搜索是电商平台的核心流量入口,承载着平台主要的成交引导、意图收敛、活动投放。一个稳定、高效、可扩展的搜索系统是电商平台得以生存发展的基石。本文探讨如何构建完善的商品搜索系统, 并根据闲鱼二手交易的差异化特性介绍闲鱼搜索系统的时效性优化。
首先,构建一个搜索系统:电商场景的搜索
搜索引擎
搜索系统的核心是搜索引擎,目前Lucene、ElasticSearch等开源引擎已十分成熟,阿里云也提供完整的搜索解决方案-OpenSearch,包含基于Ha3的搜索引擎(Heaven ask 3)及系列管控工具。这里,我们简单描述下搜索引擎内的基本概念作为导引,不过多深入引擎的具体实现(那将是一个冗长的话题,网络上的资料也随处可见)。
搜索引擎的基本概念
• 分词 通过一定规则对文本分出单词,每个单词作为搜索的最小粒度单元。只有单词匹配,文档才能被召回,因此分词的准确是搜索精准的基础。如“红色摩托车” 被分词成“红色”, “摩托车”, 那它将被“摩托车”或者“红色”召回, 如果分词成“红色摩托”, “车”,那它在引擎中被搜索出的概率就将大打折扣。
• 索引
• _ 红色苹果手机, doc1_
• _ 红色苹果, doc2_
• “红色”,“苹果” -> doc1, doc2
• _“手机” -> doc1 _
• 倒排索引 称为反向索引、置入档案或反向档案,是一种索引方法。被用来存储在全文搜索下某单词在文档存储位置的映射。它是文档检索系统中最常用的数据结构。
• 正排索引 也叫attribute索引或者profile索引,是存储doc某特定字段(正排字段)对应值的索引,用来进行过滤、统计、排序或者算分使用。正排索引中“正"指的是从doc-> fieldInfo的过程。
• 索引内容类型 文本索引、空间索引 、向量索引、数值索引
• 排序方法 匹配召回的结果集,通过特定的排序规则呈现。这里的排序规则,可以是单一维度的排序(如按价格、销量、发布时间);人工设置的权重分;相关性得分;特定场景的模型打分等。
基于这三个基本概念,搜索动作就可以简化地理解为“利用搜索词的分词结果,通过倒排索引匹配相应的文档,并依据特定排序方法有序透出”的过程。
搜索引擎仅提供搜索的基础能力,现实环境下的搜索场景当然要复杂的多, 一款地图搜索和一款商品搜索所面临的挑战大相径庭。作为原材料的搜索引擎,该打造成何种形状,就看面对问题如何去设计模具了。
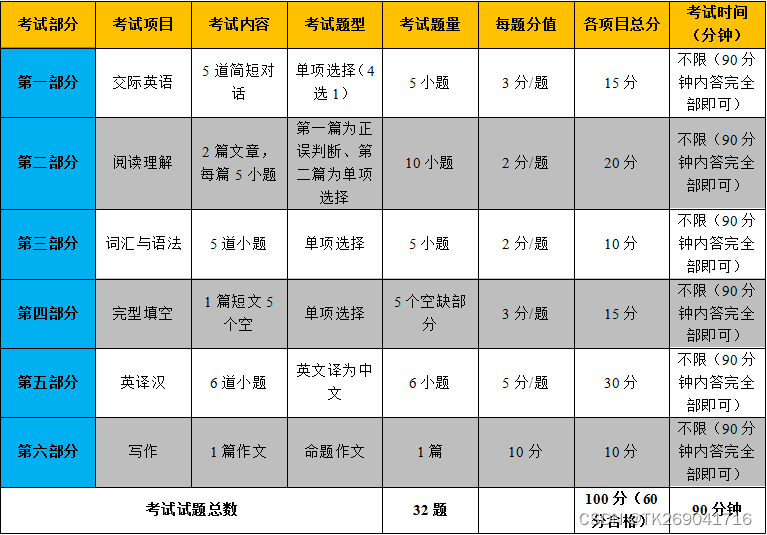
以闲鱼为例, 搜索系统的整体架构如下:

在线服务
上述架构图中的步骤1 ~ 8为一次搜索请求的完整执行流程
1)请求接入模块 -> 应用层
处理客户端或h5请求,请求接入模块的主要工作:参数校验、负载均衡、安全拦截。大部分的非法请求在这一层被拦截,避免进入系统核心模块后,导致不可预期的结果。应用层承载面向用户的业务逻辑:实际处理用户的业务请求,进行安全合规检测,同时并行请求投放的各类资源位。
2)应用层 -> 排序接入层
排序接入层是连接应用层与底层引擎的纽带,也是闲鱼搜索系统的最核心模块。他负责解析应用层的搜索请求,并对其进行合适流程编排:意图预测->请求拼串->搜索引擎召回->精排模型打分->重排规则->外部混排。
3)排序接入层 -> 意图预测模块
负责分词并预测搜索请求的实际意图,包括错词改写(例:平果->苹果)、同义词的合并(例:pingguo->苹果),类目预测(例:“苹果”出手机,还是出水果,它们各自的权重又是多少?)。
4)排序接入层 -> 搜索引擎
利用意图预测得到的信息,合并应用层参数,拼装出合法的搜索引擎请求,在搜索引擎内部历经“海选”、“粗排” 、"精排" 三个阶段,得到符合召回条件的商品集。
5)排序接入层 -> 精排模型打分
由于RT的限制,搜索引擎内部无法完成对海量商品复杂度较高的打分计算。这一步的工作,将引擎召回的商品集送入更精准的打分系统进行算分。为什么不把打分服务放在引擎内部?技术上是可行的,但由于打分服务变更频率频繁,而引擎相对稳定,处于系统迭代稳定性的考虑,独立拆分精排打分服务是更好的选择。
6)排序接入层 -> 混排模块
部分业务场景下,合作方有合并混排的诉求。独立拆分混排服务,隔离开发环境,让不熟悉主搜的外部开发同学在独立混排模块内做开发,即使服务异常,也不至于影响闲鱼本身的搜索能力。
7)排序接入层 -> 应用层
排序完成的商品列表,在应用层补充实时信息,如各类标签,促销信息等。同时,将商品搜索结果与广告等各类投放组装层最终的搜索结果页。
8) 应用层 -> 接入层 -> 客户端
将最终的搜索结果页返回到客户端或h5页面进行渲染。
离线模块
与在线服务对应, 搜索系统的离线模块负责数据的dump,清洗,索引构建。
搜索引擎离线模块

全量索引(Fullindex) :数据源来自多表join后的全量业务数据,包含所有商品信息,由buildSerive构建好索引后提供给Ha3使用,系统内仅有一份全量索引。
批次增量索引 (IncIndex) :根据周期内(通常30分钟到1小时)数据产出方发送的增量消息(如:商品修改信息),在BuildService上构建成索引段,定期发送给Ha3加载,引擎存在多段批次增量。
实时索引(RtIndex): 将数据产出方实时生产的数据经中转Topic发送至Ha3,由Ha3引擎内的BS lib构建出实时索引加载使用,时效性为实时。在新的批次增量索引加载后,Ha3对实时索引作清理。
稳定性
搜索承载闲鱼导购线的核心流量,因此对系统的稳定性和业务的高可用有极高的要求。闲鱼搜索系统,分别在中心机房(张北)和单元机房(南通)进行了异地多机房部署,确保当单一机房故障时,流量可转发至正常机房服务。
应用层异地多活

引擎层异地多活

外围系统
核心链路以外,搜索业务的高效运作也离不开一系列外围系统。
投放系统 —— 资源位与配置的投放


评测系统 —— 算法标注、效果评测

Debug平台 —— 可视化的在线debug工具,负责线上请求回放、舆情排查等

然后,优化它:闲鱼搜索系统时效性优化
差异化场景
上一章节提到的搜索系统架构适用于大部分电商平台,但闲鱼搜索场景与常规电商平台之间,又存在着显著差异。
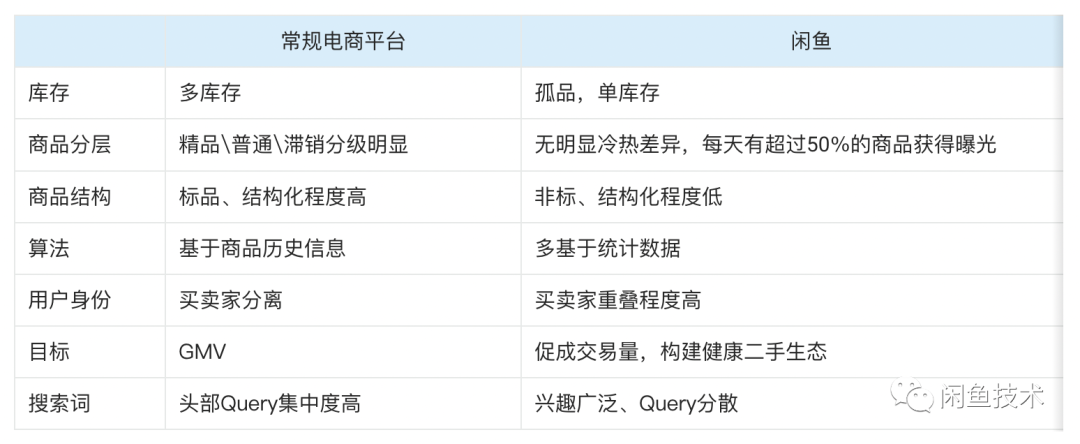
其中,闲鱼商品单库存,无明显冷热差异且变更频繁的特性, 对全链路的实时处理能力都提出较高的要求。试想一下,热门的商品被买下架后,并没有及时同步引擎。对买家、卖家和平台来说都是一种困扰与损失。

闲鱼搜索经年累月的业务迭代,累积了相当量级的实时增量。最严重的时期,引擎的增量延时一度达到8小时之久,对用户体验、成交效率形成了巨大冲击。因此过去的一段时间,我们开启了搜索时效优化的专项。

Searcher扩列
排查链路实时处理能力的瓶颈,如上文离线模块中对实时增量的描述(数据产出方实时生产的数据经中转Topic实时发送至Ha3,由Ha3引擎内的BS_lib构建出实时索引加载使用), 在实时增量到达索引所在searcher列之前都未出现延时,因此瓶颈位于在线searcher的BS_lib的消费能力, 最直接的方式是提升searcher的处理能力。因此,我们将searcher的列数从16列扩大至24列,提升了50%的实时增量处理能力,增量延时缓解。
引擎架构治理
我们重新思考了闲鱼主搜引擎的架构与定位 。在之前的架构中,倒排、正排、详情字段部署在同个引擎(Ha3引擎支持这种能力)。倒排、正排用作查询索引,详情字段补充商品详细信息,并对外提供信息补全服务。但查询的请求量是极其不对等的, 详情字段的qps为索引字段的5.3倍。倒排与正排字段的数量远大于详情字段, 因此查询请求的机器要求是小CPU, 大内存,详情请求的机器则是大CPU,小内存。两类字段部署在同一引擎, 各自的资源短板被放大。同时,各字段实时增量是累加的。因此,我们拆分了查询引擎 与 详情引擎,缓解增量压力的同时,机器资源消耗也有所降低。

增量分级
做了以上两个优化后, 增量延迟有所缓解,但整体的增量量级并没有下降多少。因此在离线链路中,我们开发了增量Profile插件,用来统计字段修改的频率。


其中两个字段合计占到修改量的37%(总400+字段), 经排查,两个字段并不需要秒级的实时性。引擎的离线链路中,虽然设定了批次增量与实时增量,但事实上所有开启的增量都会走实时增量通道,挤占优先级更高的增量的吞吐量。因此,进入引擎的增量务必根据业务诉求再做一次分级。由此,我们在buildService上开发了增量分级插件,提供增量分级处理的能力, 对于准实时性要求的增量仅做批次增量(1小时进引擎),不挤占核心实时增量的通道,保障商品核心特征的实时性。

辅表写扩散问题
优化增量量级的另一个重要关注点就是辅表写扩散问题。商品以item_id为主键分列部署,离线阶段,当辅表有驱动增量时,跟主表join后增量翻倍增长。例:商品上挂载用户在线状态的特征,当用户状态变化时,该用户的所有商品都会发出实时增量消息。量级将远大于用户在线状态的实际消息量级。解决方式是将这一类字段,单独改造成在线辅表, 通过在线join的方式查询。

经过以上系列的优化后,我们最终把引擎延迟抹平,达到真正实时化搜索的定义( 基本无延迟, 红框部分为全量后追增量阶段, 采用逐行Rolling模式, 切换中机器不服务,对用户体验无感知)。

最后
电商平台的搜索是一项系统性工程, 经过多年发展,已沉淀出一套通用性的框架。里面不仅包含对搜索引擎的理解,也体现服务端架构设计的可伸缩、平行扩展等概念。但仅有框架的认知还不足以支撑快节奏的互联网业务发展。在通用框架的基础上,深刻理解搜索业务,关注稳定性、研发效能,找到应用场景的痛点,有针对性的做出架构调整,才能构建出真正助力业务发展的搜索系统。