本文的主要解决方法来自于博客(Qt与MSVC中文乱码问题的解决方案_liuweilhy的博客-CSDN博客),特此鸣谢。
1.背景
今天心血来潮,将Qt编译器改为msvc 2019 64,应用程序中qdebug输出和界面输出的中文均出现乱码,而以前在用mingw编译器的时候,没有出现这种情况。
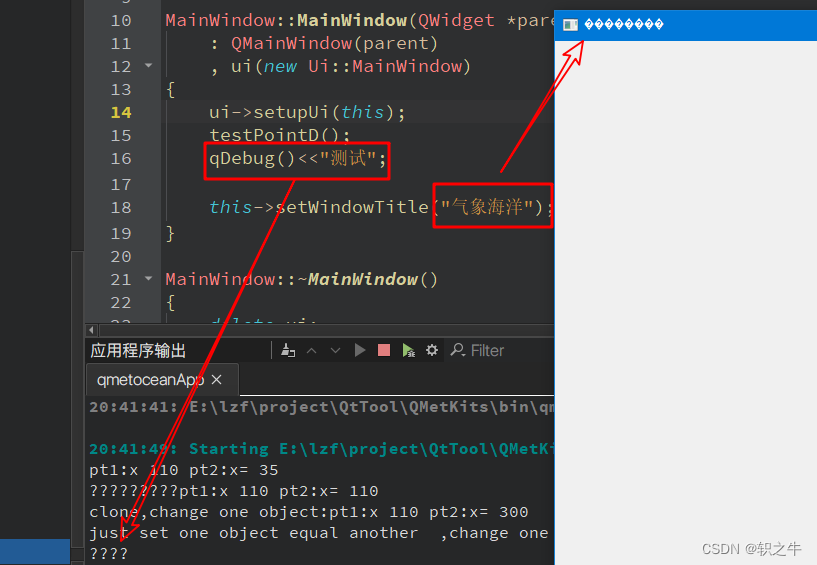
2、解决方法
出现问题,作为一个小白,自然是网上搜索,阅读了很多帖子,发现解决方案主要有以下几种:
-
(1)设置编码文件的编码为utf-8,且加入bom
- (2)添加QMAKE_CXXFLAGS += /utf-8到您的.pro文件中
- (3)在main函数中加入
QTextCodec *codec = QTextCodec::codecForName("UTF-8"); QTextCodec::setCodecForLocale(codec);
以上方法均尝试,在满足(1)的条件下,均无效。程序依然如故。
最后找到一个博客(Qt与MSVC中文乱码问题的解决方案_liuweilhy的博客-CSDN博客),最终解决了问题,为了便于以后查阅,特摘录部分
1. Qt Creator的编辑器默认使用UTF-8(代码页65001)编码来读取文本文件。而Visual Studio保存文件时默认采用的是本地编码,对于简体中文的Windows操作系统,这个编码就是GB2312(代码页936)。如果使用Qt Creator读取由Visual Studio创建的文件,那么编辑器就会以UTF-8编码格式读取GB2312编码格式的文件,出现中文乱码,因为这两套编码系统对汉字编码是不同的。至于英文部分不会乱码,是因为UTF-8和GB2312在单字节字符部分是兼容的。
2. MSVC在编译时,会根据源代码文件有无BOM来定义源码字符集。如果有BOM,则按BOM解释识别编码;如果没有,则使用本地字符集,对于简体中文的Windows操作系统就是GB2312。那么,当MSVC遇到一个没有BOM的UTF-8编码的文件时,它通常会把文件看作GB2312的来处理。如果文件全是英文没有问题,但如果包含中文,编译器就会出现误读。这种情况下,Qt Creator编辑器是正常的。但对于MSVC编译器,原代码会被它认识成下图这个样子:
不过,当以无BOM的UTF-8编码的字符串正好凑够偶数个字节时(比如偶数个汉字,或奇数个汉字加奇数个英文字母),编译器通常不会报警,因为它以为用GB2312编码读出的是正确的。
3. 不管源文件是何种编码,只要MSVC能够正确识别,就可以通过编译。但MSVC的执行字符集默认是本地字符集。对我们来说,它生成的可执行文件中的文字是GB2312编码的。而生成的Qt程序以UTF-8编码来识别GB2312编码的文字,对于“你好中文!”这几个字符,采用GB2312编码后再以UFT-8编码来读取,就会变成如下的乱码:
当以无BOM的UTF-8编码的字符串正好凑够偶数个字节时(比如偶数个汉字,或奇数个汉字加奇数个英文字母),反而不会出现乱码。那是因为,编译器用GB2312编码读出的乱码本身就是UTF-8编码的,现在又用UTF-8解读,自然就正确了。这纯粹是歪打正着。
首先,你要确定采用哪种源码字符集。你有两个选择:
1. 采用本地编码字符集(不推荐,跨平台时会比较麻烦,但在Visual Studio环境下配合Add-in工具编程比较方便);
2. 采用UTF-8编码字符集(推荐,适合跨平台)。
第二种方案的解决方法:
首先,要把项目中所有的头文件和源文件全都转换成UTF-8+BOM编码保存。
1. 第1个问题不存在了。
2. 第2个问题也不存在了。
3. 第3个问题,你也可以用上个方案中的方法来解决,但有更好的方法。那就是要用到中文字符的头文件和源文件开头加上MSVC的一个宏:
#if _MSC_VER >= 1600
#pragma execution_character_set("utf-8")
#endif
这个宏告诉MSVC,执行字符集是UTF-8编码的,别瞎整成GB2312的!还有个好处,就是能用tr包中文,方便日后的翻译
添加后,解决问题。

3 进一步探究
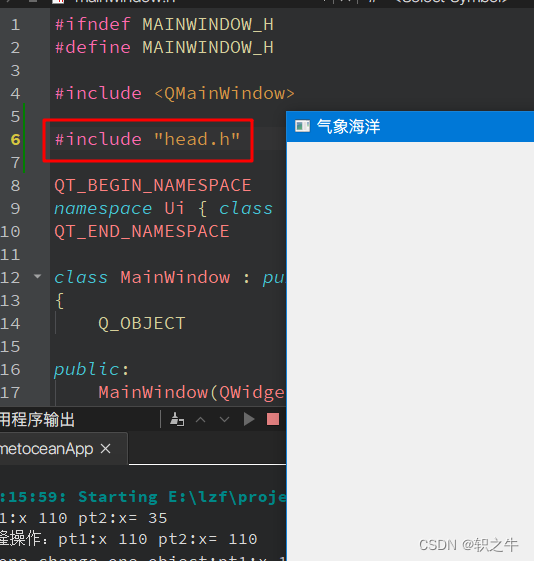
在尝试的过程中,我也尝试了刘典武大神的方法,在head.h中加入
#pragma execution_character_set("utf-8")在出现中文的代码文件中,加入该头文件的引用,依然可以解决问题。