本设计源码、数据和设计已经开源,点击链接下载,喜欢的话就点赞加收藏吧!
下载链接:https://pan.baidu.com/s/1ys2F6ZH4EgnFdVP2mkTcsA?pwd=LCFZ
提取码:LCFZ
研究基础
心脏病是一类比较常见的循环系统疾病。循环系统由心脏、血管和调节血液循环的神经体液组织构成,循环系统疾病也称为心血管病,包括上述所有组织器官的疾病,在内科疾病中属于常见病,其中以心脏病最为多见,能显著地影响患者的劳动力。典型症状:蹲踞体征、杵状指(趾)、肺动脉高压、年长儿可有生长发育迟缓。患儿面色苍白,憋气,呼吸困难和心动过速,在鼻尖、口唇、指(趾)甲床明显紫绀。患儿往往发育不正常,表现为瘦弱、营养不良、发育迟缓等。部分有胸痛、晕厥。部分排汗量异常。
基本分类
心脏病是一种统称,其实心脏病是分了很多的的种类的,可以根据发病部位分类也可以根据发病原因分类。在临床上一般将心脏病分为4种。不同种类的心脏疾病会出现不同的症状,平时掌握不同心脏病的征兆,可以及时的预防,心脏病发作时才能尽快的急救。
现在我们国家有很多的风湿患者,而长期的风湿又会导致慢性风湿性心脏病,这是心脏病中很常见的一种。当风湿疾病患者体内的热症蔓延到心脏的时候就容易引发心脏病的发生。
第二种常见的心脏病类型是先天性心脏,这一类人是生下来的时候就有心脏病,主要是在胚胎发育的时候染色体发生异常。
第三种心脏病类型是冠心病,这也是心脏病患者中最多的一种类型。冠心病患者常常都有抽烟的习惯,吸烟又及其容易引发心脏疾病。另外糖尿病、高血压等疾病会使我们血流受阻,易使心肌缺氧而受损,也容易导致心脏病。现在很多年轻人有冠心病,主要是因为劳累过度还有长期处于精神紧张。
第四种类型就是高血压心脏病,高血压患者的血压太高会导致心室肥大,心室长期处于超负荷状态,心肌就会坏死造成心脏病。有的高血压患者冠状动脉血管发生病变,最终导致心律紊乱,甚至出现心绞痛、心肌梗死,严重的威胁着患者的生命。
研究现状
近日,中国医学科学院阜外医院高润霖院士、王增武教授等发表研究称,我国瓣膜性心脏病加权患病率为3.8%,估计我国有2500万瓣膜病患者。研究发现,风湿性心脏病仍是瓣膜病的主要原因,但退行性瓣膜病的患病率明显增加。研究者表示,由于人口老龄化,瓣膜病负担巨大,风湿性心脏病和退行性瓣膜病目前是中国老年人健康的主要威胁。
伯明翰大学的计算机和心血管专家与英国,荷兰和澳大利亚的同行合作开发了ElectroMap--一种用于处理,分析和绘制复杂心脏数据的新型开源软件。相关结果发表在最近的《Scientific Reports》杂志上。伯明翰大学计算机科学高级讲师兼项目总监Kashif Rajpoot博士评论说:“这是一个经过有效验证的开源灵活工具,用于处理和使用我们开发的新型数据分析策略,该软件将提供对心脏病的更深入了解,特别是支持潜在致命性心律失常的机制”。
研究意义
心脏疾病是一类比较常见的循环系统疾病,可导致心悸、心绞痛、心力衰竭、心律失常等临床症状,是引起死亡的主要原因。尽管溶栓等药物治疗、支架的植入和心脏移植等方面取得了很大的进展,但前两种方法并不能有效治疗所有心脏疾病或改善预后,而心脏移植还会有排斥反应的风险。尽管现代医学的发展和医疗设备的开发能有效延缓疾病的进展,但是心脏疾病的患病率仍然呈逐年增加的趋势。目前,研究发现能够对心脏病数据进行分析,建立联防预警机制,在心脏病前期筛查和预警方面前景广阔。
相关技术
1.线性回归
线性回归模型属于经典的统计学模型,该模型的应用场景是根据已知的变量(即自变量)来预测某个连续的数值变量(即因变量)。例如餐厅根据媒体的营业数据(包括菜谱价格、就餐人数、预订人数、特价菜折扣等)预测就餐规模或营业额;网站根据访问的历史数据(包括新用户的注册量、老用户的活跃度、网站内容的更新频率等)预测用户的支付转化率;医院根据患者的病历数据(如体检指标、药物复用情况、平时的饮食习惯等)预测某种疾病发生的概率。
2.随机森林
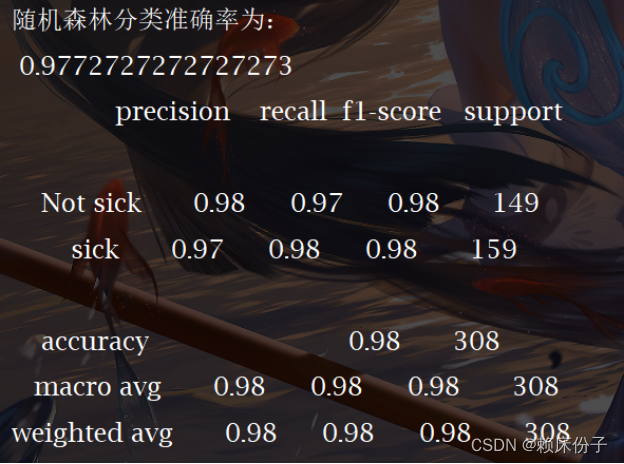
作为高度灵活的一种机器学习算法,随机森林(Random Forest,简称RF)拥有广泛的应用前景,从市场营销到医疗保健保险,既可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预测疾病的风险和病患者的易感性。最近几年的国内外大赛,包括2013年百度校园电影推荐系统大赛、2014年阿里巴巴天池大数据竞赛以及Kaggle数据科学竞赛,参赛者对随机森林的使用占有相当高的比例。所以可以看出,Random Forest在准确率方面还是相当有优势的。
如果接触过决策树(Decision Tree)的话,那么会很容易理解什么是随机森林。随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,这样的比喻还是很贴切的,其实这也是随机森林的主要思想--集成思想的体现。
其实从直观角度来解释,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。
3.数据热力图
热力图,是一种通过对色块着色来显示数据的统计图表。绘图时,需指定颜色映射的规则。例如,较大的值由较深的颜色表示,较小的值由较浅的颜色表示;较大的值由偏暖的颜色表示,较小的值由较冷的颜色表示等。从数据结构来划分,热力图一般分为两种。
第一,表格型热力图,也称色块图。它需要2个分类字段+1个数值字段,分类字段确定x、y轴,将图表划分为规整的矩形块。数值字段决定了矩形块的颜色。
第二,非表格型热力图,或平滑的热力图,它需要3个数值字段,可绘制在平行坐标系中(2个数值字段分别确定x、y轴,1个数值字段确定着色)。
热力图适合用于查看总体的情况、发现异常值、显示多个变量之间的差异,以及检测它们之间是否存在任何相关性。值得注意的是,绘制热力图时,建议选择恰当的调色板,既在视觉上便于区分,也符合所要传达的主旨。
适用场景
1.热力图的优势在于“空间利用率高”,可以容纳较为庞大的数据。热力图不仅有助于发现数据间的关系、找出极值,也常用于刻画数据的整体样貌,方便在数据集之间进行比较(例如将每个运动员的历年成绩都浓缩成一张热力图,再进行比较)。
2.如果将某行或某列设置为时间变量,热力图也可用于展示数据随时间的变化。例如,用热力图来反映一个城市一年中的温度变化,气候的冷暖走向,一目了然。
数据属性说明
age: 年龄
sex: 性别 (1 = 男性,0 = 女性)
cp: 经历过的胸痛类型(值1:典型心绞痛,值2:非典型性心绞痛,值3:非心绞痛,值4:无症状)
trestbps: 静息血压(入院时的毫米汞柱)
chol: 该朋友的胆固醇测量值,单位 :mg/dl
fbs: 人的空腹血糖(> 120 mg/dl,1=真;0=假)
restecg: 静息心电图测量(0=正常,1=患有ST-T波异常,2=根据Estes的标准显示可能或确定的左心室肥大)
thalach: 最大心率
exang: 运动引起的心绞痛(1=有过;0=没有)
oldpeak: ST抑制,由运动引起的相对于休息引起的(“ ST”与ECG图上的位置有关。)
slope: 最高运动ST段的斜率(值1:上坡,值2:平坦,值3:下坡)
ca: 萤光显色的主要血管数目(0-4)
thal: 一种称为地中海贫血的血液疾病(3=正常;6=固定缺陷;7=可逆缺陷)
target: 心脏病(0=否,1=是)
数据分析
首先引入函数依赖

导入数据
由于数据存放在.CSV文件中,所以需要通过pandas的rend_csv()方式进行导入,但是由于数据中不包含标签信息,需要新建name函数用以存放标签并于存放数据函数data进行映射。

检查数据的基本结构和分布情况

为保证系统分析的准确性和模型建立的一致性,需要对数据进行检查,检查数据内的NAN值,若存在NAN值在不影响整体系统的情况下可以进行删除或进行均值填充。

本次使用的数据已经提前进行过清洗,所以数据并不存在空值情况,可以进行下一步的处理。这里还使用了print(data.describe())方法进行统计描述,查看各数据列的最大值、均值、所占比例等信息。


年龄分析
作为心脏病指标中较为重要的因素,大多数人会随着时间的流逝,身体的基本功能开始下降,由此会引发各类亚健康体征,间接促使心脏病的形成。

在此实验中,age标签下的数据的平均数为约为54岁,中位数为56岁,众数为58岁,反应了实验数据的来源多为中老年人,作为心脏病的高发群体,应给予足够的重视。

胆固醇分析
长期的高胆固醇的身体情况会致使心脏负担加重,由此导致的血栓会进一步加剧心脏病的出现,为此如何将胆固醇维持在合理的区间内对中老年人群是十分必要的。为此实验以胆固醇200作为基准线,高于200则归类为胆固醇异常人群,低于200则归类为正常人群,通过与年龄列age进行相互映射输出分类直方图



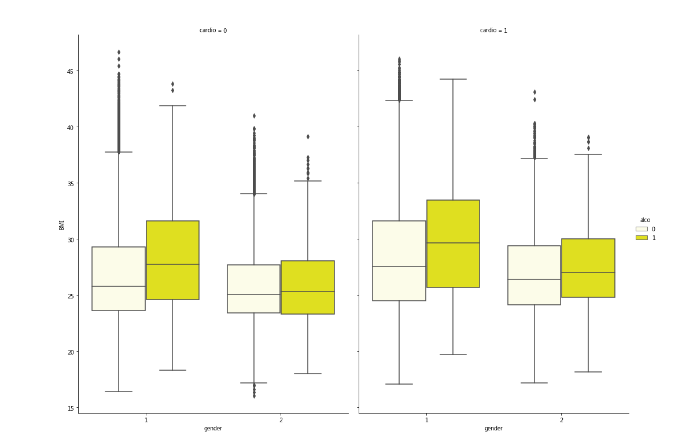
在这里可以看出不正常胆固醇人群多集中与60岁左右,正常人群的分布在40岁区间内较为集中,但是在50-60的区间范围内出现了峰值,但是在60-70岁区间出现了谷值,表明在经过了60岁后胆固醇会出现较大波动,需要注意饮食和合理调整作息规律。
通过进一步分类发现,胆固醇随年龄的波动规律如下:年龄越小,胆固醇含量较低,反之胆固醇升高。


求解极差
极差:称为全距,极大值减去极小值所得;主要用于衡量能否代表一组数据
四分位差:上四分位数-下四分位数所得;反映了中间50%数据的离散程度,数值越小说明中间的数据越集中。
极差与四分位差都用来判断数据的离散程度。


数据中采集的是已经患有心脏病的患者数据,数据中最大值为564,最小值为126,极差为438,四分位差为57.75,由此可得心脏病患者的胆固醇大部分都不正常。数据箱线图如下:
正态分布计算
判断一个数据是否符合正态分布,这里用SW检验,SW检验中的S就是偏度,W就是峰度。这里需要先将数据转为Series类数据,随后直接用pd进行偏度计算,最后用相关系数或卡方计算12个属性和得心脏病的相关性,分析哪些因素对确诊心脏病作用大。通过对数据进行相关性矩阵计算,形成可视化图表。



由实验结果可以看出oldpeak,cp,exang,slope指标对确诊心脏病作用较大。
线性回归
回归分析是研究自变量与因变量之间数量变化关系的一种分析方法,它主要是通过因变量Y与影响它的自变量Xi(i1,2,3…)之间的回归模型,衡量自变量Xi对因变量Y的影响能力的,进而可以用来预测因变量Y的发展趋势。
1、根据预测目标,确定自变量和因变量;
2、绘制散点图,确定回归模型类型;
3、估计模型参数,建立回归模型;
4、对回归模型进行检验;
5、利用回归模型进行预测。


随机森林
对于随机森林来进行回归任务,可以分两个部分来实现。第一部分我们先实现回归决策树,第二部分在回归决策树的基础上实现回归随机森林。回归森林使用N棵回归决策树, 这里有两点需要注意:
1.样本的随机性。对于每棵树输入的数据需要是不同的,如果对N棵树输入同样的数据,那得出的结果都是一样的,随机森林也就没有了意义。所以,对于每一棵树,使用的数据是训练集通过随机有放回的采样得到的。
2.属性的随机性。寻找最优划分属性时,先随机选出一部分,再在这一部分中选取增益最大属性的。

心脏病的预防与保养
对于心脏病的预防与保养要在生活中注意如下几点:
1、要定期监测血压、血糖以及到医院抽血化验血脂,以保证处于正常血压、血糖、血脂的范围之内,因为高血压、高血糖、高血脂等三高人群极容易得心脏病尤其是冠心病。
2、除此之外,患者应该注意戒烟和限酒,逢年过节可以少量饮酒,但是也不能暴饮暴食以及酗酒,烟对身体有百害而无一利,因此烟一定要戒掉,酒只能适当的喝一点。
3、要注意清淡饮食,低盐低脂饮食,少吃肥腻,少吃红肉,多吃绿色蔬菜以及优质蛋白比如鱼肉、虾肉等。
4、应该注意保持良好的体型以及合适和合理的健身计划,比如每周运动2-3次,每次30分钟左右。
5、要保持非常愉悦的心情,即使生活压力、工作压力很大也要经常放松心情,注意劳逸结合,因为情绪紧张、过于焦虑都是冠心病的高危因素。



![[QMT]05-获取基础行情信息](https://img-blog.csdnimg.cn/img_convert/70358ad12f64f7448d5c49797db12755.png)