学习本部分默认大家对RNN神经网络已经深入理解了,这是基础,同时理解什么是时间序列,尤其RNN的常用展开形式进行画图,这个必须理解了。
这篇文章整理有关注意力机制(Attention Mechanism )的知识,主要涉及以下几点内容:
1、注意力机制是为了解决什么问题而提出来的?
2、软性注意力机制的数学原理;
3、软性注意力机制、Encoder-Decoder框架与Seq2Seq
4、自注意力模型的原理。
一、注意力机制可以解决什么问题?
神经网络中的注意力机制(Attention Mechanism)是在计算能力有限的情况下,将计算资源分配给更重要的任务,同时解决信息超载问题的一种资源分配方案。在神经网络学习中,一般而言模型的参数越多则模型的表达能力越强,模型所存储的信息量也越大,但这会带来信息过载的问题。那么通过引入注意力机制,在众多的输入信息中聚焦于对当前任务更为关键的信息,降低对其他信息的关注度,甚至过滤掉无关信息,就可以解决信息过载问题,并提高任务处理的效率和准确性。
这就类似于人类的视觉注意力机制,通过扫描全局图像,获取需要重点关注的目标区域,而后对这一区域投入更多的注意力资源,获取更多与目标有关的细节信息,而忽视其他无关信息。通过这种机制可以利用有限的注意力资源从大量信息中快速筛选出高价值的信息。
二、软性注意力机制的数学原理
在神经网络模型处理大量输入信息的过程中,利用注意力机制,可以做到只选择一些关键的的输入信息进行处理,来提高神经网络的效率,比如在机器阅读理解任务中,给定一篇很长的文章,然后就文章的内容进行提问。提出的问题只和段落中一两个句子有关,其余部分都是无关的,那么只需要把相关的片段挑出来让神经网络进行处理,而不需要把所有文章内容都输入到神经网络中。
(一)普通模式
用数学语言来表达这个思想就是:用表示N个输入信息,为了节省计算资源,不需要让神经网络处理这N个输入信息,而只需要从X中选择一些与任务相关的信息输进行计算。软性注意力(Soft Attention)机制是指在选择信息的时候,不是从N个信息中只选择1个,而是计算N个输入信息的加权平均,再输入到神经网络中计算。相对的,硬性注意力(Hard Attention)就是指选择输入序列某一个位置上的信息,比如随机选择一个信息或者选择概率最高的信息。但一般还是用软性注意力机制来处理神经网络的问题。
注意力值的计算是任务处理中非常重要的一步,这里单独拿出来,完整的带注意力机制的神经网络工作流程在文章的第三部分。
注意力值的计算可以分为两步:
(1)在所有输入信息上计算注意力分布
(2)根据注意力分布来计算输入信息的加权平均。
1、注意力分布
给定这样一个场景:把输入信息向量X看做是一个信息存储器,现在给定一个查询向量q,用来查找并选择X中的某些信息,那么就需要知道被选择信息的索引位置。采取“软性”选择机制,不是从存储的多个信息中只挑出一条信息来,而是雨露均沾,从所有的信息中都抽取一些,只不过最相关的信息抽取得就多一些。
于是定义一个注意力变量来表示被选择信息的索引位置,即
来表示选择了第i个输入信息,然后计算在给定了q和X的情况下,选择第i个输入信息的概率
:
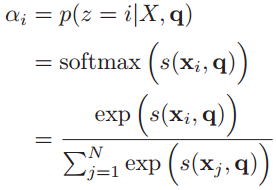
其中构成的概率向量就称为注意力分布(Attention Distribution)。
是注意力打分函数,有以下几种形式:
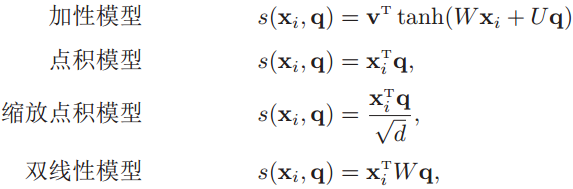
其中W、U和v是可学习的网络参数,d是输入信息的维度。
2、加权平均
注意力分布表示在给定查询q时,输入信息向量X中第i个信息与查询q的相关程度。采用“软性”信息选择机制给出查询所得的结果,就是用加权平均的方式对输入信息进行汇总,得到Attention值:
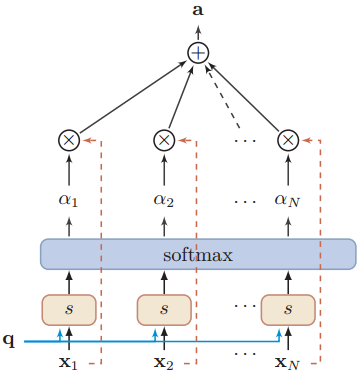
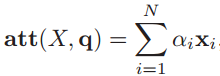 下图是计算Attention值的过程图:
下图是计算Attention值的过程图:
(二)键值对注意力模式
更一般的,可以用键值对(key-value pair)来表示输入信息,那么N个输入信息就可以表示为,其中“键”用来计算注意分布
,“值”用来计算聚合信息。
那么就可以将注意力机制看做是一种软寻址操作:把输入信息X看做是存储器中存储的内容,元素由地址Key(键)和值Value组成,当前有个Key=Query的查询,目标是取出存储器中对应的Value值,即Attention值。而在软寻址中,并非需要硬性满足Key=Query的条件来取出存储信息,而是通过计算Query与存储器内元素的地址Key的相似度来决定,从对应的元素Value中取出多少内容。每个地址Key对应的Value值都会被抽取内容出来,然后求和,这就相当于由Query与Key的相似性来计算每个Value值的权重,然后对Value值进行加权求和。加权求和得到最终的Value值,也就是Attention值。
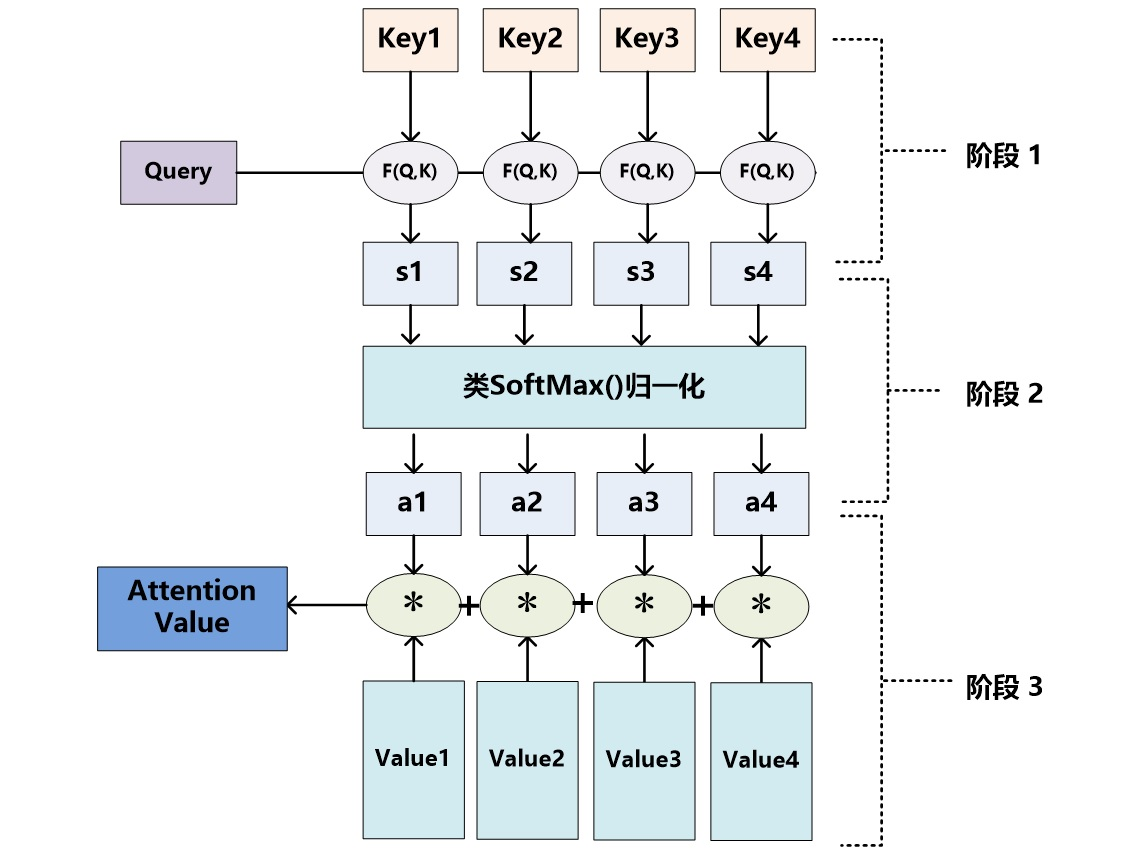
如下图所示,以上的计算可以归纳为三个过程:
第一步:根据Query和Key计算二者的相似度。可以用上面所列出的加性模型、点积模型或余弦相似度来计算,得到注意力得分si;

第二步:用softmax函数对注意力得分进行数值转换。一方面可以进行归一化,得到所有权重系数之和为1的概率分布,另一方面可以用softmax函数的特性突出重要元素的权重;

第三步:根据权重系数对Value进行加权求和:

图示如下:
可以把以上的过程用简洁的公式整理出来:
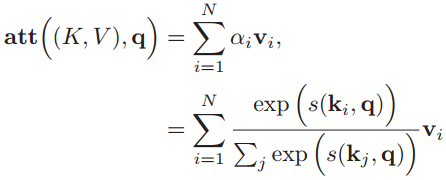
以上就是软性注意力机制的数学原理。
三、软性注意力机制与Encoder-Decoder框架
注意力机制是一种通用的思想,本身不依赖于特定框架,但是目前主要和Encoder-Decoder框架(编码器-解码器)结合使用。下图是二者相结合的结构:
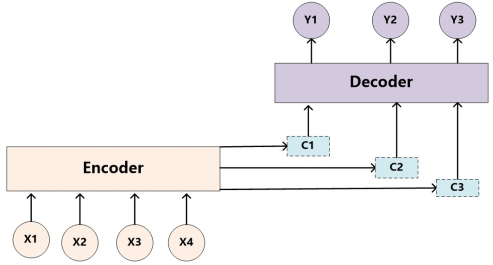
类似的,Encoder-Decoder框架作为一种深度学习领域的常用框架模式,在文本处理、语言识别和图像处理等领域被广泛使用。其编码器和解码器并非是特定的某种神经网络模型,在不同的任务中会套用不同的模型,比如文本处理和语言识别中常用RNN模型,图形处理中一般采用CNN模型。
在前面整理的关于循环神经网络的文章中,说明了以RNN作为编码器和解码器的Encoder-Decoder框架也叫做异步的序列到序列模型,而这就是如雷灌耳的Seq2Seq模型!惊不惊喜,意不意外!?
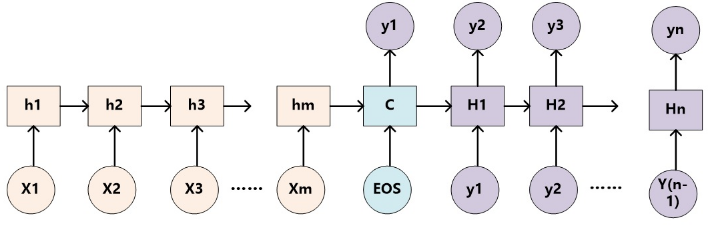
以下是没有引入注意力机制的RNN Encoder-Decoder框架:
下面就以Seq2Seq模型为例,来对比未加入注意力机制的模型和加入了注意力机制后的模型。
(一)未加入注意力机制的RNN Encoder-Decoder
未加入注意力机制的RNN Encoder-Decoder框架在处理序列数据时,可以做到先用编码器把长度不固定的序列X编码成长度固定的向量表示C,再用解码器把这个向量表示解码为另一个长度不固定的序列y,输入序列X和输出序列y的长度可能是不同的。
《Learning phrase representations using RNN encoder-decoder for statistical machine translation》这篇论文提出了一种RNN Encoder-Decoder的结构,如下图。除外之外,这篇文章的牛逼之处在于首次提出了GRU(Gated Recurrent Unit)这个常用的LSTM变体结构。
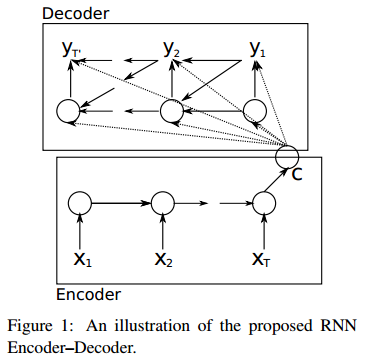
把这种结构用在文本处理中,给定输入序列,也就是由单词序列构成的句子,这样的一个解码-编码过程相当于是求另一个长度可变的序列
的条件概率分布:
。经过解码后,这个条件概率分布可以转化为下面的连乘形式:

所以在得到了表示向量c和之前预测的所有词后,这个模型是可以用来预测第t个词
的,也就是求条件概率
。
对照上面这个图,我们分三步来计算这个条件概率:
1、把输入序列X中的元素一步步输入到Encoder的RNN网络中,计算隐状态ht,然后再把所有的隐状态[h1, h2, ..., hT]整合为一个语义表示向量c:
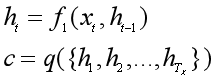
2、Decoder的RNN网络每一时刻t都会输出一个预测的yt。首先根据语义表示向量c、上一时刻预测的yt-1和Decoder中的隐状态st-1,计算当前时刻t的隐状态st:
![]()
3、由语义表示向量c、上一时刻预测的词yt-1和Decoder中的隐状态st,预测第t个词yt,也就是求下面的条件概率。
![]()
可以看到,在生成目标句子的每一个单词时,使用的语义表示向量c都是同一个,也就说生成每一个单词时,并没有产生这样与每个输出的单词相对应的多个不同的语义表示。那么在预测某个词yt时,任何输入单词对于它的重要性都是一样的,也就是注意力分散了。
(二)加入注意力机制的RNN Encoder-Decoder
《Neural Machine Translation by Jointly Learning to Align and Translate 》这篇论文在上面那篇论文的基础上,提出了一种新的神经网络翻译模型(NMT)结构,也就是在RNN Encoder-Decoder框架中加入了注意力机制。这篇论文中的编码器是一个双向GRU,解码器也是用RNN网络来生成句子。
用这个模型来做机器翻译,那么给定一个句子,通过编码-解码操作后,生成另一种语言的目标句子
,也就是要计算每个可能单词的条件概率,用于搜索最可能的单词,公式如下:
![]()
生成第t个单词的过程图示如下:
和未加入注意力机制的RNN Encoder-Decoder框架相比,一方面从yi的条件概率计算公式来看,g(•)这个非线性函数中的语义向量表示是随输出yi的变化而变化的ci,而非万年不变的c;另一方面从上图来看,每生成一个单词yt,就要用原句子序列X和其他信息重新计算一个语义向量表示ci,而不能吃老本。所以增加了注意力机制的RNN Encoder-Decoder框架的关键就在于,固定不变的语义向量表示c被替换成了根据当前生成的单词而不断变化的语义表示ci。
好,那我们来看看如何计算生成的单词yi的条件概率。
第一步:给定原语言的一个句子X=[x1,x2,...,xT],把单词一个个输入到编码器的RNN网络中,计算每个输入数据的隐状态ht。这篇论文中的编码器是双向RNN,所以要分别计算出顺时间循环层和逆时间循环层的隐状态,然后拼接起来:
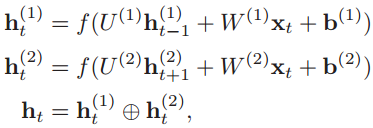
第二步:跳到解码器的RNN网络中,在第t时刻,根据已知的语义表示向量ct、上一时刻预测的yt-1和解码器中的隐状态st-1,计算当前时刻t的隐状态st:
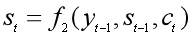
第三步:第2步中的ct还没算出来,咋就求出了隐状态st了?没错,得先求ct,可前提又是得知道st-1:
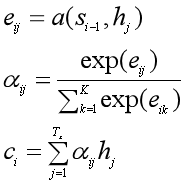
这里的eij就是还没有归一化的注意力得分。a(•)这个非线性函数叫做对齐模型(alignment model),这个函数的作用是把编码器中的每个单词xj对应的隐状态hj,和解码器中生成单词yi的前一个词对应的隐状态si-1进行对比,从而计算出每个输入单词xj和生成单词yi之间的匹配程度。匹配程度越高,注意力得分就越高,那么在生成单词yi时,就需要给与这个输入单词更多的关注。
得到注意力得分eij后,用softmax函数进行归一化,得到注意力概率分布σij。用这个注意力分布作为每个输入单词xj受关注程度的权重,对每个输入单词对应的隐状态hj进行加权求和,就得到了每个生成的单词yi所对应的语义向量表示ci,也就是attention值。
第四步:求出Attention值可不是我们的目的,我们的目的是求出生成的单词yi的条件概率。经过上面三步的计算,万事俱备,就可以很舒服地得到单词yi的条件概率:
![]()
以上就是一个注意力机制与RNN Encoder-Decoder框架相结合,并用于机器翻译的例子,我们不仅知道了怎么计算Attention值(语言向量表示ci),而且知道了怎么用Attention值来完成机器学习任务。
四、自注意力模型
1、通俗解释
首先通过与软注意力Encoder-Decoder模型进行对比,来获得对自注意力模型(Self-Attention Model)的感性认识。
在软注意力Encoder-Decoder模型中,更具体地来说,在英-中机器翻译模型中,输入序列和输出序列的内容甚至长度都是不一样的,注意力机制是发生在编码器和解码器之间,也可以说是发生在输入句子和生成句子之间。而自注意力模型中的自注意力机制则发生在输入序列内部,或者输出序列内部,可以抽取到同一个句子内间隔较远的单词之间的联系,比如句法特征(短语结构)。
如果是单纯的RNN网络,对于输入序列是按步骤顺序计算隐状态和输出的,那么对于距离比较远又相互依赖的特征,捕获二者之间联系的可能性比较小,而在序列内部引入自注意力机制后,可以将句子中任意两个单词通过一个计算直接联系起来,就更容易捕获相互依赖的特征。
2、理论阐述
有了感性认识后,我们用公式来定义自注意力模型。
自注意力模型在我看来是在同一层网络的输入和输出(不是模型最终的输出)之间,利用注意力机制“动态”地生成不同连接的权重,来得到该层网络输出的模型。
前面说了自注意力模型可以建立序列内部的长距离依赖关系,其实通过全连接神经网络也可以做到,但是问题在于全连接网络的连接边数是固定不变的,因而无法处理长度可变的序列。而自注意力模型可以动态生成不同连接的权重,那么生成多少个权重,权重的大小是多少,都是可变的,当输入更长的序列时,只需要生成更多连接边即可。如下图,虚线连接边是动态变化的。

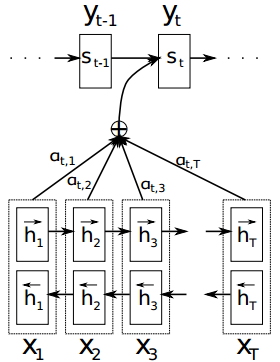
用数学公式来表达自注意力机制:假设一个神经层中的输入序列为X=[x1,x2,...,xN],输出序列为同等长度的H=[h1, h2, ..., hN],首先通过线性变换得到三组向量序列:
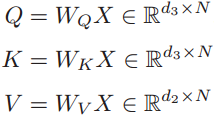
其中Q, K, V 分别为查询向量序列,键向量序列和值向量序列, WQ, WK, WV分别是可以学习的参数矩阵。
于是输出向量hi这样计算:

其中 i, j ∈ [1, N]为输出和输入向量序列的位置,连接权重 αij由注意力机制动态生成。
自注意力模型可以作为神经网络的一层来使用,也可以用来替换卷积层或循环层,也可以与卷积层或循环层交叉堆叠使用。
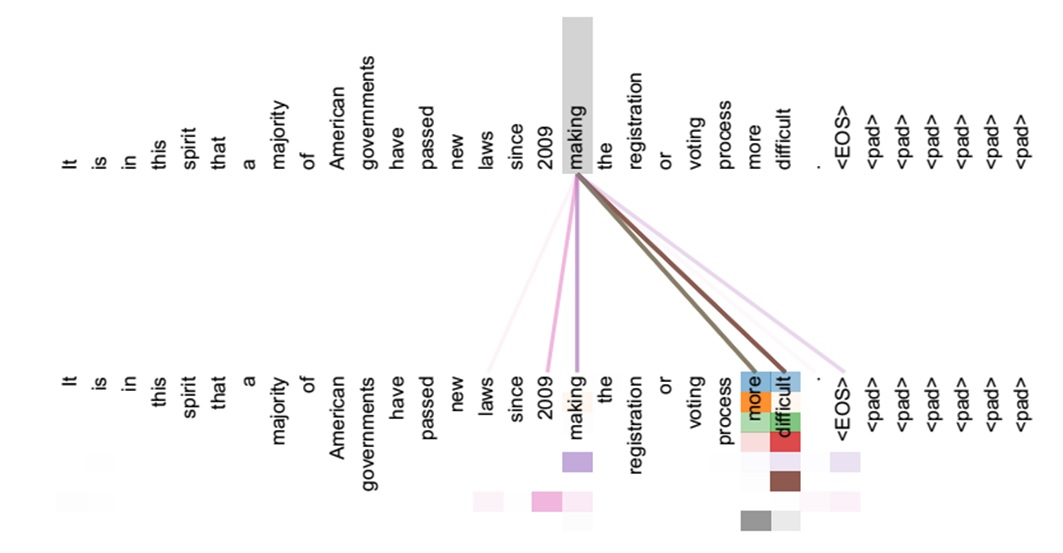
这些数学表达式背后的含义真的明白了吗?哈哈,其实不太明白,需要在实践当中去领悟。不过下面这张图或许有助于加深对以上公式的理解。在下图中,输入序列和输出序列都是同一个句子,通过由自注意力机制动态生成的权重,可以发现making与more-difficult的权重比较大(颜色深),于是捕获了这三个词之间存在的联系——构成了一个短语。
参考资料:
1、邱锡鹏:《神经网络与深度学习》
2、深度学习中的注意力机制(2017版)
https://blog.csdn.net/malefactor/article/details/78767781
3、Dzmitry Bahdanau、KyungHyun Cho、Yoshua Bengio.
《Neural Machine Translation by Jointly Learning to Align and Translate 》
4、Cho, K., van Merrienboer, B., Gulcehre, C., Bougares, F., Schwenk, H., and Bengio, Y. (2014a).
《Learning phrase representations using RNN encoder-decoder for statistical machine translation》
注:这篇博客是别人总结的,为了以后的阅读方便,同时为了尊重原著,这里把原网址贴出来,我感觉写的很容易理解了,就不做搬运工了,大家也可以多参考上面的引用文章,都挺好的,但是这篇是最言简意赅、简单明了,很符合我的风格,因此就直接摘抄过来了,原地址是:(如有侵权,请联系本人删除,谢谢)
https://www.cnblogs.com/Luv-GEM/p/10712256.html