代谢组是对生物体内代谢产物全谱分析的一种研究手段,代谢产物包括核酸、蛋白质、脂类生物大分子以及其他小分子物质,目前主要是检测1000Da以下的物质。代谢组研究具有高通量的检测能力、高灵敏度和准确度、非侵入性、非破坏性、全面性、数据资源整合等特点。通过LC-MS/GC-MS评估生物体或细胞产生的代谢产物的水平以及变化,可以进一步研究这些代谢产物与转录组学差异基因或微生物的关系。在这个系统生物学和功能基因组时代,将多个组学联合运用、从整体上解释生物学问题才是大势所趋。所以代谢组学一般会和基因组、转录组等联合分析,深入解释功能基因、表达调控等问题。


言归正传,一起来看看常见的问题与解答吧!
问题1. 非靶、靶向、类靶向代谢组傻傻分不清楚?
非靶代谢:类似于转录组,蛋白质组,筛选不同组之间的差异代谢物,扫描模式是全扫描(full scan),属于盲筛,得到物质的相对定量结果。后续要进行一系列生信分析。
凌恩生物非靶向代谢项目,采用mzCloud搭配mzVault数据库和Masslist数据库进行搜库注释。数据库具体信息如下:
mzCloud数据库:该数据库是Thermo公司基于标品在Orbitrap质谱仪上构建的包含一级及儿既高分辨率精确质量(HRAM)谱图数据的数据库,是在线实时更新数据库。基于现有版本(截至2020年4月7日),mzCloud 在线数据库有17802 种化合物,6,536,790张二级图谱。分为16大类物质,其中内源性代谢物有3000+种。内源性代谢物又可细分为氨基酸及其衍生物、核苷酸及其衍生物、糖代谢途径中的各种代谢物、生物碱、黄酮类、萜类、酚胺类、激素及其衍生物、脂肪酸等。
mzVault数据库:该数据库是含二级谱图的本地数据库,包含Thermo公司提供的谱图和公司从其他公共数据库中搜集到的与Orbitrap质谱仪匹配的谱图,其中包括普通代谢物质近 2000 种,脂质类物种近10万种。
mzCloud和mzVault 都是含有二级谱图的数据库,通过子离子、母离子同时匹配, 代谢物鉴定准确性最高。
Masslist数据库:该数据库是公司积累的包含内源性物质信息的一级谱图本地数据库, 基于一级库鉴定到的物质可以作为参考。
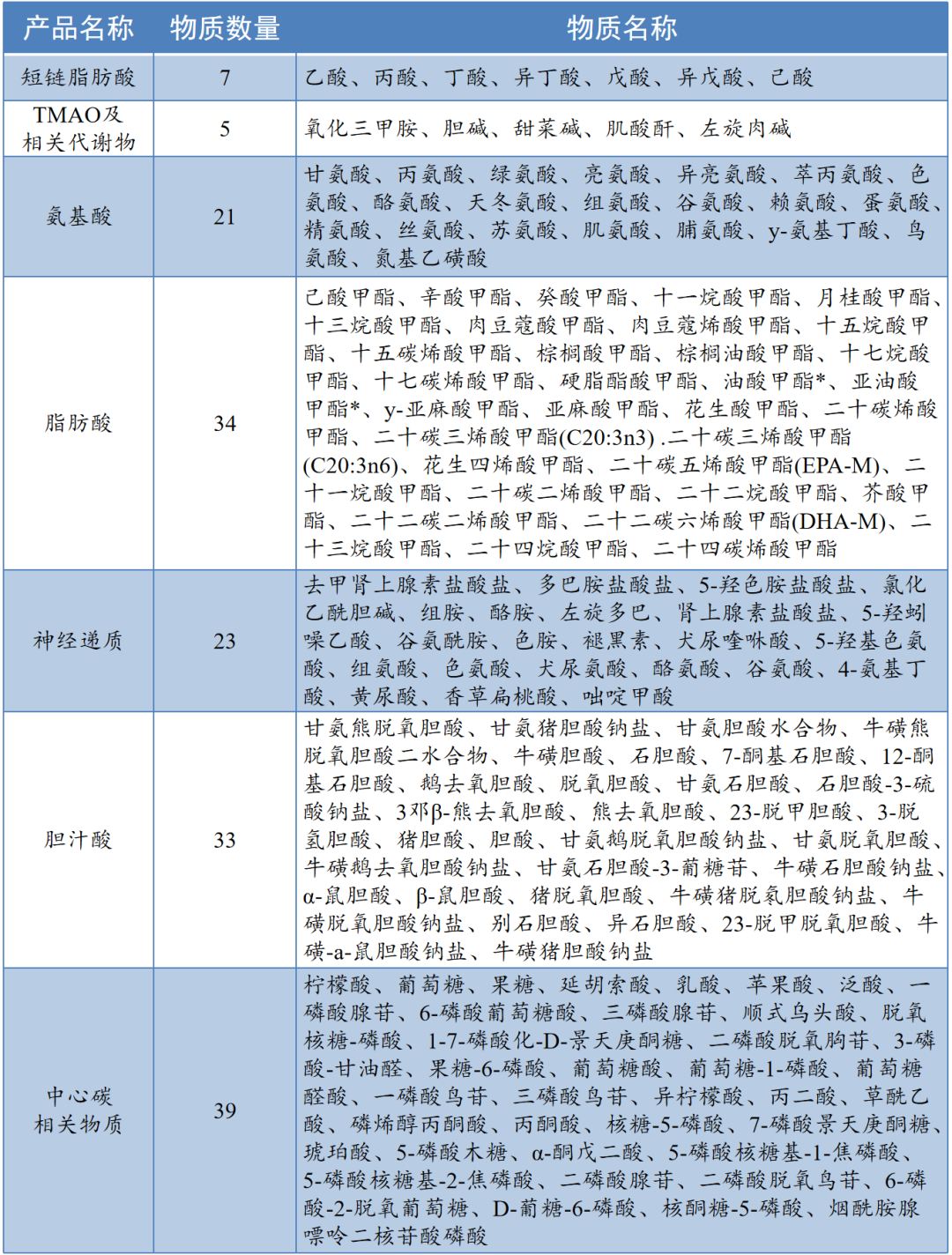
靶向代谢:客户已经明确要检测的物质,首先用这些物种的标准品,配置不同浓度的溶液,上机,绘制出标准曲线,建立检测该类物质的方法,验证方法的专属性、基质效应、精密度、准确度、稳定性等方面,属于绝对定量。
凌恩生物部分靶向代谢检测物质,如下:
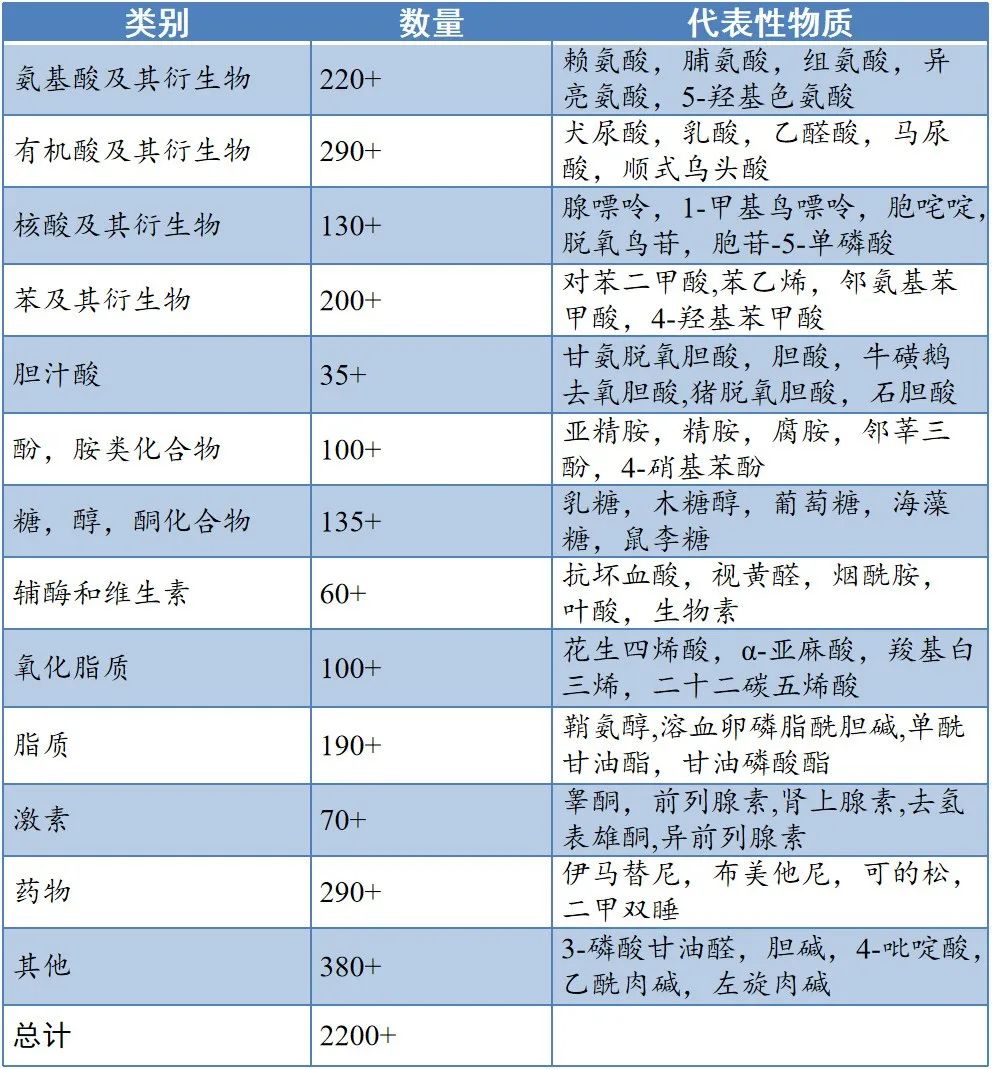
类靶向代谢:核心在于类靶向代谢数据库,根据客户不同的样本类型分为植物类靶向数据库和人&动物类靶向数据库两种,植物库中包含 3250+的代谢物,人&动物数据库中包含 2200+的代谢物;按照 sMRM(Schedule Multiple Reaction Monitoring)的采集模式对样本中所含代谢物进行采集,可检测的物质是我们数据库中包含的代谢物,所以老师有关注的物质的时候需要做好售前咨询工作,避免出现关注的物质不在数据库中而导致检测不到的情况,也是相对定量。后续要进行一系列生信分析。
植物-类靶向数据库V2.0:

人&动物-类靶向数据库V2.0:
问题2.非靶向代谢和类靶向代谢是否能给出代谢物的有无的结果?
不能提供真正意义上的代谢物的有无。
类靶向和非靶代谢都要进行缺失值填充,即使是缺失值填充前的数据,鉴定到的这些物质也是基于仪器筛选出来的有无,而不是真正的有无,没有鉴定到的原因可能是样本中没有这个物质,也可能是含量很低而被软件过滤掉了。
问题3.正负离子模式是指什么?
代谢物的性质不同,离子化后,有的容易带正电荷,有的容易带负电荷。为了能检测到更多的代谢物,所以一般分为正负离子两个模式分别去检测。有些物质属于两性物质,在正负模式下都会被检测出。
问题4.代谢组生物学重复数如何设置?
植物类靶向代谢生物学重复数≥6,根据目前做过的类靶向项目来看,生物学数目小于 6 的项目,鉴定结果和组内的相关性不是很好,这会影响 P 值的计算进而影响差异代谢物的筛选,而且有离群点也不能剔除,所以推荐生物学重复数要大于 6,建议 6个及以上。
问题5.非靶向代谢组中,关注某个物质,但检测结果中却没有,是什么原因,如何改进?
1、非靶向代谢物提取方法需要尽可能多的提取到大多数代谢,对于特定代谢物来说,该方法并非最优的提取方法;
2、非靶向代谢扫描模式是 DDA(数据依赖性),在特定物质出峰处有其它物质干扰,因此未采集到该物质的谱图信息;
3、搜库过程,由于低于设置的阈值(质量偏差:5ppm、信号强度:100000、信噪比而被过滤掉。
因为目前任何一种技术平台都无法检测到全部的代谢物质,非靶向代谢灵敏度相对较低,
综上,如有明确的目标代谢物,建议直接选择靶向代谢产品并优化提取方法。
问题6.代谢物提取通常采用什么方法?
色谱相分离通常取决于含有甲醇、水和氯仿的萃取溶液,具有高溶解度的代谢物,例如碳水化合物通常在甲醇、水中提取;而具有低溶解度的代谢物,例如膜脂和脂肪酸通常在氯仿、水中提取。
问题7.如果想检测的物质不在靶向检测列表中怎么办?
由于代谢物有数万种,并非所有物质都被检测过。另外,现有公共数据库或商业数据库中也不一定包含该物质的一级或者二级质谱图。因此,可以按照定制化产品进行评估,提供待检测的物质,并查找相应检测方法的文献,以此评估定制靶向产品的可行性。
但靶向产品的开发需要购买标准品,建立检测物质的方法学,再进行样本的检测,因此周期较长,成本也较高。
问题8.代谢物种类繁多,为何只能鉴定到几百到上千个物质?
由于代谢物分子量小,结构复杂,只通过分子量和电荷数(一级质谱)鉴定不是很准确,因此更依赖标准品二级谱图数据库,但很多公共数据库(HMDB、Metlin等)中约有90%的已知代谢物都没有标准的二级谱图。即使有二级信息,由于代谢物的离子谱图可能由不同实验室的不同质谱仪器打出,仪器的种类、参数设置不同,都可能导致同一个代谢物产生的谱图存在偏差。因此代谢物虽然种类多数量多,但是鉴定到的物质相对较少。
问题9.在检测两种物质的丰度水平时,代谢组学获得的两种物质丰度比值关系和其他技术的检测结果明显相反,这是什么原因?
不同物质结构、携带的基团不同,质谱检测过程中,物质的离子化效率、对仪器信号的响应等方面可能存在较大差异,结果就呈现出不同物质的质谱检测效率不一致。因此,代谢组数据仅适用于不同组别间同一物质的比较,不适用于同一样本内部比较不同物质的差异。
问题10.代谢组学与其他组学相比,有什么优势?
基因和蛋白质表达的微小变化会在代谢物水平得到放大;代谢组学的研究不需进行全基因组测序及建立大量表达序列标签的数据库;
代谢物种类远少于基因和蛋白的数目,每个生物体中代谢产物大约在103数量级,而最小的细菌,其基因组中也有几千个基因,因此,通过代谢组可以更好的定位关键代谢物,开展生物体生理生化机制研究;
生物体液的代谢物分析可反映机体系统的生理和病理状态。