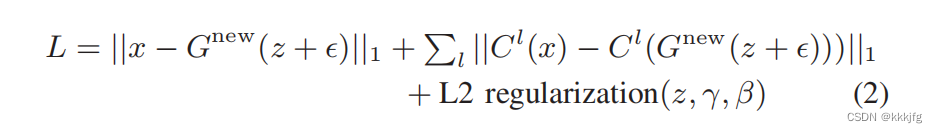作者:黄娘球本文约1600字,建议阅读5分钟
本文澄清易混淆基础概念、推导公式为主,回顾强化学习基础知识。ChatGPT已成为继AlphaGo之后的社会现象级人工智能,引发了大模型研究的热潮。戴琼海院士提出,五年后大模型将成为AI的"操作系统"。ChatGPT良好的用户体验,以RLHF(Reinforcement Learning from Human Feedback)为代表Alignment技术,功不可没。
(注:Alignment对齐使得机器学习系统的目标与人类真实的设计意图相吻合,并且更安全、可信、可靠。)
RLHF的核心属于强化学习的范畴,强化学习在大模型时代仍然是非常重要的。此文以澄清易混淆基础概念、推导公式为主,回顾强化学习基础知识。
Lecture 1 基本概念
强化学习是智能体在与环境的互动当中为了达成目标而进行的学习过程。强化学习涉及以下基本的概念:
策略(Policy): 智能体(agent)的行为模型(behavior model), 从状态(state/observation)到动作(action)的映射。
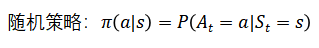
价值函数(Value Function): 在特定策略 下,未来奖励(reward)的期望加权和(expected discounted sum)。在策略
下,未来奖励(reward)的期望加权和(expected discounted sum)。在策略 下状态
下状态 的价值即回报(return)的数学期望,公式:
的价值即回报(return)的数学期望,公式:


动作价值函数(Q-function):根据策略 π,在状态 s 时执行动作 a 的价值,公式:


 预测下一状态:
预测下一状态:
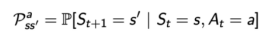
 预测下一奖励:
预测下一奖励:
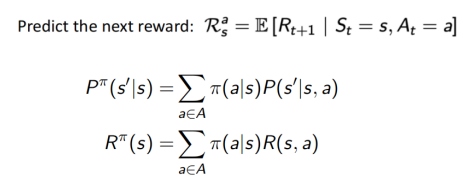
贝尔曼方程(Bellman equation)公式推导:
贝尔曼方程(Bellman Equation)由美国统计学家、数学家和工程师理查·贝尔曼(Richard Bellman)在20世纪20年代提出。贝尔曼方程是强化学习的基本方程,用于计算给定一定状态、动作的期望回报,并可用于寻找问题的最优策略。
1. 在MDP中的状态-价值函数 State-value function 
 为在策略
为在策略 下,从状态s开始的期望回报:
下,从状态s开始的期望回报:
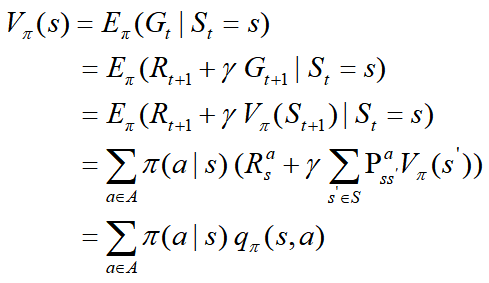
2. 动作价值函数(action-value function):

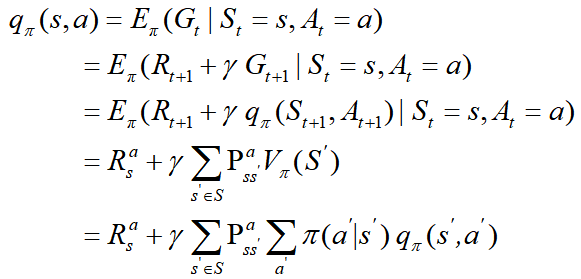
Lecture 2 预测与控制 (求解已知的MDP)
(prediction and control)for solving a known MDP
强化学习在求解已知的MDP 中主要有预测和控制两种应用。
1. 预测(Prediction)
给定策略 下,评估状态的价值, 即策略评估(policy evaluation)
下,评估状态的价值, 即策略评估(policy evaluation)
输入:


输出:价值函数 
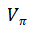
方法:对贝尔曼期望方程进行迭代 iteration on Bellman expectation backup,同步备份synchronous backup

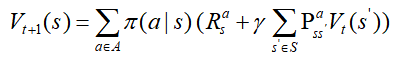
收敛:
控制 control : 寻找最优策略
输入:
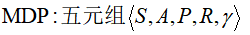
输出:最优价值函数 和最优策略
和最优策略
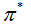
2. MDP中的控制 (MDP Control)
MDP中控制的目标是计算最优策略,
 。
。
1) 策略迭代 policy iteration
策略评估(价值预测) policy evaluation (value prediction) + 策略改进 policy improvement
这两步重复迭代直到策略收敛:
a. 评估策略π :给定目前策略π
:给定目前策略π ,计算价值函数value function
,计算价值函数value function
b. 通过对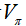
 的贪婪算法改进策略 improve the policy by acting greedily with respect to
的贪婪算法改进策略 improve the policy by acting greedily with respect to
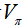
 。
。
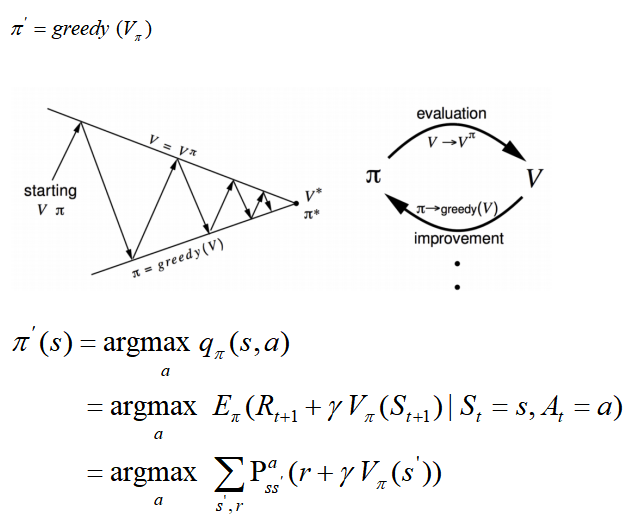
策略改进policy improvement
a. 计算策略 π的状态-动作价值函数
π的状态-动作价值函数
b. 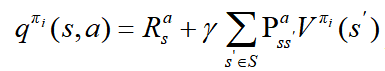
 对所有
对所有 的状态
的状态 计算新的策略
计算新的策略
 ,即:
,即: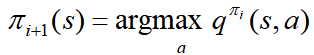 。
。

2) 价值迭代 Value iteration
找到最优的价值函数 + 策略提取 (one policy extraction)
达到最优价值后,使用策略提取以检索(retrieve)得到最优策略
目标:找到最优策略 π
π
方法:对贝尔曼最优方程(Bellman optimality backup)进行迭代
算法:


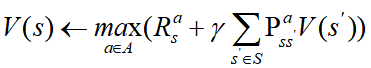
一旦价值函数达到了最优,由其而来的策略同样也是最优(收敛)的。
3. 动态规划算法总结

策略迭代与价值迭代的对比:
策略迭代:策略评估和策略改进(更新)的迭代
价值迭代:给定一个已知的MDP,计算最优价值函数
① 贝尔曼最优方程(Bellman optimality backup)的迭代

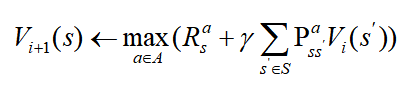
② 价值迭代后,再检索(retrieve)得到最优策略

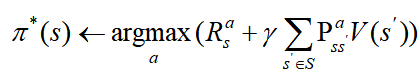
本文主要以周博磊的课程PPT为基础,并参考了Richard Sutton、DeepMind & UCL、董豪《深度强化学习:基础、研究与应用》以及许志钦等课程资料。内容包含了笔者对这些材料的理解和公式推导。由于篇幅所限,笔记中只保留了个人认为需要重点理解的概念和公式,因此具有主观性。另外,原始笔记是英文的,翻译术语有不周之处,欢迎批评指正。
编辑:于腾凯
校对:林亦霖
作者简介

黄娘球,广东财经大学统计与数学学院,21级统计学硕士研究生,一个对AI各领域有广泛兴趣的技术狂热者,感兴趣的领域包括:Explainable AI,AI Safety and Alignment,AIGC, LLMs。读研前曾是广东以色列理工学院GTIIT(以色列理工学院(Technion, Israel)中国校区)的Staff。目前是数据派THU研究组志愿者,AI TIME学术部志愿者。且在安远AI担任线上作者,职责包括帮助修改、审核文章,提供AI Safety and Alignment领域内的原创稿件。主持2022年广东省科技创新战略专项资金(攀登计划)资助项目,可解释神经网络赋能政府统计工作的可行性研究。乐于分享交流,思想碰撞。始终保持高度的学习热情,享受潜心科研的过程。
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。
往期回顾


 点击“阅读原文”加入组织~
点击“阅读原文”加入组织~