一、概述
title:Dr. LLaMA: Improving Small Language Models in Domain-Specific QA via Generative Data Augmentation
论文地址:Paper page - Dr. LLaMA: Improving Small Language Models in Domain-Specific QA via Generative Data Augmentation
代码:GitHub - zguo0525/Dr.LLaMA
1.1 Motivation
- 大模型LLM训练成本比较高,如果想引入一些特定领域的知识,对其进行重新训练,开销比较大。
- 小模型SML由于capacity有限同时训练数据有限,表现效果也不好。
1.2 Methods
- 利用LLMs做数据增强小模型的训练数据
1.3 Conclusion
- 大模型可以有效的refine和生成各式各样的QA对数据,利用这些领域内的数据进行fine-tuning后,小的多的模型在该领域上可以带来一个不错的提升。
- Prefix Tuning and Low-rank Adaptation对于SLMs是一个有效的训练方法,并且low-rank adaptation对超参数选择上比较鲁棒。
- 大模型LLMs在领域知识上做fine-tuning能极大的提升特定领域任务的表现。
- 结合知识蒸馏,对比学习等技术,加上本文提到的利用LLM做数据增强的方法,训练SLMs小预训练模型来解决特定领域的应用上可能更有效。
二、详细内容
1 小模型经过微调后于大模型Chatgpt3.5-turbo以及GPT-4对比

- 1.6B的小模型微调后效果比130+B的大模型效果还要好
2 本文用到的微调技术
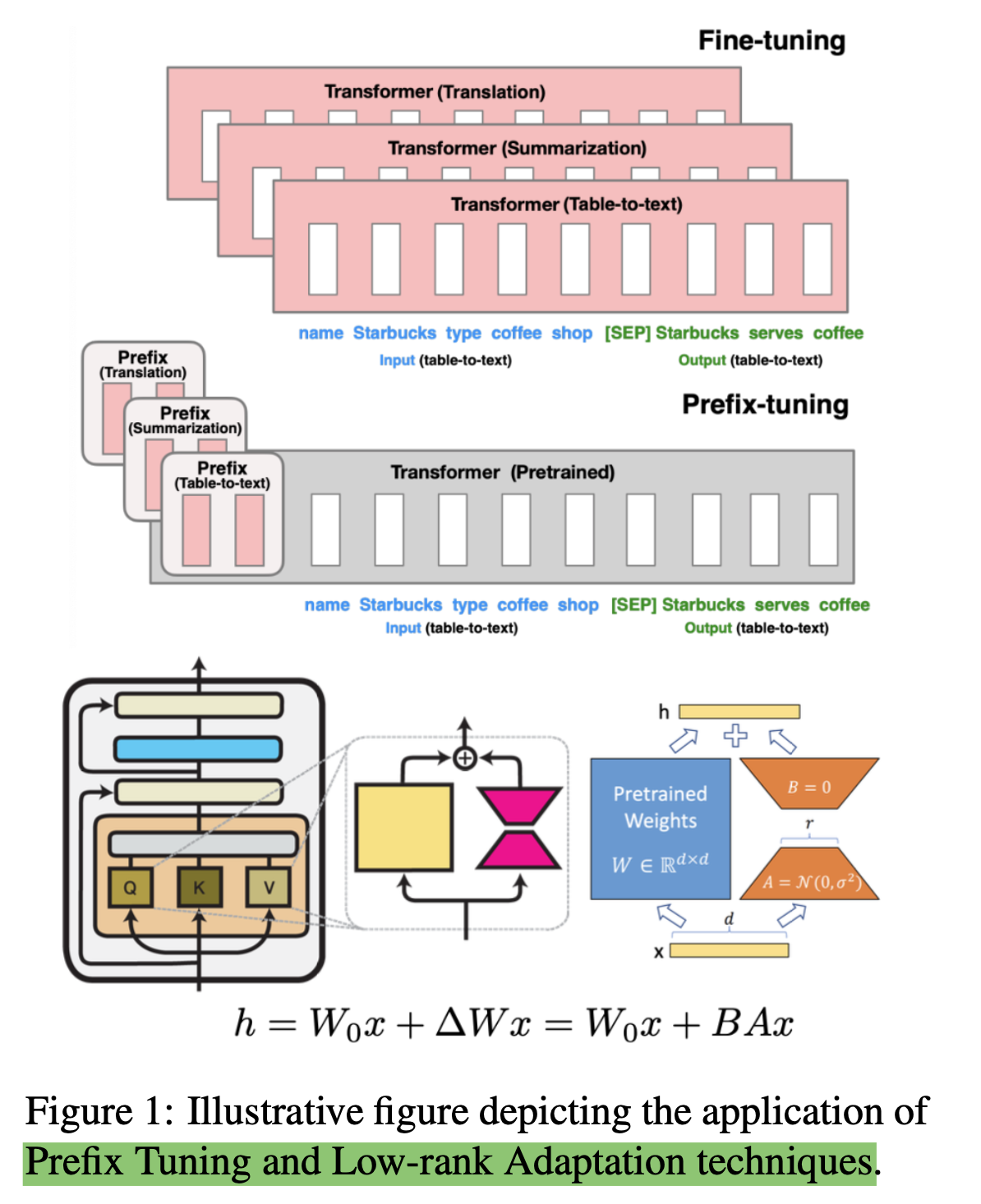
- 主要用了Prefix Tuning和low-rank Adaptation
3 不同模型效果对比

- Alpaca-7b是LLamA-7b衍生过来,但是做了instruction-tuned,限制了其适应领域知识的能力,效果比较差。
- fine-tuning可能比特定领域预训练重要
- LLaMA-7b虽然比BioGPT大很多,但是也可以单卡跑起来,后续作用可能比较大
4 哪种数据增强的效果比较好?
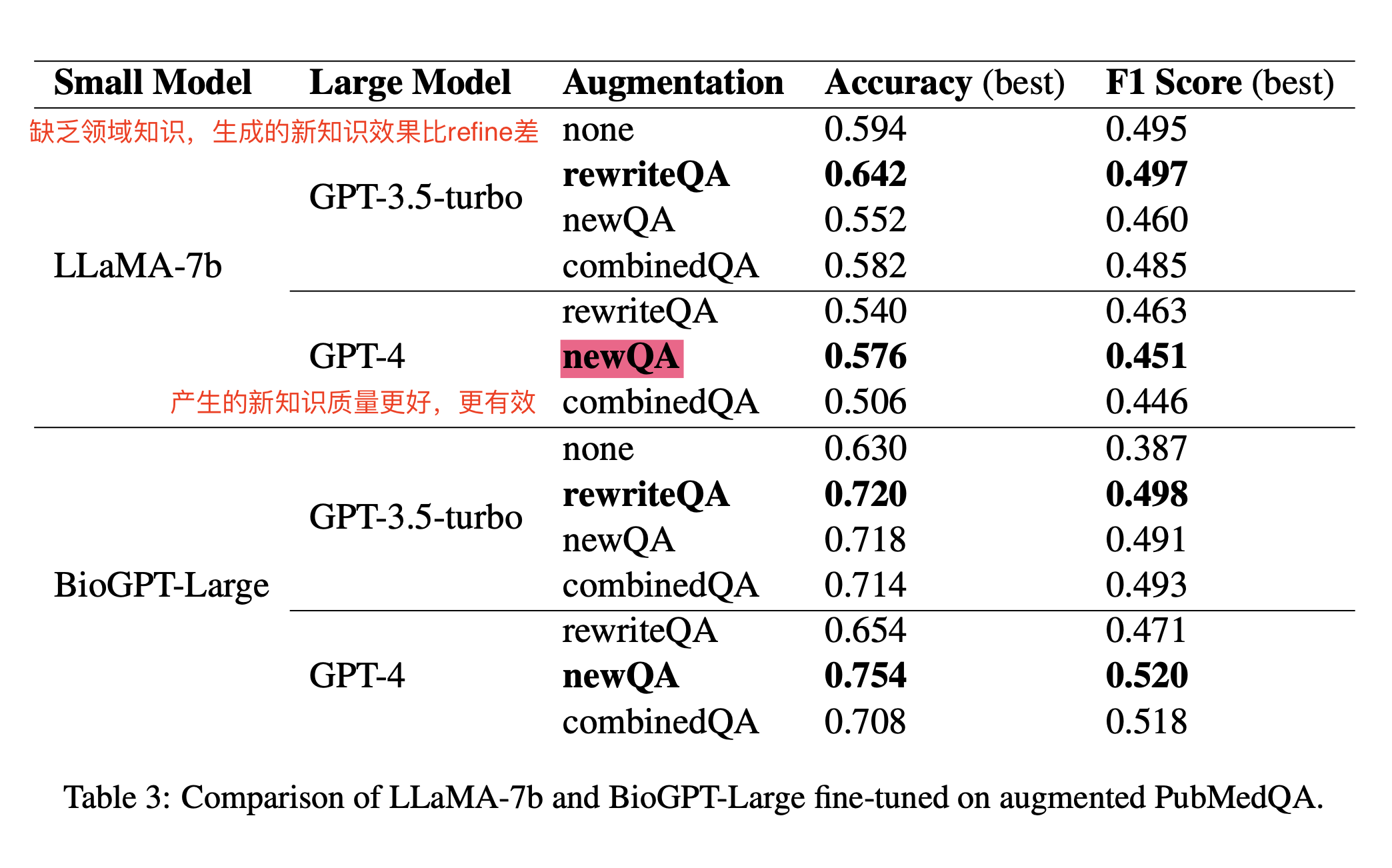
- rewriteQA:重新改写已有的QA对,使其多样化
- newQA:生成新的QA对
- 结论1:GPT-3.5-turbo:有能力去使已有的QA对refine和多样化,给模型带来一定提升,但是缺乏领域知识,生成的新的QA来做数据增强对并不能带来效果提升。
- 结论2:GPT-4有pubmedQA的领域知识,生成的新的QA对质量更高,所带来的提升也越大。
- 结论3:BioGPT-Large:在医疗领域进行了预训练,效果还是比没有经过预训练的LLaMA-7b要好,还是说明了领域预训练的重要性。