Attention
首先谈一谈attention。
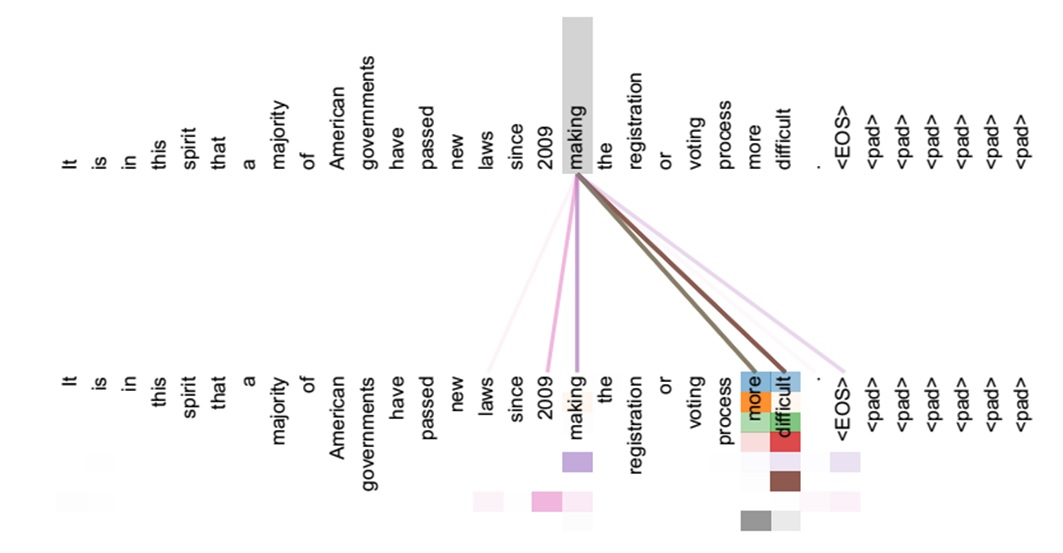
注意力函数其实就是把一个query,一个key-value的集合映射成一个输出。其中query,key,value,output(Attention Value)都是向量。输出是values的加权求和,是query与当前key的相关程度。
Attention 函数的本质可以被描述为:
一个查询(query)到一个系列(键key-值value)对的映射。
例如:计算A与B的attention,就是用A的Q与B的K-V来计算。

Scaled Dot-Product Attention(缩放点乘积注意力)(常用)

微观下的Attention
什么是Q(查询向量)、K(键向量)和V(值向量)?
每一个词向量,都有自己的QKV。通过矩阵变换而来,矩阵可以学习得到。这里Thinking为词向量X1,Machine为词向量X2。分别经过矩阵变换得到自己的QKV。

多头注意力机制
多头 Attention(Multi-head Attention)结构如下图。

微观下的多头Attention

这里说一下我的理解
八个头相当于八个不同的表征子空间,类似于apple拥有水果的含义,同时也有商标的含义,不同的含义由不同的表征子空间学习。让其他词的Q来和apple这个词不同组的K-V进行attention。再把所有的attention结果拼接起来,通过一个全连接层(矩阵变换)得到最终结果。

参考博客:
图解Transfomer
NLP中的attention