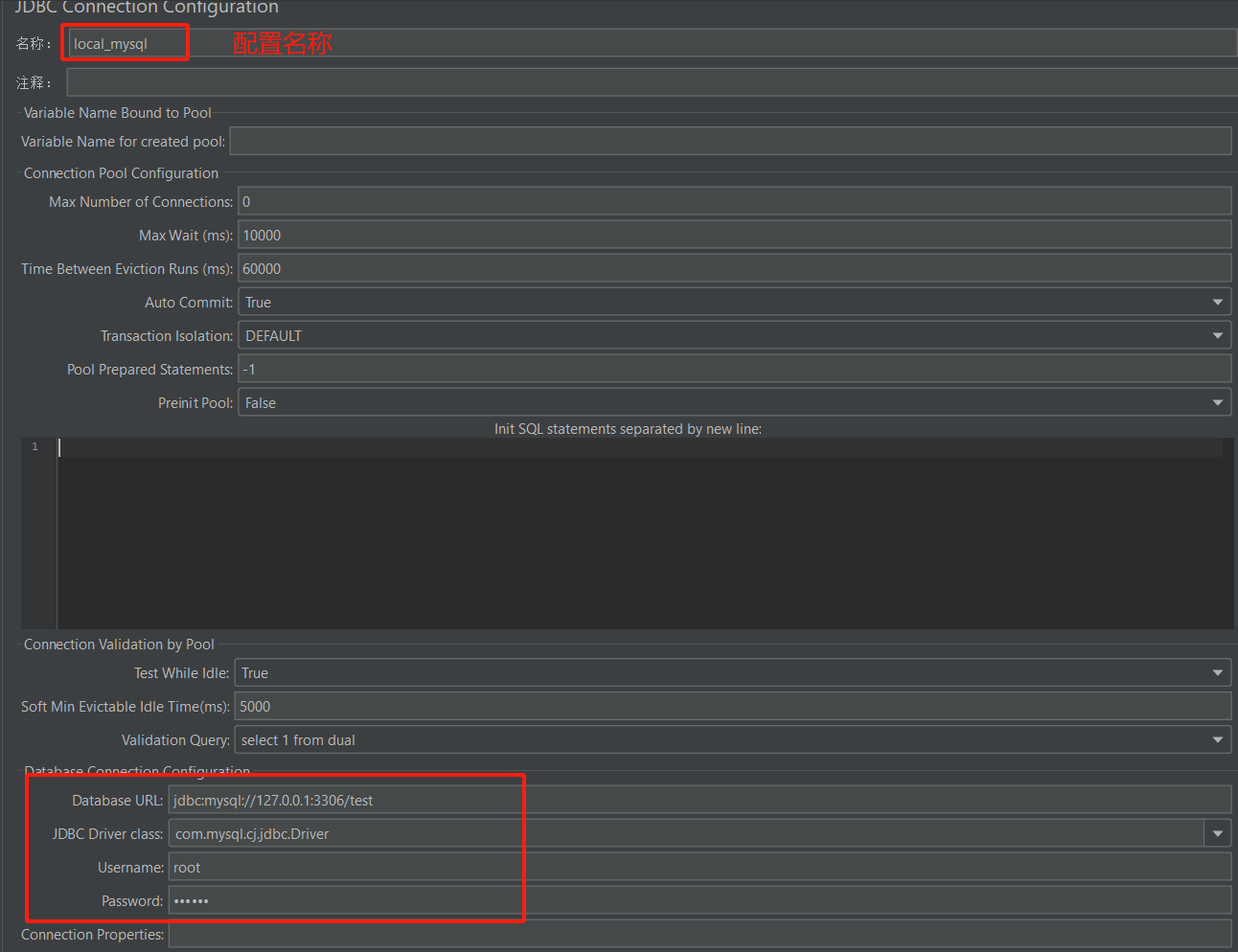
- 编辑jdbc的配置文件:
配置名称为local_tidb
tidb的database_url为:jdbc: mysql://127.0.0.1:3306/test
tidb的driver class为:com.tidb.cj.jdbc.Driver
user为root
密码为123456
- 添加jdbc request,右击线程组“查询”,添加-->取样器-->jdbc request
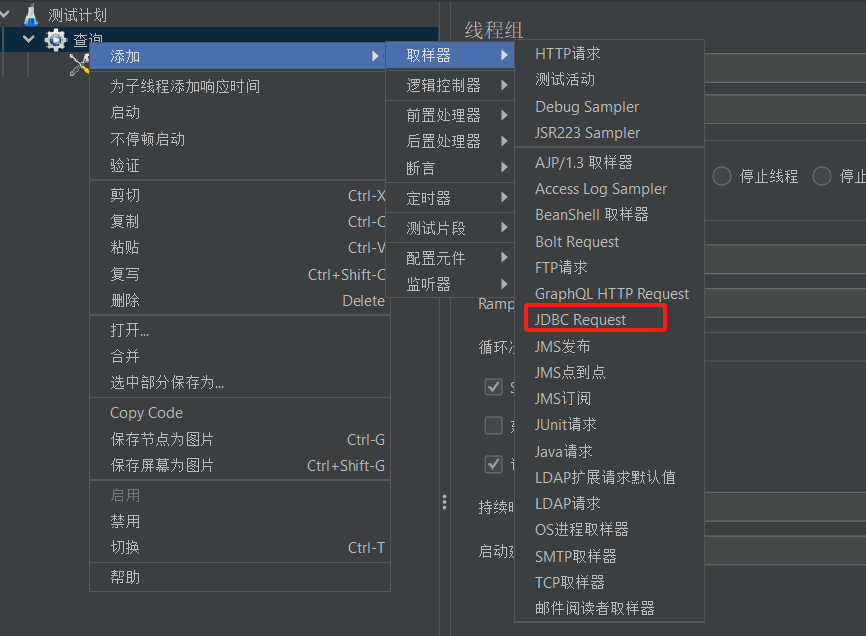
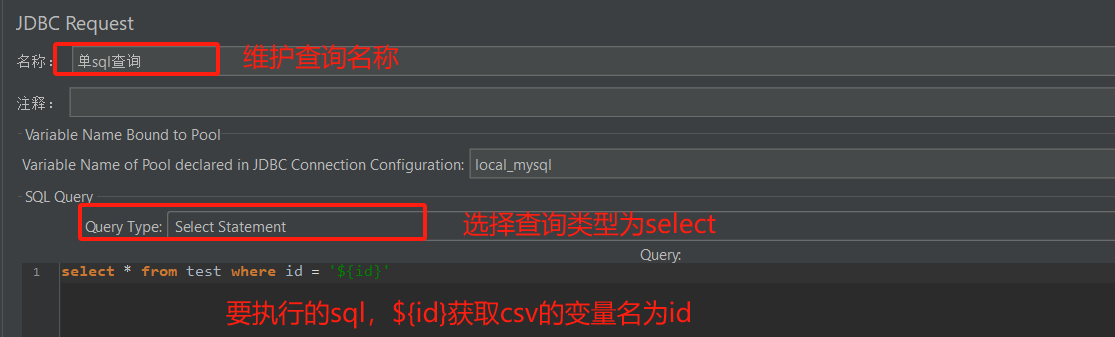
- 修改jdbc request配置信息
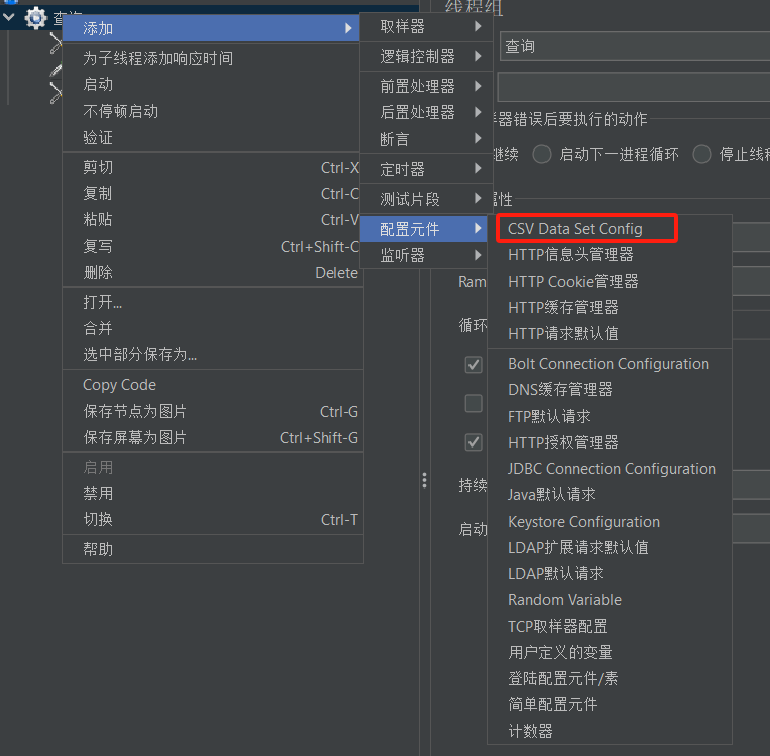
- 添加csv配置,右击线程组“查询”,添加 --> 配置元件 --> CSV Data Set Config
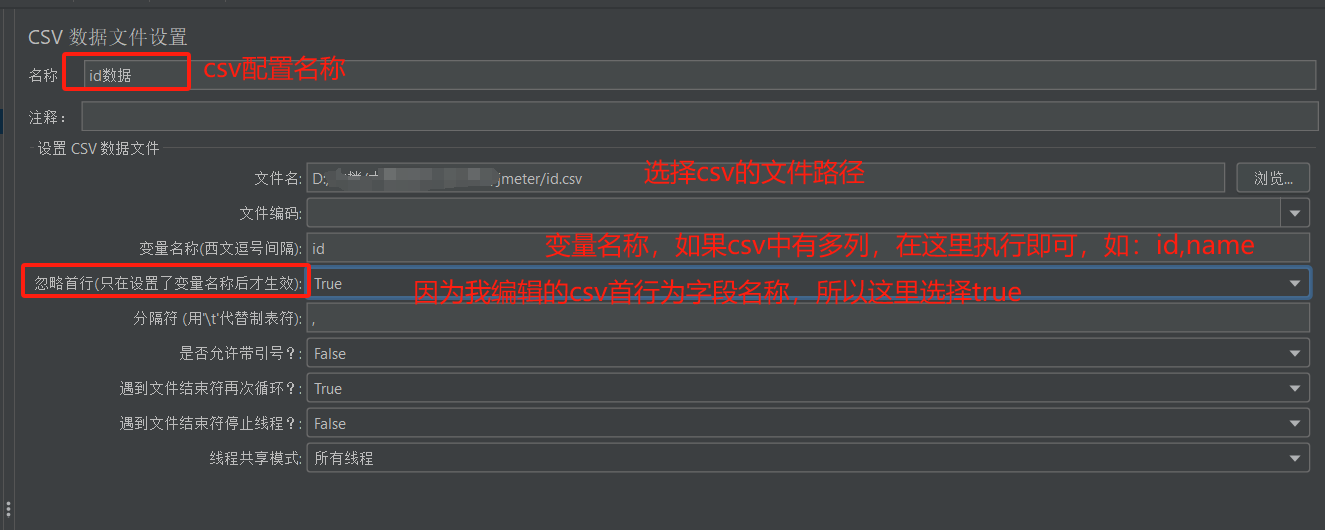
- 配置csv信息
创建一个csv文件,首行为列名“id”

- 添加查看结果树,(这里本地测试的时候添加即可,正式压测时可以删除)。右击线程组“查询”,添加 --> 监听器 --> 查看结构树
- 添加汇总报告,右击线程组“查询”,添加 --> 监听器 --> 汇总报告。
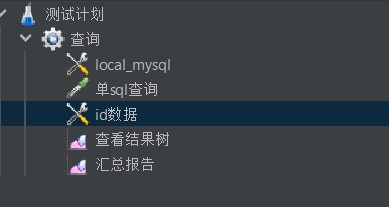
- 最终的配置结构如下:
- 执行压测,点击如下绿色按钮。

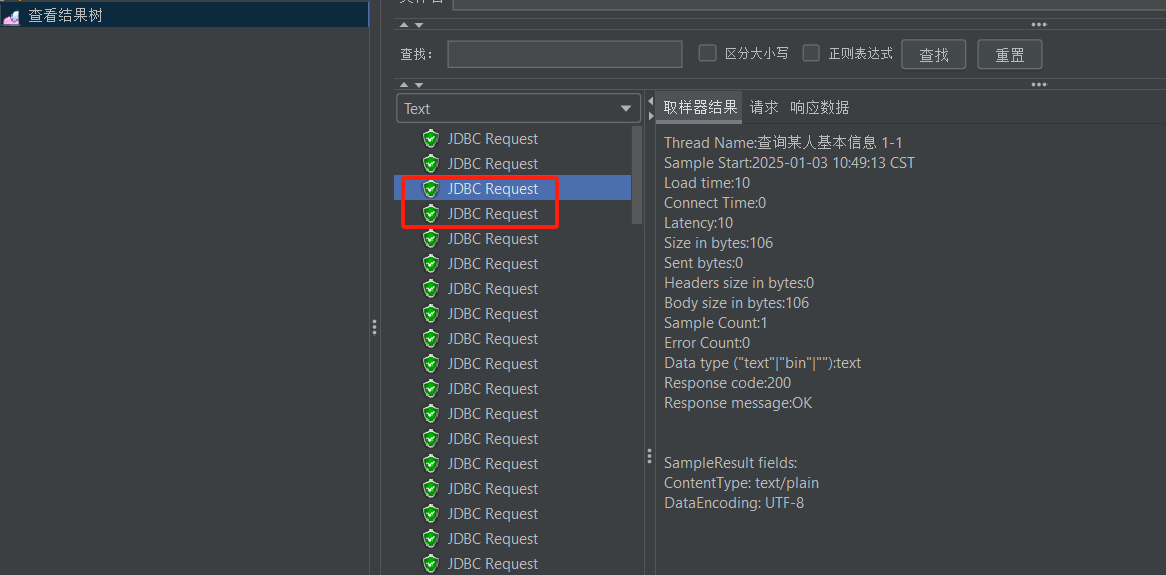
- 执行后查看结构树
这里可以看到每次请求的执行结果,列表中绿色图标表示成功,红色图标表示失败。
右侧的取样器:展示具体的请求和响应延时等
请求:展示执行的sql和参数。
响应数据:查看查询出的数据。
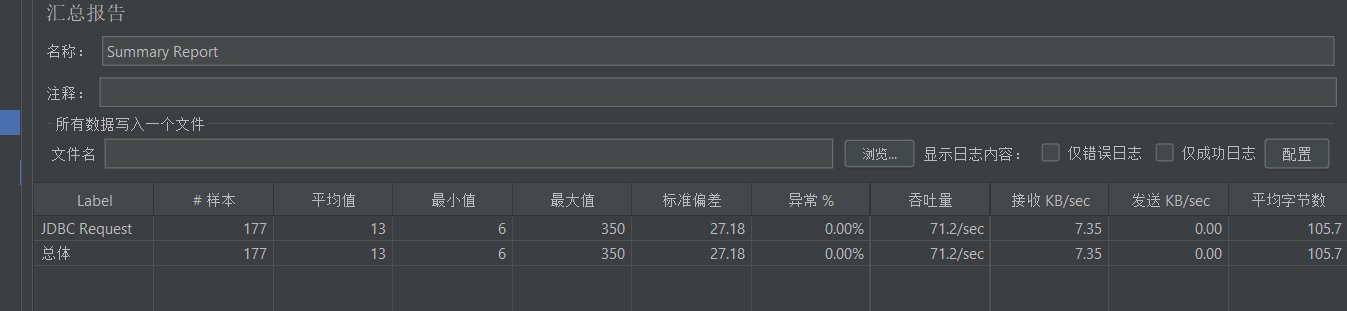
- 查看汇总报告
(二)、执行多个查询
场景:
连接tidb数据库127.0.0.1 端口3306,账户:root,密码:3306
开启一个线程执行sql1:select * from test where id = '?' 和sql2:select * from test where name = '?',参数动态从csv中获取,持续运行30s。
注意:步骤和一个查询的相同,下面只列出不同的配置。
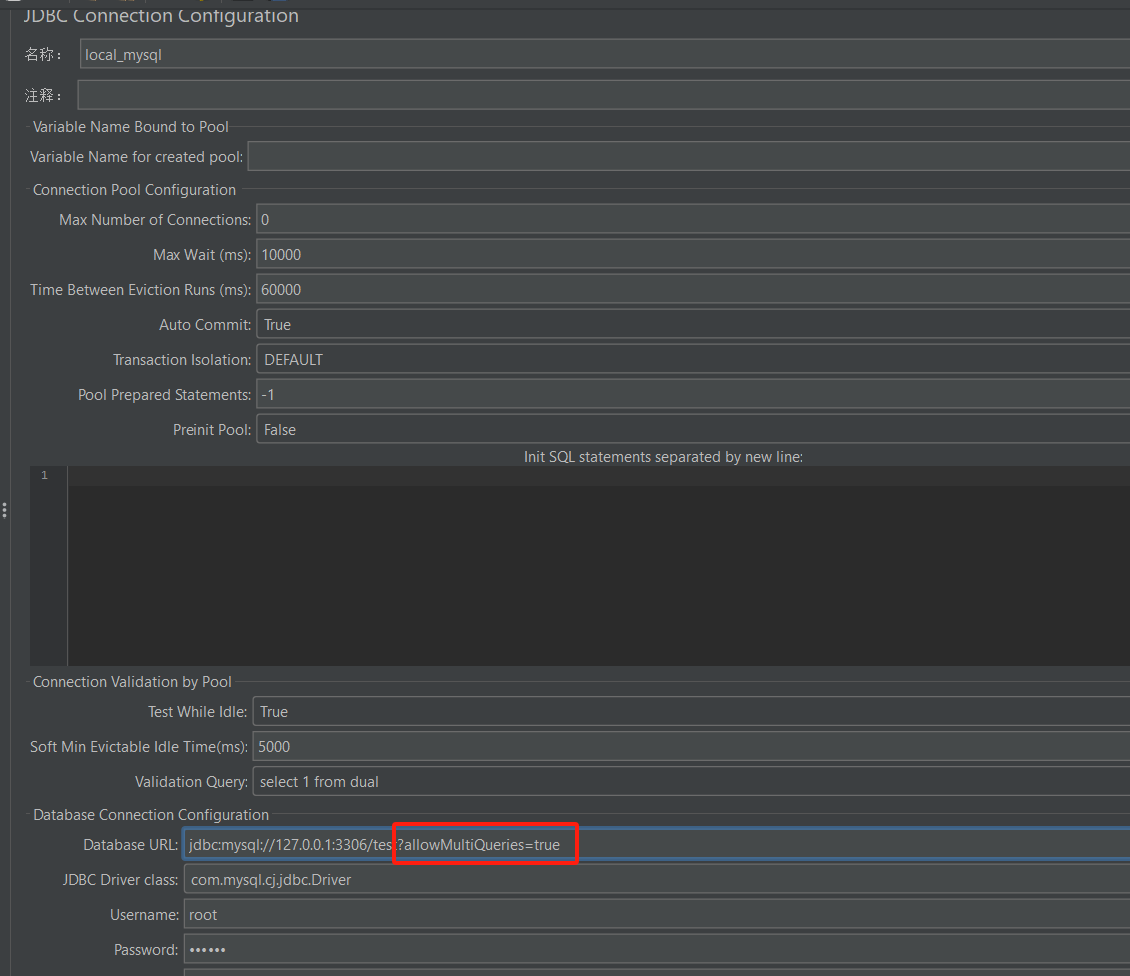
- jdbc 配置中增加?allowMultiQueries=true
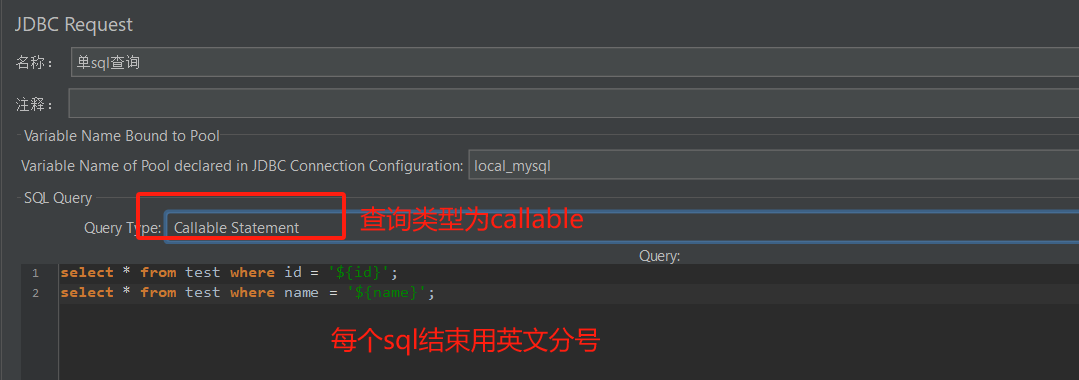
- jdbc request配置
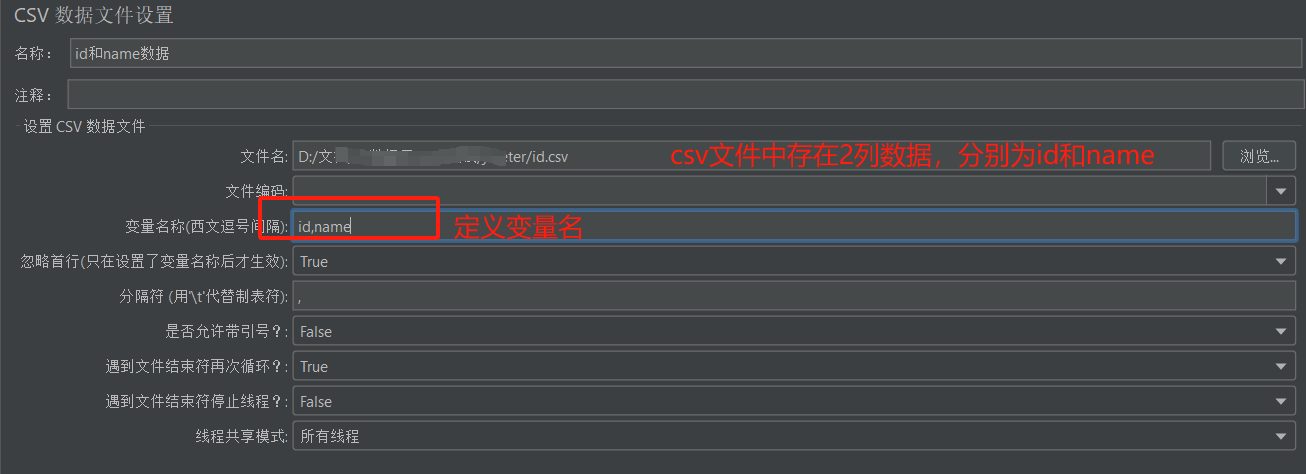
- csv配置信息
(三)、多个线程组执行不同类型sql
场景:
连接tidb数据库127.0.0.1 端口3306,账户:root,密码:3306
开启1个线程执行sql1:select * from test where id = '?'
开启2个线程执行sql2:update test set create_time = now() where name = '?',
参数动态从csv中获取,两组线程都持续运行30s。
- 总体的配置如下
在测试计划下维护jdbc配置信息,提供给线程组1和线程组2共同使用。
这里我想看一个总体结果,所以汇总报告和结构树放在测试计划下面,而不是每个线程组下。如果想查看每个线程组的汇总报告,可以在每个线程组下放汇总报告和结果树。
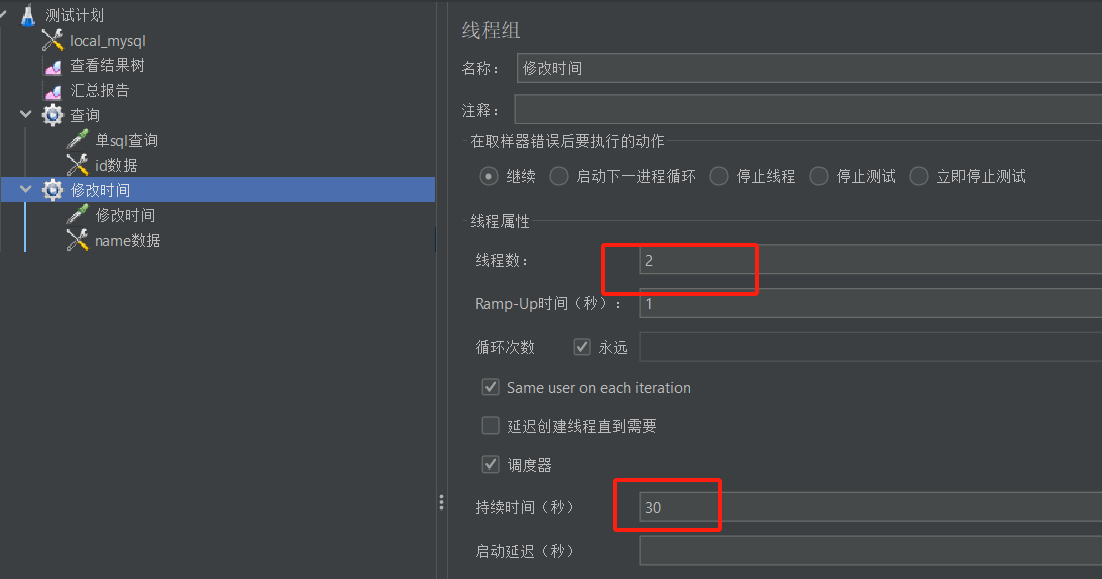
- 线程组1开启了1个线程,持续30s。
- 线程组2开启了2个线程,持续30s。
五、linux下使用上述配置进行压测
- 在上述的可视化界面中编辑完配置,ctrl + s 保存配置到本地,比我我保存的为 yc.jmx
- 记得上传jdbc驱动jar到linux环境下的jmeter中lib下。
- 把yc.jmx和csv上传到装有jmeter的linux上。
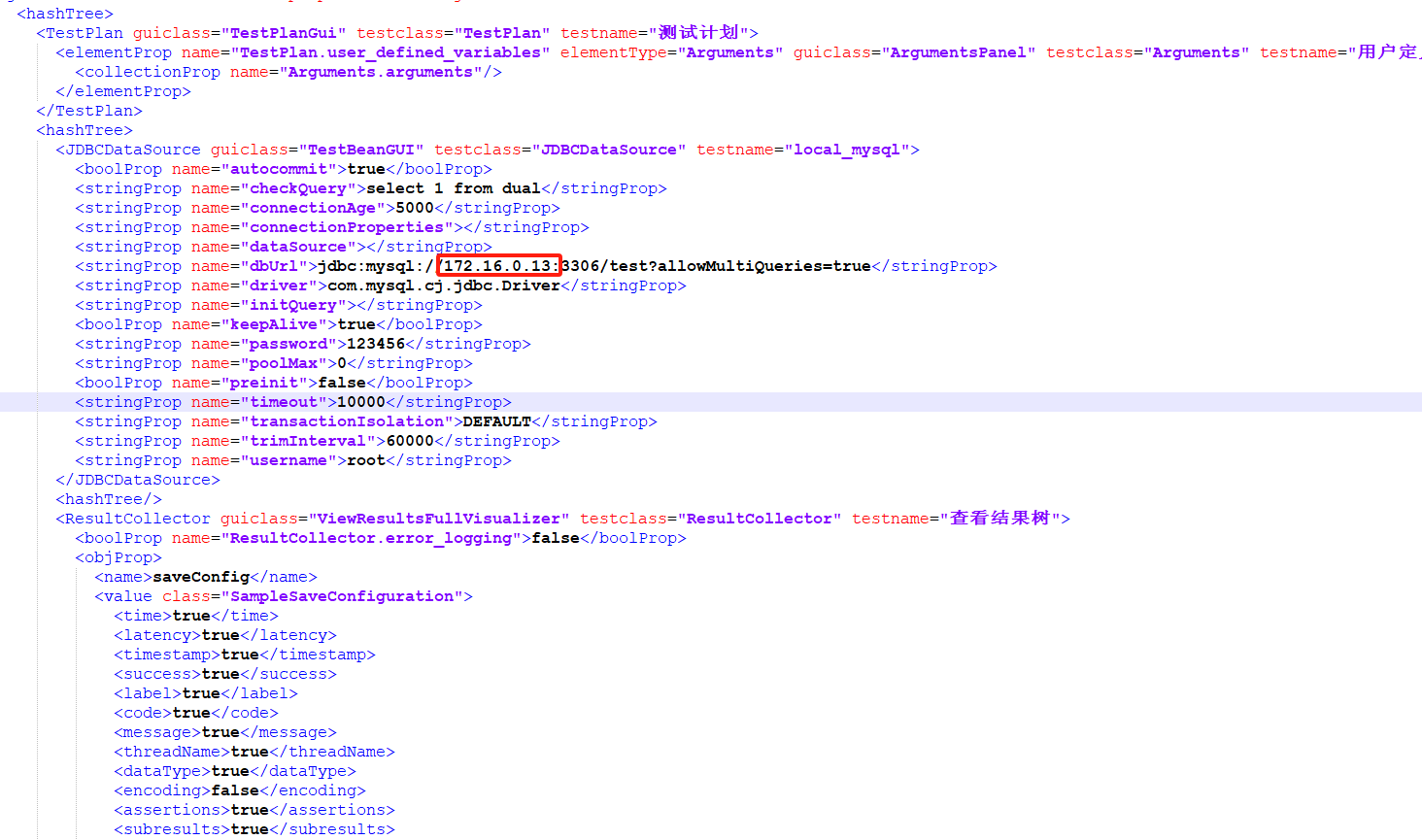
- 如果想修改个别参数,可以直接编辑yc.jmx文件即可。如下修改数据库连接为172.16.0.13
- 修改查询线程组的线程数为5

- 修改csv的路径为当前目录(即和jmx文件相同目录)
- 执行如下命令进行压测:
#jmeter -n -t test-file [-p property-file] [-l results-file] [-j log-file] # -n -t 后指定配置文件jmx,-l 是导出压测结果到文件jtl,-j是输出log文件。 jmeter -n -t ./yc.jmx -l ../test/yc.jtl
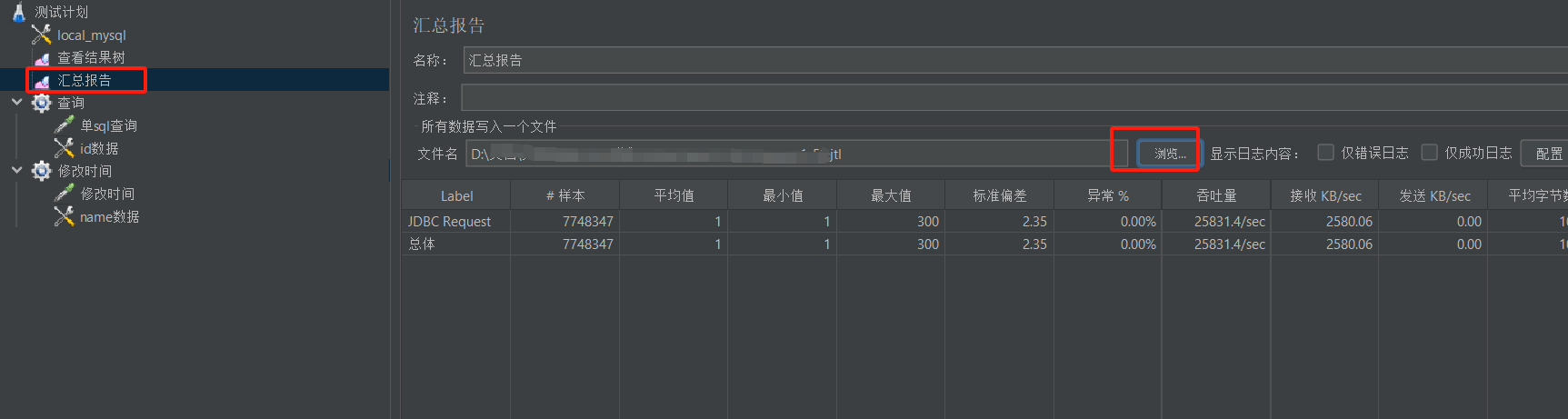
- 把yc.jtl文件导入到windows可视化工具查看结果,查看汇总报告:
打开汇总报告,选择文件yc.jtl, 可以加载如下的压测数据信息
六、总结
JMeter是个开源的工具,支持各种的压测场景,不管是对tidb还是对其他数据库都存在高度的支持。还可以根据自己的业务场景定制化不同的脚本来执行压测操作。
以上是本人使用过程中的场景总结,希望给大家提供帮助。