#### 任务二:对数据集字符进行可视化,统计标签和字符分布
- 说明:在这个任务中,你需要使用Pandas库对数据集的字符进行可视化,并统计数据集中的标签和字符的分布情况,以便更好地理解数据集。
- 实践步骤:
- 使用Pandas库读取和加载数据集。
- 使用Pandas的可视化功能,如柱状图或饼图,对数据集的字符进行可视化展示。
- 使用Pandas的统计功能,如value_counts()方法,统计数据集中的标签和字符的分布情况。
1.查看前十频数
import pandas as pd
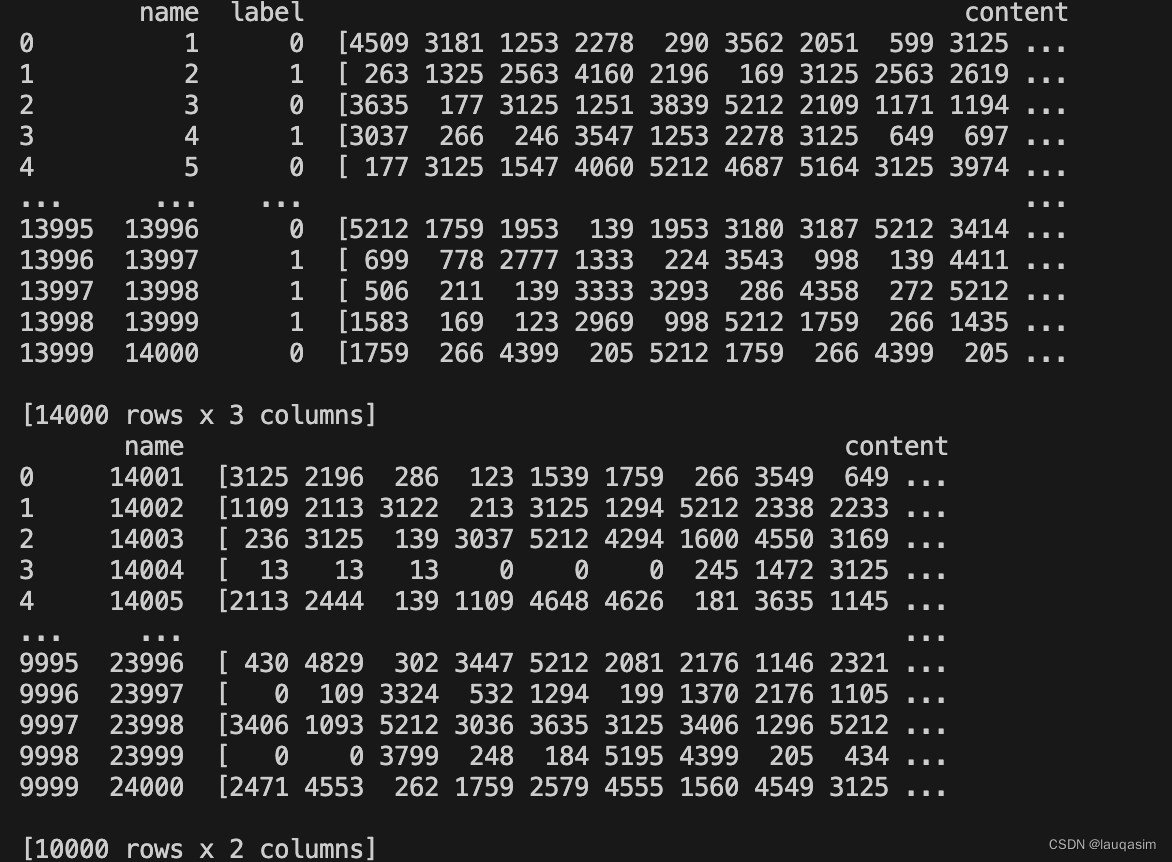
train_data = pd.read_csv('./ChatGPT生成文本检测器公开数据-更新/train.csv')
test_data = pd.read_csv('./ChatGPT生成文本检测器公开数据-更新/test.csv')
# 对输入的内容进行处理
train_data['content'] = train_data['content'].apply(lambda x: x[1:-1].strip().replace('\n', ' \n '))
test_data['content'] = test_data['content'].apply(lambda x: x[1:-1].strip().replace('\n', ' \n '))
train_data['content'] = train_data['content'].apply(lambda x: x.split(' '))
test_data['content'] = test_data['content'].apply(lambda x: x.split(' '))
train_data['content'] = train_data['content'].apply(lambda x: [i for i in x if i != ''])
test_data['content'] = test_data['content'].apply(lambda x: [i for i in x if i != ''])
# print(train_data)
# 统计字符出现的频次并输出前10个最常见的字符
from collections import Counter
import seaborn as sns
import matplotlib.pyplot as plt
def huatu(data, ax, title):
c = Counter()
for content in data['content']:
c.update(content)
print(c.most_common(10))
x, y = zip(*c.most_common(10))
print(x, y)
for content in test_data['content']:
c.update(content)
# plotting columns
sns.barplot(x=list(x), y=list(y), ax=ax)
ax.set_title(title)
# creating subplots
ax, (train_ax, test_ax) = plt.subplots(2, 1, figsize=(10, 10))
huatu(train_data, train_ax, 'train')
huatu(test_data, test_ax, 'test')
plt.show()

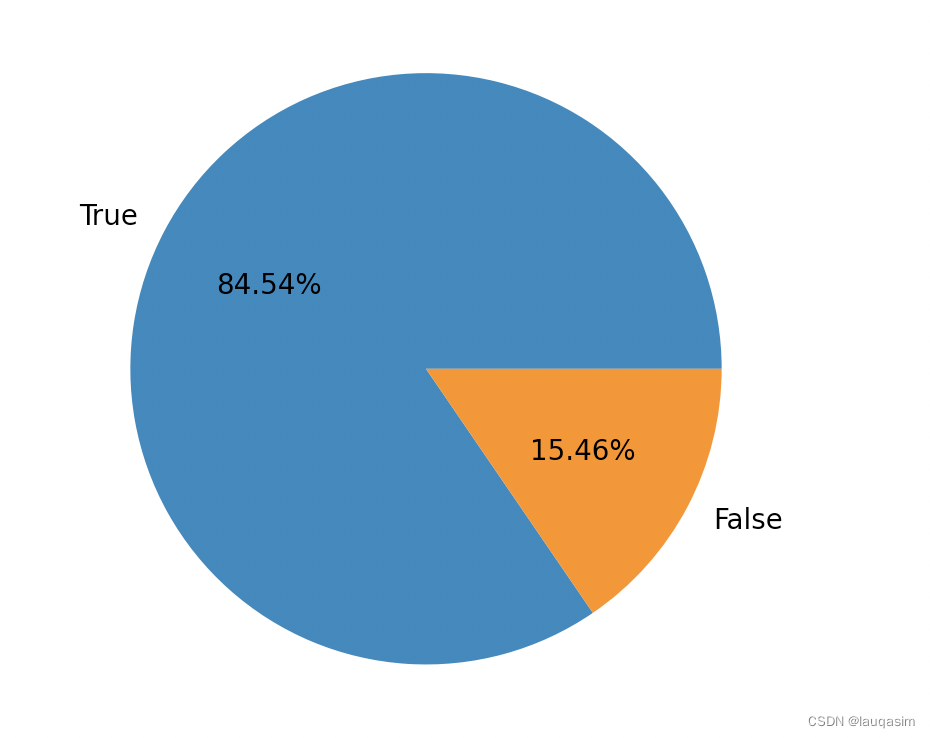
2.正负比例:正负比例近似各占一半
def label_true_or_false_counts(data):
TrueAndFalse = data['label'].value_counts().tolist()
TrueRatio = TrueAndFalse[0]/data.shape[0]
print(TrueRatio)
FalseRatio = TrueAndFalse[1]/data.shape[0]
print(FalseRatio)
label_true_or_false_counts(train_data)
# 0.8454285714285714
# 0.15457142857142858