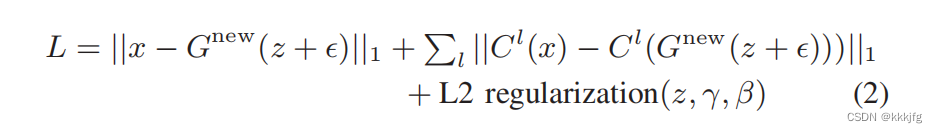©作者 | 机器之心编辑部
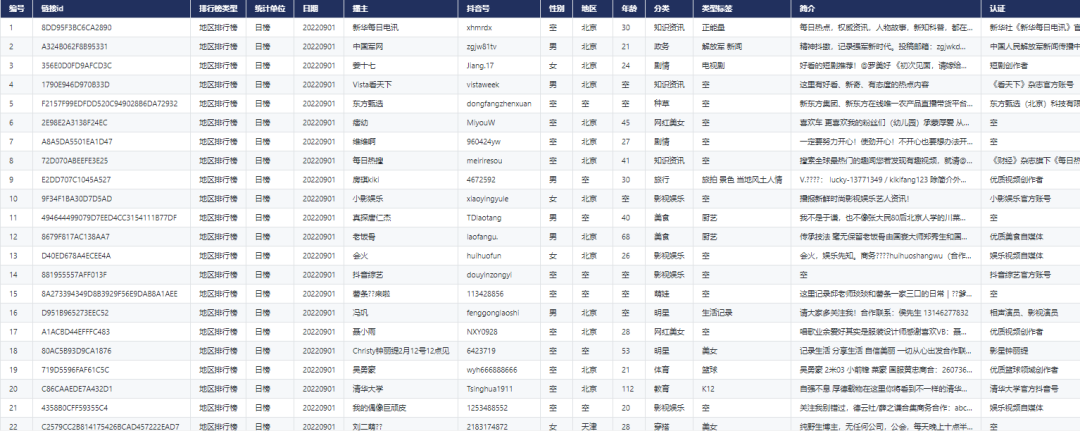
来源 | 机器之心
近日,来自卡耐基梅隆大学(CMU)的 Catalyst Group 团队发布了一款「投机式推理」引擎 SpecInfer,可以借助轻量化的小模型来帮助大模型,在完全不影响生成内容准确度的情况下,实现两到三倍的推理加速。
随着 ChatGPT 的出现,大规模语言模型(LLM)研究及其应用得到学术界和工业界的广泛关注。一方面,开源的 LLM 模型不断涌现,比如 OPT、BLOOM、LLaMA 等,这些预训练模型的推出极大地促进了 LLM 的相关研究,使得 LLM 可以被应用于解决愈发复杂的实际问题。利用这些开源模型,快速构建一套基于 LLM 的应用服务已经变得愈发容易,但 LLM 面临着高昂的计算和存储需求,其成本也令人望而却步。
另一方面,以羊驼家族(如 Alpaca、Vicuna、Guanaco)为代表的,经过微调或蒸馏的小型化 LLM 也成为了当下的研究焦点之一,在多项测评中都展现出了优异的表现;此外,以 Quantization、LoRA、Offloading 为代表的多项系统优化技术使得以更低的资源需求部署这些 LLM 成为可能。但天下没有免费的午餐,有关证据表明 [1],这些小型化的 LLM 以及面向低资源场景的系统优化技术往往都会带来模型质量的下降,影响最终应用的效果。
因此,如何在保证模型输出质量的前提下,让 LLM 推理变得高效和廉价,已经成为了 MLSys 领域非常重要的研究问题。近日,来自卡耐基梅隆大学(CMU)的 Catalyst Group 团队发布了一款「投机式推理」引擎 SpecInfer,可以借助轻量化的小模型来帮助大模型,在完全不影响生成内容准确度的情况下,实现两到三倍的推理加速。

论文链接:
https://arxiv.org/abs/2305.09781
项目链接:
https://github.com/flexflow/FlexFlow/tree/inference
论文作者之一、CMU 助理教授 Zhihao Jia 表示:「生成式大规模语言模型不仅推理效率低下而且部署成本很高;它们小型化的版本具有速度和价格上的优势,但是也会影响生成内容的质量;而 SpecInfer 可以实现这两方面的双赢。」
同样来自 CMU Catalyst Group 的助理教授 Tianqi Chen 也表示:「SpecInfer 可以适用于云上的 LLM 部署等场景,让 LLM 推理更加可扩展。」

研究现状
目前 LLM 推理主要依赖于自回归式(auto-regressive)的解码(decoding)方式,每步解码只能够产生一个输出 token,并且需要将历史输出内容拼接后重新作为 LLM 的输入,才能进行下一步的解码。考虑到这种数据依赖,现有 LLM 推理系统如 FasterTransformer 会采用一种增量式解码(incremental decoding)技术,将已经解码的 token 对应的 key/value 进行缓存,避免重新计算。
但是,这类系统仍然面临两个关键的缺陷:1)由于逐 token 计算的解码范式,算子并行度有限,GPU 硬件资源难以被充分利用;2)当序列过长时,KV-cache 空间消耗过大,有限的 GPU 显存无法承载。因此,当面对超大规模的 LLM 推理时(如 GPT-4 32K tokens),现有系统往往面临资源利用低效,推理延迟过高的问题。

▲ Incremental Decoding示意图
为了解决上述问题,研究者提出了一种「投机式」推理引擎 SpecInfer,其核心思想是通过计算代价远低于 LLM 的 “小模型” SSM(Small Speculative Model)替代 LLM 进行投机式地推理(Speculative Inference),每次会试探性地推理多步,将多个 SSM 的推理结果汇聚成一个 Speculated Token Tree,交由 LLM 进行验证,通过高效的树形解码算子实现并行化推理,验证通过的路径将会作为模型的推理结果序列,进行输出。
总体上来说,SpecInfer 利用了 SSM 的内在知识帮助 LLM 以更低廉的计算成本完成了主要的推理过程,而 LLM 则在一定程度上破除了逐 token 解码的计算依赖,通过并行计算确保最终输出的结果完全符合原始的推理语义。
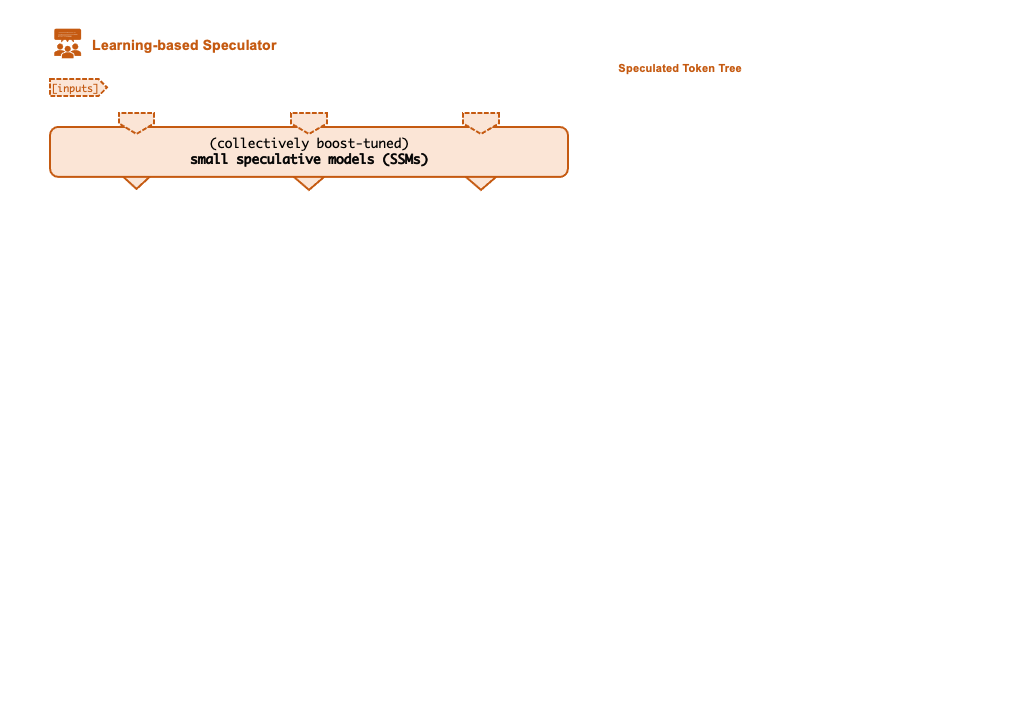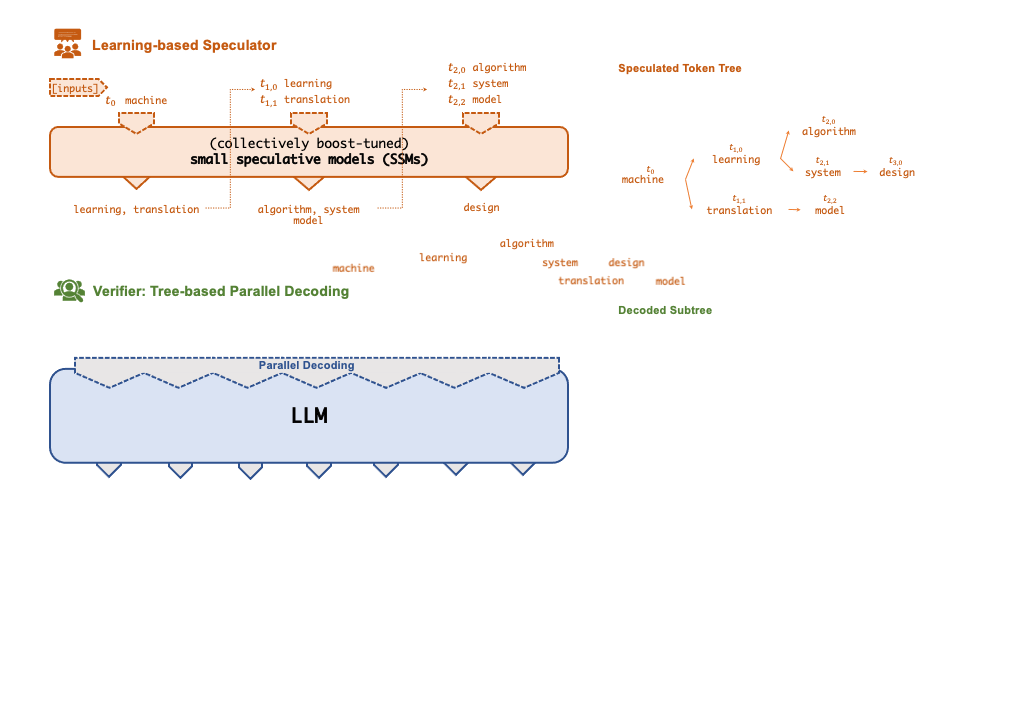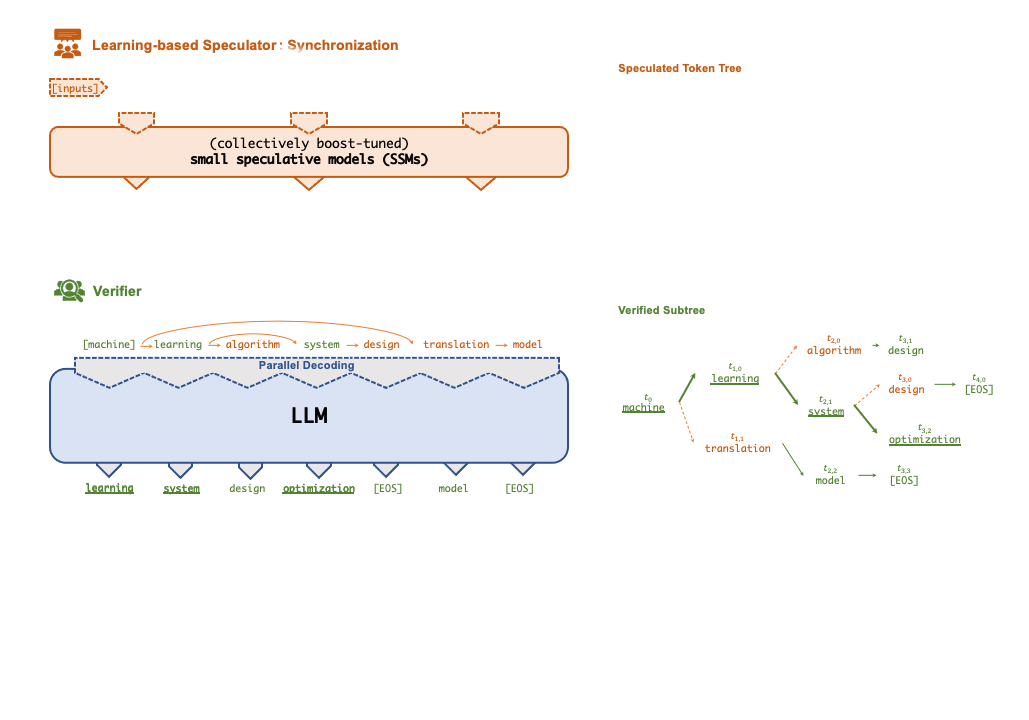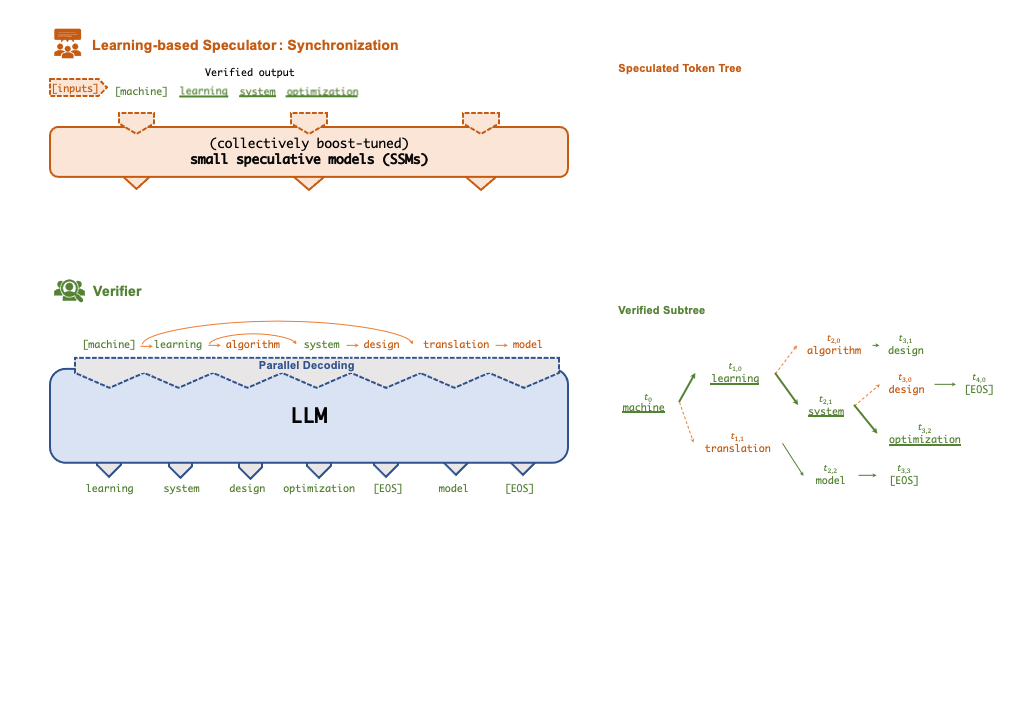
▲ SpecInfer工作流程

系统设计
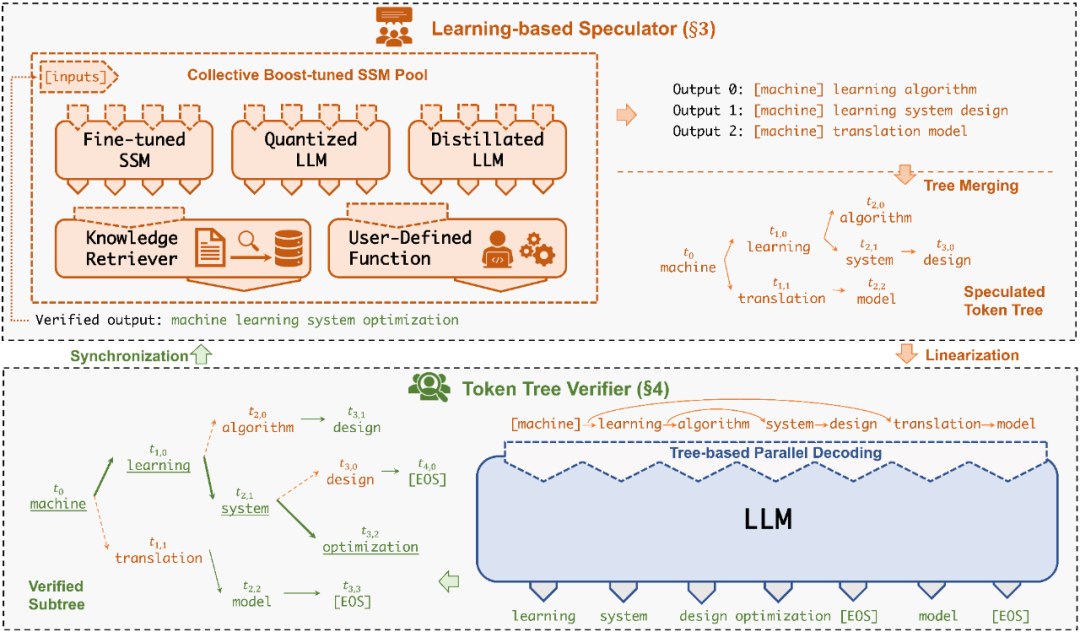
▲ SpecInfer系统架构
可学习推测器(Learning-based Speculator)
Speculator 的主要作用是利用 SSM 快速产生对 LLM 未来输出的推测结果,SSM 可以是(微调后)小版本的 LLM(如 LLaMA 7B),也可以是量化或蒸馏的小规模 LLM,还可以是可供检索的知识库(如参考文本)亦或是用户的自定义函数。总之,SSM 的输出结果越接近 LLM,验证时才会更容易通过,整体的推理效率才会更高。
为此,SpecInfer 引入集成学习的思想,将多个 SSM 的结果融合,提高输出的差异化程度。为了尽可能提高匹配率,Speculator 提出了 Collective Boost-Tuning 方法,即在一个公开的通用数据集(如 OpenWebText)上,从一个较弱的 SSM 开始进行微调,将匹配程度较低的序列不断从数据中过滤,交由新的 SSM 来学习,持续多次,提高整体的推测质量;此外,Speculator 还引入了一个可学习的调度器(scheduler)来决定选用哪些 SSM 以获得更长的匹配序列长度。
Token树验证器(Token Tree Verifier)
SSM 的推理速度优势是 SpecInfer 能够加速推理的前提,但另一个不可或缺的因素就是 LLM 对并行化推理的支持。在 SpecInfer 中,LLM 并不直接作为推理引擎产生输出 token,但是它需要对 Speculator 中 SSM 产生的 token 进行验证,确保输出内容符合 LLM 的推理语义。
在 SpecInfer 中,SSM 产生的输出序列会被组织成 token tree 的树形结构,避免冗余的存储开销。为了能够在 token tree 上进行并行化的验证,SpecInfer 提出了一种树形注意力(Tree Attention)计算方法,通过构造的 mask 矩阵和基于深度优先的 KV-cache 更新机制,Verifier 可以在不增加额外存储的同时,尽可能并行化树中每一条路径的解码过程。相比于朴素的逐序列或逐 Token 的解码方式,树形解码可以同时在内存开销和计算效率上达到最优。
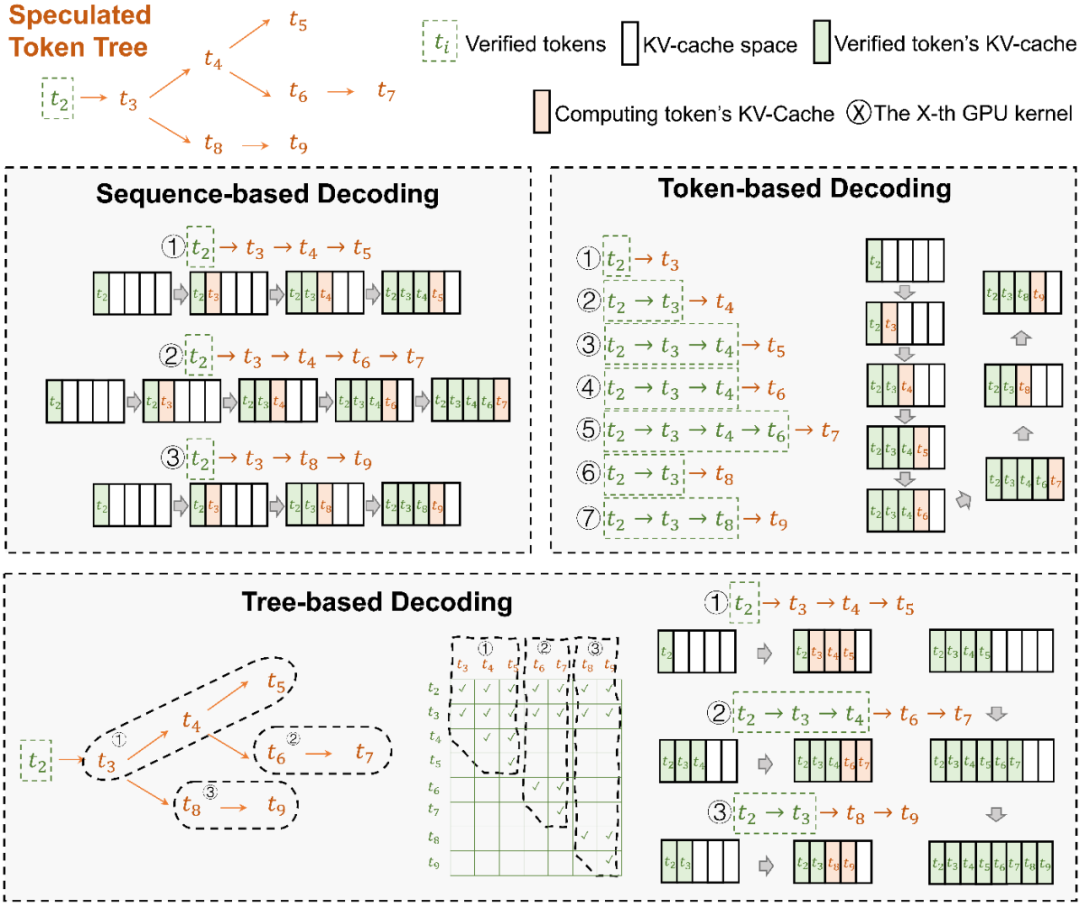
▲ Tree-based Decoding示意图
大规模LLM和小规模SSM协同工作
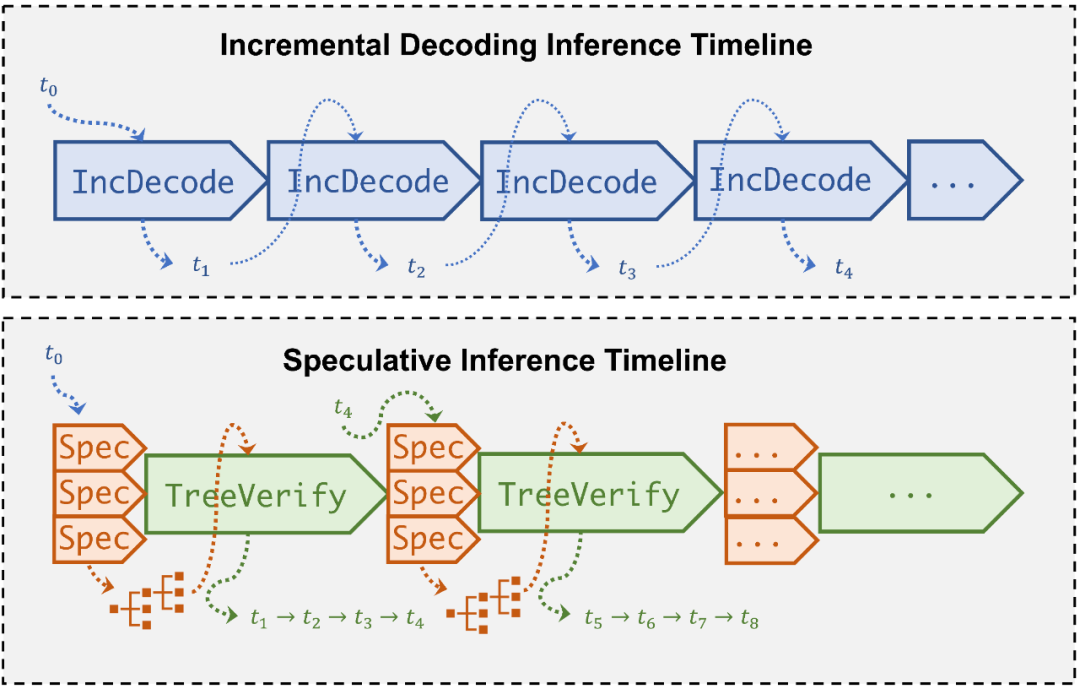
▲ Speculative Inference执行Timeline对比
大规模的 LLM 在参数量上通常可以达到小规模 SSM 的几十倍甚至上百倍,而 SSM 相比于 LLM,在推理速度上,基于通常的系统实现,也有数倍到数十倍的性能优势,SpecInfer 结合了 SSM 极低的推理延迟以及 LLM 的并行验证能力,大幅降低了较为耗时的 LLM 推理次数,最终可以在保证推理结果质量的情况下显著提升模型推理速度。

系统实现
SpecInfer 基于 FlexFlow 系统实现,支持用户自定义模型结构,导入模型参数,兼容主流深度学习框架的 operator 或 layer 抽象,现已支持常规的 GPT、LLaMA 等多种主流基础模型。值得注意的是,FlexFlow 是一款面向分布式场景的深度学习系统,由来自 CMU、Stanford、MIT、NVIDIA 等机构的研究人员共同维护,是机器学习系统领域最早提出 “自动并行” 的工作之一 (MLSys’19, ICML’18) [2,3],也是最早将计算图优化以及自动并行优化集成进行联合优化的工作 (Unity, OSDI’22) [4]。
借助于 FlexFlow 的自动并行能力,SpecInfer 可以自动完成大规模 LLM 的最优分布式部署。与此同时,SpecInfer 还可以支持 Offloading 操作,以较低的成本扩展模型的规模。SpecInfer 通过独特的「投机式推理」机制,可以大幅降低 LLM 所需的推理步数,从而减小分布式场景的网络通信开销,缓解 Offloading 场景下的 PCIe 传输带宽瓶颈。

实验结果

▲ 端到端推理延迟
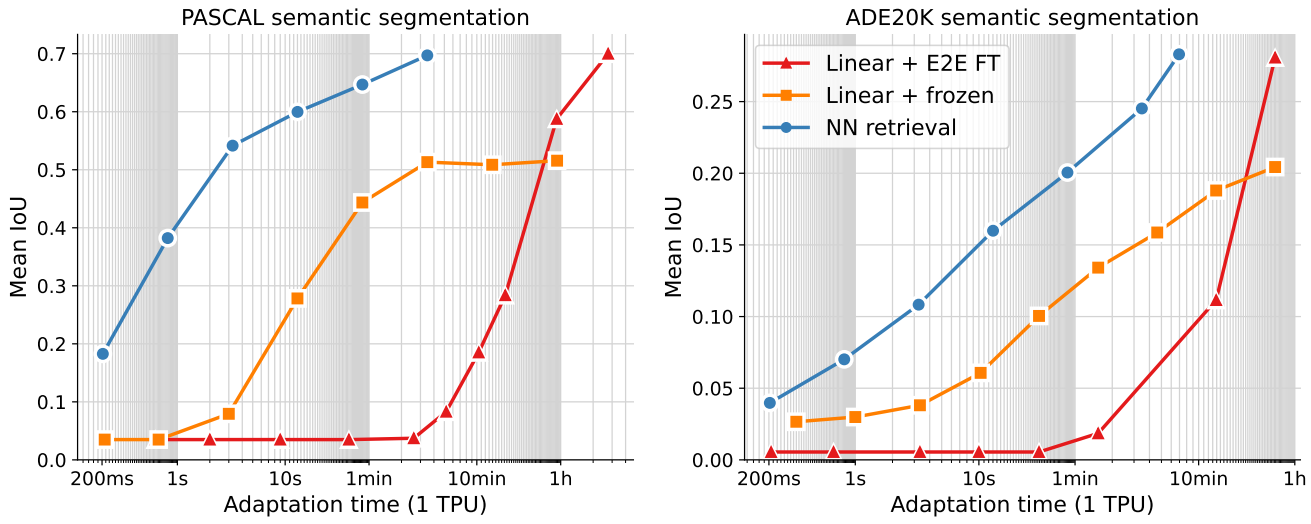
端到端实验:使用 LLaMA-7B 作为 LLM,LLaMA-160M 作为 SSM,在五个对话数据集上进行了测试,相比于依赖于增量式解码的 LLM,SpecInfer 可以使推理延迟降低 1.9-2.8 倍。
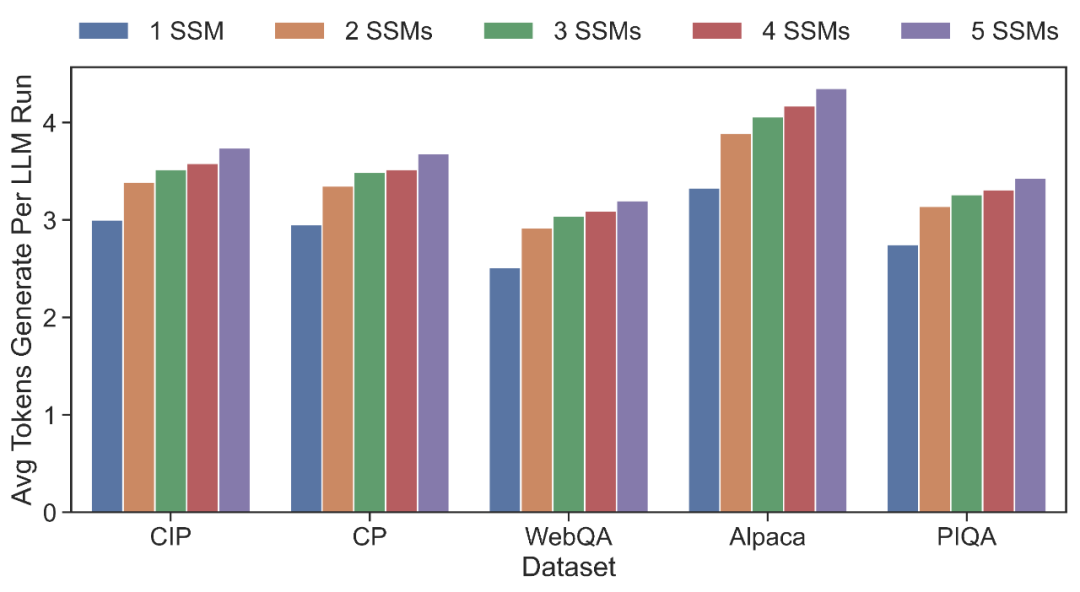
▲ 单次推理平均步长(LLM:OPT-13B + SSMs:OPT-125M)

▲ 单次推理平均步长(LLM:LLaMA-7B + SSMs:LLaMA-160M)
匹配长度测试:分别使用 OPT 和 LLaMA 系列模型,测试 SpecInfer 中 LLM 的平均验证通过序列长度,可以看出,随着 SSM 数量的提升,在各个对话数据集上,LLM 的验证通过长度均会得到提升,以 5 个 SSM 为例,OPT 和 LLaMA 在 5 个数据集上平均可达 3.68 和 2.67,相比于仅使用单一 SSM,分别提升 26.4% 和 24.8%。
更多更详细的实验结果可以参考论文原文:
https://arxiv.org/abs/2305.09781

总结
SpecInfer 是首个基于「推测式解码」的分布式 LLM 推理引擎,通过集成多个小模型,以及基于 token tree 的原创系统实现优化,可以帮助现有的主流 LLM 减少内存访问需求,实现两到三倍的无损推理加速,大幅降低推理成本。

作者介绍

SpecInfer 项目的指导老师是 Zhihao Jia,他目前在卡耐基梅隆大学计算机学院担任助理教授。他的研究兴趣主要包括面向机器学习、量子计算以及大规模数据分析的系统研究。此前他曾毕业于清华大学的姚班,博士毕业于 Stanford 大学,师从 Alex Aiken 和 Matei Zaharia,曾获 Stanford Arthur Samuel Best Doctoral Thesis Award,NSF CAREER Asward 以及来自 Amazon, Google, Meta, Oracle, 以及 Qualcomm 的多项研究奖项,个人主页:https://www.cs.cmu.edu/~zhihaoj2/。
孵化 SpecInfer 项目的主要是 CMU 的 Catalyst Group 实验室,该实验室由 Zhihao Jia 与 Tianqi Chen(陈天奇)在 CMU 共同主持,致力于集成来自于机器学习算法、系统、硬件等多方面的优化技术,构造自动化的机器学习系统。此前,该实验室还推出了 MLC-LLM [5] 等开源项目,推进 LLM 大模型相关系统的研究和应用。实验室主页:https://catalyst.cs.cmu.edu。

论文的共同一作分别是 Xupeng Miao(博士后研究员),Gabriele Oliaro(博一)以及 Zhihao Zhang(博一),均来自于 CMU Catalyst Group 团队。其中,Xupeng Miao 博士毕业于北京大学,主要研究方向包括机器学习系统、数据管理和分布式计算,曾获 VLDB2022 最佳可扩展数据科学论文奖、2022 年 ACM 中国优博奖、2022 年世界人工智能大会(WAIC)云帆奖等荣誉,个人主页:https://hsword.github.io。

参考文献
[1] Gudibande, A., Wallace, E., Snell, C., Geng, X., Liu, H., Abbeel, P., Levine, S., & Song, D. (2023). The False Promise of Imitating Proprietary LLMs.
[2] Jia, Z., Lin, S., Qi, C. R., & Aiken, A. (2018, July). Exploring Hidden Dimensions in Parallelizing Convolutional Neural Networks. In ICML (pp. 2279-2288).
[3] Jia, Z., Zaharia, M., & Aiken, A. (2019). Beyond Data and Model Parallelism for Deep Neural Networks. Proceedings of Machine Learning and Systems, 1, 1-13.
[4] Unger, C., Jia, Z., Wu, W., Lin, S., Baines, M., Narvaez, C. E. Q., ... & Aiken, A. (2022). Unity: Accelerating {DNN} Training Through Joint Optimization of Algebraic Transformations and Parallelization. In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) (pp. 267-284).
[5] https://github.com/mlc-ai/mlc-llm
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·