ChatGPT毫无疑问是当红炸子鸡,它用一种无法阻挡的魅力,彻底带红了 GPT (Generative Pre-Trained Transformer : 生成式预训练模型,基于Transformer 实现) ,LLM (Large Language Model, 大语言模型) 和 AIGC (Artificial Intelligence Generative Content, 人工智能生成内容) 这几个概念。
透过现象看本质,你可能和我一样好奇,这把火到底是怎么烧起来?它目前又有哪些主要的关注方向?未来可能还会怎么发展呢?
如果我去问ChatGPT,可能会得到如下的回复。
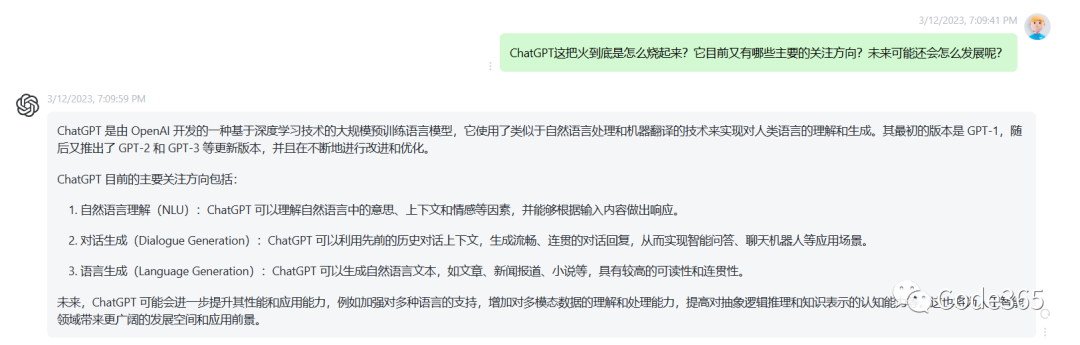
但作为一个还没有完全丧失理智的人类,我愿意做一次最后的挣扎,尝试自己通过数据来剖析一下,而我目前想到的数据源是 Github。
如果你在Github上面搜索 chatgpt 这个关键字,你会发现目前又接近 19K(一万九千个)个项目,喔嚯,这可真不少呢?
如果包括那些fork的项目,数量则更惊人,达到了将近77K(七万七千)个项目,而且这还只是那些公开(public)的项目,根据经验,如果算上私有(private)项目,则数量级还可以翻几倍。
那么,这些项目到底是怎么被创建起来的,他们在不同的维度所表现出来一些信息和规律大致是怎样的呢?
首先,我们来看一下整体的统计数据。
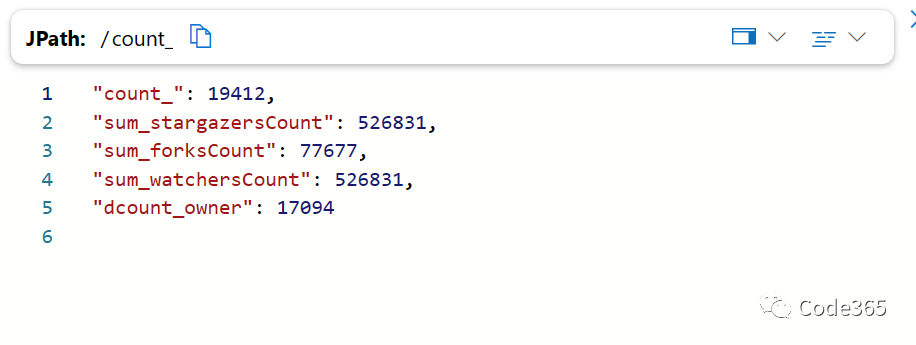
也就是说,17094个作者,一共创建了19412个项目,获得star数约53万,fork数约8万,watch数约53万(似乎跟star是一样,因为一旦star就自动watch了)。
接下来,看一下不同的日期创建项目的规律。
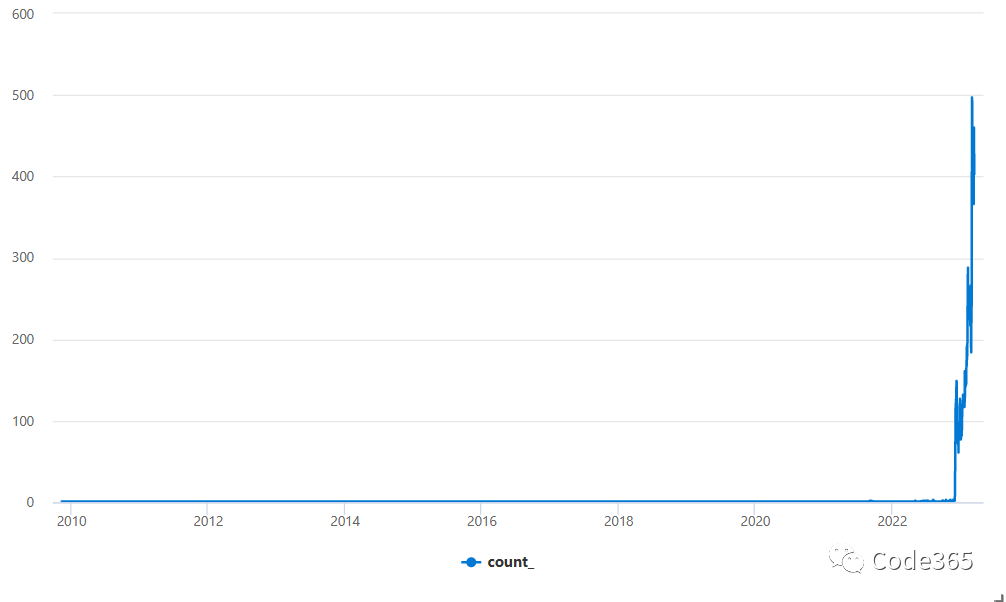
可以看出,真正开始热起来是从2022年12月左右,因为直到2022年11月30日,单日创建项目的数量也不过是2, 而截止到2022年12月的所有项目,也不过区区 171个,不足总数的 1%。
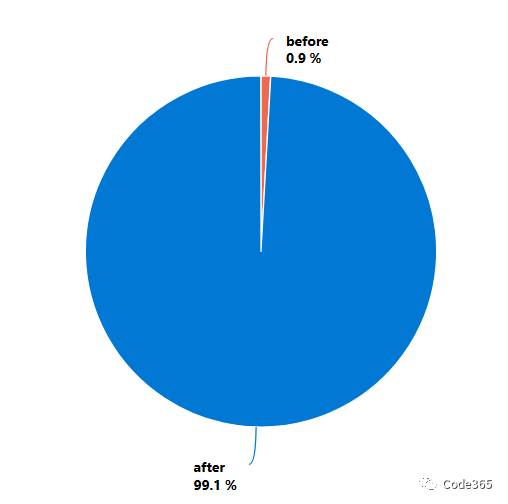
从2022年12月1日到现在100多天,平均每天有185个新项目创建出来,请注意,这不包含fork的项目。

单日创建项目最多出现在 2023年3月2日,达到了 497个。
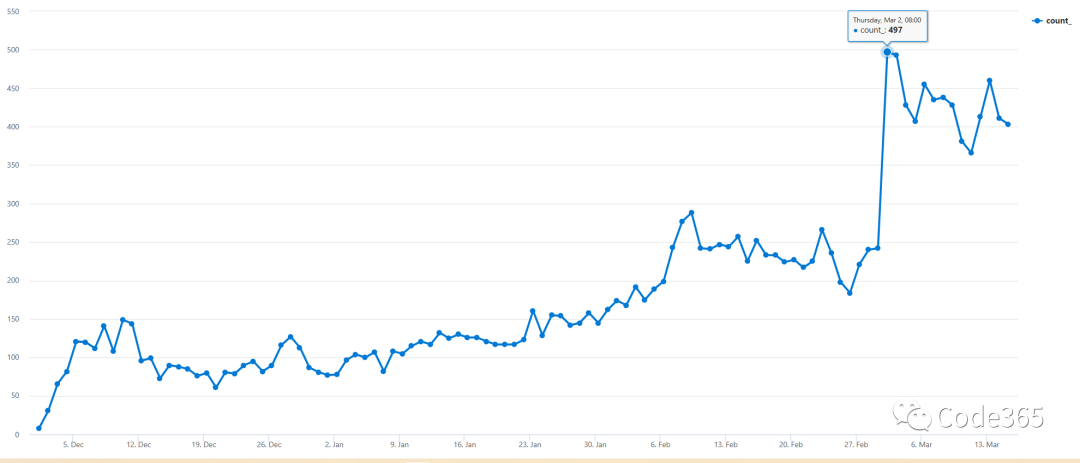
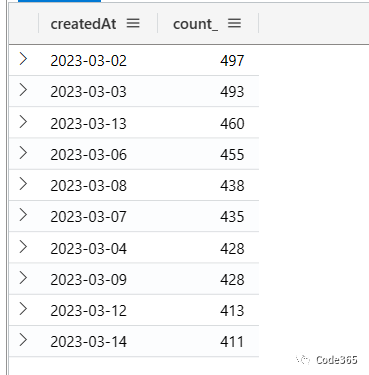
而单日创建项目数量超过100个的天数达到79天,占总比约为 75%。下面列出了Top 10的记录。
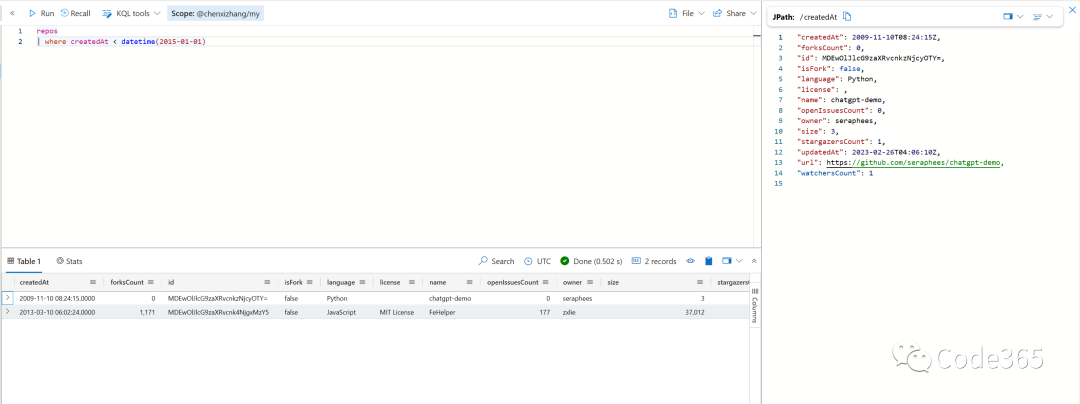
我们都知道OpenAI公司是在2015年才成立的,而ChatGPT真正开始做,估计最快也是2019年。但 2015年前居然有两个项目跟ChatGPT相关,这不仅让人诧异。细看之后,其中一个项目可能是最近才改的名字,而另外一个,其实跟 ChatGPT无关,但他自己强行加上了 chatgpt 的tag。这可能也算是一种其他的SEO手法吧,属于噪音的部分。做数据分析,或者使用ChatGPT这些人工智能,都需要有一种理性期待,就是甄别数据本身的真伪。
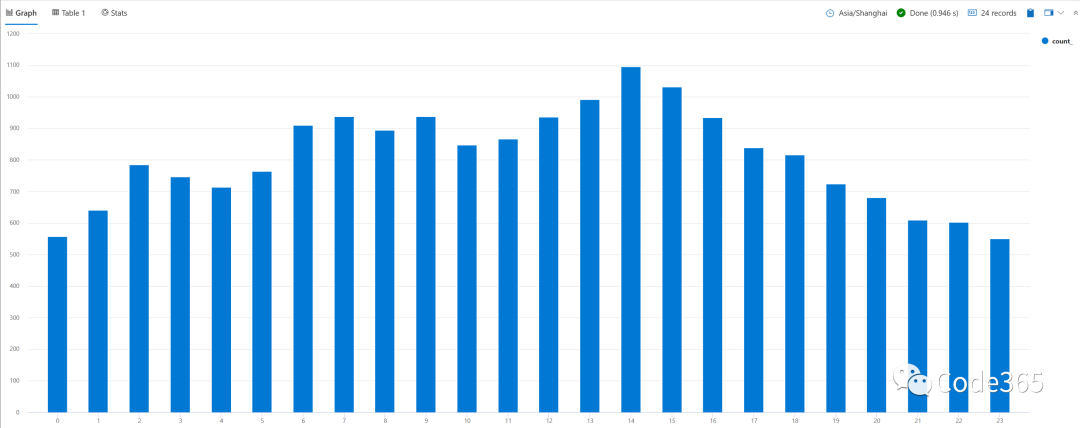
如果从时间轴中看一天中哪些时间段创建的项目更多,你可以得到下面的规律。
那么到底什么项目是最火的?下面是top 10的项目。
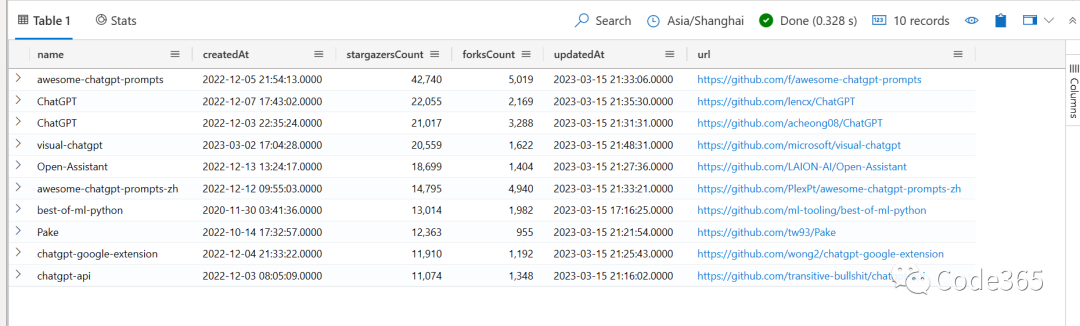
我们可以发现, prompt engineering真的是最热门的,这是符合预期的,因为大语言模型的当下,人类能做的事情已经不多了,学会如何做prompt似乎是当务之急。
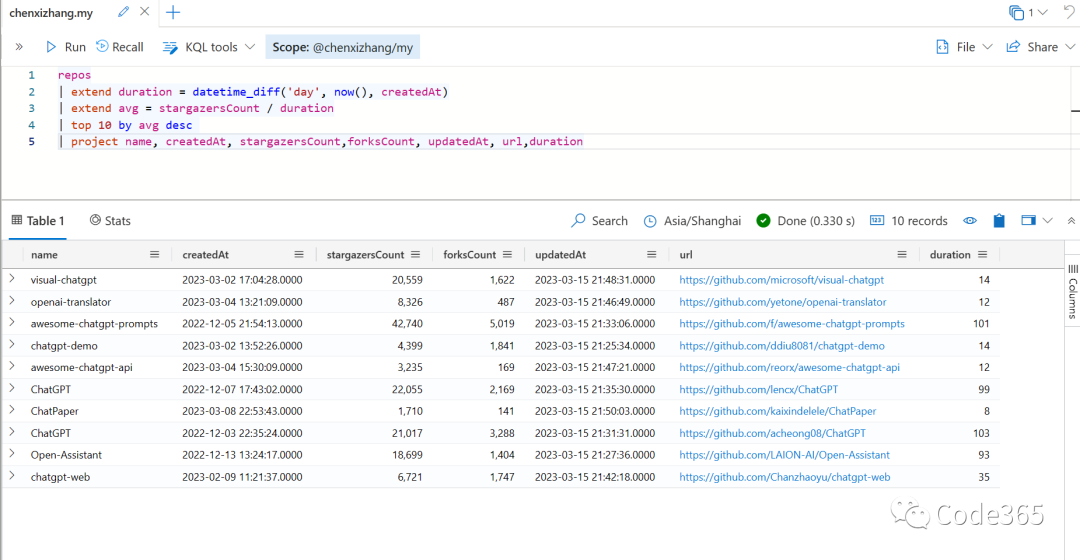
如果按照平均获赞的速度来看,排名如下。微软的 visual-chatgpt 排到了第一名,另外我们看到一些很有意思的新项目。(这种排名的方法,可以让我们发现哪些突然新出现热起来的方向)。
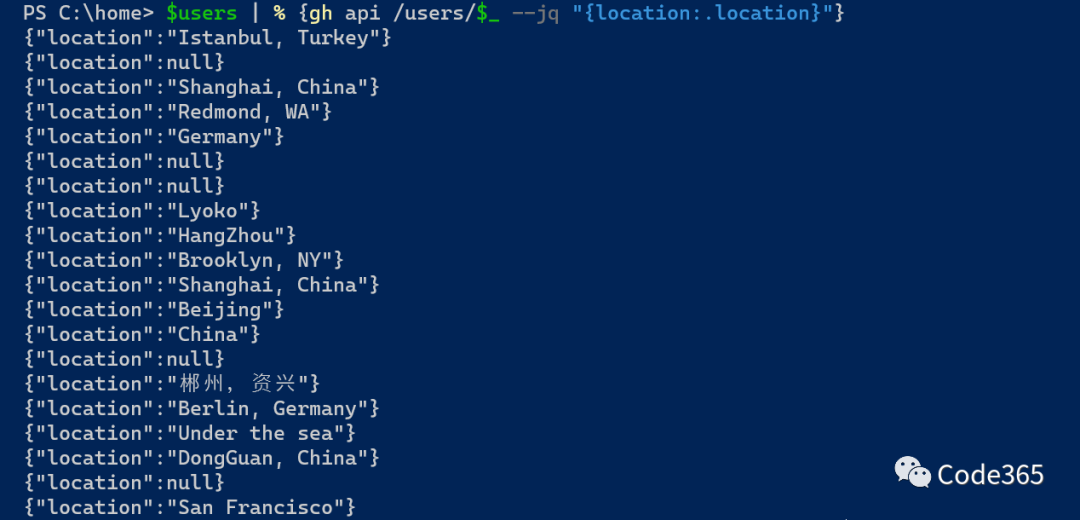
在过去的28内活跃的项目,如果按照作者及其创建过的chatgpt项目数量和获赞来排名,下面是一个top 20的名单。
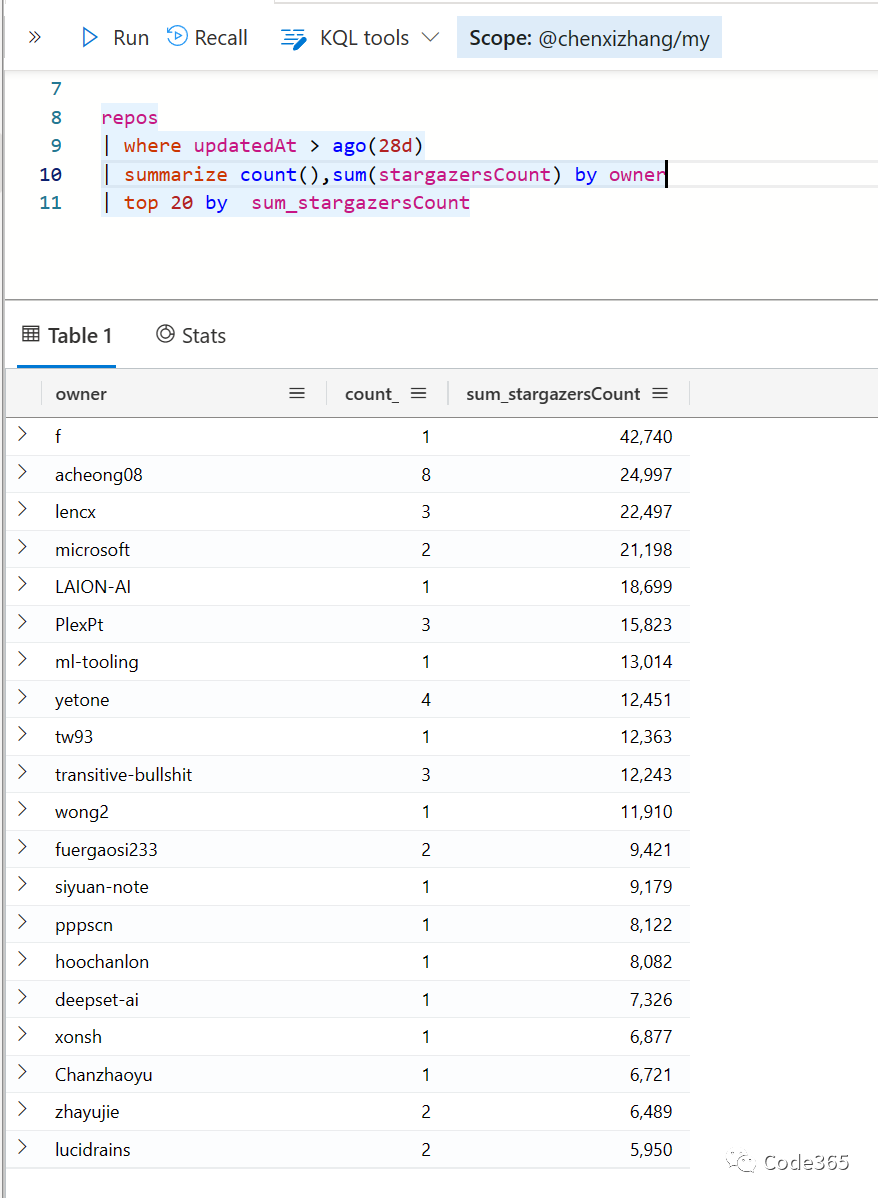
我特别关心一个问题,在这一波浪潮中,中国的开发者占到的比重有多大。根据这个top 20的用户信息,我们可以看到至少,除去地理位置未知的5个作者,中国的账号是7个,占到将近 50%的比例(7/15)。壮哉,我的国。
敬请关注,我还会更加全面地分析所有作者的信息。后续发布。
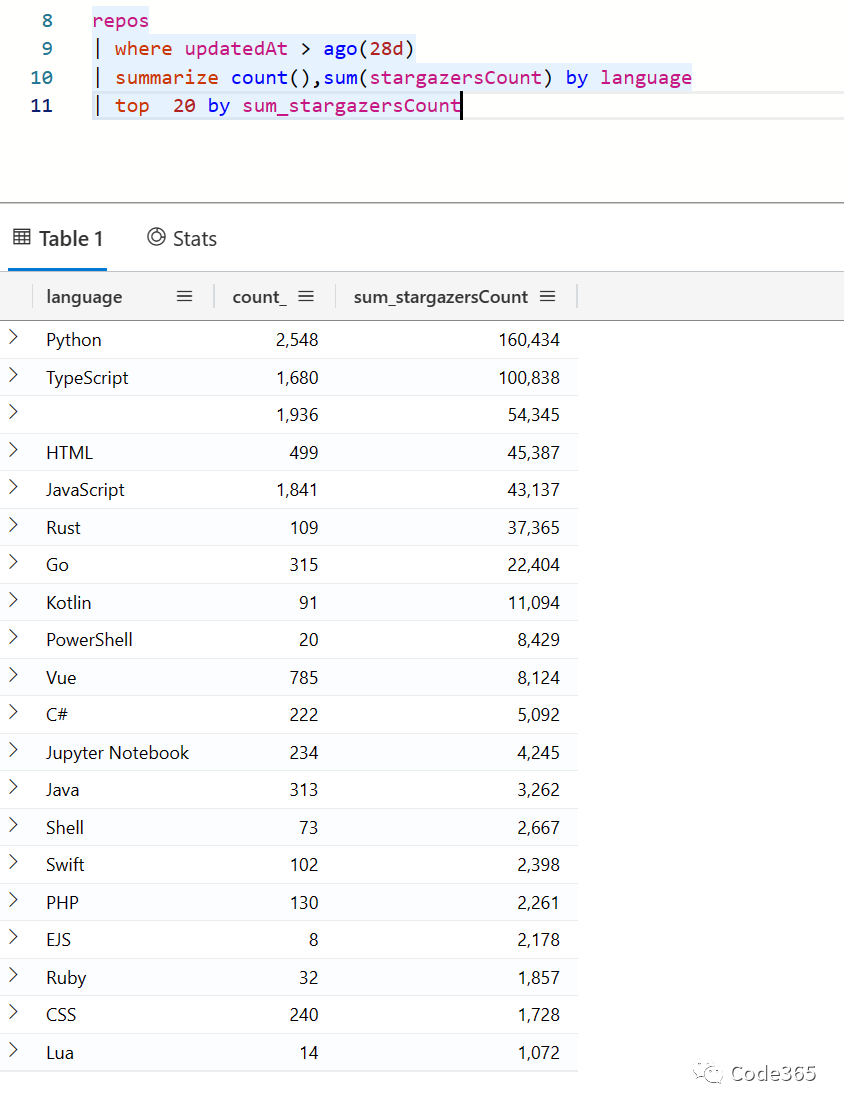
本文最后,我大致地看一下从语言的角度,目前的排名情况。
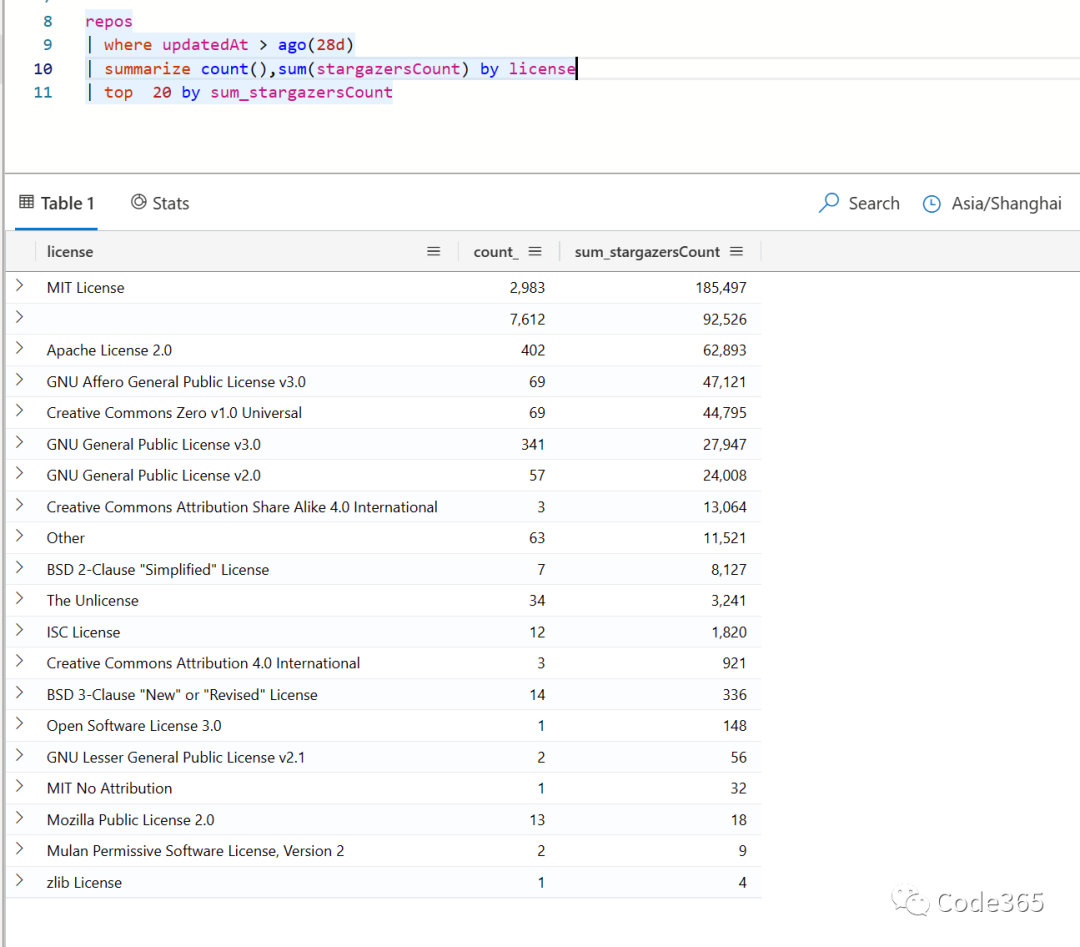
还有就是从license角度,目前的排名情况如下。
后续我还将继续发布各方面的深度研究,以及对重点项目进行分析。敬请关注。未来我会用ChatGPT来自动写这个报告,数据集会公开。