🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
在上一章中,我们通过情感分析项目了解了循环神经网络( RNN ) 及其在自然语言处理( NLP ) 中的应用。然而,最近出现了一种新的架构,该架构已被证明优于多个 NLP 任务中基于 RNN 的序列到序列( seq2seq ) 模型。这就是所谓的变压器架构。
变形金刚已经彻底改变了自然语言处理,并处于许多令人印象深刻的应用程序的前沿,包括自动语言翻译 ( https://ai.googleblog.com/2020/06/recent-advances-in-google-translate.html ) 和建模基础蛋白质序列 ( https://www.pnas.org/content/118/15/e2016239118.short ) 的特性来创建帮助人们编写代码的 AI ( https://github.blog/2021-06-29-introducing -github-copilot-ai-pair-programmer)。
在本章中,您将了解注意力和自注意力的基本机制,并了解它们是如何在原始转换器架构中使用的。然后,在了解了转换器如何工作的基础上,我们将探索从该架构中出现的一些最具影响力的 NLP 模型,并学习如何在 PyTorch 中使用大规模语言模型,即所谓的 BERT 模型。
我们将涵盖以下主题:
- 使用注意力机制改进 RNN
- 引入独立的self-attention机制
- 了解原始变压器架构
- 比较基于 Transformer 的大规模语言模型
- 用于情绪分类的微调 BERT
向 RNN 添加注意力机制
注意力帮助 RNN 访问信息
要了解注意力机制的发展,请考虑用于seq2seq 任务的传统 RNN 模型,例如语言翻译,它在生成之前解析整个输入序列(例如,一个或多个句子)翻译,如图16.1所示: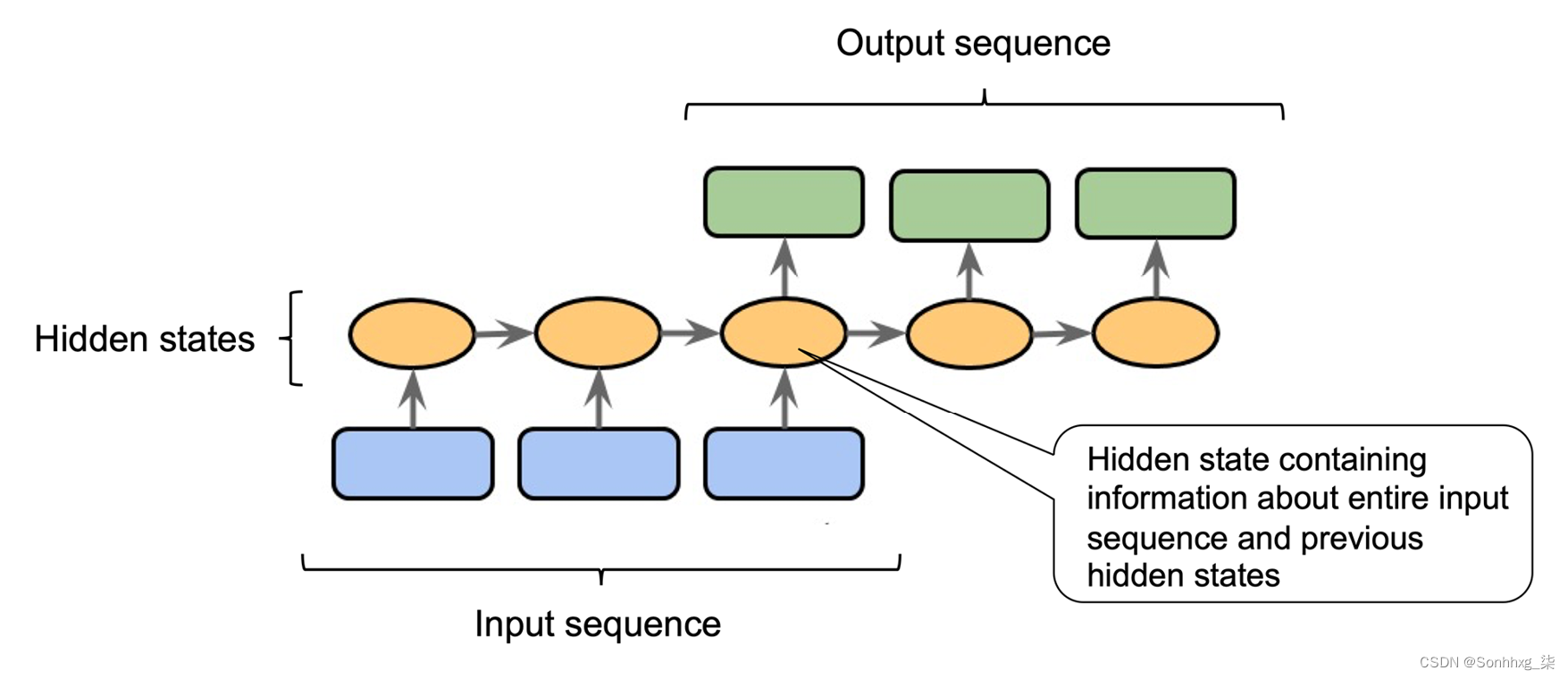
图 16.1:用于 seq2seq 建模任务的传统 RNN 编码器-解码器架构
为什么 RNN 在产生第一个输出之前解析整个输入句子?这是因为逐字翻译句子可能会导致语法错误,如图 16.2 所示: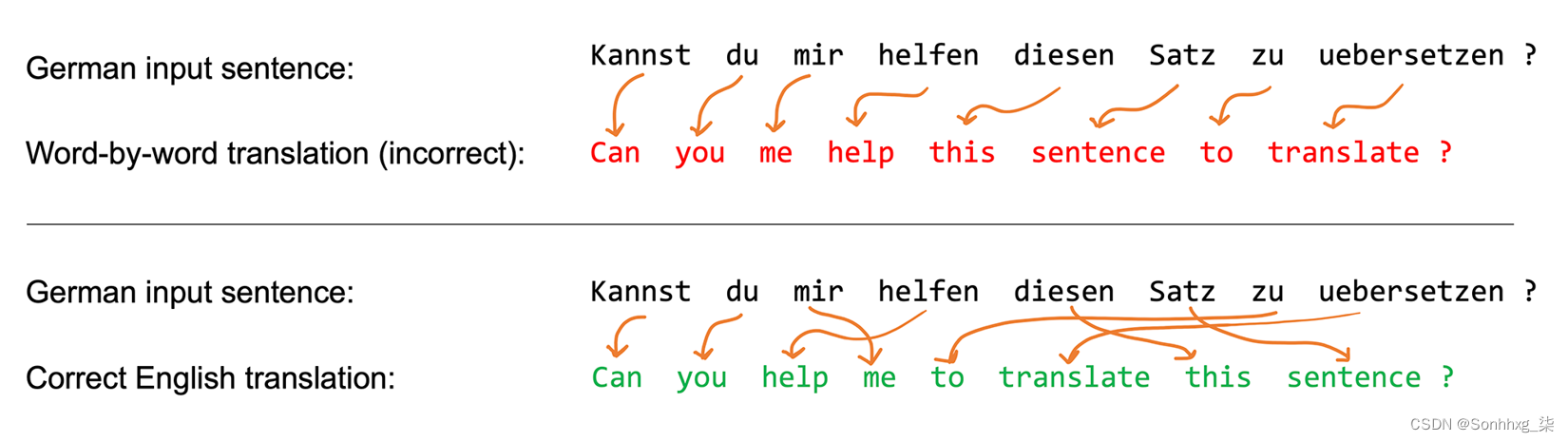
图 16.2:逐字翻译句子会导致语法错误
然而,如图 16.2 所示,这种 seq2seq 方法的一个限制是 RNN 在翻译之前试图通过一个隐藏单元记住整个输入序列。将所有信息压缩到一个隐藏单元中可能会导致信息丢失,尤其是对于长序列。因此,类似于人类翻译句子的方式,在每个时间步访问整个输入序列可能是有益的。
与常规 RNN 相比,注意力机制允许 RNN 在每个给定时间步访问所有输入元素。但是,在每个时间步都可以访问所有输入序列元素可能会让人不知所措。因此,为了帮助 RNN 关注输入序列中最相关的元素,注意力机制为每个输入元素分配不同的注意力权重。这些注意力权重指定给定输入序列元素在给定时间步的重要性或相关性。例如,再看图 16.2,单词“mir, helfen, zu”可能比单词“kannst, du, Satz”更相关于生成输出单词“help”。
下一小节介绍了一种配备注意机制的 RNN 架构,以帮助处理用于语言翻译的长序列。
RNN 的原始注意力机制
在本小节中,我们将总结注意力机制的机制它最初是为语言翻译而开发的,最初出现在以下论文中:神经机器翻译联合学习对齐和翻译,Bahdanau, D.、Cho, K. 和 Bengio, Y., 2014 年,https://arxiv。 org/abs/1409.0473。
给定一个输入序列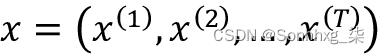 ,注意力机制为每个元素x(i)(或者更具体地说,它的隐藏表示)分配一个权重,并帮助模型识别它应该关注输入的哪一部分。例如,假设我们的输入是一个句子,权重较大的单词对我们对整个句子的理解贡献更大。具有如图 16.3所示的注意力机制的 RNN (根据前面提到的论文建模)说明了生成第二个输出词的总体概念:
,注意力机制为每个元素x(i)(或者更具体地说,它的隐藏表示)分配一个权重,并帮助模型识别它应该关注输入的哪一部分。例如,假设我们的输入是一个句子,权重较大的单词对我们对整个句子的理解贡献更大。具有如图 16.3所示的注意力机制的 RNN (根据前面提到的论文建模)说明了生成第二个输出词的总体概念: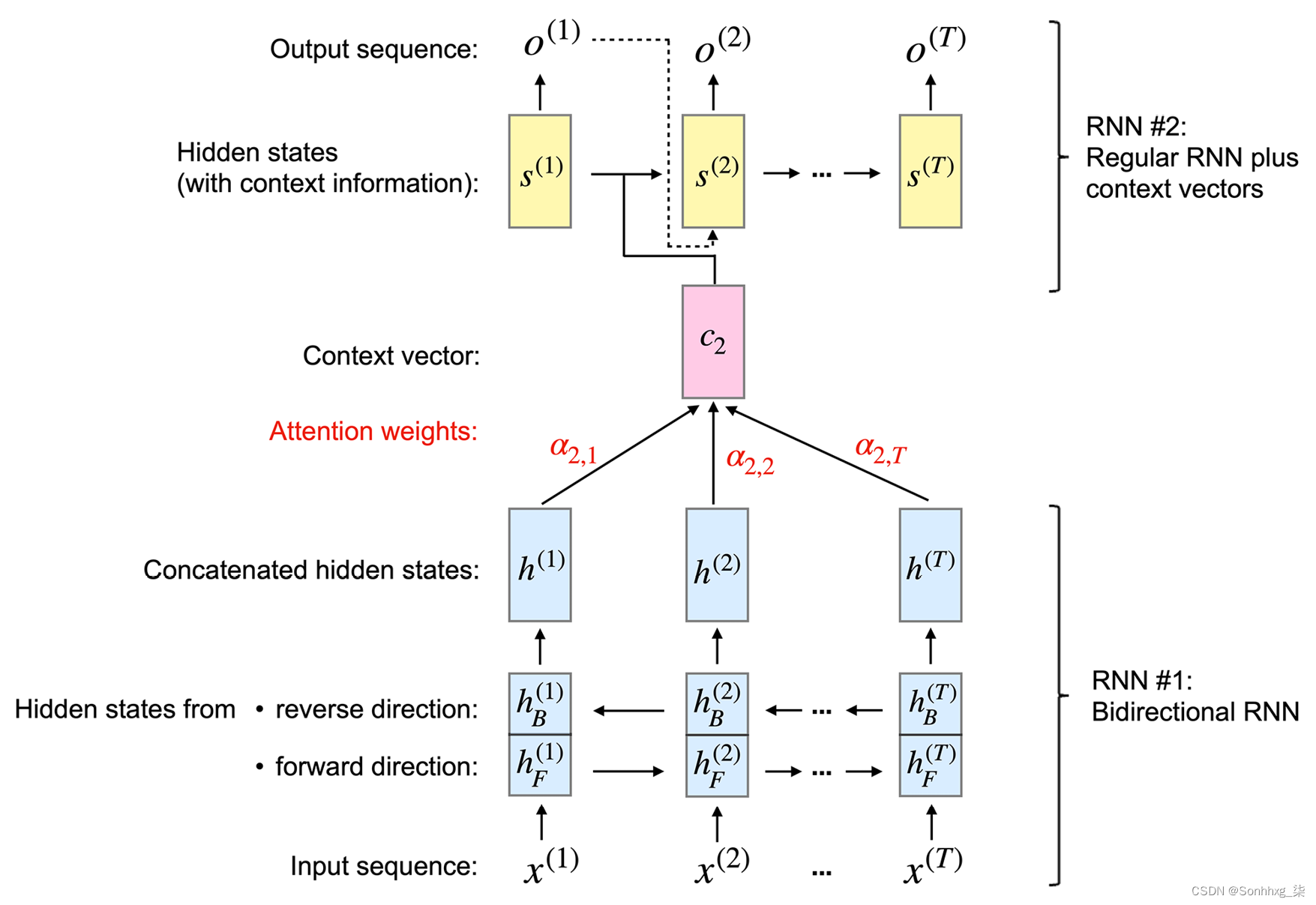
图 16.3:带有注意力机制的 RNN
这基于注意力的图中描绘的架构由两个 RNN 模型组成,我们将在下一小节中进行解释。
使用双向 RNN 处理输入
首先图 16.3中基于注意力的 RNN 的 RNN (RNN #1)是一个生成上下文向量的双向 RNN
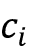
。您可以将上下文向量视为输入向量的增强版本。换句话说,输入向量还通过注意力机制合并了来自所有其他输入元素的信息。如图16.3 所示,RNN #2 然后使用由 RNN #1 准备的上下文向量来生成输出。在本小节的其余部分,我们将讨论 RNN #1 的工作原理,并在下小节中重新讨论 RNN #2。
双向 RNN #1在常规前向 ( ·) 和后向 ( ·) 上处理输入序列x。反向解析序列与反转原始输入序列具有相同的效果——想想以相反的顺序阅读一个句子。这背后的基本原理是捕获额外的信息,因为当前输入可能依赖于句子中出现在它之前或之后的序列元素,或者两者兼而有之。

因此,从两次读取输入序列(即向前和向后),每个输入序列有两个隐藏状态元素。例如,对于第二个输入序列元素
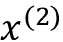
,我们从前向传播中获得隐藏状态,从后向传播中获得隐藏状态。然后将这两个隐藏状态连接起来形成隐藏状态。例如,如果和都是 128 维向量,则连接的隐藏状态将由 256 个元素组成。我们可以将这种连接的隐藏状态视为源词的“注释”,因为它包含第j个词在两个方向上的信息。
在下一节中,我们将看到第二个 RNN 如何进一步处理和使用这些连接的隐藏状态来生成输出。
从上下文向量生成输出
在图 16.3中,我们可以将 RNN #2 视为主要的 RNN,即生成输出。除了隐藏状态之外,它还接收所谓的上下文向量作为输入。上下文向量
是连接隐藏状态的加权版本,我们在上一小节中从 RNN #1 中获得。我们可以将第i个输入的上下文向量计算为加权和:
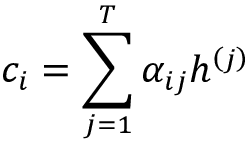
这里,表示在第i个输入序列元素的上下文中
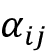
输入序列的注意力权重。请注意,每个第i个输入序列元素都有一组唯一的注意力权重。我们将在下一小节讨论注意力权重的计算。
对于本小节的其余部分,让我们讨论如何通过上图中的第二个 RNN(RNN #2)使用上下文向量。就像普通(常规)RNN 一样,RNN #2 也使用隐藏状态。考虑到前面提到的“注释”和最终输出之间的隐藏层,让我们将时间的隐藏状态表示
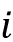
为。现在,RNN #2在每个时间步i接收上述上下文向量作为输入。
在图 16.3中,我们看到隐藏状态
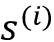
取决于前一个隐藏状态、前一个目标词和上下文向量,它们用于生成目标词在时间i的预测输出。请注意,序列向量是指表示训练期间可用的输入序列的正确翻译的序列向量。在训练过程中,真正的标签(单词)被送入下一个状态;由于这种真实的标签信息不可用于预测(推理),因此我们提供预测的输出,如上图所示。
总结我们刚刚在上面讨论过的,基于注意力的 RNN 由两个 RNN 组成。RNN #1 从输入序列元素中准备上下文向量,RNN #2 接收上下文向量作为输入。上下文向量是通过输入的加权和来计算的,其中权重是注意力权重
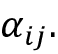
。下一小节将讨论我们如何计算这些注意力权重。
计算注意力权重
最后,让我们参观最后一个我们的难题中缺少的一块——注意力权重。因为这些权重成对连接输入(注释)和输出(上下文),所以每个注意力权重
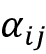
都有两个下标:j指的是输入的索引位置,i对应于输出的索引位置。注意权重是对齐分数的归一化版本,其中对齐分数评估位置j附近的输入与位置i的输出匹配程度。更具体地说,注意力权重是通过将对齐分数归一化来计算的,如下所示:
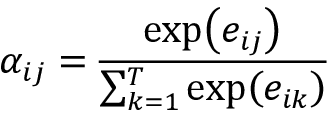
请注意,这个方程类似于 softmax 函数,我们在第 12 章使用PyTorch 并行化神经网络训练,在通过 softmax 函数估计多类分类中的类概率一节中讨论过。因此,注意力权重

......总和为 1。
现在,总结一下,我们可以将基于注意力的 RNN 模型分为三个部分。第一部分计算输入的双向注释。第二部分由循环块组成,它与原始 RNN 非常相似,只是它使用上下文向量而不是原始输入。最后一部分涉及注意力权重和上下文向量的计算,它们描述了每对输入和输出元素之间的关系。
这Transformer 架构也利用了注意力机制,但与基于注意力的 RNN 不同,它仅依赖于自注意力机制,不包括 RNN 中的循环过程。换句话说,Transformer 模型一次处理整个输入序列,而不是一次读取和处理一个元素的序列。在下一节中,我们将介绍自我注意机制的基本形式,然后在下一节中更详细地讨论 Transformer 架构。
引入自注意力机制
在上一节中,我们看到注意力机制可以帮助 RNN 在处理长序列时记住上下文。正如我们将在下一节中看到的,我们可以拥有一个完全基于注意力的架构,而无需 RNN 的循环部分。这种基于注意力的架构称为transformer,稍后我们将更详细地讨论它。
事实上,变压器乍一看可能有点复杂。因此,在下一节讨论 Transformer 之前,让我们深入了解 Transformer 中使用的自注意力机制。事实上,正如我们将看到的,这种自注意力机制只是我们在上一节中讨论的注意力机制的不同形式。我们可以将前面讨论的注意力机制视为连接两个不同模块的操作,即 RNN 的编码器和解码器。正如我们将看到的,self-attention 只关注输入并且只捕获输入元素之间的依赖关系。无需连接两个模块。
在第一小节中,我们将介绍一种没有任何学习参数的自我注意的基本形式,它非常类似于对输入的预处理步骤。然后在第二小节中,我们将介绍在 Transformer 架构中使用并涉及可学习参数的 self-attention 的常见版本。
从自我注意的基本形式开始
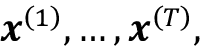
以及一个输出序列 。为避免混淆,我们将使用它作为整个 Transformer 模型的最终输出和自注意力层的输出,因为它是模型中的一个中间步骤。
这些序列中的 每个第i
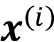
个元素和是大小为d的向量(即 ),表示位置i处输入的特征信息,这类似于 RNN。然后,对于 seq2seq 任务,self-attention 的目标是对当前输入元素与所有其他输入元素的依赖关系进行建模。为了实现这一点,自我注意机制由三个阶段组成。首先,我们根据当前元素与序列中所有其他元素之间的相似性推导出重要性权重。其次,我们对权重进行归一化,这通常涉及使用已经熟悉的 softmax 函数。第三,我们将这些权重与相应的序列元素结合使用来计算注意力值。
更正式地说,self-attention 的输出,是所有T个输入序列
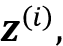
的加权和, (其中)。例如,对于第i个输入元素,对应的输出值计算如下:
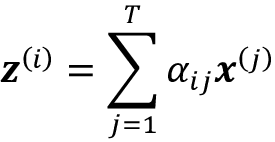
因此,我们可以将其
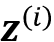
视为输入向量中的上下文感知嵌入向量,它涉及所有其他输入序列元素,这些元素由它们各自的注意力权重加权。这里,注意力权重 ,是根据当前输入元素 与输入序列中的所有其他元素之间的相似性计算的。更具体地说,这种相似性是在下一段中解释的两个步骤中计算的。
首先,我们计算当前输入元素
和输入序列中的另一个元素 之间的点积:
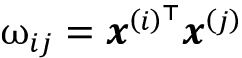
在我们对
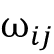
值进行归一化以获得注意力权重之前,让我们用一个代码示例来说明我们如何计算这些值。在这里,假设我们有一个输入句子“你能帮我翻译这个句子吗”,它已经通过字典映射到整数表示,如第 15 章中所述,使用递归神经网络建模序列数据:
>>> import torch
>>> sentence = torch.tensor(
>>> [0, # can
>>> 7, # you
>>> 1, # help
>>> 2, # me
>>> 5, # to
>>> 6, # translate
>>> 4, # this
>>> 3] # sentence
>>> )
>>> sentence
tensor([0, 7, 1, 2, 5, 6, 4, 3])我们还假设我们已经通过嵌入层将这个句子编码为实数向量表示。在这里,我们的嵌入大小为 16,我们假设字典大小为 10。以下代码将生成我们八个单词的词嵌入:
>>> torch.manual_seed(123)
>>> embed = torch.nn.Embedding(10, 16)
>>> embedded_sentence = embed(sentence).detach()
>>> embedded_sentence.shape
torch.Size([8, 16])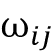
之间的点积。我们可以对所有值执行此操作,如下所示:
>>> omega = torch.empty(8, 8)
>>> for i, x_i in enumerate(embedded_sentence):
>>> for j, x_j in enumerate(embedded_sentence):
>>> omega[i, j] = torch.dot(x_i, x_j)虽然前面的代码易于阅读和理解,但for循环可能非常低效,所以让我们使用矩阵乘法来计算它:
>>> omega_mat = embedded_sentence.matmul(embedded_sentence.T)我们可以使用该torch.allclose函数来检查这个矩阵乘法是否产生了预期的结果。如果两个张量包含相同的值,则torch.allclose返回True,如下所示:
>>> torch.allclose(omega_mat, omega)
True我们已经学习了如何为第 i个输入和序列中的所有输入 (
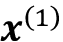
to ) 计算基于相似性的权重,即“原始”权重 ( to )。我们可以通过熟悉的 softmax 函数对值进行归一化来获得注意力权重,如下所示:
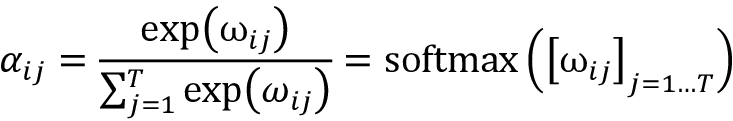
请注意,分母涉及所有输入元素的总和 (

)。因此,由于应用了这个 softmax 函数,在这个归一化之后权重总和为 1,也就是说,
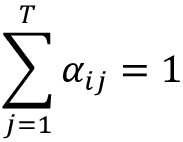
我们可以计算使用 PyTorch 的 softmax 函数的注意力权重如下:
>>> import torch.nn.functional as F
>>> attention_weights = F.softmax(omega, dim=1)
>>> attention_weights.shape
torch.Size([8, 8])请注意,这attention_weights是一个

矩阵,其中每个元素代表一个注意力权重,。例如,如果我们正在处理第i个输入词,则该矩阵的第i行包含句子中所有词的相应注意力权重。这些注意力权重表明每个词与第i个词的相关程度。因此,这个注意力矩阵中的列应该总和为 1,我们可以通过以下代码确认:
>>> attention_weights.sum(dim=1)
tensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000])现在我们已经了解了如何计算注意力权重,让我们回顾和总结自注意力操作背后的三个主要步骤:
- 对于给定的输入元素 , 以及集合 {1, ..., T
} 中的每个第j个元素,计算点积, -
通过使用 softmax 函数对点积进行归一化,获得注意力权重 , - 将输出 计算
为整个输入序列的加权和:
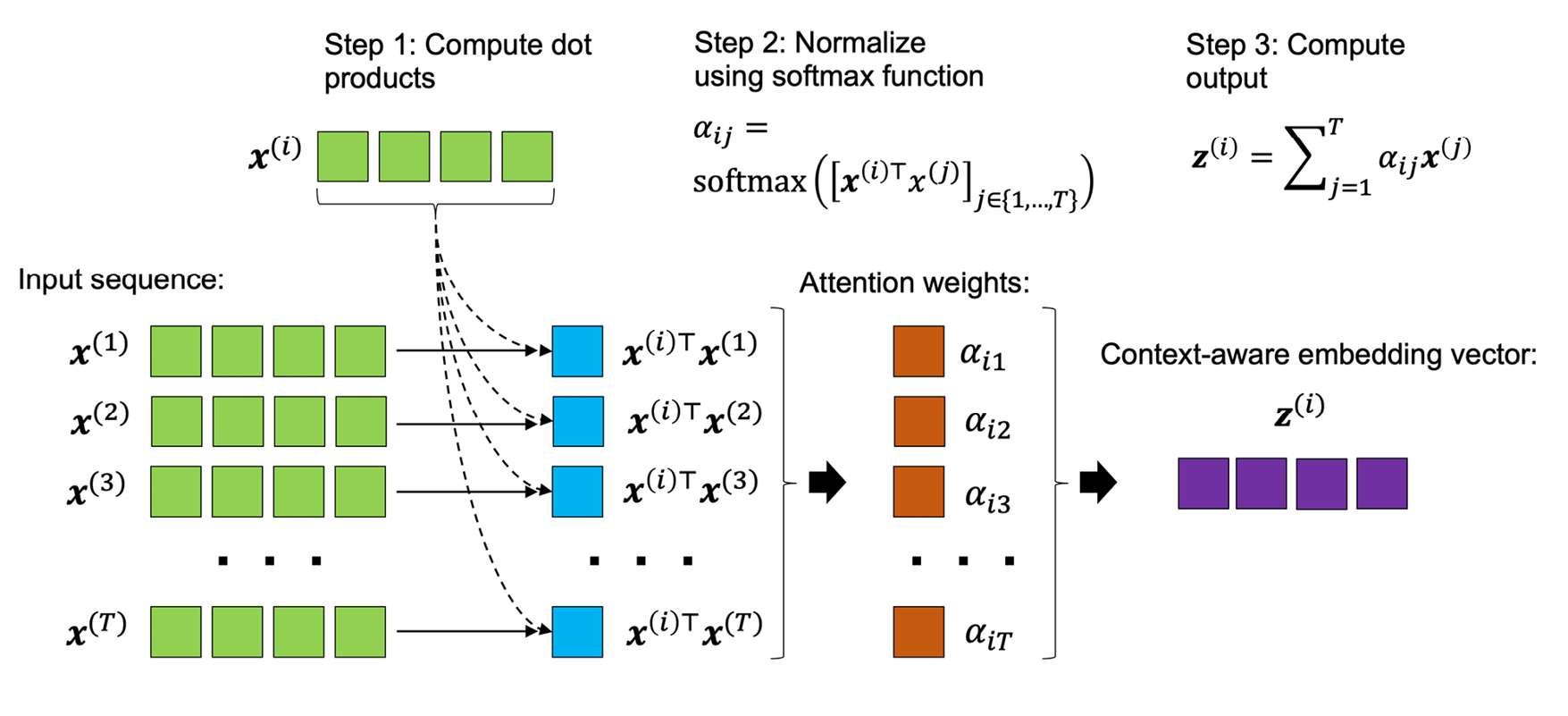
图 16.4:用于说明目的的基本自注意过程
最后,让我们看一个计算上下文向量的代码示例
,作为输入的注意力加权和(图 16.4中的步骤 3 )。特别是,假设我们正在计算第二个输入词的上下文向量,即:
>>> x_2 = embedded_sentence[1, :]
>>> context_vec_2 = torch.zeros(x_2.shape)
>>> for j in range(8):
... x_j = embedded_sentence[j, :]
... context_vec_2 += attention_weights[1, j] * x_j
>>> context_vec_2
tensor([-9.3975e-01, -4.6856e-01, 1.0311e+00, -2.8192e-01, 4.9373e-01, -1.2896e-02, -2.7327e-01, -7.6358e-01, 1.3958e+00, -9.9543e-01,
-7.1288e-04, 1.2449e+00, -7.8077e-02, 1.2765e+00, -1.4589e+00,
-2.1601e+00])同样,我们可以通过使用矩阵乘法更有效地实现这一点。使用以下代码,我们正在计算所有八个输入词的上下文向量:
>>> context_vectors = torch.matmul(
... attention_weights, embedded_sentence)与存储在 中的输入词嵌入类似embedded_sentence,context_vectors矩阵具有维数
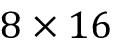
。该矩阵的第二行包含第二个输入词的上下文向量,我们可以torch.allclose()再次使用以下命令检查实现:
>>> torch.allclose(context_vec_2, context_vectors[1])
True正如我们所见,第二个上下文向量的手动for循环和矩阵计算产生了相同的结果。
本节实现了自我注意的基本形式,在下一节中,我们将使用可在神经网络训练期间优化的可学习参数矩阵来修改此实现。
参数化自注意力机制:缩放的点积注意力
现在你有介绍了自我注意背后的基本概念后,本小节总结了变压器架构中使用的更高级的自我注意机制,称为缩放点积注意。请注意,在上一小节,我们在计算输出时没有涉及任何可学习的参数。换句话说,使用前面介绍的基本自注意力机制,Transformer 模型在给定序列的模型优化期间如何更新或更改注意力值方面是相当有限的。为了使自注意力机制更灵活,更适合模型优化,我们将引入三个额外的权重矩阵,可以在模型训练期间作为模型参数进行拟合。我们将这三个权重矩阵表示为
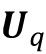
、和。它们用于将输入投影到查询、键和值序列元素中,如下所示:
- 查询顺序:
for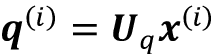
- 键序:
for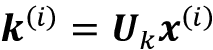
- 值序列:
for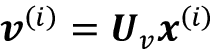
图 16.5说明了如何使用这些单独的组件来计算对应于第二个输入元素的上下文感知嵌入向量:
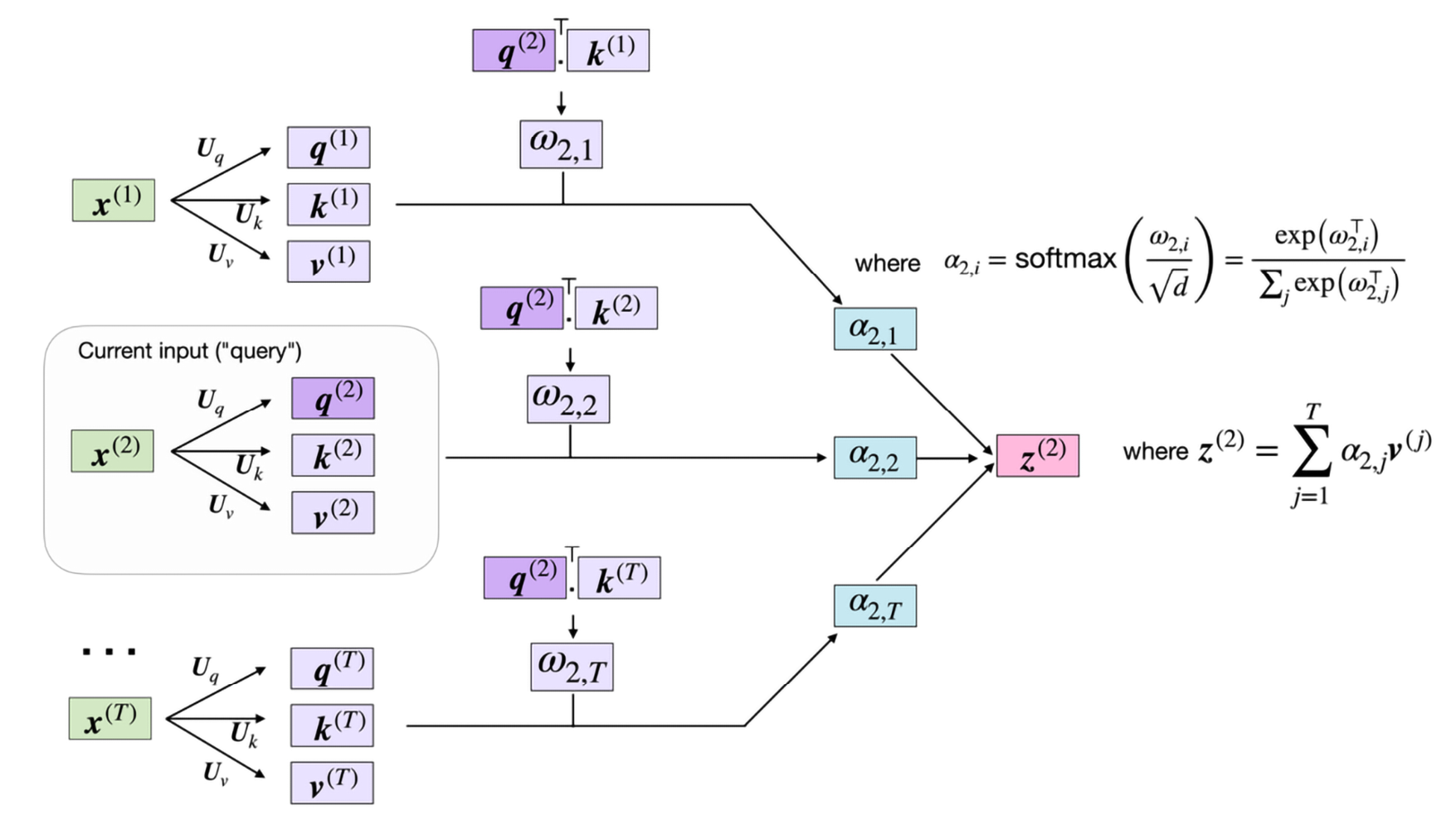
图 16.5:计算第二个序列元素的上下文感知嵌入向量
查询、键和值术语
最初的 Transformer 论文中使用的术语查询、键和值受到信息检索系统和数据库的启发。例如,如果我们输入一个查询,它会与检索某些值的键值相匹配。
在这里,
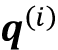
和 都是 size 的向量 。因此,投影矩阵 有形 , 而 有形 。(注意,这是每个词向量的维数, 。)为简单起见,我们可以将这些向量设计为具有相同的形状,例如,使用 . 为了通过代码提供额外的直觉,我们可以如下初始化这些投影矩阵:
>>> torch.manual_seed(123)
>>> d = embedded_sentence.shape[1]
>>> U_query = torch.rand(d, d)
>>> U_key = torch.rand(d, d)
>>> U_value = torch.rand(d, d)使用查询投影矩阵,我们可以计算查询序列。对于这个例子,考虑第二个输入元素 ,
作为我们的查询,如图 16.5 所示:
>>> x_2 = embedded_sentence[1]
>>> query_2 = U_query.matmul(x_2)以类似的方式,我们可以计算键和值序列,
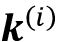
并且:
>>> key_2 = U_key.matmul(x_2)
>>> value_2 = U_value.matmul(x_2)然而,正如我们从图 16.5中看到的,我们还需要所有其他输入元素的键和值序列,我们可以计算如下:
>>> keys = U_key.matmul(embedded_sentence.T).T
>>> values = U_value.matmul(embedded_sentence.T).T在关键矩阵中,第i个row对应于第i个输入元素的键序列,同样适用于值矩阵。我们可以通过torch.allclose()再次使用来确认这一点,它应该返回True:
>>> keys = U_key.matmul(embedded_sentence.T).T
>>> torch.allclose(key_2, keys[1])
>>> values = U_value.matmul(embedded_sentence.T).T
>>> torch.allclose(value_2, values[1])在上一节中,我们计算了非归一化权重 ,作为给定输入序列元素和第 j个序列元素
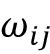
之间的成对点积 。现在,在这个参数化版本的 self-attention 中,我们计算查询和键之间的点积:

例如,以下代码计算非标准化注意力权重 ,
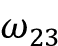
即我们的查询与第三个输入序列元素之间的点积:
>>> omega_23 = query_2.dot(keys[2])
>>> omega_23
tensor(14.3667)由于我们稍后将需要这些,我们可以将此计算扩展到所有键:
>>> omega_2 = query_2.matmul(keys.T)
>>> omega_2
tensor([-25.1623, 9.3602, 14.3667, 32.1482, 53.8976, 46.6626, -1.2131, -32.9391])self-attention 的下一步是使用 softmax 函数从非
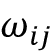
归一化注意力权重 , 到归一化注意力权重 , 。然后,我们可以在通过 softmax 函数对其进行归一化之前进一步使用 缩放 ,如下所示:
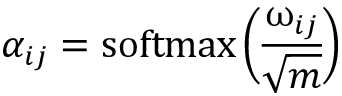
请注意,通常
按缩放,可确保权重向量的欧几里得长度大致在相同的范围内。
以下代码用于实现此归一化以计算整个输入序列相对于作为查询的第二个输入元素的注意力权重:
>>> attention_weights_2 = F.softmax(omega_2 / d**0.5, dim=0)
>>> attention_weights_2
tensor([2.2317e-09, 1.2499e-05, 4.3696e-05, 3.7242e-03, 8.5596e-01, 1.4025e-01, 8.8896e-07, 3.1936e-10])最后,输出是值序列的加权平均:
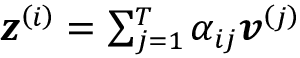
,可以如下实现:
>>> context_vector_2 = attention_weights_2.matmul(values)
>>> context_vector_2
tensor([-1.2226, -3.4387, -4.3928, -5.2125, -1.1249, -3.3041,
-1.4316, -3.2765, -2.5114, -2.6105, -1.5793, -2.8433, -2.4142,
-0.3998, -1.9917, -3.3499])在本节中,我们介绍了一种具有可训练参数的自注意力机制,它允许我们通过涉及所有输入元素来计算上下文感知嵌入向量,这些输入元素由它们各自的注意力分数加权。在下一节中,我们将了解 Transformer 架构,这是一种以本节介绍的自注意力机制为中心的神经网络架构。
我们只需要注意:引入原始的transformer架构
有趣的是,最初的 Transformer 架构是基于最初在 RNN 中使用的注意力机制。最初,使用注意力机制的目的是提高 RNN 在处理长句子时的文本生成能力。然而,在对 RNN 的注意力机制进行实验仅仅几年之后,研究人员发现,当删除循环层时,基于注意力的语言模型更加强大。这导致了变压器架构,这是本章和其余部分的主题。
Transformer 架构最初是在A. Vaswani及其同事的 NeurIPS 2017 论文Attention Is All You Need ( https://arxiv.org/abs/1706.03762 ) 中提出的。由于自注意机制,transformer 模型可以捕获输入序列中元素之间的长期依赖关系——在 NLP 上下文中;例如,这有助于模型更好地“理解”输入句子的含义。
虽然这种转换器架构最初是为语言翻译而设计的,但它可以推广到其他任务,例如英语选区解析、文本生成和文本分类。稍后,我们将讨论流行的语言模型,例如 BERT 和 GPT,它们都源自这种原始的 Transformer 架构。图 16.6是我们改编自原始的 Transformer 论文,展示了我们将在本节中讨论的主要架构和组件:
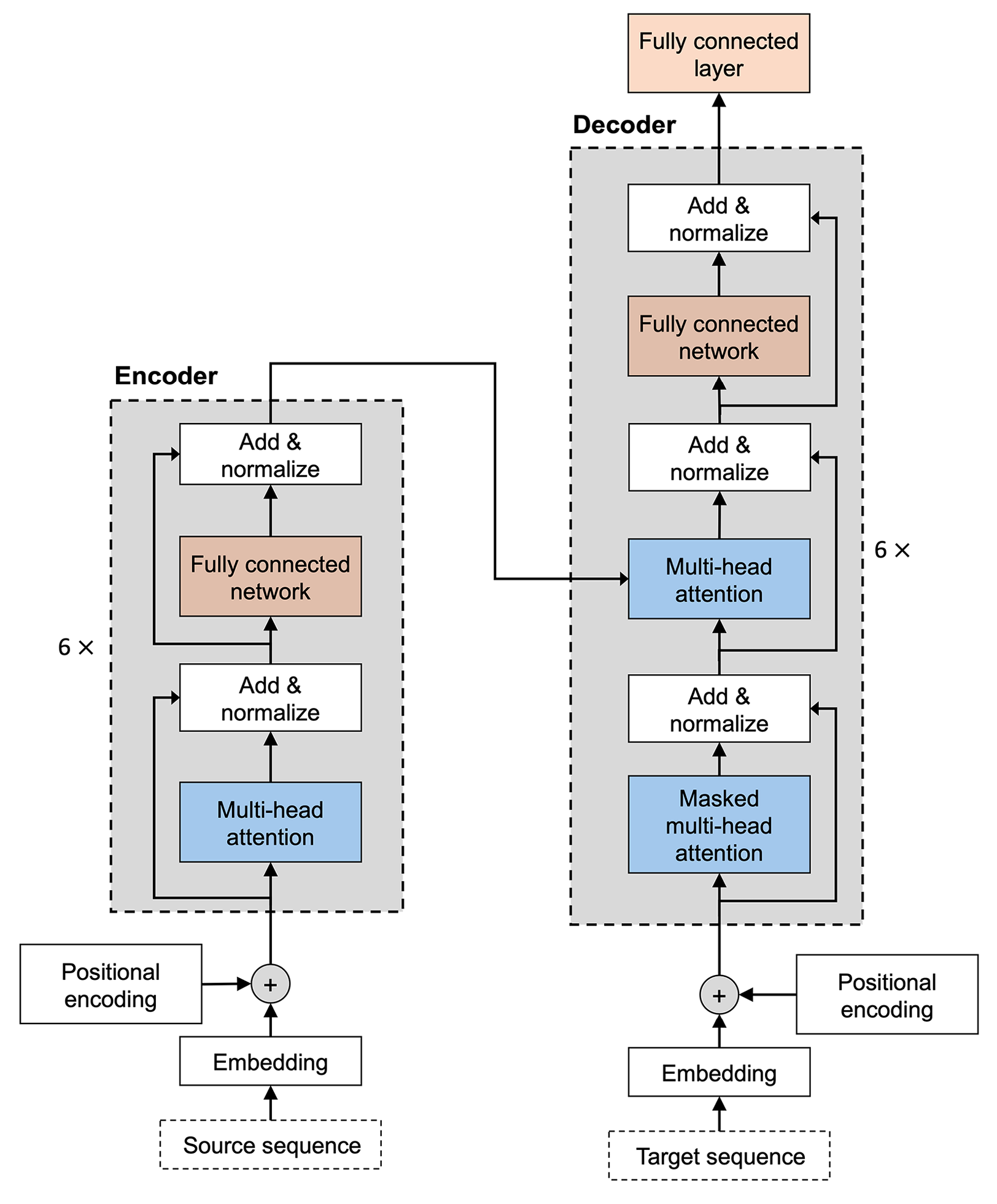
图 16.6:最初的 Transformer 架构
在接下来的小节中,我们将逐步介绍这个原始的 Transformer 模型,将其分解为两个主要模块:编码器和解码器。编码器接收原始顺序输入并使用多头自注意力模块对嵌入进行编码。解码器接收处理后的输入,并使用掩码形式的自我注意输出结果序列(例如,翻译后的句子) 。
通过多头注意力编码上下文嵌入
这编码器块的总体目标是接收顺序输入
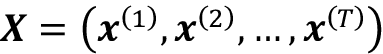
并将其映射为连续表示,然后传递给解码器。
编码器是六个相同层的堆栈。6 在这里不是一个神奇的数字,而只是原始转换器论文中的一个超参数选择。您可以根据模型性能调整层数。在每个相同的层中,都有两个子层:一个计算多头自注意力,我们将在下面讨论,另一个是全连接层,您在前面的章节中已经遇到过。
我们先来说说多头自注意力,它是一个本章前面介绍的缩放点积注意力的简单修改。在缩放的点积注意力中,我们使用了三个矩阵(对应于查询、值和键)来转换输入序列。在多头注意力的情况下,我们可以将这组三个矩阵视为一个注意力头。正如其名称所示,在多头注意力中,我们现在有多个这样的头(查询、值和关键矩阵集),类似于卷积神经网络可以有多个内核。
为了解释多头概念self-attention with
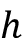
head 更详细,让我们将其分解为以下步骤。
首先,我们读入顺序输入
。假设每个元素都嵌入了一个长度为d的向量。在这里,输入可以嵌入到矩阵中。然后,我们创建查询、键和值学习参数矩阵集:
-

-
- ...
-
因为我们使用这些权重矩阵来投影每个元素
,以便在矩阵乘法中进行所需的尺寸匹配,两者都有和具有形状,并且具有 形状。结果,结果序列(查询和键)都具有长度,而结果值序列具有长度。在实践中,人们往往选择简单。
为了在代码中说明多头自注意力堆栈,首先考虑我们如何在上一小节中创建单查询投影矩阵,参数化自注意力机制:缩放点积注意力:
>>> torch.manual_seed(123)
>>> d = embedded_sentence.shape[1]
>>> one_U_query = torch.rand(d, d)现在,假设我们有八个类似于原始转换器的注意力头,即
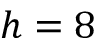
:
>>> h = 8
>>> multihead_U_query = torch.rand(h, d, d)
>>> multihead_U_key = torch.rand(h, d, d)
>>> multihead_U_value = torch.rand(h, d, d)正如我们在代码中看到的,只需添加一个额外的维度即可添加多个注意力头。
跨多个注意力头拆分数据
在实践中,不是每个注意力头都有一个单独的矩阵,而是转换器实现对所有注意力头使用一个矩阵。然后,注意力头在这个矩阵中被组织成逻辑上独立的区域,可以通过布尔掩码访问这些区域。这使得可以更有效地实现多头注意力,因为多个矩阵乘法可以实现为单个矩阵乘法。但是,为简单起见,我们在本节中省略了这个实现细节。
初始化后投影矩阵,我们可以计算投影序列,类似于它在缩放点积注意力中的完成方式。现在,我们需要计算h组,而不是计算一组查询、键和值序列。更正式地说,例如,涉及第j个头部中第i个数据点的查询投影的计算可以写成如下:
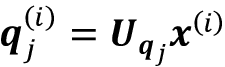
然后我们对所有的 head 重复这个计算
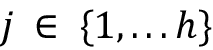
。
在代码中,作为查询的第二个输入单词如下所示:
>>> multihead_query_2 = multihead_U_query.matmul(x_2)
>>> multihead_query_2.shape
torch.Size([8, 16])该multihead_query_2矩阵有八行,其中每一行对应于第j个注意力头。
同样,我们可以计算每个头的键和值序列:
>>> multihead_key_2 = multihead_U_key.matmul(x_2)
>>> multihead_value_2 = multihead_U_value.matmul(x_2)
>>> multihead_key_2[2]
tensor([-1.9619, -0.7701, -0.7280, -1.6840, -1.0801, -1.6778, 0.6763, 0.6547,1.4445, -2.7016, -1.1364, -1.1204, -2.4430, -0.5982, -0.8292, -1.4401])代码输出通过第三个注意力头显示了第二个输入元素的关键向量。
但是,请记住,我们需要对所有输入序列元素重复键和值计算,而不仅仅是x_2——我们需要它来稍后计算自注意力。一种简单且具有说明性的方法是将输入序列嵌入扩展为大小为 8 作为第一维,即注意力头的数量。我们.repeat()为此使用方法:
>>> stacked_inputs = embedded_sentence.T.repeat(8, 1, 1)
>>> stacked_inputs.shape
torch.Size([8, 16, 8])然后,我们可以通过torch.bmm()注意力头进行批量矩阵乘法来计算所有键:
>>> multihead_keys = torch.bmm(multihead_U_key, stacked_inputs)
>>> multihead_keys.shape
torch.Size([8, 16, 8])在这段代码中,我们现在有一个张量是指到第一维度的八个注意力头。第二维和第三维分别指嵌入大小和单词数。让我们交换第二维和第三维,使键具有更直观的表示,即与原始输入序列相同的维数embedded_sentence:
>>> multihead_keys = multihead_keys.permute(0, 2, 1)
>>> multihead_keys.shape
torch.Size([8, 8, 16])重新排列后,我们可以访问第二个注意力头中的第二个键值,如下所示:
>>> multihead_keys[2, 1]
tensor([-1.9619, -0.7701, -0.7280, -1.6840, -1.0801, -1.6778, 0.6763, 0.6547,1.4445, -2.7016, -1.1364, -1.1204, -2.4430, -0.5982, -0.8292, -1.4401])我们可以看到这与我们之前得到的键值相同multihead_key_2[2],这表明我们复杂的矩阵操作和计算是正确的。所以,让我们对值序列重复一遍:
>>> multihead_values = torch.matmul(multihead_U_value, stacked_inputs)
>>> multihead_values = multihead_values.permute(0, 2, 1)我们按照单头注意力计算的步骤来计算上下文向量,如参数化自注意力机制:缩放的点积注意力部分中所述。为简洁起见,我们将跳过中间步骤,并假设我们已经计算了的上下文向量第二个输入元素作为查询和八个不同的注意力头,我们multihead_z_2通过随机数据表示:
>>> multihead_z_2 = torch.rand(8, 16)请注意,八个注意力头上的第一维索引和上下文向量,类似于输入句子,是 16 维向量。如果这看起来很复杂,可以将其视为图 16.5中所示的multihead_z_2八个副本;也就是说,八个注意力头中的每一个都有一个。
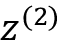
然后,我们将这些向量连接成一个长度为的长向量,

并使用线性投影(通过全连接层)将其映射回长度为 的向量。这个过程如图 16.7 所示:
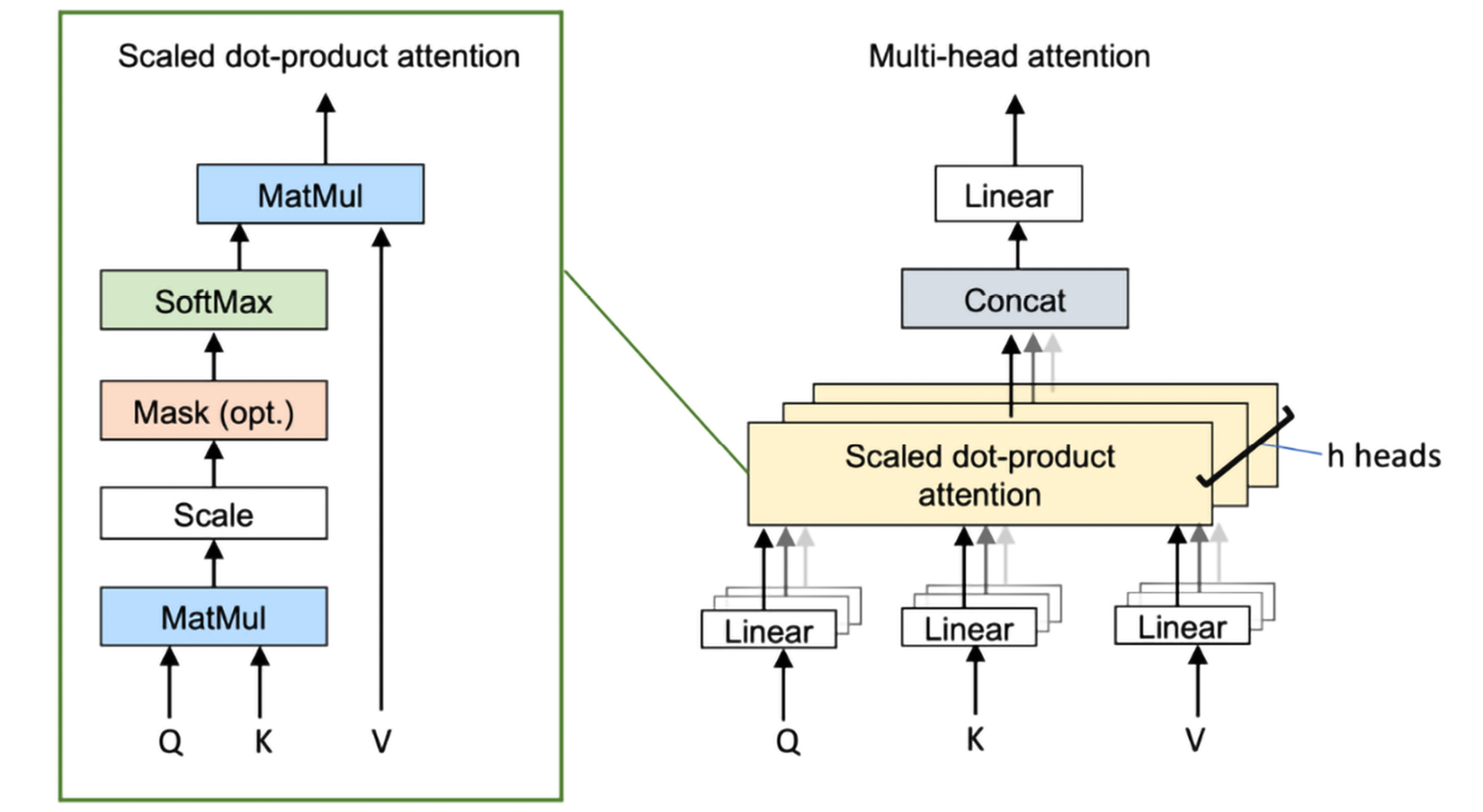
图 16.7:将缩放的点积注意力向量连接成一个向量并通过线性投影传递
在代码中,我们可以如下实现连接和压缩:
>>> linear = torch.nn.Linear(8*16, 16)
>>> context_vector_2 = linear(multihead_z_2.flatten())
>>> context_vector_2.shape
torch.Size([16])学习语言模型:decoder and masked multi-head attention
与编码器类似,解码器也包含几个重复的层。除了我们在前面的编码器部分已经介绍过的两个子层(多头自注意力层和全连接层),每个重复层还包含一个掩蔽的多头注意力子层。
蒙面注意是原始注意机制的一种变体,其中屏蔽注意仅通过“屏蔽”一定数量的单词将有限的输入序列传递到模型中。例如,如果我们正在使用标记数据集构建语言翻译模型,则在训练过程中序列位置i处,我们仅从位置 1、...、i -1 输入正确的输出单词。所有其他词(例如,在当前位置之后的词)对模型隐藏,以防止模型“作弊”。这也符合文本生成的本质:虽然在训练过程中知道真实的翻译词,但在实践中我们对 ground truth 一无所知。因此,我们只能在位置为模型提供它已经生成的解决方案我。
图 16.8说明了层在解码器块中的排列方式:
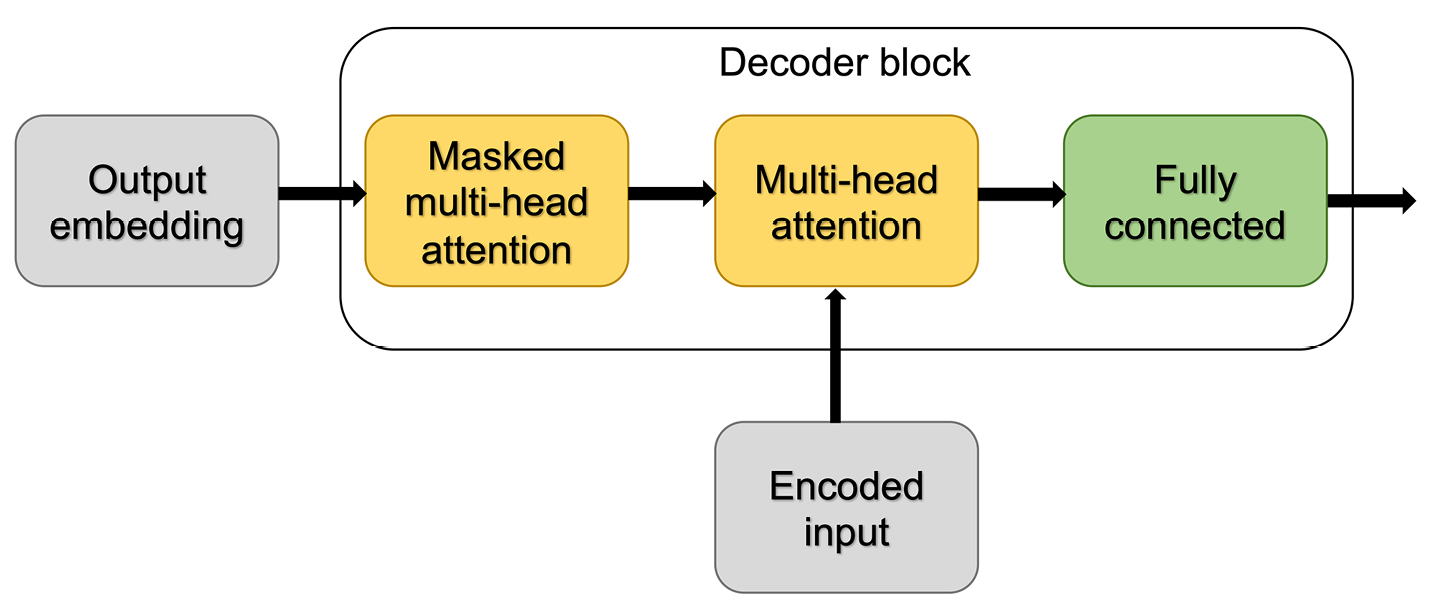
图 16.8:解码器部分的层排列
首先,之前的输出词(输出嵌入)被传递到掩码的多头注意力层。然后,第二层接收来自编码器块的编码输入和掩码多头注意力层的输出到多头注意力层。最后,我们将多头注意力输出传递到一个全连接层,该层生成整体模型输出:对应于输出单词的概率向量。
请注意,我们可以使用 argmax 函数从这些单词概率中获得预测的单词,类似于我们在第 15 章使用递归神经网络建模序列数据中采用的总体方法。
将解码器与编码器块进行比较,主要区别在于模型可以处理的序列元素的范围。在编码器中,对于每个给定的单词,计算一个句子中所有单词的注意力,这可以被认为是双向输入解析的一种形式。解码器还接收来自编码器的双向解析输入。但是,当涉及到输出序列时,解码器只考虑当前输入位置之前的那些元素,这可以解释为单向输入解析的一种形式。
实现细节:位置编码和层归一化
在本小节中,我们将讨论到目前为止我们已经浏览过但值得一提的转换器的一些实现细节。
首先,让我们考虑位置编码是图 16.6中原始变压器架构的一部分。位置编码有助于捕获有关输入序列排序的信息,并且是转换器的关键部分,因为缩放的点积注意力层和完全连接的层都是置换不变的。这意味着,在没有位置编码的情况下,单词的顺序将被忽略,并且对基于注意力的编码没有任何影响。但是,我们知道词序对于理解句子至关重要。例如,考虑以下两个句子:
- 玛丽给约翰一朵花
- 约翰给玛丽一朵花
两个句子中出现的单词完全相同;然而,含义却大相径庭。
Transformers 通过在编码器和解码器块的开头向输入嵌入添加一个小值向量,使不同位置的相同单词具有略微不同的编码。特别是,原始变压器架构使用所谓的正弦编码:
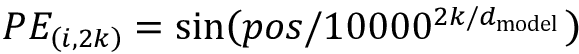
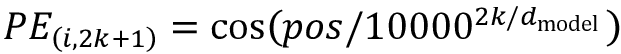
这里

是词的位置,k表示编码向量的长度,我们选择k与输入词嵌入具有相同的维度,这样位置编码和词嵌入可以相加。正弦函数用于防止位置编码变得太大。例如,如果我们使用绝对位置 1,2,3…, n作为位置编码,它们将主导词编码并使词嵌入值可以忽略不计。
一般来说,有两种位置编码的类型,绝对编码(如前面的公式所示)和相对编码。前者会记录单词的绝对位置,对句子中的单词移位很敏感。也就是说,绝对位置编码是每个给定位置的固定向量。另一方面,相对编码只保持单词的相对位置,对句子移位是不变的。
接下来,我们来看看层归一化机制,由 J. Ba、JR Kiros 和 GE Hinton 于 2016 年在同名论文层归一化(URL:https ://arxiv.org/abs/1607.06450 )中首次引入。虽然批量标准化(我们将在第 17 章“用于合成新数据的生成对抗网络”中更详细地讨论)是计算机视觉上下文中的一种流行选择,但层标准化是 NLP 上下文中的首选,其中句子长度可以变化。图 16.9并排说明了层和批标准化的主要区别:
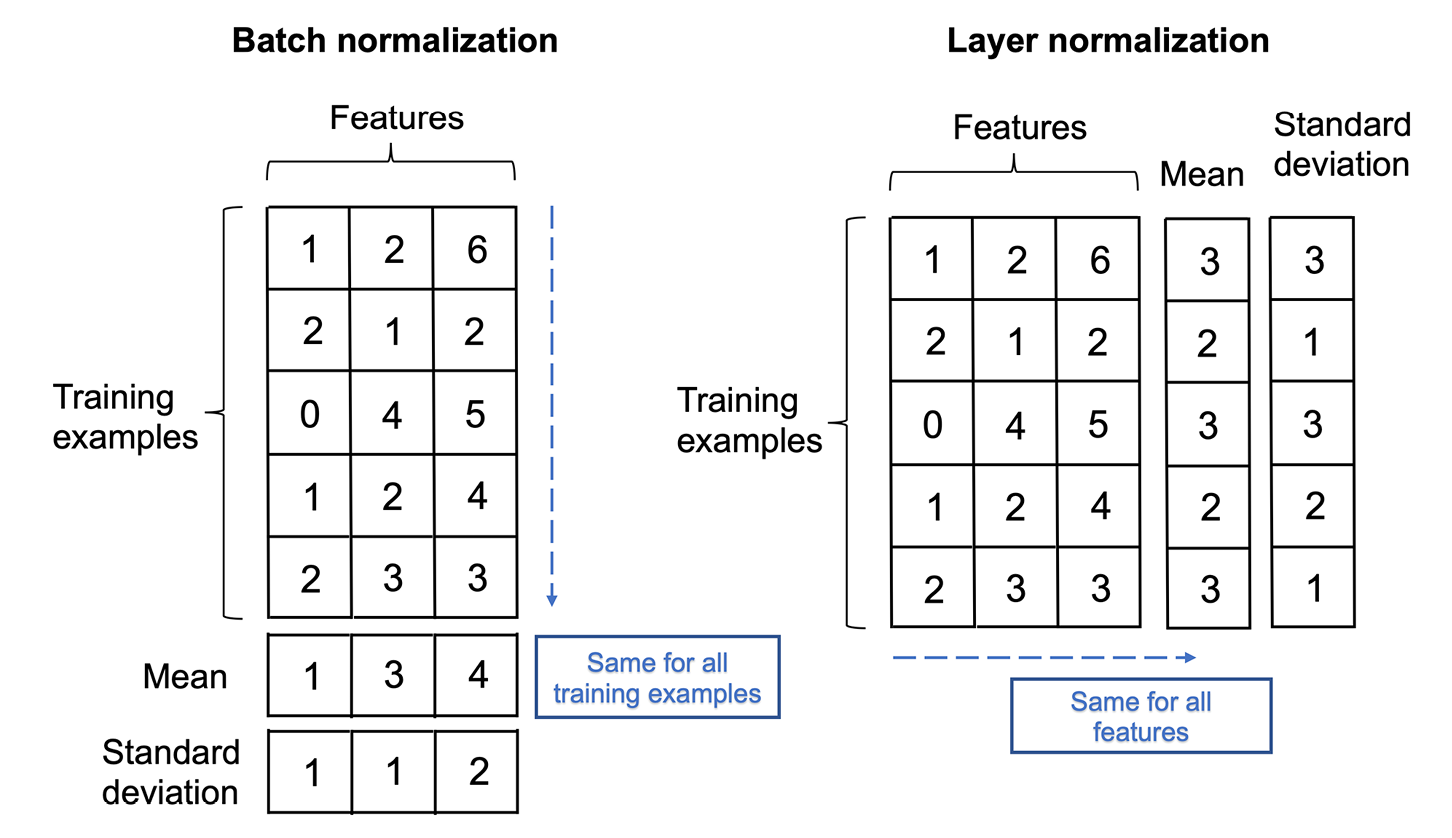
图 16.9:批量标准化和层标准化的比较
虽然传统上对每个特征的给定特征中的所有元素独立执行层归一化,但变换器中使用的层归一化扩展了这一概念,并为每个训练示例独立计算所有特征值的归一化统计。
由于层归一化计算每个训练示例的均值和标准差,它放宽了小批量大小约束或依赖关系。与批量归一化相比,层归一化因此能够从具有小批量大小和不同长度的数据中学习。但是,请注意,原始的 Transformer 架构没有可变长度的输入(需要时填充句子),并且与 RNN 不同,模型中没有重复。那么,我们如何证明使用层归一化而不是批量归一化是合理的呢?Transformers 通常在非常大的文本语料库上进行训练,这需要并行计算;这可能是通过批量标准化实现的挑战,这在训练示例之间具有依赖性。层归一化没有这种依赖性,因此对于转换器来说是更自然的选择。
利用未标记数据构建大规模语言模型
在本节中,我们将讨论流行从原始变压器中出现的大型变压器模型。这些转换器的一个共同主题是,它们在非常大的、未标记的数据集上进行了预训练,然后针对各自的目标任务进行了微调。首先,我们将介绍基于 Transformer 的模型的常见训练过程并解释它与原版有何不同变压器。然后,我们将专注于流行的大规模语言模型,包括生成式预训练转换器( GPT )、来自转换器的双向编码器表示( BERT ) 以及双向和自回归转换器( BART )。
预训练和微调变压器模型
在前面的部分,Attention 是我们所需要的:介绍原始 Transformer 架构,我们讨论了原始 Transformer 架构如何用于语言翻译。语言翻译是一个有监督的任务,需要一个标记的数据集,这可能非常昂贵。缺乏大型标记数据集是深度学习中长期存在的问题,尤其是对于像变压器这样的模型,它们比其他深度学习架构更需要数据。然而,鉴于每天都会生成大量文本(书籍、网站和社交媒体帖子),一个有趣的问题是我们如何使用这些未标记的数据来改进模型训练。
我们是否可以在转换器中利用未标记数据的答案是肯定的,诀窍是一个称为自我监督学习的过程:我们可以从监督学习中生成“标签”纯文本本身。例如,给定一个大型的未标记文本语料库,我们训练模型执行下一个词预测,即使模型能够学习到单词的概率分布,可以为成为强大的语言模型奠定坚实的基础。
自监督学习是传统的也称为无监督预训练,对于现代基于变压器的模型的成功至关重要。无监督预训练中的“无监督”据说是指我们使用未标记数据的事实;但是,由于我们使用数据的结构来生成标签(例如,前面提到的下一个词预测任务),它仍然是一个监督学习过程。
为了进一步详细说明无监督预训练和下一个单词预测的工作原理,如果我们有一个包含n 个单词的句子,预训练过程可以分解为以下三个步骤:
- 在时间步 1处,输入真实单词 1, ..., i -1。
- 让模型预测位置i处的单词并将其与真实单词i进行比较。
- 更新模型和时间步长,i := i +1。返回步骤 1 并重复,直到处理完所有单词。
我们应该注意到,在在下一次迭代中,我们总是向模型提供真实(正确)的词,而不是模型在上一轮中生成的词。
预训练的主要思想是利用纯文本,然后转移和微调模型以执行一些特定任务,这些任务可以使用(较小的)标记数据集。现在,有许多不同类型的预训练技术。例如,前面提到的下一个词预测任务可以被认为是一种单向的预训练方法。稍后,我们将介绍在不同语言模型中使用的其他预训练技术,以实现各种功能。
基于 Transformer 的模型的完整训练过程由两部分组成:(1)在大型未标记数据集上进行预训练;(2)使用标记数据集为特定下游任务训练(即微调)模型. 第一步,预训练模型不是为任何特定任务设计的,而是作为“通用”语言模型进行训练的。之后,通过第二步,可以通过对标记数据集的常规监督学习将其推广到任何定制任务。
对于可以从预训练模型获得的表示,主要有两种策略可以将模型迁移和采用到特定任务:(1)基于特征的方法和(2)微调方法。(在这里,我们可以将这些表示视为模型最后一层的隐藏层激活。)
基于特征的方法使用预训练的表示作为标记数据集的附加特征。这需要我们学习如何从预训练模型中提取句子特征。一个早以这种特征提取方法而闻名的模型是 Peters 及其同事在 2018 年在Deep Contextualized Word Representations论文中提出的ELMo(Embeddings from Language Models ) (网址:https ://arxiv.org/abs/1802.05365 )。ELMo 是一种预训练的双向语言模型,它以一定的速率掩盖单词。特别是,它随机屏蔽了 15% 的输入词预训练,建模任务就是填写这些空白,即预测缺失(掩蔽)的单词。这与我们之前介绍的单向方法不同,后者在时间步i隐藏了所有未来的单词。双向掩蔽使模型能够从两端学习,从而可以捕获有关句子的更多整体信息。预训练的 ELMo 模型可以生成高质量的句子表示,然后作为特定任务的输入特征。换句话说,我们可以将基于特征的方法视为一种基于模型的特征提取技术,类似于我们在第 5 章“通过降维压缩数据”中介绍的主成分分析。
另一方面,微调方法通过反向传播以常规监督方式更新预训练模型参数。与基于特征的方法不同,我们通常还会在预训练模型中添加另一个全连接层,以完成分类等某些任务,然后根据标记训练集上的预测性能更新整个模型。遵循这种方法的一个流行模型是 BERT,这是一种预先训练为双向语言模型的大型变压器模型。我们将在以下小节中更详细地讨论 BERT。此外,在本章的最后一节,我们将看到一个代码示例,展示如何使用我们在第 8 章中使用的电影评论数据集微调预训练的 BERT 模型以进行情感分类,将机器学习应用于情感分析,以及第 15 章,使用递归神经网络对序列数据进行建模。
在我们继续下一节并开始讨论流行的基于 Transformer 的语言模型之前,下图总结了训练 Transformer 模型的两个阶段,并说明了基于特征的方法和微调方法之间的区别: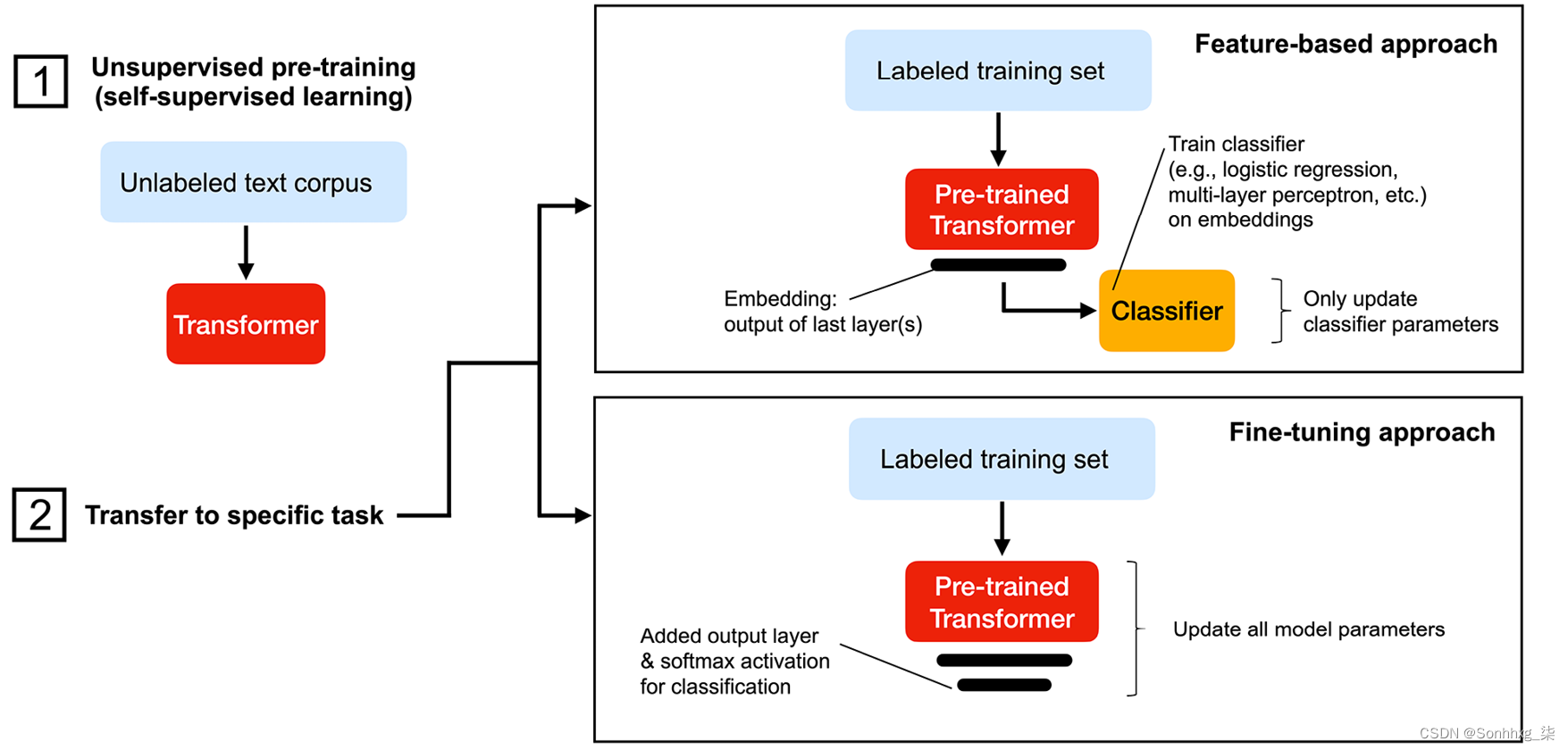
图 16.10:为下游任务采用预训练 Transformer 的两种主要方式
使用 GPT 来利用未标记的数据
Generative Pre-trained Transformer ( GPT ) 是一系列流行的大型语言模型,用于生成文本由 OpenAI 开发。2020 年 5 月发布的最新模型 GPT-3(Language Models are Few-Shot Learners)正在产生惊人的结果。GPT-3 生成的文本质量很难与人工生成的文本区分开来。在本节中,我们将讨论 GPT 模型是如何在高层次上工作的,以及它多年来是如何演变的。
如表 16.1所列,GPT 模型系列中的一个明显演变是参数的数量:
| 模型 | 发布年份 | 参数数量 | 标题 | 论文链接 |
|---|---|---|---|---|
| GPT-1 | 2018 | 1.1亿 | 通过生成式预训练提高语言理解 | https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf |
| GPT-2 | 2019 | 15亿 | 语言模型是无监督的多任务学习者 | [PDF] Language Models are Unsupervised Multitask Learners | Semantic Scholar |
| GPT-3 | 2020 | 1750亿 | 语言模型是少数人的学习者 | https://arxiv.org/pdf/2005.14165.pdf |
表 16.1:GPT 模型概述
但是我们不要超越我们自己,并且仔细看看 GPT-1 模型首先,它于 2018 年发布。它的训练过程可以分解为两个阶段:
- 对大量未标记的纯文本进行预训练
- 监督微调
如图16.11(改编自 GPT-1 论文)所示,我们可以将 GPT-1 视为由 (1) 解码器(并且没有编码器块)和 (2) 稍后添加的附加层组成的转换器。监督微调以完成特定任务:
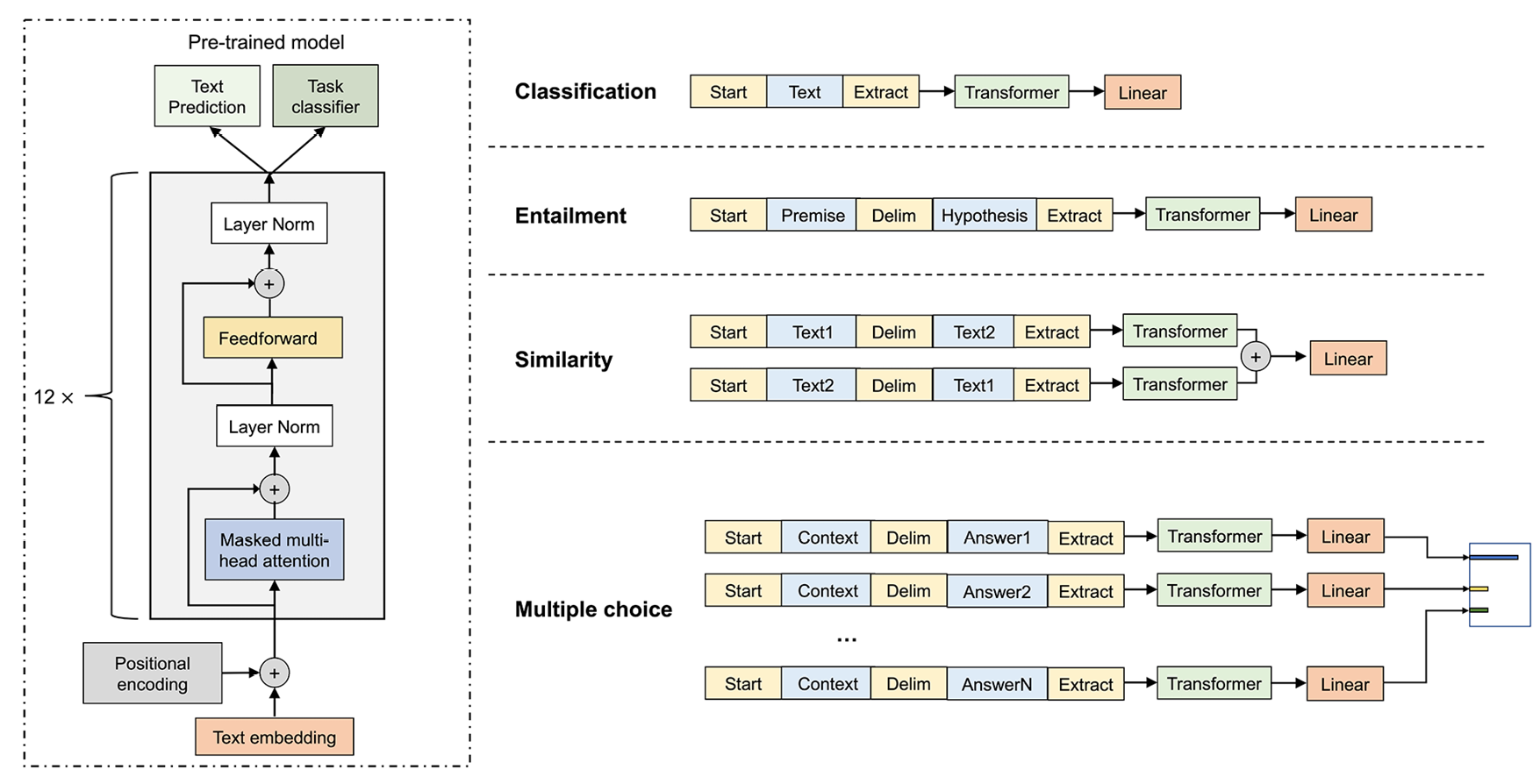
图 16.11:GPT-1 变压器
在图中,注意如果我们的任务是文本预测(预测下一个单词),那么模型在预训练步骤之后就准备好了。否则,例如,如果我们的任务与分类或回归有关,则需要有监督的微调。
期间预训练,GPT-1 利用转换器解码器结构,其中,在给定的单词位置,模型仅依靠前面的单词来预测下一个单词。GPT-1使用单向自注意力机制,而不是像 BERT 中的双向自注意力机制(我们将在本章后面介绍),因为 GPT-1 专注于文本生成而不是分类。在文本生成过程中,它以自然的从左到右的方向一个一个地生成单词。这里还有一个值得强调的方面:在训练过程中,对于每个位置,我们总是将来自先前位置的正确单词提供给模型。然而,在推理过程中,我们只是为模型提供它生成的任何单词,以便能够生成新文本。
得到预训练模型后(上图中标注为Transformer的块),然后我们将其插入到输入预处理块和线性层之间,其中线性层用作输出层(类似于我们在本书前面讨论的先前的深度神经网络模型)。对于分类任务,微调就像首先标记输入然后将其输入预训练模型和新添加的线性层一样简单,然后是 softmax 激活函数。但是,对于更复杂的任务(例如问答),输入以某种格式组织,不一定与预训练模型匹配,这需要为每个任务定制额外的处理步骤。鼓励对特定修改感兴趣的读者阅读 GPT-1 论文以获取更多详细信息(上表中提供了链接)。
GPT-1 也在零样本任务上表现出奇的好,这证明了它有能力成为一个通用的语言模型,可以为不同类型的任务定制,只需最少的任务特定微调。零样本学习通常描述了机器学习中的一种特殊情况,在这种情况下,在测试和推理过程中,模型需要对训练期间未观察到的类中的样本进行分类。在 GPT 的上下文中,零样本设置是指看不见的任务。
GPT的适应性启发研究人员摆脱特定于任务的输入和模型设置,这导致了GPT-2。不同于其前身 GPT-2在输入或微调阶段不再需要任何额外的修改。GPT-2 无需重新排列序列以匹配所需的格式,而是可以区分不同类型的输入,并通过少量提示(即所谓的“上下文”)执行相应的下游任务。这是通过以输入和任务类型为条件的输出概率建模来实现的
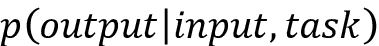
,而不是仅以输入为条件。例如,如果上下文包括translate to French, English text, French text.
这听起来比 GPT 更“人工智能”,确实是除了模型大小之外最显着的改进。正如其对应论文的标题所示(Language Models are Unsupervised Multitask Learners),无监督语言模型可能是零样本学习的关键,而 GPT-2 充分利用零样本任务迁移来构建这种多任务学习者。
与 GPT-2 相比,GPT-3 不那么“雄心勃勃”,因为它将焦点从零镜头转移到了镜头镜头。和小样本学习通过情境学习。虽然不提供特定于任务的训练示例似乎过于严格,但few-shot learning 不仅更现实,而且更类似于人类:人类通常需要看到一些示例才能学习新任务。正如它的名字所暗示的那样,few-shot learning 意味着模型可以看到任务的几个示例,而 one-shot 学习仅限于一个示例。
图 16.12说明了 zero-shot、one-shot、few-shot 和微调过程之间的区别:
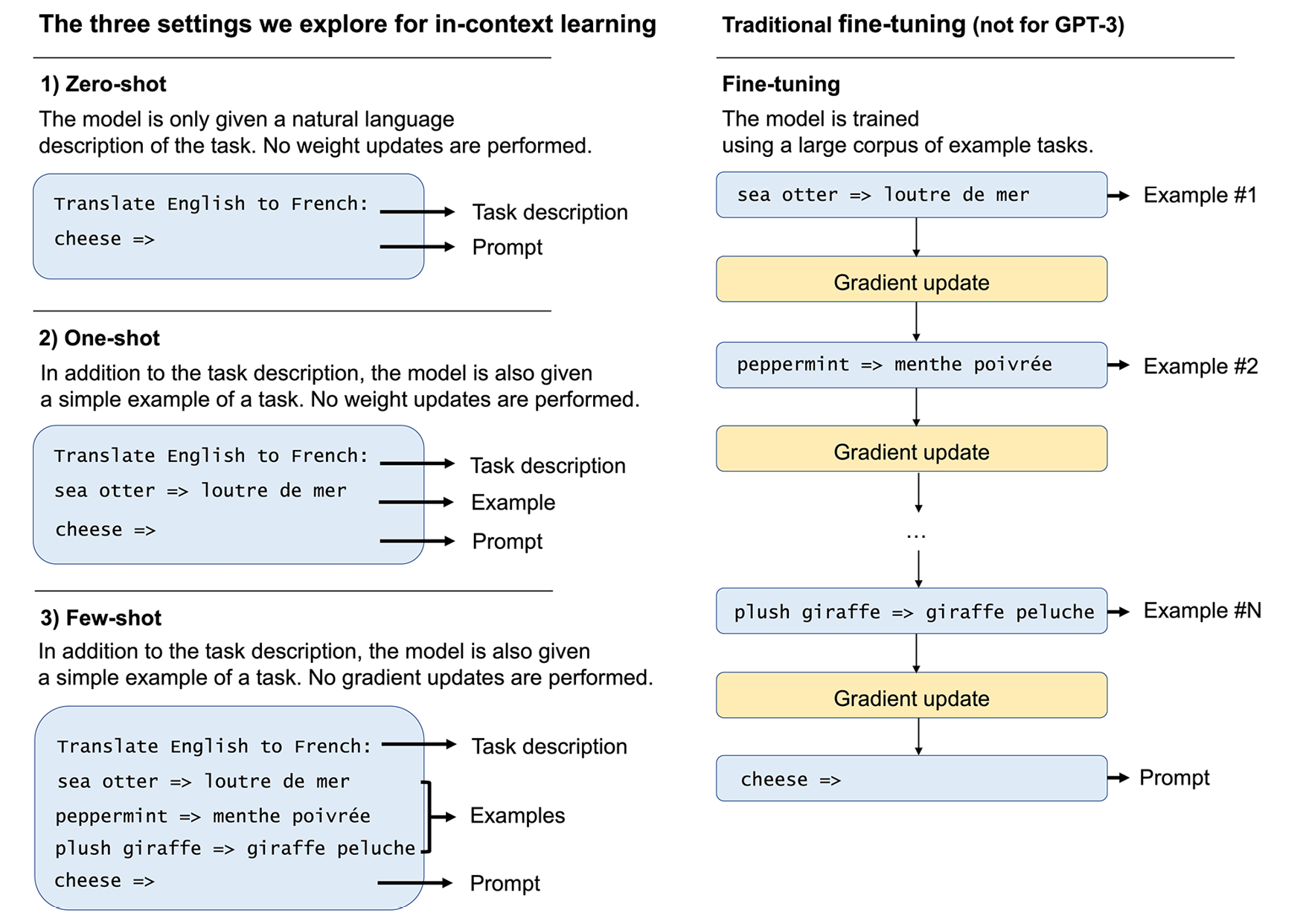
图 16.12:零样本、单样本和少样本学习的比较
的模型架构GPT-3 与 GPT-2 几乎相同,只是参数大小增加了 100 倍,并且使用了稀疏变换器。在我们之前讨论的原始(密集)注意力机制中,每个元素都关注输入中的所有其他元素,这会随着
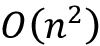
复杂性而扩展。稀疏注意力通过只关注一个子集来提高效率尺寸有限的元素,通常与 成比例。感兴趣的读者可以通过访问稀疏变换器论文了解更多关于特定子集选择的信息:Rewon Child 等人的用稀疏变换器生成长序列。2019(网址:https ://arxiv.org/abs/1904.10509 )。
使用 GPT-2 生成新文本
在我们继续之前下一个transformer架构,我们来看看了解我们如何使用最新的 GPT 模型生成新文本。请注意,GPT-3 仍然相对较新,目前只能通过OpenAI API上的 OpenAI API 作为测试版使用。但是,Hugging Face(一家流行的 NLP 和机器学习公司; http://huggingface.co )已经提供了 GPT-2 的实现,我们将使用它。
我们将访问GPT-2 via transformers,这是一个非常Hugging Face 创建的综合 Python 库,为预训练和微调提供各种基于转换器的模型。用户还可以在论坛上讨论和分享他们定制的模型。如果您有兴趣,请随时查看并与社区互动:https ://discuss.huggingface.co 。
安装变压器版本 4.9.1
因为这个包是快速发展,您可能无法复制以下小节中的结果。作为参考,本教程使用 2021 年 6 月发布的 4.9.1 版本。要安装我们在本书中使用的版本,您可以在终端中执行以下命令从 PyPI 安装它:
pip install transformers==4.9.1我们还建议您查看官方安装页面上的最新说明:
Installation
安装transformers库后,我们可以运行以下代码来导入可以生成新文本的预训练 GPT 模型:
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2')然后,我们可以使用文本片段提示模型,并要求它根据该输入片段生成新文本:
>>> set_seed(123)
>>> generator("Hey readers, today is",
... max_length=20,
... num_return_sequences=3)
[{'generated_text': "Hey readers, today is not the last time we'll be seeing one of our favorite indie rock bands"},{'generated_text': 'Hey readers, today is Christmas. This is not Christmas, because Christmas is so long and I hope'},{'generated_text': "Hey readers, today is CTA Day!\n\nWe're proud to be hosting a special event"}]从输出中可以看出,该模型根据我们的文本片段生成了三个合理的句子。如果您想探索更多示例,请随意更改随机种子和最大序列长度。
另外,和之前一样如图16.10 所示,我们可以使用变压器模型来生成用于训练其他模型的特征。以下代码说明了我们如何使用 GPT-2 根据输入文本生成特征:
>>> from transformers import GPT2Tokenizer
>>> tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
>>> text = "Let us encode this sentence"
>>> encoded_input = tokenizer(text, return_tensors='pt')
>>> encoded_input
{'input_ids': tensor([[ 5756, 514, 37773, 428, 6827]]), 'attention_mask': tensor([[1, 1, 1, 1, 1]])}此代码将输入句子文本编码为 GPT-2 模型的标记化格式。正如我们所见,它将字符串映射为整数表示,并将注意力掩码设置为全 1,这意味着当我们将编码输入传递给模型时,所有单词都会被处理,如下所示:
>>> from transformers import GPT2Model
>>> model = GPT2Model.from_pretrained('gpt2')
>>> output = model(**encoded_input)该output变量存储了最后一个隐藏状态,也就是我们基于 GPT-2 对输入句子的特征编码:
>>> output['last_hidden_state'].shape
torch.Size([1, 5, 768])为了抑制冗长的输出,我们只展示了张量的形状。它的第一个维度是批量大小(我们只有一个输入文本),然后是句子长度和特征编码的大小。在这里,五个单词中的每一个都被编码为一个 768 维的向量。
现在,我们可以将此特征编码应用于给定数据集,并基于基于 GPT-2 的特征表示训练下游分类器,而不是使用第 8 章中讨论的词袋模型,将机器学习应用于情感分析。
此外,如前所述,使用大型预训练语言模型的另一种方法是微调。我们将在本章后面看到一个微调示例。
如果您对使用的其他详细信息感兴趣GPT-2,我们推荐以下文档页面:
- gpt2 · Hugging Face
- OpenAI GPT2
使用 BERT 进行双向预训练
BERT,它的完整名称为来自 Transformers 的双向编码器表示,由 Google 研究团队于 2018 年创建(BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding by J. Devlin、M. Chang、K. Lee和K. Toutanova,https: //arxiv.org/abs/1810.04805)。作为参考,尽管我们无法直接比较 GPT 和 BERT,因为它们是不同的架构,但 BERT 有 3.45 亿个参数(这使得它仅比 GPT-1 略大,其大小仅为 GPT-2 的 1/5)。
顾名思义,BERT具有基于变压器编码器的模型结构,该结构利用双向训练过程。(或者,更准确地说,我们可以将 BERT 视为使用“非定向”训练,因为它一次读取所有输入元素。)在这种设置下,某个单词的编码取决于前面和后面的单词。回想一下,在 GPT 中,输入元素以自然的从左到右的顺序读入,这有助于形成强大的生成语言模型。双向训练禁用了 BERT 逐字生成句子的能力,但为其他任务(例如分类)提供了更高质量的输入编码,因为该模型现在可以在两个方向上处理信息。
回想一下,在转换器的编码器中,令牌编码是位置编码和令牌嵌入的总和。在 BERT 编码器中,有一个额外的段嵌入,指示该令牌属于哪个段。这意味着每个令牌表示包含三个成分,如图 16.13所示:

图 16.13:为 BERT 编码器准备输入
为什么我们在 BERT 中需要这些额外的细分信息?对这一段信息的需求源于 BERT 的特殊预训练任务,称为下一句预测。在这个预训练任务中,每个训练示例都包含两个句子,因此需要特殊的句段符号来表示它属于第一个句子还是第二个句子。
现在,让我们看看 BERT 的更详细的预训练任务。与所有其他基于转换器的语言模型类似,BERT 有两个训练阶段:预训练和微调。预训练包括两个无监督任务:掩码语言建模和下一句预测。
在掩码语言模型( MLM ) 中,标记被所谓的掩码标记,随机替换[MASK],并且需要模型来预测这些隐藏词。与 GPT 中的下一个词预测相比,BERT 中的 MLM 更类似于“填空”,因为该模型可以处理句子中的所有标记(被屏蔽的标记除外)。但是,简单地屏蔽单词可能会导致预训练和微调之间的不一致,因为[MASK]标记不会出现在常规文本中。为了缓解这种情况,对选择进行掩蔽的单词进行了进一步的修改。例如,BERT 中 15% 的单词被标记为掩码。然后将这 15% 的随机选择的单词进一步处理如下:
- 10% 的时间保持单词不变
- 10% 的时间用随机词替换原始词标记
[MASK]80% 的时间用掩码标记替换原始单词标记
除了在将令牌引入训练过程时避免上述预训练和微调之间的不一致之外[MASK],这些修改还有其他好处。首先,不变的词包括保持原始令牌信息的可能性;否则,模型只能从上下文中学习,而不能从掩码中学习。其次,10% 的随机词可以防止模型变得懒惰,例如,除了返回给出的内容之外什么都不学。通过消融研究选择了掩蔽、随机化和保持单词不变的概率(参见 GPT-2 论文);例如,作者测试了不同的设置,发现这种组合效果最好。
图 16.14说明了一个例如,单词fox被屏蔽,并且以一定的概率保持不变或被替换为[MASK]or coffee。然后需要该模型来预测被屏蔽(突出显示)的单词是什么,如图 16.14 所示:

图 16.14:传销的一个例子
考虑到 BERT 的双向编码,下一句预测是对下一个词预测任务的自然修改。事实上,许多重要的 NLP 任务,例如问答,都依赖于文档中两个句子的关系。这种关系很难通过常规语言模型捕获,因为由于输入长度限制,下一个词预测训练通常发生在单句级别。
在下一句预测任务中,模型给出了两个句子,A 和 B,格式如下:
[CLS] A [九月] B [九月]
[CLS] 是一个分类标记,用作解码器输出中预测标签的占位符,以及表示句子开头的标记。另一方面,附加 [SEP] 标记以表示每个句子的结尾。然后模型需要对 B 是否是 A 的下一个句子(“IsNext”)进行分类。为了给模型提供一个平衡的数据集,50% 的样本被标记为“IsNext”,而剩余的样本被标记为“NotNext”。
BERT 同时在这两个任务上进行了预训练,掩蔽句子和下一句预测。在这里,BERT 的训练目标是最小化两个任务的组合损失函数。
从预训练模型开始,在微调阶段需要针对不同的下游任务进行具体的修改。每个输入示例需要匹配一定的格式;例如,它应该以 [CLS] 标记开头,如果它包含多个句子,则使用 [SEP] 标记分隔。
粗略地说,BERT可以在四类任务上进行微调:(a)句子对分类;(b) 单句分类;(c) 问答;(d) 单句标记。
其中,(a) 和 (b) 是序列级分类任务,只需要在 [CLS] 标记的输出表示中添加一个额外的 softmax 层即可。另一方面,(c)和(d)是令牌级别的分类任务。这意味着模型将所有相关标记的输出表示传递给 softmax 层,以预测每个单独标记的类标签。
问答
与其他流行的分类任务(如情感分类或语音标记)相比,任务 (c)(问答)似乎很少被讨论。在问答中,每个输入示例可以分为两部分,即问题和有助于回答问题的段落。该模型需要指出段落中形成正确答案的开始和结束标记。这意味着模型需要为段落中的每个标记生成一个标签,指示该标记是开始标记还是结束标记,或者两者都不是。作为旁注,值得一提的是,输出可能包含出现在开始标记之前的结束标记,这将导致生成答案时发生冲突。这种输出将被识别为问题的“No Answer”。
如图16.15所示,模型微调设置有一个非常简单的结构:一个输入编码器附加到一个预训练的 BERT,并添加一个 softmax 层用于分类。一旦建立模型结构,所有参数将随着学习过程进行调整。
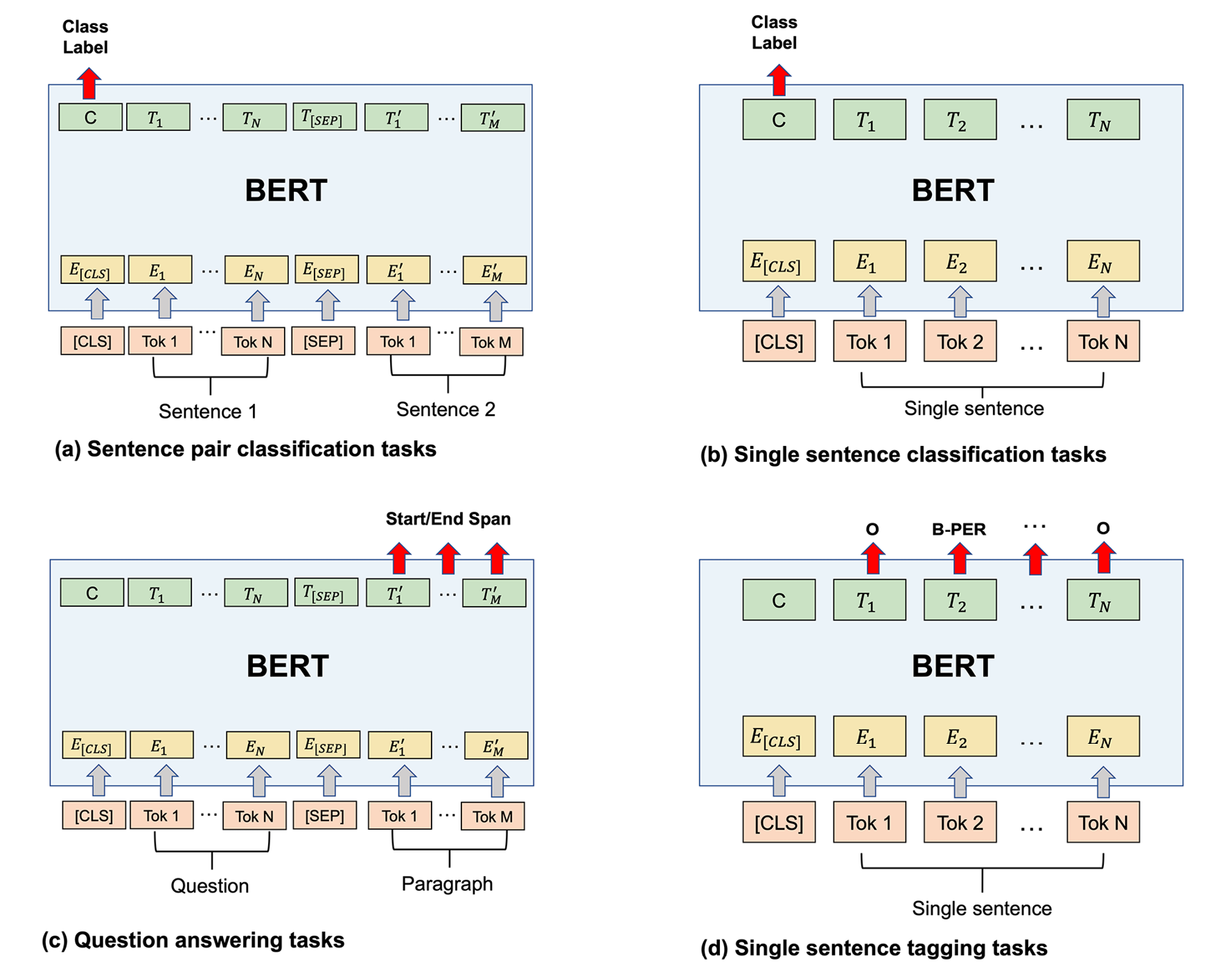
图 16.15:使用 BERT 微调不同的语言任务
两全其美:BART
双向自回归变压器,缩写为BART,由2019 年 Facebook AI Research 的研究人员:BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension,Lewis及其同事,https://arxiv.org/abs/1910.13461. 回想一下,在前面的部分中,我们认为 GPT 使用了变压器的解码器结构,而 BERT 使用了变压器的编码器结构。因此,这两个模型能够很好地执行不同的任务:GPT 的专长是生成文本,而 BERT 在分类任务上表现更好。BART 可以看作是 GPT 和 BERT 的泛化。正如本节的标题所示,BART 能够完成生成和分类文本这两项任务。它能够很好地处理这两个任务的原因是该模型带有一个双向编码器以及一个从左到右的自回归解码器。
您可能想知道这与原始变压器有何不同。模型大小有一些变化,还有一些小的变化,比如激活函数的选择。然而,更有趣的变化之一是 BART 可以使用不同的模型输入。最初的 Transformer 模型是为语言翻译而设计的,因此有两个输入:编码器的待翻译文本(源序列)和解码器的翻译(目标序列)。此外,解码器还接收编码的源序列,如图 16.6 所示. 然而,在 BART 中,输入格式被概括为只使用源序列作为输入。BART 可以执行更广泛的任务,包括语言翻译,其中仍然需要目标序列来计算损失和微调模型,但不需要将其直接输入解码器。
现在让我们仔细看看BART 的模型结构。如前所述,BART 由一个双向编码器和一个自回归解码器组成。在接收到纯文本形式的训练示例后,输入将首先被“损坏”,然后由编码器进行编码。这些输入编码将与生成的令牌一起传递给解码器。将计算编码器输出和原始文本之间的交叉熵损失,然后通过学习过程进行优化。想象一个转换器,我们有两个不同语言的文本作为解码器的输入:要翻译的初始文本(源文本)和生成的目标语言文本。BART 可以理解为用损坏的文本替换前者,用输入文本本身替换后者。
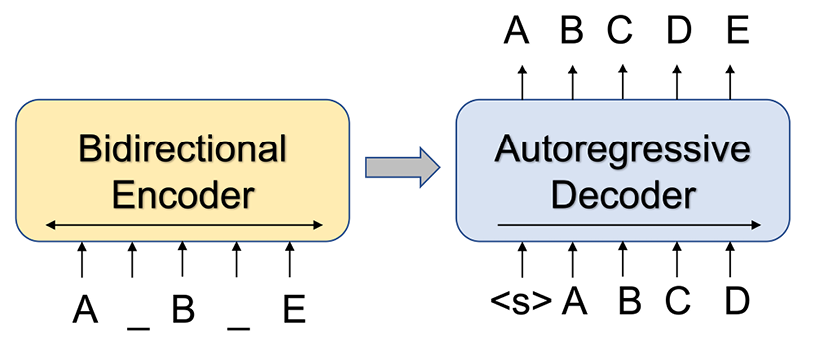
图 16.16:BART 的模型结构
为了更详细地解释损坏步骤,回想一下 BERT 和 GPT 是通过重构掩码单词进行预训练的:BERT 是“填补空白”,GPT 是“预测下一个单词”。这些预训练任务也可以被识别为重建损坏的句子,因为掩蔽词是损坏句子的一种方式。BART 提供了以下可应用于纯文本的损坏方法:
- 令牌掩码
- 令牌删除
- 文字填充
- 句子排列
- 文档轮换
上面列出的一种或多种技术可以应用于同一个句子;在最坏的情况下,所有信息都被污染和损坏,文本变得毫无用处。因此,编码器的实用性有限,并且只有解码器模块正常工作,该模型本质上将变得更类似于单向语言。
巴特可以在广泛的下游任务上进行微调,包括 (a) 序列分类、(b) 标记分类、(c) 序列生成和 (d) 机器翻译。与 BERT 一样,需要对输入进行小的更改才能执行不同的任务。
在序列分类任务中,需要在输入上附加一个额外的token作为生成的标签token,类似于BERT中的[CLS]token。此外,不会干扰输入,而是将未损坏的输入馈入编码器和解码器,以便模型可以充分利用输入。
对于token分类,不需要额外的token,模型可以直接使用为每个token生成的表示进行分类。
由于存在编码器,BART 中的序列生成与 GPT 略有不同。通过 BART 的序列生成任务不是从头开始生成文本,而是更类似于摘要,其中模型被赋予上下文语料库,并被要求为某些问题生成摘要或抽象答案。为此,整个输入序列被馈送到编码器,而解码器自回归生成输出。
最后,考虑到 BART 与原始转换器之间的相似性,BART 执行机器翻译是很自然的。然而,研究人员并没有遵循与训练原始变压器完全相同的程序,而是考虑了将整个 BART 模型合并为预训练解码器的可能性。为了完成翻译模型,添加了一组新的随机初始化参数作为新的附加编码器。然后,微调阶段可以分两步完成:
- 一、冻结除编码器外的所有参数
- 然后,更新模型中的所有参数
巴特在针对各种任务的多个基准数据集上进行了评估,与其他著名的语言模型(例如 BERT)相比,它获得了非常有竞争力的结果。特别是,对于包括抽象问答、对话响应和摘要任务在内的生成任务,BART 取得了最先进的结果。
在 PyTorch 中微调 BERT 模型
现在我们已经介绍并讨论了所有必要的概念以及原始变压器和流行的基于变压器的模型背后的理论,是时候看看更多实用部分!在本节中,您将学习如何在 PyTorch 中微调 BERT 模型以进行情感分类。
请注意,尽管有许多其他基于变压器的模型可供选择,但 BERT 提供了一个模型受欢迎程度和具有可管理的模型大小,以便可以在单个 GPU 上对其进行微调。另请注意,考虑到 Hugging Face 提供的 Python 包的可用性,从头开始预训练 BERT 是很痛苦的,而且完全没有必要transformers,其中包括一堆准备好进行微调的预训练模型。
在以下部分中,您将了解如何准备和标记 IMDb 电影评论数据集,并微调精炼的 BERT 模型以执行情感分类。我们特意选择情感分类作为一个简单但经典的例子,尽管语言模型还有许多其他有趣的应用。此外,通过使用熟悉的 IMDb 电影评论数据集,我们可以通过将 BERT 模型与第 8 章中的逻辑回归模型、将机器学习应用于情感分析和第 15 章中的 RNN进行比较来更好地了解 BERT 模型的预测性能。 ,使用递归神经网络对序列数据进行建模。
加载 IMDb 电影评论数据集
在本小节中,我们将首先加载所需的包和数据集,分为训练集、验证集和测试集。
对于本教程的BERT相关部分,我们将主要使用上一节安装的Hugging Face创建的开源transformers库(🤗 Transformers ),使用GPT-2生成新文本。
DistilBERT模型_我们在本章中使用的是通过提炼预训练的 BERT 基础模型创建的轻量级 Transformer 模型。原始的未加壳 BERT 基础模型包含超过 1.1 亿个参数,而 DistilBERT 的参数减少了 40%。此外,DistilBERT运行速度提高了 60%,并且在 GLUE 语言理解基准测试中仍保留了 BERT 95% 的性能。
以下代码导入我们将在本章中使用的所有包来准备数据和微调 DistilBERT 模型:
>>> import gzip
>>> import shutil
>>> import time
>>> import pandas as pd
>>> import requests
>>> import torch
>>> import torch.nn.functional as F
>>> import torchtext
>>> import transformers
>>> from transformers import DistilBertTokenizerFast
>>> from transformers import DistilBertForSequenceClassification接下来,我们指定一些常规设置,包括我们训练网络的 epoch 数、设备规格和随机种子。要重现结果,请确保设置特定的随机种子,例如123:
>>> torch.backends.cudnn.deterministic = True
>>> RANDOM_SEED = 123
>>> torch.manual_seed(RANDOM_SEED)
>>> DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
>>> NUM_EPOCHS = 3我们将研究 IMDb 电影评论数据集,您已经在第 8 章和第15章中看到了该数据集。以下代码获取压缩数据集并将其解压缩:
>>> url = ("https://github.com/rasbt/"
... "machine-learning-book/raw/"
... "main/ch08/movie_data.csv.gz")
>>> filename = url.split("/")[-1]
>>> with open(filename, "wb") as f:
... r = requests.get(url)
... f.write(r.content)
>>> with gzip.open('movie_data.csv.gz', 'rb') as f_in:
... with open('movie_data.csv', 'wb') as f_out:
... shutil.copyfileobj(f_in, f_out)如果你的硬盘上还有第 8 章movie_data.csv的文件,你可以跳过这个下载和解压过程。
接下来,我们将数据加载到pandasDataFrame并确保它看起来没问题:
>>> df = pd.read_csv('movie_data.csv')
>>> df.head(3)
图 16.17:IMDb 影评数据集的前三行
下一步是将数据集拆分为单独的训练、验证和测试集。在这里,我们将 70% 的评论用于训练集,10% 用于验证集,剩下的 20% 用于测试:
>>> train_texts = df.iloc[:35000]['review'].values
>>> train_labels = df.iloc[:35000]['sentiment'].values
>>> valid_texts = df.iloc[35000:40000]['review'].values
>>> valid_labels = df.iloc[35000:40000]['sentiment'].values
>>> test_texts = df.iloc[40000:]['review'].values
>>> test_labels = df.iloc[40000:]['sentiment'].values标记数据集
至此,我们获得了用于训练、验证和测试集的文本和标签。现在,我们将使用从预训练模型类继承的标记器实现将文本标记为单个单词标记:
>>> tokenizer = DistilBertTokenizerFast.from_pretrained(
... 'distilbert-base-uncased'
... )
>>> train_encodings = tokenizer(list(train_texts), truncation=True, padding=True)
>>> valid_encodings = tokenizer(list(valid_texts), truncation=True, padding=True)
>>> test_encodings = tokenizer(list(test_texts), truncation=True, padding=True)选择不同的分词器
如果您对应用不同类型的分词器感兴趣,请随意探索包tokenizers( Tokenizers ),它也是由 Hugging Face 构建和维护的。然而,继承的分词器保持了预训练模型和数据集之间的一致性,这为我们节省了寻找模型对应的特定分词器的额外工作。换句话说,如果您想微调预训练模型,推荐使用继承的标记器。
最后,让我们将所有内容打包到一个名为IMDbDataset并创建相应数据加载器的类中。这样一个自定义的数据集类让我们可以为我们的自定义电影评论数据集定制所有相关的特性和功能,DataFrame格式为:
>>> class IMDbDataset(torch.utils.data.Dataset):
... def __init__(self, encodings, labels):
... self.encodings = encodings
... self.labels = labels
>>> def __getitem__(self, idx):
... item = {key: torch.tensor(val[idx])
... for key, val in self.encodings.items()}
... item['labels'] = torch.tensor(self.labels[idx])
... return item
>>> def __len__(self):
... return len(self.labels)
>>> train_dataset = IMDbDataset(train_encodings, train_labels)
>>> valid_dataset = IMDbDataset(valid_encodings, valid_labels)
>>> test_dataset = IMDbDataset(test_encodings, test_labels)
>>> train_loader = torch.utils.data.DataLoader(
... train_dataset, batch_size=16, shuffle=True)
>>> valid_loader = torch.utils.data.DataLoader(
... valid_dataset, batch_size=16, shuffle=False)
>>> test_loader = torch.utils.data.DataLoader(
... test_dataset, batch_size=16, shuffle=False)虽然从前面的章节中应该对整体数据加载器设置很熟悉,但一个值得注意的细节是方法中的item变量__getitem__。我们之前生成的编码存储了大量关于标记化文本的信息。通过字典我们用来将字典分配给item变量的理解,我们只提取最相关的信息。例如,生成的字典条目包括input_ids(与标记对应的词汇表中的唯一整数)、labels(类标签)和attention_mask。这里,attention_mask是一个具有二进制值(0 和 1)的张量,表示模型应该关注哪些标记。特别是,0 对应于用于将序列填充为相等长度的标记,并且被模型忽略;1 对应于实际的文本标记。
加载和微调预训练的 BERT 模型
照顾了数据准备,在本小节中,您将看到如何加载预训练的 DistilBERT 模型并使用我们刚刚创建的数据集对其进行微调。加载预训练模型的代码如下:
>>> model = DistilBertForSequenceClassification.from_pretrained(
... 'distilbert-base-uncased')
>>> model.to(DEVICE)
>>> model.train()
>>> optim = torch.optim.Adam(model.parameters(), lr=5e-5)DistilBertForSequenceClassification指定我们想要微调模型的下游任务,在这种情况下是序列分类。如前所述,'distilbert-base-uncased'它是 BERT 无外壳基础模型的轻量级版本,具有可管理的大小和良好的性能。请注意,“未区分大小写”表示模型不区分大小写字母。
使用其他预训练的转换器
变压器包_还提供了许多其他预训练模型和各种下游任务进行微调。在https://huggingface.co/transformers/上查看它们。
现在,是时候训练了该模型。我们可以把它分成两部分。首先,我们需要定义一个准确度函数来评估模型的性能。请注意,此精度函数计算常规分类精度。为什么这么冗长?在这里,我们将逐批加载数据集,以解决使用大型深度学习模型时 RAM 或 GPU 内存 (VRAM) 的限制:
>>> def compute_accuracy(model, data_loader, device):
... with torch.no_grad():
... correct_pred, num_examples = 0, 0
... for batch_idx, batch in enumerate(data_loader):
... ### Prepare data
... input_ids = batch['input_ids'].to(device)
... attention_mask = \
... batch['attention_mask'].to(device)
... labels = batch['labels'].to(device)... outputs = model(input_ids,
... attention_mask=attention_mask)
... logits = outputs['logits']
... predicted_labels = torch.argmax(logits, 1)
... num_examples += labels.size(0)
... correct_pred += \
... (predicted_labels == labels).sum()
... return correct_pred.float()/num_examples * 100在compute_accuracy函数中,我们加载给定的批次,然后从输出中获取预测标签。在执行此操作时,我们通过 跟踪示例总数num_examples。correct_pred同样,我们通过变量跟踪正确预测的数量。最后,在我们遍历整个数据集之后,我们将准确率计算为正确预测标签的比例。
总体而言,通过该compute_accuracy功能,您已经可以一瞥我们如何使用变压器模型来获得类标签。也就是说,我们向模型input_ids提供attention_mask信息以及在此表示标记是实际文本标记还是用于将序列填充为相等长度的标记的信息。然后model调用返回输出,这是一个特定于转换器库的SequenceClassifierOutput对象。然后,我们从这个对象中获取我们通过函数转换为类标签的 logits,argmax就像我们在前几章中所做的那样。
最后,让我们进入主要部分:训练(或者更确切地说,微调)循环。您会注意到,从转换器库中微调模型与在纯 PyTorch 中从头开始训练模型非常相似:
>>> start_time = time.time()
>>> for epoch in range(NUM_EPOCHS):... model.train()... for batch_idx, batch in enumerate(train_loader):... ### Prepare data
... input_ids = batch['input_ids'].to(DEVICE)
... attention_mask = batch['attention_mask'].to(DEVICE)
... labels = batch['labels'].to(DEVICE)
... ### Forward pass
... outputs = model(input_ids,
... attention_mask=attention_mask,
... labels=labels)
... loss, logits = outputs['loss'], outputs['logits']... ### Backward pass
... optim.zero_grad()
... loss.backward()
... optim.step()... ### Logging
... if not batch_idx % 250:
... print(f'Epoch: {epoch+1:04d}/{NUM_EPOCHS:04d}'
... f' | Batch'
... f'{batch_idx:04d}/'
... f'{len(train_loader):04d} | '
... f'Loss: {loss:.4f}')... model.eval()
... with torch.set_grad_enabled(False):
... print(f'Training accuracy: '
... f'{compute_accuracy(model, train_loader, DEVICE):.2f}%'
... f'\nValid accuracy: '
... f'{compute_accuracy(model, valid_loader, DEVICE):.2f}%')... print(f'Time elapsed: {(time.time() - start_time)/60:.2f} min')... print(f'Total Training Time: {(time.time() - start_time)/60:.2f} min')
... print(f'Test accuracy: {compute_accuracy(model, test_loader, DEVICE):.2f}%')产生的输出通过前面的代码如下(注意代码不是完全确定的,这就是为什么你得到的结果可能会略有不同):
Epoch: 0001/0003 | Batch 0000/2188 | Loss: 0.6771
Epoch: 0001/0003 | Batch 0250/2188 | Loss: 0.3006
Epoch: 0001/0003 | Batch 0500/2188 | Loss: 0.3678
Epoch: 0001/0003 | Batch 0750/2188 | Loss: 0.1487
Epoch: 0001/0003 | Batch 1000/2188 | Loss: 0.6674
Epoch: 0001/0003 | Batch 1250/2188 | Loss: 0.3264
Epoch: 0001/0003 | Batch 1500/2188 | Loss: 0.4358
Epoch: 0001/0003 | Batch 1750/2188 | Loss: 0.2579
Epoch: 0001/0003 | Batch 2000/2188 | Loss: 0.2474
Training accuracy: 96.32%
Valid accuracy: 92.34%
Time elapsed: 20.67 min
Epoch: 0002/0003 | Batch 0000/2188 | Loss: 0.0850
Epoch: 0002/0003 | Batch 0250/2188 | Loss: 0.3433
Epoch: 0002/0003 | Batch 0500/2188 | Loss: 0.0793
Epoch: 0002/0003 | Batch 0750/2188 | Loss: 0.0061
Epoch: 0002/0003 | Batch 1000/2188 | Loss: 0.1536
Epoch: 0002/0003 | Batch 1250/2188 | Loss: 0.0816
Epoch: 0002/0003 | Batch 1500/2188 | Loss: 0.0786
Epoch: 0002/0003 | Batch 1750/2188 | Loss: 0.1395
Epoch: 0002/0003 | Batch 2000/2188 | Loss: 0.0344
Training accuracy: 98.35%
Valid accuracy: 92.46%
Time elapsed: 41.41 min
Epoch: 0003/0003 | Batch 0000/2188 | Loss: 0.0403
Epoch: 0003/0003 | Batch 0250/2188 | Loss: 0.0036
Epoch: 0003/0003 | Batch 0500/2188 | Loss: 0.0156
Epoch: 0003/0003 | Batch 0750/2188 | Loss: 0.0114
Epoch: 0003/0003 | Batch 1000/2188 | Loss: 0.1227
Epoch: 0003/0003 | Batch 1250/2188 | Loss: 0.0125
Epoch: 0003/0003 | Batch 1500/2188 | Loss: 0.0074
Epoch: 0003/0003 | Batch 1750/2188 | Loss: 0.0202
Epoch: 0003/0003 | Batch 2000/2188 | Loss: 0.0746
Training accuracy: 99.08%
Valid accuracy: 91.84%
Time elapsed: 62.15 min
Total Training Time: 62.15 min
Test accuracy: 92.50%在这段代码中,我们迭代多个时代。在每个时期,我们执行以下步骤:
- 将输入加载到我们正在处理的设备(GPU 或 CPU)中
- 计算模型输出和损失
- 通过反向传播损失调整权重参数
- 在训练集和验证集上评估模型性能
请注意,训练时间可能因不同设备而异。在三个 epoch 之后,测试数据集的准确率达到了 93% 左右,与第 15 章RNN 实现的 85% 的测试准确率相比,这是一个巨大的进步。
使用 Trainer API 更方便地微调转换器
在上一个在小节中,我们在 PyTorch 中手动实现了训练循环,以说明微调变压器模型与从头开始训练 RNN 或 CNN 模型并没有太大区别。但是,请注意,该transformers库包含几个不错的额外功能以提供额外的便利,例如我们将在本小节中介绍的 Trainer API。
Hugging Face 提供的 Trainer API 针对 Transformer 模型进行了优化,具有广泛的训练选项和各种内置功能。使用 Trainer API 时,我们可以跳过自己编写训练循环的工作,训练或微调 Transformer 模型就像调用函数(或方法)一样简单。让我们看看这在实践中是如何工作的。
通过加载预训练模型后
>>> model = DistilBertForSequenceClassification.from_pretrained(
... 'distilbert-base-uncased')
>>> model.to(DEVICE)
>>> model.train();然后可以用以下代码替换上一节中的训练循环:
>>> optim = torch.optim.Adam(model.parameters(), lr=5e-5)
>>> from transformers import Trainer, TrainingArguments
>>> training_args = TrainingArguments(
... output_dir='./results',
... num_train_epochs=3,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... logging_dir='./logs',
... logging_steps=10,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=train_dataset,
... optimizers=(optim, None) # optim and learning rate scheduler
... )在前面的代码片段中,我们首先定义了训练参数,它们是关于输入和输出位置、时期数和批量大小的相对不言自明的设置。我们试图使设置尽可能简单;但是,还有许多其他设置可用,我们建议您查阅TrainingArguments文档页面以获取更多详细信息:https ://huggingface.co/transformers/main_classes/trainer.html#trainingarguments 。
然后我们将这些TrainingArguments设置传递给Trainer类以实例化一个新trainer对象。在trainer使用设置、要微调的模型以及训练和评估集启动之后,我们可以通过调用该trainer.train()方法来训练模型(稍后我们将进一步使用该方法)。就是这样,使用 Trainer API 就像前面的代码一样简单,不需要更多的样板代码。
然而,你可能已经注意到这些代码片段中没有涉及测试数据集,并且我们没有在本小节中指定任何评估指标。这是因为 Trainer API 默认只显示训练损失,不提供模型评估。有两种方法可以显示最终模型的性能,我们将在下面进行说明。
评估最终模型的第一种方法是将评估函数定义compute_metrics为另一个Trainer实例的参数。该compute_metrics函数对模型的测试预测作为 logits(这是模型的默认输出)和测试标签进行操作。要实例化这个函数,我们建议datasets通过安装 Hugging Face 的库pip install datasets并使用它,如下所示:
>>> from datasets import load_metric
>>> import numpy as np
>>> metric = load_metric("accuracy")
>>> def compute_metrics(eval_pred):
... logits, labels = eval_pred
... # note: logits are a numpy array, not a pytorch tensor
... predictions = np.argmax(logits, axis=-1)
... return metric.compute(
... predictions=predictions, references=labels)更新后的Trainer实例化(现在包括compute_metrics)如下:
>>> trainer=Trainer(
... model=model,
... args=training_args,
... train_dataset=train_dataset,
... eval_dataset=test_dataset,
... compute_metrics=compute_metrics,
... optimizers=(optim, None) # optim and learning rate scheduler
... )现在,让我们训练模型(再次注意,代码不是完全确定的,这就是为什么您可能会得到略有不同的结果):
>>> start_time = time.time()
>>> trainer.train()
***** Running training *****Num examples = 35000Num Epochs = 3Instantaneous batch size per device = 16Total train batch size (w. parallel, distributed & accumulation) = 16Gradient Accumulation steps = 1Total optimization steps = 6564
Step Training Loss
10 0.705800
20 0.684100
30 0.681500
40 0.591600
50 0.328600
60 0.478300
...
>>> print(f'Total Training Time: '
... f'{(time.time() - start_time)/60:.2f} min')
Total Training Time: 45.36 min训练完成后(根据您的 GPU 可能需要长达一个小时),我们可以调用trainer.evaluate()以获取测试集上的模型性能:
>>> print(trainer.evaluate())
***** Running Evaluation *****
Num examples = 10000
Batch size = 16
100%|█████████████████████████████████████████| 625/625 [10:59<00:00, 1.06s/it]
{'eval_loss': 0.30534815788269043,'eval_accuracy': 0.9327,'eval_runtime': 87.1161,'eval_samples_per_second': 114.789,'eval_steps_per_second': 7.174,'epoch': 3.0}我们可以看,评估准确率约为 94%,类似于我们自己之前使用的 PyTorch 训练循环。(请注意,我们跳过了训练步骤,因为在model上一次调用之后已经对其进行了微调trainer.train()。)我们的手动训练方法和使用类之间存在小的差异Trainer,因为Trainer类使用了一些不同的设置和一些额外的设置。
我们可以用来计算最终测试集准确度的第二种方法是重用compute_accuracy我们在上一节中定义的函数。我们可以通过运行以下代码直接评估微调模型在测试数据集上的性能:
>>> model.eval()
>>> model.to(DEVICE)
>>> print(f'Test accuracy: {compute_accuracy(model, test_loader, DEVICE):.2f}%')
Test accuracy: 93.27%事实上,如果你想在训练过程中定期检查模型的性能,你可以通过定义训练参数来要求训练器在每个 epoch 之后打印模型评估,如下所示:
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments("test_trainer",
... evaluation_strategy="epoch", ...)但是,如果您计划更改或优化超参数并多次重复微调过程,我们建议为此目的使用验证集,以保持测试集的独立性。我们可以通过实例化Trainerusing来实现这一点valid_dataset:
>>> trainer=Trainer(
... model=model,
... args=training_args,
... train_dataset=train_dataset,
... eval_dataset=valid_dataset,
... compute_metrics=compute_metrics,
... )在本节中,我们看到了我们如何微调 BERT 模型进行分类。这与使用其他深度学习架构(如 RNN)不同,我们通常从头开始训练。然而,除非我们正在进行研究并试图开发新的变压器架构——这是一项非常昂贵的工作——没有必要对变压器模型进行预训练。由于 Transformer 模型是在一般的、未标记的数据集资源上进行训练的,因此我们自己对它们进行预训练可能不会很好地利用我们的时间和资源;微调是要走的路。
概括
在本章中,我们介绍了一种全新的自然语言处理模型架构,即转换器架构。Transformer 架构建立在一个叫做 self-attention 的概念上,我们开始逐步介绍这个概念。首先,我们研究了一个配备注意力的 RNN,以提高其对长句的翻译能力。然后,我们轻轻介绍了 self-attention 的概念,并解释了它是如何在 Transformer 内的 multi-head attention 模块中使用的。
自 2017 年最初的 Transformer 发布以来,Transformer 架构的许多不同衍生产品已经出现和发展。在本章中,我们重点选择了一些最受欢迎的产品:GPT 模型系列、BERT 和 BART。GPT 是一种单向模型,特别擅长生成新文本。BERT 采用双向方法,更适合其他类型的任务,例如分类。最后,BART 结合了 BERT 的双向编码器和 GPT 的单向解码器。感兴趣的读者可以通过以下两篇调查文章了解其他基于变压器的架构:
- 自然语言处理的预训练模型:邱及其同事的一项调查,2020 年。可在https://arxiv.org/abs/2003.08271
- AMMUS:Kayan及其同事对自然语言处理中基于 Transformer 的预训练模型的调查,2021 年。可在https://arxiv.org/abs/2108.05542
Transformer 模型通常比 RNN 更需要数据,并且需要大量数据进行预训练。预训练利用大量未标记的数据来构建通用语言模型,然后可以通过在较小的标记数据集上对其进行微调来专门针对特定任务。
为了了解这在实践中是如何工作的,我们从 Hugging Facetransformers库中下载了一个预训练的 BERT 模型,并对其进行了微调,以便在 IMDb 电影评论数据集上进行情感分类。
在下一章中,我们将讨论生成对抗网络。顾名思义,生成对抗网络是可用于生成新数据的模型,类似于我们在本章中讨论的 GPT 模型。然而,我们现在将自然语言建模这个话题抛在脑后,将在计算机视觉和生成新图像的背景下研究生成对抗网络,这些网络最初是为这项任务而设计的。