作者 | matrix明仔 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/616531799
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群
1说在前面的话
我一个朋友昨天喝了两大口白开水,也不知他是不是喝上头了,突然转过头冲我喊道“明仔,自动驾驶已经不存在了!我们都不愿意承认它的失败,现在的工作,就是自动驾驶脱不下的长衫罢了。”我说:"你吼辣么大声干嘛!我连驾照都没有考,还等着自动驾驶呢!"
写这篇稿子之前我其实也没有完整且系统的看过3DTrans,但是我读完了Uni3D的文章。前几天偶然间,无意间,看到了文章有1/12的机会拿到best paper,所以就心血来潮,带着大家来开箱这篇突破无监督源域自适应感知性能极限的高分神作—Uni3D,
2工作发生的背景:
其实自动驾驶,特别是3D目标检测,一直以来好像都是自己做自己的数据集,自己玩自己的。当你试图将模型从nuScenes数据集上迁移到Waymo的时候,多数情况下优势不能保持,都会出现精度下降的问题。这时候很多人会说,几个数据集的LiDAR 类型和数据采集标准都不一样,数据的质量,数量以及标准都不统一,你这样的迁移实验没有意义啊!可是我们要知道,现在的大模型依旧是数据驱动型的,模型强大的表征能力依旧是从海量的数据中学习来的,所以,将所有的数据都有效的利用起来,使得模型具备更强的泛化性以及分辨能力就是我们所追求的短期靠近大模型的目标,先行业内大一统,再谈大模型。或者说得再直白一些就是,先把数据给统一了,再开始一步一步的把模型加大
讲完上面那些场面话,这里也稍微带大家回顾一下(预习一下)nuScenes, Waymo and Kitti,以及安利一下MMDetection3D,但是本文很大程度是依赖OpenPCDet进行开发的,其实我知道很多伙伴都不太了解MM系列的MMDetction3d和OpenPCDet,不过也没关系,我稍后会在尬聊环节也会讲几句他们之间的一些区别。
nuScenes
nnScenes是由Motional(formerly nuTonomy)所创建的,旨在帮助研究人员开发自动驾驶系统。该数据集包括超过140万张图像,其中包含来自20个城市的街景图像、2D/3D注释以及物体检测框。nnScenes涵盖了不同时间和天气条件下的各种驾驶场景,使其成为评估自动驾驶系统性能的理想数据集。
Waymo
Waymo是谷歌旗下的自动驾驶技术公司,也是自动驾驶领域最具影响力的公司之一。Waymo数据集是由Waymo公司发布的,包括高分辨率的图像、3D点云数据和传感器数据,其中包括激光雷达、摄像头和雷达。Waymo数据集的标注包括物体检测、物体跟踪、语义分割和道路线等信息。
KITTI
KITTI是德国卡尔斯鲁厄理工学院计算机视觉与激光雷达研究组开发的自动驾驶数据集。该数据集包括2D/3D标注的图像、激光雷达和GPS数据,以及精确的物体检测、3D物体跟踪和道路标记等信息。KITTI数据集广泛应用于目标检测、3D物体识别和轨迹预测等方面的研究。
与本文的一些对比工作/相关工作
3工作内容的介绍
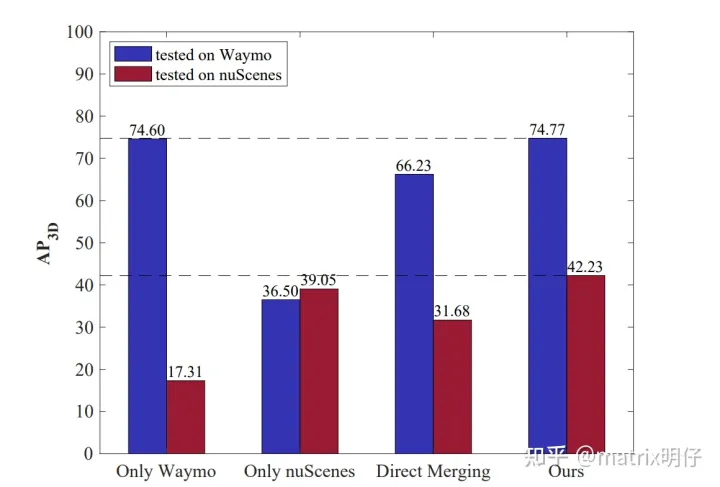
图一给我们展示了是一组打脸实验,证明了开头提出了的问题点
不幸的是,现有的监督三维目标检测模型是按照典型的单数据集训练和测试范式设计的,当这些检测模型直接部署到另一个数据分布不同的数据集时,不可避免地会出现严重的精度下降问题[。文中的实验表明,在Waymo上训练的基线检测器在另一个不同的数据集nuScenes上进行评估时,检测精度严重下降(从74.60%下降到17.31%)。因此,这种单数据集训练和测试范式在不同的数据集上表现不佳,进一步损害了当前3D感知模型的数据集级泛化能力。
为了减少不同 3D 数据集之间的差异,一些研究人员尝试利用无监督域适应 (UDA) 技术,该技术旨在将预训练的源域检测器转移到新领域(或数据集)。尽管这些基于 UDA 的 3D 对象检测工作在新目标域上取得了良好的检测精度增益,但它们仍然是源到目标单向模型适应过程,而不是多数据集双向泛化过程。
因此,为了设计一个能够充分从不同目标数据集学习的统一 3D 对象检测框架,我们首先直接合并多个数据集并在合并数据集上重新训练基线检测器,发现这种简单的方法实现的多数据集检测精度并不令人满意,如图 1 中的直接合并结果所示。这主要是因为与 2D 图像域相比,3D 点云数据呈现出更严重的跨数据集差异,原因是传感器类型差异、交通场景变化、数据采集变化等原因多种多样和复杂的原因,这被称为数据集干扰问题。此外,随着自动驾驶数据集的不断增加,如何从如此多样化的 3D 数据集训练一个统一的检测器成为一个非常重要的话题。
这里我不想码字,偷懒直接翻译了原文
在本文中,我们提出了一个统一的 3D 对象检测框架 (Uni3D) 来解决数据集干扰问题。与现有的 3D 对象检测研究工作正交,专注于开发在单个数据集中验证的有效框架,Uni3D 旨在提出一种简单且通用的方法,以使现有的 3D 对象检测模型能够从多个多样化的 3D 数据集中学习。为了实现这一目标,我们设计了一个简单的数据级校正操作,该操作可以使用特定于数据集的通道的均值和方差来规范化每个主干层的特征。此外,通过计算空间注意图和数据集级注意掩码,设计了一个语义级耦合和重新耦合模块来加强不同3D数据集的特征重用性,将学习到的高级特征约束为数据集不可知的。
在三个公共 3D 自动驾驶数据集上进行了广泛的实验,包括 Waymo 、nuScenes 和 KITTI ,以研究 3D 数据集干扰问题的原因。此外,本文提供了许多初步研究,以探索在合并数据集下训练 3D 对象检测模型的可能性。实验结果表明,Uni3D具有较强的数据集级泛化能力,提高了不可见场景的零镜头学习能力,甚至超过了在单个数据集上训练的基线方法。
4相关工作的发展进程
3D目标检测的工作
最近的基于激光雷达的三维物体检测工作大致可以分为基于体素的方法、基于点的方法和点体素融合方法。
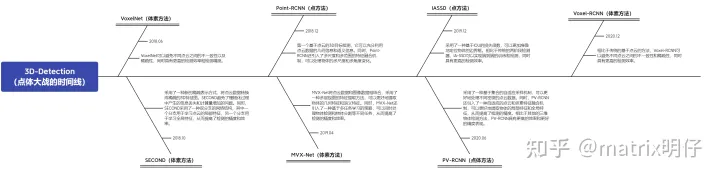
基于体素的方法主要是在主干特征提取之前将不规则的LiDAR点转换为有序的体素。其中比较有代表性的就是SECOND,它利用稀疏卷积作为3D主干,大大提高了检测效率。Voxel-RCNN则在SECOND的基础上分析了体素特征的优点,探索了检测精度和推理速度之间的良好权衡。与基于体素的方法不同,基于点的方法直接从原始点云生成特征映射。受PointNet和PointNet++的启发,Point-RCNN是研究如何从点云数据生成边界框的先驱。为了减少基于点的方法的高内存和计算成本,IA-SSD 通过采用基于学习的实例感知下采样的策略提出了一种单阶段方法。进一步提上点云方法的时间和效率优势。此外,一些作品试图结合点的表示和体素表示的优势。其中,PV-RCNN就设计了一个非常棒的点体素融合的方案,将两个模式进行融合。
为了方便刚接触的新手(我)了解,我把上面high line的工作给大家做了一个时间图,方便大家看一下点体大战的时间线。
域对齐/同步的思考
在2D方向中,也常出现这样类型的问题。如果我们使用所有的数据集去训练一个统一的模型,精度也还是不高。这是由于在不同的数据集中,对于label的标注是不一致的。数据集与数据集之间的差异往往是毒害模型精度的罪魁祸首。想要解决上述问题也非常简单,之前的方法概况其起来就是“统一标注体系”。但是“统一标注体系”这个工作说起来简单,实际上需要付出非常巨大的人力成本来完成对数据集的标签回炉重造的一系列工作。这时候会有人站出来说,我们可以训练一个模型用于重新设计那些差异较大数据集的标签就好了。即使是伪标签,只要符合标准,也是能够提升精度的。即使是这样已经是会耽误一些时间,如果我们可以实现在线训练的过程中能够自适应的完全源域的适配调整就好了。于是很多域适应的结构和注意力机制受到好评。(这里稍稍的唠一下,我自己的最近在研究的多模态感知RGB-X的工作其实也使用和设计不同类型的注意力机制来自适应的完成RGB和X模态的数据源域调整,但遗憾是因为我自己也是水水的,所以在这方面没有做到突破性的进展,比较长时间也是在调参炼丹的方式来找到调整和建模两个源域的关系,所以这里,如果有朋友希望和我们交流的话,我是非常,非常欢迎!谁不想在考公务员前多点文章呢?哈哈哈)回到正题,尽管最近在 我们在2D 感知任务能够做到大数据集的大一统,但它在 3D 感知任务(例如 3D 对象检测)上的进一步探索仍然不足。
5结构设计
问题设置
对于怎么设计这样一个域融合的任务,文章中其实用来非常简单的一条数学公式来进行表达,就是X,Y代表了输入的点云和标签,MDF 的目的是从多个标记域 S 训练一个统一的模型,以获得更通用的表示 F : X → Y,这将在多个不同领域 S 上具有最小预测误差。其实直接说就是希望学习出一个统一的点云-标签的空间,使得整体数据集上的优化都往这个空间上靠拢。说得再直白一点就是,我们希望学习出一种新的标注方式,这个标注再各个数据集都通用,这样子就可以使得多个数据集的优化任务转变变为一个大数据集的整体的学习任务。
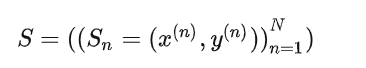
评估机制如何设置
因为重新对数据集进行了设计之后,所以样本对象的类别,类型,以及数量都会与之前的占比有很大的不同。而且有一个值得我们注意的是,因为是几个数据集混在一起训练,样本空间本身就不一致,假设在实际应用中,我们可以同时访问多个基于 3D 点云的域或数据集(例如,Waymo 和 nuScenes),但这些标记数据集通常具有不同的标签空间 Y,例如仅出现在 nuScenes中的Barrier 类别。所以原来单一数据集所对应的评估方法应该是不能直接用了。
又因为我们的研究主要关注自动驾驶场景下的MDF,所以我们当然是希望模型训练和评估更多是在自动驾驶场景有着很高相关度高的类别上进行的:比如说车辆、行人和骑自行车的人。但是不用觉这样的操作是在建立一套有偏置的利己的评估系统,其实这种选择常见类别(例如车辆、行人和骑自行车的人类别)的设置在此前许多跨数据集 3D 检测工作中也非常常见,例如 ST3D、ST3D++。(工作是有迹可循的,绝对客观)
3D 多数据集训练和评估。
假设在实际应用中,我们可以同时访问多个标记的基于 3D 点云的域或数据集(例如,Waymo 和 nuScenes),但这些标记数据集通常具有不同的标签空间 Y,例如仅出现在 nuScenes中的Barrier 类别。我们的研究主要关注自动驾驶场景下的MDF,其中模型训练和评估是在与自动驾驶场景相关的感兴趣的类别上进行的:车辆、行人和骑自行车的人。请注意,这种选择常见类别(例如车辆、行人和骑自行车的人类别)的设置在许多跨数据集 3D 检测工作中非常常见,例如 ST3D、ST3D++。
单数据集 3D 对象检测。目前,最先进的 3D 对象检测模型在单个公共基准中训练和评估,可以将其视为所谓的单数据集训练范式。但是要在多数据上进行实验,测试和优化的目标就需要进行重新设计,本文采取的方式如下面的公式一样,组合几个单一数据集上的优化目标。
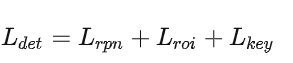
其中 L_{rpn} 用于生成预设提案的准确定位预测,L_{roi} 有助于细化提案以获得最终的 3D 边界框结果。此外,一些 3D 基线检测器,例如 PV-RCNN 和 PV-RCNN++,使用关键点预测损失 L_{key},用之后可以识别重要的前景点进而实现关键点到网格区域特征提取的过程。这里没有对任务的优化目标有加权,相当于只做了一个优化目标的线性叠加,大家地位都是一样的,我这里埋一个思考的彩蛋啊,如果我给这个几个优化目标加权会怎样呢?
基于MDF的三维目标检测的局限性。
如果是大一的我的话,接到这样的优化任务,第一反应就是一锅炖,直接all in所有数据将所有源数据集简单地组合成一个更大的源数据集。但是在嗑盐圈摸爬滚打这么久的我们一定知道的,这样做即使work也没有任何novel,如果这样work,这就变成了一个单纯的工程优化问题了,也就没有发文空间了。不过这都是嗑盐人的"彼得一激灵",如果没有一下子这样思考过来的同学们也不要紧。其实扎实的科学素养也会让你敏锐的察觉到这种操作其实没有对Domain GAP的问题有进行任何的调整,不work在理论上是成立的。不过最坏的情况就算你的嗑盐灵感没有,扎实的素养也没有,实验也会告诉你的,而其实就算上面说的再怎么合情合理,也需要做一组实验来证明,所以本质上实验科学面前,大家都是公平的。回到文章
不幸的是,在对这种自然数据集组合方式的初步尝试显示了,发现检测性能与在单独在各子数据集上进行训练相比有了显著的下降。
我们观察到,对于3D场景级数据集,直接执行数据集级合并无助于提高检测器的跨数据集检测精度。相反,由于不同数据集的显着差异,检测器可能会整个混乱数据集的影响,从而无法进一步学习到特征,甚至会直接把原本好的特征给学歪。例如,Voxel-RCNN可以在仅在Waymo数据集上训练时获得相对较高的检测精度(Waymo验证集上的75.08% AP)。但是,当VoxelRCNN在Waymo和nuScenes的组合数据集上联合训练时,它面临着严重的性能下降(Waymo验证集上的AP仅为66.67%)。
下面是文章给性能下降找了几个理由。(记住,这里的对MDF的实验总结很重要,这里每一个都是文章的问题点,也是决定你文章能不接受,或者能不能高分的重中之重!)
1)数据级差异:
与由值范围为[0,255]的像素组成的二维自然图像相比,通常使用不同点云范围的不同传感器类型收集三维点云,导致数据集之间的分布差异。
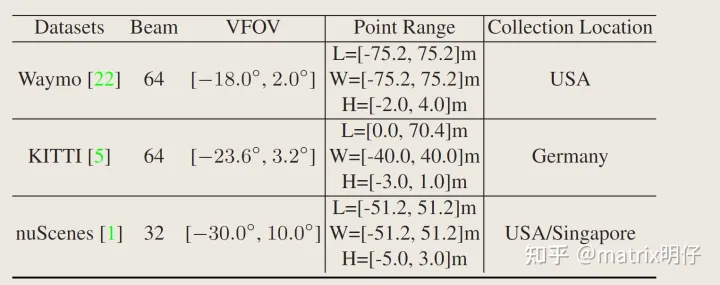
实际上,从上表看,不同传感器的一些差异,导致导出的点范围是有明显的差异。这也是干扰多个数据集共同特征学习的主要因素。因此,点云范围对齐是实现多数据集 3D 对象检测的必要预处理步骤。
此外,如下图所示,来自不同数据集的点云呈现出更多样化的数据分布
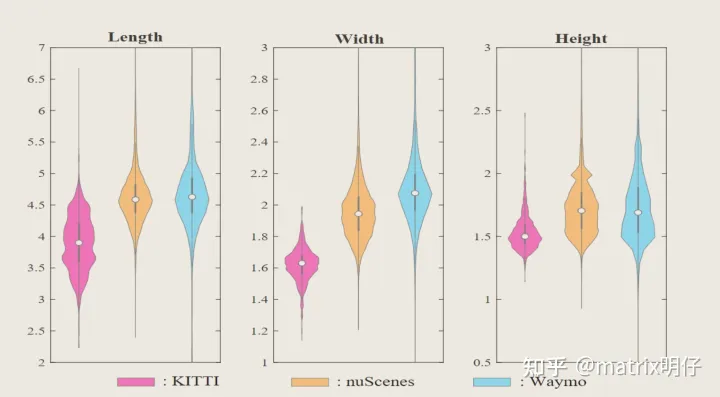
2) 分类级差异:
鉴于不同的自主驾驶制造商采用不一致的类定义以及不同的注释粒度。例如,对于 Waymo 所有驾驶道路(包括汽车和卡车)都被注释为一个统一的类别,即“车辆”。而对于 nuScenes,不同的车辆使用不同的细粒度分类法进行注释,例如数据集会把这些各种车给注释出来“汽车”“卡车”。因此,MDF 任务也需要考虑如何在不一致的分类标签空间下训练 3D 检测器,并有效地复用这些来自不同数据集共享的与领域无关的知识。
6主角登场!Uni3D:统一的 3D 多数据集对象检测基线
前面铺垫这么多,都是为了Uni3D这个主角登场而已。
为了解决上面提到的问题,本文给自己设定了一个目标:开发一个简易模块,使模型可以再不同的数据源域里面也能够学习到泛化性!
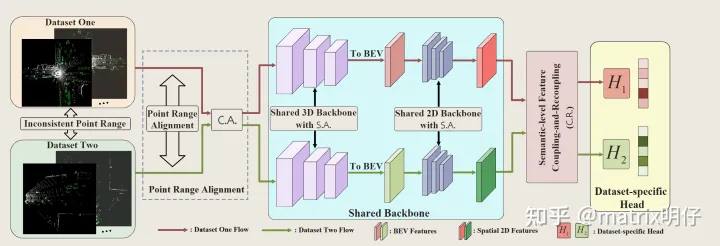
数据级校正操作。
首先,为了实现数据级校正操作,我们引入了一个统计级对齐的方法用于缓解常见2D或者3D的backbone在特征统计上的差异。这种方法可以与任何 3D 检测器相结合,包括 PV-RCNN和Voxel-RCNN。
具体来说,假设 μ和 σ 表示第 j 层网络层上每个通道的均值和方差。
通常来说,我们都会使用均值和方差的统计数值对每一层的特征进行归一化,使得每一层的输入数据符合均值为0方差为1的标准正态分布,例如大家熟悉的BatchNorm。
然而,这种统计共享归一化方式可能会损害 MDF 训练中的模型可迁移性,因为一个batch内的数据可能来自不同的数据集,具有较大的均值和方差差异。
为此,在 MDF 的模式下,我们首先从第 t 个数据集中获得这个数据集特定的通道平均值 μ 和σ方差。然后,来自每个数据集的样本由当前特定的数据集进行均值/方差正则化处理,如下所示:(具体操作看下面的代码)
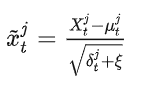
其中 表示第 t 个数据集中每个网络层的输入特征,并添加 ξ 以确保数值稳定性。此外,与BN[8]类似,x下面的转换步骤来恢复表示能力,如下所示:

其中我们使用数据集相同的 gamma γ 和 beta β,因为即使是在来自不同数据集的特征但是在被归一化为零均值和1方差之后,一阶/二阶的数据集间差异是一致的,所以对不同的数据集使用相同的 gamma γ 和 beta β也是合理的。
其实总结起来就是给BN层多加了一个t的参数,用于区分不同数据集从而提供针对性的操作而已,这个数据矫正的策略不算很复杂。
语义级特征耦合和重新耦合模块。
在这一部分中,我来介绍一下这一个简单的语义级耦合和解耦模块,我觉得这部分是有趣的,其实也与我在RGBT(论文即将开源)上的新工作有很多不谋而合的地方。我先给大家介绍一下Uni3D的思路表达
首先是这个类型的模块可以很容易地插入许多单数据集 3D 检测器中,并可以从特征耦合和特征重新耦合两个方面思考如何高效率的复用跨数据集的特征。
特征耦合:假设 表示由 2D 主干网络提取的 BEV特征,来自不同数据集的 Bev 特征 沿通道维度cat在一起,以使用前景感知和数据集级别的注意力掩码的方式对数据未知的感知领域进行学习。如下所示:

其中 [...,...] 表示的是沿通道维度的连接操作, 和 分别表示来自第 i 个和第 j 个数据集的 BEV 特征。 = φ,其中φ表示通过计算 BEV 特征的通道最大值来实现前景感知空间注意力的操作。此外,φ表示多层感知器 实现的数据集级注意掩码,然后是 N-cls softmax 操作,其中 N 表示要合并的数据集的数量。这样的数据集级注意掩码意味着 φ可以预测重新缩放分数以重新组合来自不同数据集的 BEV 特征,以便组合的 BEV 特征与数据集无关。
2)特征重新耦合:由于共享特征 共享主要关注多个数据集的共同知识,因此我们希望使用通道重新缩放操作将此类知识进行融合和共享特征 与之前与数据集相关的 BEV 特征 或者 共享:
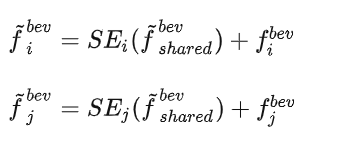
其中 SE 是 Squeeze-and-Excitation Network,所设计的耦合和解耦模块的整体网络结构如下图所示。
然而,探索跨数据集的这种特征关系会导致模型多数据集训练和单数据集测试之间的不一致,这主要是由于共享特征f^{bev}共享需要 和 的参与,但是单数据集的测试的情况只有 就没办法把 给加进来,为了避免这种尴尬,所以直接决定,把输入改成 和 来进行输入,这种方式简单粗暴,但是也高效,也使得整个Uni3D的工作可以使用单数据集的情况顺利的进行。
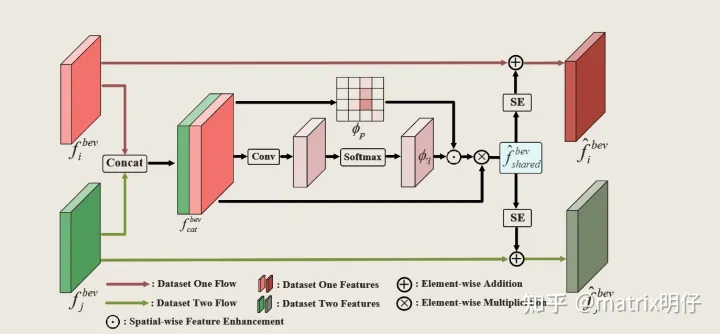
其实,我觉得这种空间+通道的信息整合模式是高效的。我也经过很多实验进行验证,我始终认为目前的最暴力,最简单,最粗犷,最高效的就是使用组合化SELayer的方式对多模态感知,多数据集的训练(我这里统称为多源域工作)进行性能提升。但是我们需要合适使用这种方式,常规的思路会把这个当成一个降噪的优化模块,或者更无脑的直接当个tricks用。导致现阶段的朋友们对这个工作误会和成见非常的大,大到直接用此模块来区分工作的novel。但是大家却忽略它本身对于特征语义思考的那部分,我觉得这也是大家对于SELayer误会最深的地方。其实无论是多数据集还是多模态上的研究,对于语义融合或者是语义对齐的研究都是必不可少的,但是大家往往会设计许多复杂的结构对这一系列的任务进行所谓的对齐和融合,我想说的是SELayer放在这里,它不香吗?SELayer模块以及一些Splat attention的模块经过设计之后,完全可以作为语义对齐和空间对齐的模块使用,而且对于算法的复杂度是相对友好的,我觉得其实我也不赖,即使文章寄了,我也至少有做对一点方向吧!
语义级特征耦合和重新耦合模块。
数据集特定的检测头。为了进一步解决数据集之间的分类级差异,会在loss上做一些手段以达到训练效果。比如使用不同的检测头 和特定于数据集的检测损失 在不同的数据集上进行实例级预测。MDF训练损失函数可以写成:
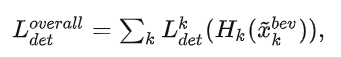
其中 是来自第 k 个数据集的特定于数据集的损失。在推理阶段,我们使用数据级校正操作来解决传感器引起的或数据分布引起的差异,并使用参数共享的 3D 和 2D 主干来提取点和体素特征。同时,分配给相应数据集的检测头用于生成最终预测结果。
论文部分结束
这里的实验结果我就不带着大家来分析了,想要复现工作的同学自己来操作一下就好了,或者有希望我往后把实验部分继续分析一下的话,先留言,我会在实验之后加更一版本的宵夜杂谈appendix
7尬聊环节
最近有朋友说我这个系列,废话又多,又没有干货,纯纯的文字搬运工,根本没有人会给我点赞。所以我特意新开了尬聊这一个新模块,用于尴尬一下,进一步证明我就是纯纯的文字搬运工!
MMDetction3D和OpenPCDet
为了增加一点节目效果,我特意开了个chatgpt的会员,帮大家问了一下GPT4,关于这两个repo的差异
以下是它的回复
OpenPCDet(OpenPCDet 是一个基于 PyTorch 的开源 3D 物体检测库,专注于点云处理。它的代码结构主要包括以下组件:数据处理、数据集、模型、网络层、训练、评估和可视化等。OpenPCDet 的设计原则是易于理解、易于扩展。这使得研究人员和工程师可以轻松地将最新的 3D 检测方法集成到 OpenPCDet 中。
MMDetection3D(MMDetection3D 是基于 MMDetection 的一个扩展库,同样是基于 PyTorch 的。它继承了 MMDetection 的优点,比如模块化、灵活、高度可扩展的代码结构。MMDetection3D 不仅包括点云处理和 3D 物体检测功能,还包括多模态数据处理(如图像和点云融合)以及 3D 语义分割等任务。
安装
安装操作(普通玩家)
1、git clone https://github.com/PJLab-ADG/3DTrans.git
2、pip install -r requirements.txt
3、python setup.py develop
高级玩家(有集群)可以使用
3、srun -p shlab_adg -N 1 -c 10 python setup.py develop实验复现的部分的朋友们可以注意一下
所有基于 LiDAR 的模型均使用 8 个 NVIDIA A100 GPU 进行训练,并可供下载。多域数据集融合 (MDF) 训练时间是使用 8 个 NVIDIA A100 GPU 和 PyTorch 1.8.1 测量的。对于 Waymo 数据集训练,使用 20% 的训练数据训练模型以节省训练时间。PV-RCNN-nuScenes 表示仅使用 nuScenes 数据集训练 PV-RCNN 模型,而 PV-RCNN-DM 表示合并了 Waymo 和 nuScenes 数据集并在合并后的数据集上进行训练。此外,PV-RCNN-DT 表示域注意力感知多数据集训练。
8总结
其实我看见,这篇文章很多时候都希望蹭上大模型的热度。自动驾驶也开始为了统一数据集,或者是多数据泛化性而进行努力了,你们其它方向,再不大一统就会不存在了。不过这篇工作的立意非常符合主基调,但是我觉得似乎还是缺点成为自动驾驶拐点的意思,但是问题不是出现在这篇工作,出现了现在的AIGC的研究背景下。主要是觉得有两个方面啦,还是觉得lidar太局限了,而且数据集也相当的少。其实我觉得是可以引入多模态的思路开进行拓展数据集的,不过这方面也确实会对源域任务带来新的挑战,这不是发文的机会就来了吗?其次的是对于自动驾驶感知的探索方向我们依旧是迷茫的,到底是使用更大量的数据集,即使是不同规格的数据集,甚至是当前认为十分有害的数据强行研究出泛化性好,还是在大量数据集中统一出一个高质量的数据集进行更高精度的冲击会比较好。这些问题我觉得都没办法在现阶段给出答案,或者在更长一段时间里面,大家都会在使劲的纠结这个问题。比起NLP出发的AIGC而言,传感器类型的研究是复杂且抽象的,信息是非常冗余的,最关键是数据成本更高,这种情况下,无脑的使用大数据的方法也不一定能够准确的学习到特征的表达和接收到合理的反馈,目前来看这个课是相当的枯燥。
但是,人生枯燥的时候很多,何必在乎这一两年呢?
另外说一下的是OpenDataLab对于3DTrans的介绍会更加详细,大家可以去看看啊,我觉得写得非常好!最后的最后,浪费了大家的时间我是十分抱歉的,希望大家可以在留言区留下改进的方向,请大家我会慢慢调整。
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称