清华唐杰新作WebGLM:参数100亿、主打联网搜索,性能超OpenAI WebGPT
github仓库地址:https://github.com/THUDM/WebGLM
上周五在WAIC 上的论坛报告回放。先放两个供大家参考,另外的报告会陆续放在 B 站。另外还有一个贴近落地实践的 prompt 课程,近期会发在 B 站上。
模型地址:https://huggingface.co/THUDM/WebGLM
【报告】ChatGLM 的路径探索
https://www.bilibili.com/video/BV1cm4y1E7uV
【报告】WebGLM: 检索增强的大规模预训练模型
https://www.bilibili.com/video/BV1f94y1q7pU/



Atlas :归根结底,检索增强模型的目标是期望模型不仅学会记忆数据,同时希望模型学会自己找到数据,这点特性在许多知识密集型的任务中具有极大的优势并且检索增强模型也在这些领域取得了巨大的成功,但是检索增强是否适用于小样本学习却不得而知。回到 Meta AI 的这篇论文,便成功试验了检索增强在小样本学习中的应用,Atlas 便应运而生。https://zhuanlan.zhihu.com/p/564646449
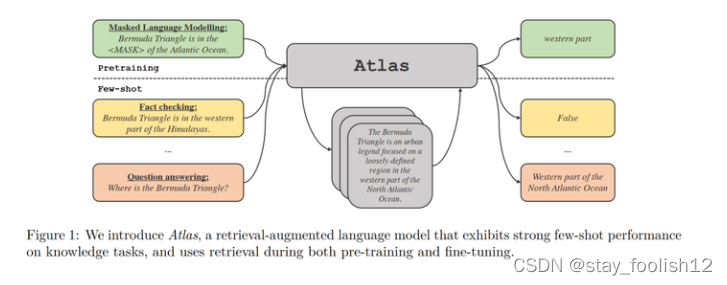 Atlas 拥有两个子模型,一个检索器与一个语言模型。当面对一个任务时,Atlas 依据输入的问题使用检索器从大量语料中生成出最相关的 top-k 个文档,之后将这些文档与问题 query 一同放入语言模型之中,进而产生出所需的输出。
Atlas 拥有两个子模型,一个检索器与一个语言模型。当面对一个任务时,Atlas 依据输入的问题使用检索器从大量语料中生成出最相关的 top-k 个文档,之后将这些文档与问题 query 一同放入语言模型之中,进而产生出所需的输出。
Atlas 模型的基本训练策略在于,将检索器与语言模型使用同一损失函数共同训练。检索器与语言模型都基于预训练的 Transformer 网络,其中:
检索器基于 Contriever 设计,Contriever 通过无监督数据进行预训练,使用两层编码器,query 与 document 被独立的编码入编码器中,并通过相应输出的点乘获得 query 与 document 的相似度。这种设计使得 Atlas 可以在没有文档标注的情况下训练检索器,从而显著降低内存需求。
语言模型基于 T5 进行训练,将不同文档与 query 相互拼接,由编码器分别独立处理,最后,解码器对于所有检索的段落串联进行 Cross-Attention 得到最后的输出。这种 Fusion-in-Decoder 的方法有利于 Atlas 有效的适应文档数量的扩展。
值得注意的是,作者对比试验了四种损失函数以及不做检索器与语言模型联合训练的情况,结果如下图:
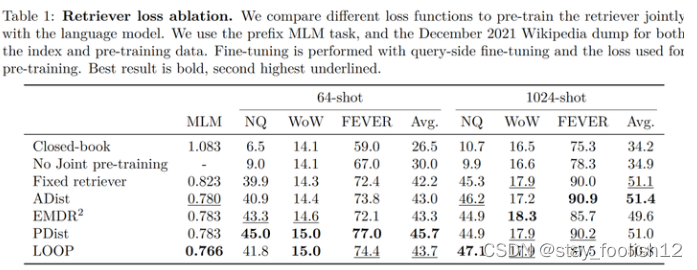
可以看出,在小样本环境下,使用联合训练的方法所得到的正确率显著高于不使用联合训练的正确率,因此,作者得出结论,检索器与语言模型的这种共同训练是 Atlas 获得小样本学习能力的关键。
- 实验结果
在大规模多任务语言理解任务(MMLU) 中,对比其他模型,Atlas 在参数量只有 11B 的情况下,具有比 15 倍于 Atlas 参数量的 GPT-3 更好的正确率,在引入多任务训练后,在 5-shot 测试上正确率甚至逼近了 25 倍于 Atlas 参数量的 Gopher。
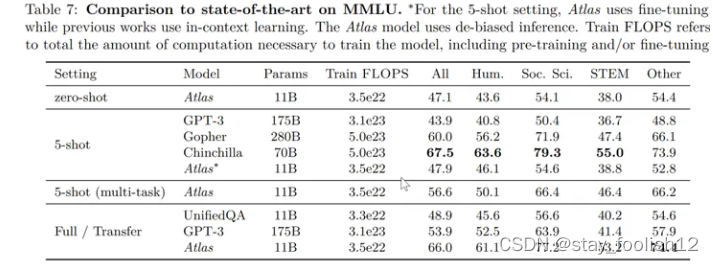
在开放域问答的两个测试数据——NaturalQuestions 以及 TriviaQA 中,对比了 Atlas 与其他模型在 64 个例子上的表现以及全训练集上的表现如下图所示,Atlas 在 64-shot 中取得了新的 SOTA,在 TrivuaQA 上仅用 64 个数据便实现了 84.7% 的准确率。
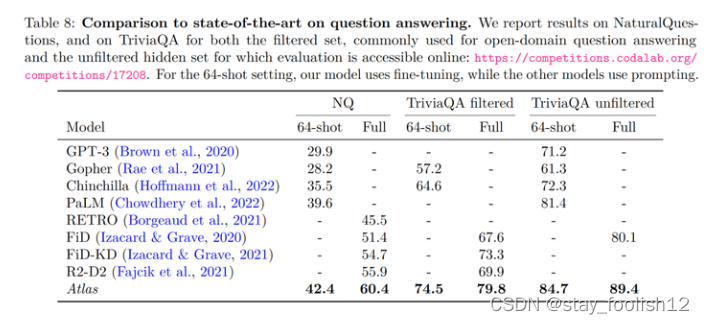
在事实核查任务(FEVER)中,Atlas 在小样本的表现也显著优于参数量数十倍于 Atlas 的 Gopher 与 ProoFVer,在 15-shot 的任务中,超出了 Gopher 5.1%。

在自家发布的知识密集型自然语言处理任务基准 KILT 上,在一些任务里使用 64 个样本训练的 Atlas 的正确率甚至接近了其他模型使用全样本所获得的正确率,在使用全样本训练 Atlas 后,Atlas 在五个数据集上都刷新了 SOTA。
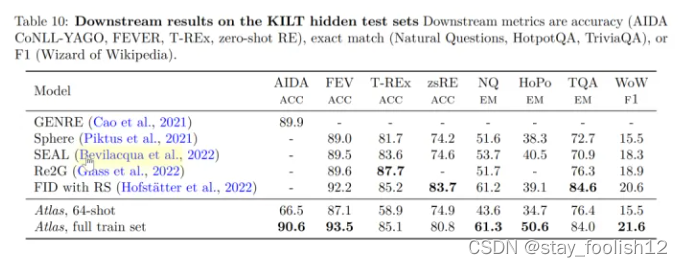
- 可解释性、可控性、可更新性
根据这篇论文的研究,检索增强模型不仅兼顾了更小与更好,同时在可解释性方面也拥有其他大模型不具备的显著优势。大模型的黑箱属性,使得研究者很难以利用大模型对模型运行机理进行分析,而检索增强模型可以直接提取其检索到的文档,从而通过分析检索器所检索出的文章,可以获得对 Atlas 工作更好的理解。
譬如,论文发现,在抽象代数领域,模型的语料有 73% 借助了维基百科,而在道德相关领域,检索器提取的文档只有3%来源于维基百科,这一点与人类的直觉相符合。如下图左边的统计图,尽管模型更偏好使用 CCNet 的数据,但是在更注重公式与推理的 STEM 领域,维基百科文章的使用率明显上升。
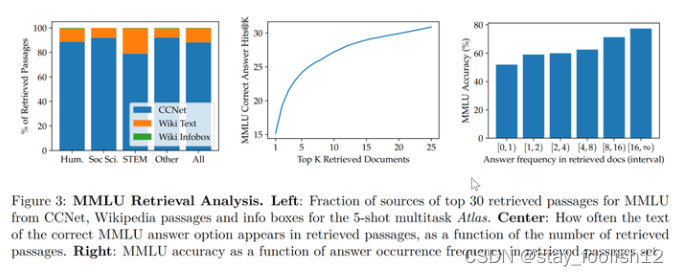
而根据上图右边的统计图作者发现,随着检索出的文章中包含正确答案的次数的升高,模型准确率也不断上升,在文章不包含答案时正确只有 55%,而在答案被提到超过 15 次时,正确率来到了 77%。除此之外,在人为检查了 50 个检索器检索出的文档时,发现其中有 44% 均包含有用的背景信息,显然,这些包含问题背景信息的资料可以为研究者扩展阅读提供很大的帮助。
一般而言,我们往往会认为大模型存在训练数据“泄露”的风险,即有时大模型针对测试问题的回答并非基于模型的学习能力而是基于大模型的记忆能力,也就是说在大模型学习的大量语料中泄露了测试问题的答案,而在这篇论文中,作者通过人为剔除可能会发生泄露的语料信息后,模型正确率从56.4%下降到了55.8%,仅仅下降0.6%,可以看出检索增强的方法可以有效的规避模型作弊的风险。
最后,可更新性也是检索增强模型的一大独特优势,检索增强模型可以无需重新训练而只需更新或替换其依托的语料库实现模型的时时更新。作者通过构造时序数据集,如下图所示,在不更新 Atlas 参数的情况下,仅仅通过使用 2020 年的语料库 Atlas 便实现了 53.1% 的正确率,而有趣的是即使是用2020年的数据微调 T5 ,T5 也没有很好的表现,作者认为,原因很大程度上是由于 T5 的预训练使用的数据是 2020 年以前的数据。
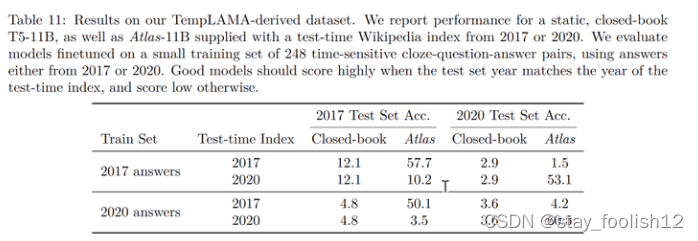
- 结论
我们可以想象有三个学生,一个学生解题只靠死记硬背,一道数学题可以把答案分毫不差的背诵下来,一个学生就靠查书,遇到不会先去翻找资料找到最合适的再一一作答,而最后一个学生则天资聪明,简单的学习一些教科书上的知识便可以自信去考场挥毫泼墨指点江山。
显然,小样本学习的理想是成为第三个学生,而现实却很可能停留在了第一个学生之上。大模型很好用,但“大”绝不是模型最终的目的,回到小样本学习期望模型具有与人类相似的推理判断与举一反三能力的初心,那么我们可以看到,这篇论文是换个角度也好是前进一步也罢,至少是让那个学生可以轻松一点不往脑袋里装那么多可能大量冗余的知识,而可以拎起一本教科书轻装上阵,或许哪怕允许学生开卷考试带着教科书不断翻查,也会比学生生搬硬套死记硬背更接近智能吧!



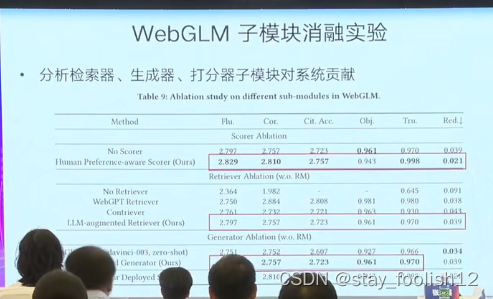
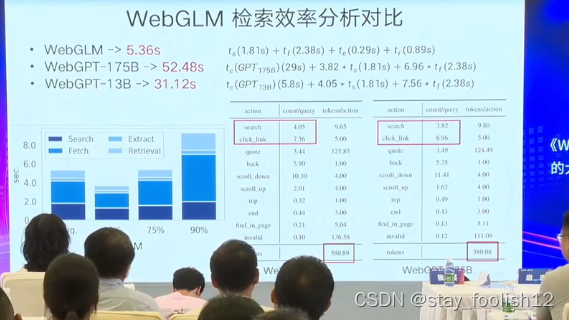
检索器:搜索引擎检索器,打分器 无人工标注

大模型采用作为标签,大模型的结果90.2%是正确的

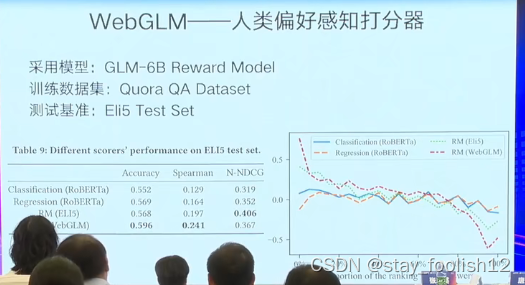

提出一套用于评价带引用长文本问答的指标