| 论文名字 | Video Object Segmentation and Tracking A Survey |
| 来源 | arXiv 论文地址:http://arxiv.org/abs/1904.09172?context=cs.CV |
| 年份 | 2019.4.26 |
| 作者 | RUI YAO, GUOSHENG LIN, SHIXIONG XIA, JIAQI ZHAO, YONG ZHOU |
| 核心点 | 对现有的VOST算法进行分类,对不同方法的技术特征概述,总结相关视频数据的数据集的特征和提供多种评估方法。 |
| 阅读日期 | 2020.11.2 |
| 影响因子 |
|
| 内容总结 | |
| 文章主要解决的问题及解决方案: 对现有的VOST算法进行分类,对不同方法的技术特征概述,总结相关视频数据的数据集的特征和提供多种评估方法。
文章的主要工作: ①如图1所示,在视频对象分割和跟踪中提供了一种分层分类的现有方法。我们大致将方法分为5类。然后,对于每个类别,不同的方法被进一步分类。 ②我们对无监督的VOS、半监督的VOS、交互式VOS和基于分割的跟踪中不同方法的技术特征进行了详细的讨论和概述。 ③总结相关视频数据集的特点,提供多种评价指标。
文章内容: ①无监督VOS和交互VOS代表着两个极端,前者没有任何输入,仅通过自上而下的过程产生连贯的时空区域;后者使用强监督交互方法,要求第一帧的像素级精确分割。半监督VOS:要求手动标注定义什么是前景对象,任何自动分割到序列的其余帧。 ②介绍VOST: [36]VOST方法被广泛应用于利用多个视频中的视觉对象的视频摘要 [138]提供一个帮助视频检索或网页浏览的有用工具 [85]VOST被用于视频编码标准MPEG-4,以实现基于内容特征和高编码效率 [37]提供的基于内容的表示将视频镜头编码为在补偿运动对象之后获得静止背景马赛克。 [183]VOST可以估计非刚性目标,以实现精确的跟踪定位和掩模描述,这可以识别其他运动指令。 ③VOST的问题: 1)哪些图像特征适合VOST? 2)哪些对象表示(即点、超像素、patch、对象)适合VOS? 3)哪些图像特征适合VOST? 4)如何模拟物体在VOST的运动 5)如何对基于CNN的VOS方法进行预处理和后处理 6)哪些数据集适合评价VOST,它们的特点是什么? ④VOST的五个分类方向:无监督的VOS、半监督的VOS、交互式VOS、弱监督的VOS以及基于分割的跟踪方法么。VOST方法如图1所示。 ⑤无监督方法: [100]第一个使用互补卷积神经网络生成显著性对象 [43,159,160,166]双分支CNN分割视频对象。 [159]MP-Net取视频序列中连续两个帧作为输入,产生每像素运动标签。 [160]做了一些改进。 [43]提出一个具有外观和光流运动的双流网络。 [166]SfM-Net结合了两个流运动和结构,通过可区分的渲染来学习对象masks和没有masks注释的运动模型。 无监督的方法计算耗费大。 ⑥半监督方法: 半监督是在第一帧的时候给masks 半监督分为两类:spatio-temporal graph和基于CNN的半监督VOS Motion-based methods.: [107][110]卷积神经网络在静态图像分割上的成功。 [32,69,78,102]使用光流训练网络。 使用光流作为线索来随着时间跟踪像素以建立时间相干性。 [32]SegFlow[192]MoNet[112]PReMVOS[83]LucidTrack[102]VS-ReID [41,74]FlowNet [78]提出一种时间双向网络,通过光流作为附加特征,以自适应方式传播视频帧 [10]利用光流建立时间相关性,在基于CNN的时间和空间MRF [69]利用光流上的活动轮廓分割运动目标。 [70,102]为捕获时间相干性,一些方法使用递归神经网络(RNN)来用光流建立masks传播 [125]使用CNN方法,根据前一帧的估计当前帧的mask。 Detection-based methods: [22]介绍一种在线训练过程,通过一个FCN对静态图像进行一次视频对象分割(OSVOS),该过程在目标视频的第一帧对一个预处理卷积神经网络进行fine-tuned。 [113]它们用明确的语义信息扩展了对象的模型,并极大地改进了结果 [167]提出了在线自适应视频对象分割,网络在线微调以适应外观的变化。 [30]提出了一种基于每帧中的成对相似性在空间上传播粗略分割mask的方法。 [147]提出一种像素级匹配网络,基于两个对象单元之间的像素级相似性来区分对象区域和背景, [29]提出一种用于视频对象分割的嵌入空间中的像素检索问题。 [72]视频匹配方法将提取的特征匹配到提供的模板,而不需要记忆对象的外观。 Fine-tuning: [22,125,167]网络使用在线fine-tuned,使用视频测试视频的第一帧来记忆目标对象的外观,导致性能的提升。 上述方法不适用于外观有大变化的情况,[10,22,69,83,113,192]由视点的剧烈变化引起的,fine-tuned模型很难推广到新的物体外观。 [118,167]使用在线update the network的方法 Computational speed: 在线fine-tuned耗费资源,[29,31,72,197]工作时不需要在线测试时间内进行计算上的昂贵的fine-tuned。 Post-processing: 后处理通常用于改善轮廓,如边界捕捉[22,113] [30,147]参考频率感知滤波器 [10,125]中的密集MRF或CRF [91]。 [22]OSVOS执行边界捕捉,将前景遮罩捕捉到精确的轮廓。 [147]对得到的分割掩模进行加权中值滤波。 [102]还考虑了链接轨迹的后处理步骤。 [10,83,192]一些VOS框架 Data augmentation.: [83]提出一种用于在线学习的大量数据扩充的策略。 [32,78,112,144]在从第一帧GT生成的一大组增强图像上对训练网络进行微调。 ⑦交互式视频对象分割: [13,23,29,114]交互式分割网络 [22]基于OSVOS技术的深度交互式图像和视频对象分割方法。 ⑧弱监督视频对象分割: [170]在弱监督语义视频对象分割的目标域中将CNN的识别和表示能力与未标记数据的内在结构相结合,以提高推理性能。 [84]使用自然语言表达式来识别视频中的目标对象 ⑨基于分割的跟踪方法: [174,207]使用CNN框架来执行视觉对象跟踪和半监督视频对象分割。 [174]提出一种Siamese network估计二值分割mask,bounding box,和相应的对象/背景分数 [207]建立一个双分支网络,即外观网络和轮廓网络。 跟踪输出和分割结果相互补充。 ⑩数据集和评估方法: 数据集:表7 评估方法: [126]对于视频对象分割,标准评估度量具有三个度量,即分割的空间精度、轮廓相似性的一致性和时间稳定性。 三个参数:1)区域相似性 IoU;2)精密度Pc和召回率Rc,F-measure;3)时间稳定性 [187][92]广泛应用于单目跟踪算法
附录:
图1 VOST方法
Table1 Summary of some major unsupervised VOS methods. #: number of objects, S: single, M: multiple.(仅截取CNN方法)
Table 3. Summary of convolutional neural network based semi-supervised video object segmentation methods. M/D: motion-based and detection-based methods. Post-pro.: post-processing. Data aug.: data augmentation.
Table 4. Summary of interactive video object segmentation methods. #: number of objects, S: single, M: multiple.
Table 6. Summary of joint segmentation-based tracking methods. #: number of objects, S: single, M: multiple. Box and Mask: the bounding box and mask of the object
Table 7. Brief illustration of datasets that are used in the evaluation of the video object segmentation and tracking methods. V #: number of video. C #: number of categories. O #: number of objects. A #: annotated frames. U, S, I, W, T: unsupervised VOS, semi-supervised VOS, interactive VOS, weakly supervised VOS, and segmentation-based tracking methods. Object pro.: object property, T. of methods: type of methods.
| |
论文阅读:Video Object Segmentation and Tracking A Survey






本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/53214.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

「都是url惹的祸」(问题:小数点参数被截取|刷新页面找不到资源)
问题背景: 在开发的时候有个页面跳转的需求点并且需要带着五个参数飞过去,其中包含版本号(就是有小数点的数字,这也是遇到的一个问题一会聊一哈),本来触发完事件横跳过去没有问题,寻思着看一下N…
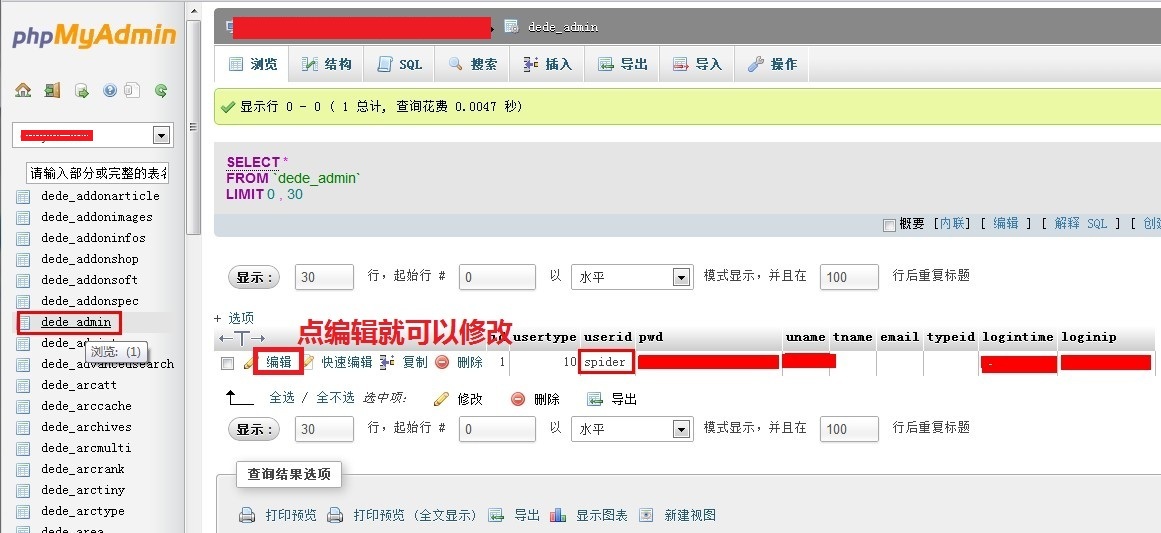
mysql用户名不存在_dedecms系统后台登陆提示用户名密码不存在
dedecms最近被曝有非常多的安全漏洞,最近有些用户反应后台管理员账号密码没有修改但无法正常登陆,提示用户名不存在,经研究发现是程序漏洞管理员被直接篡改,解决方案如下。 一、请先使用phpmyadmin登陆mysql管理,虚拟主…

桂林三金,吃不到中药股红利
如果说,国货品牌崛起的大潮本质上是国家的崛起,而非货的崛起。那么,中药的一时火热,靠的也不是疗效,是文化自信。
文化自信改变不了中药的疗效,但可以提升消费者对中药的信心。片仔癀靠着独家秘方…

如何实现沉浸式旅游与非物质文化遗产的共同发展
中国非物质文化遗产资源丰富,是世界上非物质文化遗产数量最多的国家。丰富多样的资源为非物质文化遗产旅游业的建设提供了良好的基础。非物质文化遗产旅游是基于非物质文化遗产资源开发的文化旅游消费形式。文化资源包括各民族代代相传的传统文化表现形式。非物质文…

@河南省文旅厅 携手让非遗“活”起来!
太极拳申遗成功两周年之际 河南省文化和旅游厅联合百度智能云 打造的“太极拳一张图” 正式上线啦! 河南省是我国非物质文化遗产资源大省,此次推出的“太极拳一张图”正是河南省贯彻落实二十大精神,深入推进非遗数字化保护体系建设和传播推广…
小红书百万博主如何炼成?美妆博主专访
“在小红书上如何快速涨粉?”是大家长期以来的疑惑,为此我们找到了小红书美妆博主小颠儿kini,让我们看看他在成为百万博主的道路上都总结了哪些心得吧! 采访手记:截止到发稿,美妆博主小颠儿kini在小红书上的…

基于Java Web技术的动车购票系统
毕 业 设 计 中文题目基于Java Web技术的动车购票系统英文题目Train ticket system based on Web JavaTechnology 毕业设计诚信声明书 本人郑重声明:在毕业设计工作中严格遵守学校有关规定,恪守学术规范;我所提交的毕业设计是本人在 指导教师…
深入理解注意力机制(Attention Mechanism)和Seq2Seq
学习本部分默认大家对RNN神经网络已经深入理解了,这是基础,同时理解什么是时间序列,尤其RNN的常用展开形式进行画图,这个必须理解了。
这篇文章整理有关注意力机制(Attention Mechanism )的知识࿰…
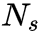
Attention注意力机制学习(一)------->SENet
目录
前言
论文
注意力机制
Squeeze-and-Excitation (SE) 模块
第一步Squeeze(Fsq)
第二步excitation(Fex)
SE注意力机制应用于inception和ResNet 前言 在深度学习领域,CNN分类网络的发展对其它计算机视觉任务如目标检测和语义分割都起到至关重要的作用&…

Attention,Multi-head Attention--注意力,多头注意力详解
Attention
首先谈一谈attention。
注意力函数其实就是把一个query,一个key-value的集合映射成一个输出。其中query,key,value,output(Attention Value)都是向量。输出是values的加权求和,是qu…


注意力机制(Attention)
注意力机制分类
包括软注意力机制(Soft Attention)和硬注意力机制(Hard Attention)。
硬注意力机制指随机选择某个信息作为需要注意的目标,是一个随机过程,不方便用梯度反向传播计算。软注意力机制指在选…

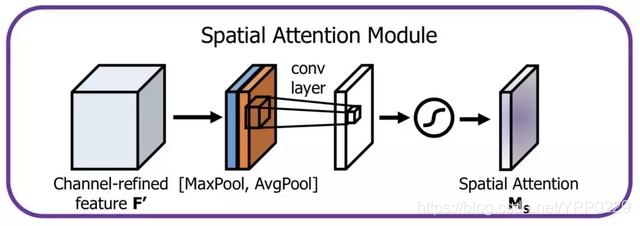
Attention机制理解笔记(空间注意力+通道注意力+CBAM+BAM)
Attention机制理解笔记 声明Attention分类(主要SA和CA)spitial attentionchannel attentionSA CA(spitial attentionchannel attention)加强SACA理解 空间注意力机制和通道注意力机制解释attention机制Attention模型架构1.空间注意力模型(spatial attention)2.通道注意力机制3…

【Attention】注意力机制在图像上的应用
【Attention】注意力机制在图像上的应用 [SeNet] Squeeze-and-Excitation Networks (CVPR2018)[Non-local] Non-local neural Networks (CVPR2018)[GCNet] Non-local Networks Meet Squeeze-Excitation Networks and Beyond 2019-…
注意力机制(Attention Mechanism)-SENet
引言
神经网络中的注意力机制(Attention Mechanism)是在计算能力有限的情况下,将计算资源分配给更重要的任务,同时解决信息超载问题的一种资源分配方案。在神经网络学习中,一般而言模型的参数越多则模型的表达能力越强…
BahdanauAttention与LuongAttention注意力机制简介
在使用tensorflow时发现其提供了两种Attention Mechanisms(注意力机制),如下
The two basic attention mechanisms are:
tf.contrib.seq2seq.BahdanauAttention (additive attention, ref.)tf.contrib.seq2seq.LuongAttention (multiplicat…

注意力机制详解系列(一):注意力机制概述
👨💻作者简介: 大数据专业硕士在读,CSDN人工智能领域博客专家,阿里云专家博主,专注大数据与人工智能知识分享。公众号: GoAI的学习小屋,免费分享书籍、简历、导图等资料,更有交流群分享AI和大数据,加群方式公众号回复“加群”或➡️点击链接。 🎉专栏推荐: 目…
深入理解图注意力机制(Graph Attention Network)
©PaperWeekly 原创 作者|纪厚业 学校|北京邮电大学博士生 研究方向|异质图神经网络及其应用 介绍 图神经网络已经成为深度学习领域最炽手可热的方向之一。作为一种代表性的图卷积网络,Graph Attention Network (GAT) 引入了…
推荐文章
- 合合信息龙湖数科一面
- LeetCode解法汇总2300. 咒语和药水的成功对数
- 如果没有pos信息,只有一些近景的照片,可以用编辑重建大师进行建模吗?
- 中国移动董事长杨杰:云擎未来铸重器,算启新程绘宏图
- # 从浅入深 学习 SpringCloud 微服务架构(六)Feign(3)
- #ARM开发 笔记
- (7)原神各属性角色的max与min
- (done) 声音信号处理基础知识(4) (Understanding Audio Signals for ML)
- (补充)3DMAX初级小白班第三课:创建物体+物体材质编辑
- (离散数学)命题逻辑中的命题符号化
- (六)SQL系列练习题(下)#CDA学习打卡
- (论文解读)Domain Adaptation via Prompt Learning