#### 任务八:使用Word2Vec词向量,搭建BILSTM模型进行训练和预测
- 说明:在这个任务中,你将使用Word2Vec词向量,搭建BILSTM模型进行文本分类的训练和预测,通过双向长短期记忆网络来进行文本分类。
- 实践步骤:
- 准备Word2Vec词向量模型和相应的训练数据集。
- 构建BILSTM模型,包括嵌入层、BILSTM层、全连接层等。
- 将Word2Vec词向量应用到模型中,作为词特征的输入。
- 使用训练数据集对BILSTM模型进行训练。
- 使用训练好的BILSTM模型对测试数据集进行预测。
from gensim.models.word2vec import Word2Vec
import pandas as pd
import numpy as np
from collections import defaultdict
from gensim import corpora
import tensorflow as tf
import tensorflow as tf
from tensorflow import keras
from tensorflow.python.keras import layers, optimizers
from keras.preprocessing.sequence import pad_sequences
# reference: https://www.kaggle.com/code/stoicstatic/twitter-sentiment-analysis-using-word2vec-bilstm
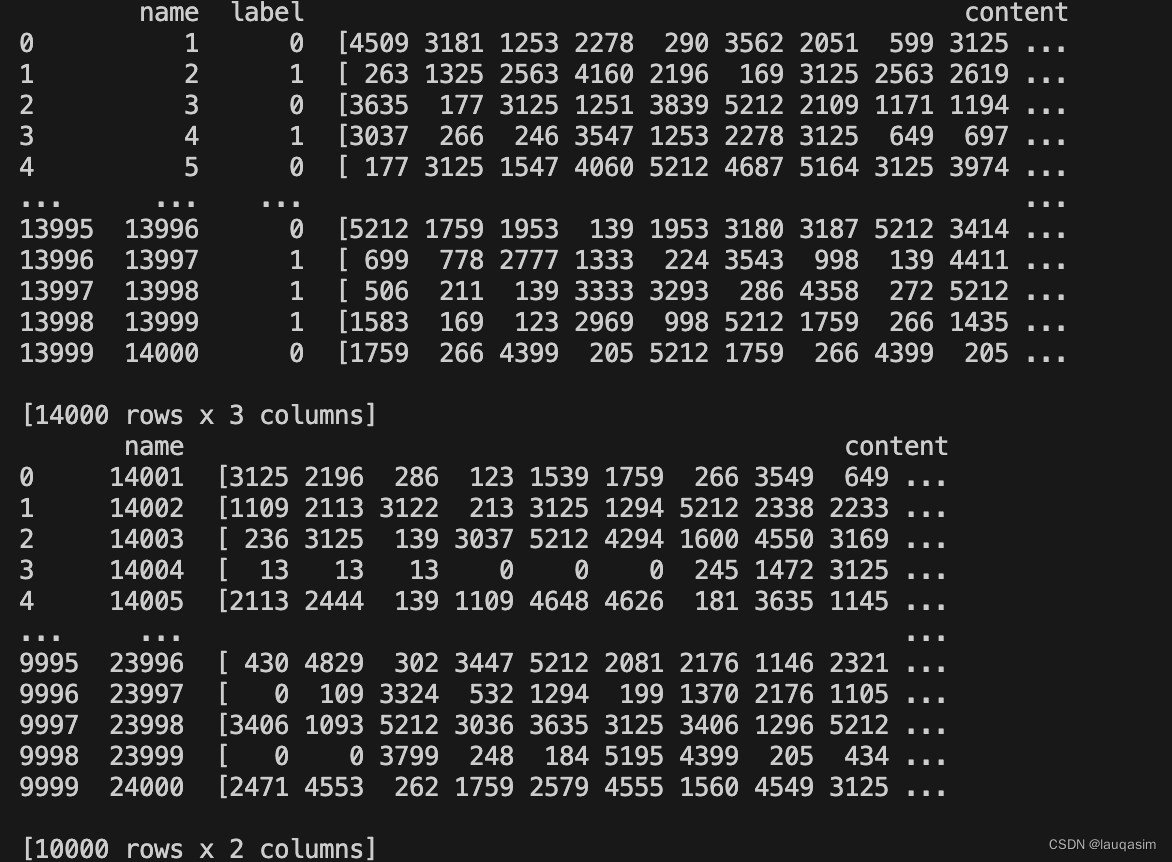
train_data = pd.read_csv('./ChatGPT生成文本检测器公开数据-更新/train.csv')
test_data = pd.read_csv('./ChatGPT生成文本检测器公开数据-更新/test.csv')
# 对输入的内容进行处理
train_labels = train_data['label']
train_data['content'] = train_data['content'].apply(lambda x: x[1:-1].strip().replace('\n', ' \n '))
test_data['content'] = test_data['content'].apply(lambda x: x[1:-1].strip().replace('\n', ' \n '))
train_data['content'] = train_data['content'].apply(lambda x: x.split(' '))
test_data['content'] = test_data['content'].apply(lambda x: x.split(' '))
train_data['content'] = train_data['content'].apply(lambda x: [i for i in x if i != '' and i != '\n'])
test_data['content'] = test_data['content'].apply(lambda x: [i for i in x if i != '' and i != '\n'])
train_data = train_data['content']
test_data = test_data['content']
# 加载Word2Vec词向量模型
word2vec_model = Word2Vec.load("word2vec.model")
# 获取Word2Vec词向量的维度
embedding_dim = word2vec_model.vector_size
print('embedding_dim', embedding_dim)
# 词典大小
vocab = word2vec_model.wv.key_to_index
vocab_length = len(vocab)
# Defining the model input length.
input_length = 200
X_train = pad_sequences(train_data, maxlen=input_length)
X_test = pad_sequences(test_data, maxlen=input_length)
print("X_train.shape:", X_train.shape)
embedding_matrix = np.zeros((vocab_length, embedding_dim))
for word, i in vocab.items():
try:
embedding_vector = word2vec_model.wv[str(word)]
embedding_matrix[i] = embedding_vector
except KeyError:
continue
print("Embedding Matrix Shape:", embedding_matrix.shape)
def getModel():
embedding_layer = layers.Embedding(input_dim = vocab_length,
output_dim = embedding_dim,
weights=[embedding_matrix],
input_length=input_length,
trainable=False)
model = tf.keras.Sequential([
embedding_layer,
layers.Bidirectional(layers.LSTM(100, dropout=0.3, return_sequences=True)),
layers.Bidirectional(layers.LSTM(100, dropout=0.3, return_sequences=True)),
layers.Conv1D(100, 5, activation='relu'),
layers.GlobalMaxPool1D(),
layers.Dense(16, activation='relu'),
layers.Dense(2, activation='softmax'),
],
name="Sentiment_Model")
return model
training_model = getModel()
print(training_model.summary())
training_model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# from keras.callbacks import ReduceLROnPlateau, EarlyStopping
# callbacks = [ReduceLROnPlateau(monitor='val_loss', patience=5, cooldown=0),
# EarlyStopping(monitor='val_accuracy', min_delta=1e-4, patience=5)]
# 转换训练数据集的标签为one-hot编码
train_labels = tf.keras.utils.to_categorical(train_labels)
history = training_model.fit(
X_train, train_labels,
batch_size=1024,
epochs=10,
validation_split=0.1,
# callbacks=callbacks,
verbose=1,
)
#模型的保存
training_model.save('BiLSTM-model-epoch10.h5')
# 预测测试数据集的分类结果
predictions = training_model.predict(X_test)
predicted_labels = predictions.argmax(axis=1)
# 读取提交样例文件
submit = pd.read_csv('./sample_submit.csv')
submit = submit.sort_values(by='name')
# 将预测结果赋值给提交文件的label列
submit['label'] = predicted_labels
# 保存提交文件
submit.to_csv('./bilstm.csv', index=None)
效果一般