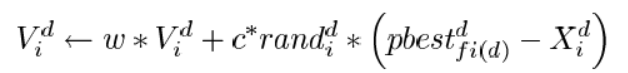粒子群算法介绍、matlab实现及相关改进
-
参数
-
N:粒子数量
⟹ \Longrightarrow ⟹一般取[20,40],对于较难或者特定类别的问题,可以取[100,200];
-
D:决策变量维度
-
iter_Max:最大迭代次数
-
X:决策变量
-
V:每个粒子个体对应速度集合
-
x j,i L x_{\text{j,i}}^L xj,iL, x j,i U x_{\text{j,i}}^U xj,iU:决策变量 边界
-
v j,i L v_{\text{j,i}}^L vj,iL, v j,i U v_{\text{j,i}}^U vj,iU:速度边界
⟹ \Longrightarrow ⟹vmax较大时,探索能力强,但是粒子容易飞过最优解;
⟹ \Longrightarrow ⟹vmax较小时,开发能力强,但是容易陷入局部最优解;
⟹ \Longrightarrow ⟹vmax一般设为每一维变脸变化范围的10%~20%;
-
w:惯性权重
⟹ \Longrightarrow ⟹w越大,全局搜索能力越强;w越小,局部搜索能力越强。
⟹ \Longrightarrow ⟹根据经验,一般最大取0.9,最小取0.4
-
c1:学习因子1 ⟹ \Longrightarrow ⟹个人认知学习因子,反映了粒子对自身历史经验的记忆和会议,代表粒子向自身历史最佳位置逼近的趋势。
-
c2:学习因子2 ⟹ \Longrightarrow ⟹个人认知学习因子,反映了粒子建协同合作与知识共享的群体历史经验,代表粒子向群体或邻近历史最佳位置逼近的趋势。
上述三个参数均可以采取不同的方式进行设置,在后面的算法改进中,会详细介绍。
-
r1、r2:两个位于0~1之间的随机数,用来增加系统的粒子运动趋势的随机性。
-
-
算法流程
-
参数及粒子初始化
-
进入迭代更新粒子的位置和速度(可以按照标号4中的不同方法进行更新)
-
更新个体最优解和全局最优解
在一迭代次数下,每更新一个粒子的位置和速度,便更新一次最优解(亲测,要是一次性更新的话,很难找到全局最优解)
-
完成迭代,对结果进行展示
-
-
流程总结

-
不同方法对于粒子群算法的改进
-
基础粒子群算法
v i,j ( t + 1 ) = v i,j ( t ) + c 1 r 1 [ p i,best ( t ) − x i,j ( t ) ] + c 2 r 2 [ g i,best ( t ) − x i,j ( t ) ] x i,j ( t + 1 ) = x i,j ( t ) + v i,j ( t + 1 ) v_\text{i,j}(t+1) = v_\text{i,j}(t)+c_1r_1[p_\text{i,best}(t)-x_\text{i,j}(t)]+c_2r_2[g_\text{i,best}(t)-x_\text{i,j}(t)]\\ x_\text{i,j}(t+1) = x_\text{i,j}(t)+v_\text{i,j}(t+1) vi,j(t+1)=vi,j(t)+c1r1[pi,best(t)−xi,j(t)]+c2r2[gi,best(t)−xi,j(t)]xi,j(t+1)=xi,j(t)+vi,j(t+1)- 优点:参数少,速度快,逻辑简单,编写代码方便
- 缺点:全局搜索能力差,容易陷入局部最优解,搜索精度低
-
标准粒子群算法
ω = ω max − ( ω max − ω min ) iter iter_Max v i,j ( t + 1 ) = ω ⋅ v i,j ( t ) + c 1 r 1 [ p i,best ( t ) − x i,j ( t ) ] + c 2 r 2 [ g i,best ( t ) − x i,j ( t ) ] x i,j ( t + 1 ) = x i,j ( t ) + v i,j ( t + 1 ) ω max = 0.9 ; ω max = 0.4 ; \begin{array}{l} \omega = \omega_{\text{max}}-(\omega_\text{max}-\omega_\text{min})\displaystyle\frac{\text{iter}}{\text{iter\_Max}}\\ v_\text{i,j}(t+1) = \omega\cdot v_\text{i,j}(t)+c_1r_1[p_\text{i,best}(t)-x_\text{i,j}(t)]+c_2r_2[g_\text{i,best}(t)-x_\text{i,j}(t)]\\ x_\text{i,j}(t+1) = x_\text{i,j}(t)+v_\text{i,j}(t+1)\\ \omega_\text{max} = 0.9;\\ \omega_\text{max} = 0.4; \end{array} ω=ωmax−(ωmax−ωmin)iter_Maxitervi,j(t+1)=ω⋅vi,j(t)+c1r1[pi,best(t)−xi,j(t)]+c2r2[gi,best(t)−xi,j(t)]xi,j(t+1)=xi,j(t)+vi,j(t+1)ωmax=0.9;ωmax=0.4;
通过增加随迭代次数改变而改变的惯性因子,使得开始时具有较强的全局搜索能力,后期具备较强的局部搜索能力。 -
压缩因子粒子群算法
ω = 2 ∣ 2 − φ − φ 2 − 4 φ ∣ v i,j ( t + 1 ) = ω ⋅ v i,j ( t ) + c 1 r 1 [ p i,best ( t ) − x i,j ( t ) ] + c 2 r 2 [ g i,best ( t ) − x i,j ( t ) ] x i,j ( t + 1 ) = x i,j ( t ) + v i,j ( t + 1 ) φ = c 1 + c 2 \begin{array}{l} \omega = \displaystyle\frac{2}{|2-\varphi-\sqrt{\varphi^2-4\varphi}|}\\ v_\text{i,j}(t+1) = \omega\cdot v_\text{i,j}(t)+c_1r_1[p_\text{i,best}(t)-x_\text{i,j}(t)]+c_2r_2[g_\text{i,best}(t)-x_\text{i,j}(t)]\\ x_\text{i,j}(t+1) = x_\text{i,j}(t)+v_\text{i,j}(t+1)\\ \varphi = c_1+c_2 \end{array} ω=∣2−φ−φ2−4φ∣2vi,j(t+1)=ω⋅vi,j(t)+c1r1[pi,best(t)−xi,j(t)]+c2r2[gi,best(t)−xi,j(t)]xi,j(t+1)=xi,j(t)+vi,j(t+1)φ=c1+c2
通过这种方式,收敛速度更快 -
结合自适应惯性权重的混合粒子群算法
ω = ( ω max − ω min ) ⋅ tan ( 0.875 ( 1 − iter iter_Max ) k ) + ω min ; v i,j ( t + 1 ) = ω ⋅ v i,j ( t ) + c 1 r 1 [ p i,best ( t ) − x i,j ( t ) ] + c 2 r 2 [ g i,best ( t ) − x i,j ( t ) ] ; x i,j ( t + 1 ) = x i,j ( t ) + v i,j ( t + 1 ) ; k = 0.6 ; 控制因子,根据经验,一般取该值 \begin{array}{l} \omega = (\omega_\text{max}-\omega_\text{min})\cdot\tan(0.875(1-\frac{\text{iter}}{\text{iter\_Max}})^k)+\omega_\text{min};\\ v_\text{i,j}(t+1) = \omega\cdot v_\text{i,j}(t)+c_1r_1[p_\text{i,best}(t)-x_\text{i,j}(t)]+c_2r_2[g_\text{i,best}(t)-x_\text{i,j}(t)];\\ x_\text{i,j}(t+1) = x_\text{i,j}(t)+v_\text{i,j}(t+1);\\ k = 0.6;\ \ \ \ \ \ 控制因子,根据经验,一般取该值 \end{array} ω=(ωmax−ωmin)⋅tan(0.875(1−iter_Maxiter)k)+ωmin;vi,j(t+1)=ω⋅vi,j(t)+c1r1[pi,best(t)−xi,j(t)]+c2r2[gi,best(t)−xi,j(t)];xi,j(t+1)=xi,j(t)+vi,j(t+1);k=0.6; 控制因子,根据经验,一般取该值
该算法将模拟退火中的Metropolis准则引入到了粒子群算法中,极大程度的避免寻优过程中陷入局部最优问题,而且收敛速度快,稳定性好。 -
动态调整惯性权重改进粒子群算法(IDWPSO)
ω = ω min + ( ω m a x − ω m i n ) ⋅ e − iter iter_Max + σ ⋅ b e t a r a n d ( p , q ) ; v i,j ( t + 1 ) = ω ⋅ v i,j ( t ) + c 1 r 1 [ p i,best ( t ) − x i,j ( t ) ] + c 2 r 2 [ g i,best ( t ) − x i,j ( t ) ] ; x i,j ( t + 1 ) = x i,j ( t ) + v i,j ( t + 1 ) ; σ = 0.1 ; 惯性调整因子,根据经验,一般取该值 p = 1 ; q = 3 ; \begin{array}{l} \omega = \omega_\text{min}+(\omega_{max}-\omega_{min})\cdot e^{-\frac{\text{iter}}{\text{iter\_Max}}}+\sigma\cdot betarand(p,q);\\ v_\text{i,j}(t+1) = \omega\cdot v_\text{i,j}(t)+c_1r_1[p_\text{i,best}(t)-x_\text{i,j}(t)]+c_2r_2[g_\text{i,best}(t)-x_\text{i,j}(t)];\\ x_\text{i,j}(t+1) = x_\text{i,j}(t)+v_\text{i,j}(t+1);\\ \sigma = 0.1;\ \ \ \ \ \ 惯性调整因子,根据经验,一般取该值\\ p = 1;\\ q = 3;\\ \end{array} ω=ωmin+(ωmax−ωmin)⋅e−iter_Maxiter+σ⋅betarand(p,q);vi,j(t+1)=ω⋅vi,j(t)+c1r1[pi,best(t)−xi,j(t)]+c2r2[gi,best(t)−xi,j(t)];xi,j(t+1)=xi,j(t)+vi,j(t+1);σ=0.1; 惯性调整因子,根据经验,一般取该值p=1;q=3;
使得 ω \omega ω随着迭代次数的增加而非线性减小,同时在最后面添加一个生成贝塔分布规律的随机数,使得算法在迭代后期可以增加算法的全局搜索能力,减少算法陷入局部最优解的可能性。 -
不同改进算法的横向性能对比
为了方便比较不同算法在面对同一优化问题时性能表现,这里针对某一优化问题采用不同的方法进行500次求解,具体数据见下两表:
-
| 方法 | 迭代次数平均值 | 迭代次数方差 | 运行时间平均值 | 运行时间方差 | 最优适应度平均值 | 最优适应度方差 | 单次迭代时间 |
|---|---|---|---|---|---|---|---|
| 基础粒子群算法 | 93 | 3168 | 0.1476 | 0.00008326 | -6.40186 | 0.00001752 | 0.0015871 |
| 标准粒子群 | 134 | 2178 | 0.1545 | 0.00003303 | -6.40720 | 0.00000029 | 0.0011530 |
| 压缩因子粒子群算法 | 92 | 3294 | 0.1492 | 0.00004816 | -6.40126 | 0.00002318 | 0.0016217 |
| 自适应惯性权重混合粒子群算法 | 146 | 2811 | 1.7072 | 0.0025975 | -6.39763 | 0.0000888 | 0.0116931 |
| IDWPSO | 187 | 0 | 1.3836 | 0.00371457 | -6.40611 | 0.00000191 | 0.0073989 |
P.S. 上述数据转载自智能算法之粒子群算法及改进
运行效率排序:
压缩因子粒子群算法 > 基础粒子群算法 > 标准粒子群 > 自适应惯性权重混合粒子群算法 > I D W P S O 压缩因子粒子群算法>基础粒子群算法>标准粒子群>自适应惯性权重混合粒子群算法>IDWPSO 压缩因子粒子群算法>基础粒子群算法>标准粒子群>自适应惯性权重混合粒子群算法>IDWPSO
寻找最优解速度排序:
基础粒子群算法 > 压缩因子粒子群算法 > 标准粒子群 > I D W P S O > 自适应惯性权重混合粒子群算法 基础粒子群算法>压缩因子粒子群算法>标准粒子群>IDWPSO>自适应惯性权重混合粒子群算法 基础粒子群算法>压缩因子粒子群算法>标准粒子群>IDWPSO>自适应惯性权重混合粒子群算法
单次迭代时间排序:
标准粒子群 > 基础粒子群算法 > 压缩因子粒子群算法 > I D W P S O > 自适应惯性权重混合粒子群算法 标准粒子群>基础粒子群算法>压缩因子粒子群算法>IDWPSO>自适应惯性权重混合粒子群算法 标准粒子群>基础粒子群算法>压缩因子粒子群算法>IDWPSO>自适应惯性权重混合粒子群算法
寻找最优解能力:
自适应惯性权重混合粒子群算法 > 压缩因子粒子群算法 > 基础粒子群算法 > I D W P S O > 标准粒子群 自适应惯性权重混合粒子群算法>压缩因子粒子群算法>基础粒子群算法>IDWPSO>标准粒子群 自适应惯性权重混合粒子群算法>压缩因子粒子群算法>基础粒子群算法>IDWPSO>标准粒子群
综合以上考虑,在使用粒子群算法时:
- 时间要求不高:采用自适应惯性权重混合粒子群算法(能有效避免局部最优解)和IDWPSO;
- 时间要求比较高时:采用压缩因子粒子群算法或者标准粒子群算法
- 示例代码
close all
clear
clcN = 50; % 粒子个数
D = 10; % 决策变量维度
X_Max = 20; X_Min = -20; % 决策变量上下限
V_Max = (X_Max - X_Min) * 0.15; V_Min = -V_Max; % 速度上下限
w_Max = 0.9; w_Min = 0.4; % 惯性因子上下限
c1 = 1.5; c2 = 1.5; % 两个学习因子
iter_Max = 1000; % 最大迭代次数
WaitbarInter = iter_Max / 100; % 一个和进度条有关的参数% 粒子初始化
X = X_Min + (X_Max - X_Min) .* rand(N, D);
V = V_Min + (V_Max - V_Min) .* rand(N, D);% 写入当前全局最优解和个体最优解
GBestFitness = zeros(1, iter_Max + 1);
PBestFitness = zeros(N, 1);
PBest = X;for i = 1:NPBestFitness(i) = Fitness(X(i, :));
end[GBestFitness(1), GBestIndex] = min(PBestFitness);
GBest = PBest(GBestIndex, :);tic
h = waitbar(0, ['已完成:0% 运算中...用时:', num2str(toc)]);for iter = 1:iter_Max% 初始化当前迭代次数下的最优解CurrentIterGbest = GBest;CurrentIterGbestFitness = GBestFitness(iter);k = 0.6; % 控制因子,一般取0.6w = (w_Max - w_Min) * tan(0.875 * (1 - (iter / iter_Max)^k)) + w_Min;for i = 1:N% 更新个体的位置和速度V(i, :) = w * V(i, :) + c1 * rand * (PBest(i, :) - X(i, :)) + c2 * rand * (CurrentIterGbest - X(i, :));X(i, :) = X(i, :) + V(i, :);% 边界条件限制[X(i, :), V(i, :)] = BoundaryLimit(X(i, :), V(i, :), X_Max, X_Min, V_Max, V_Min);% 计算当前迭代次数下当前粒子的适应度CurrentFitness = Fitness(X(i, :));% 更新当前迭代次数下该粒子的最优解!!!% 事实证明,粒子个体最优解的更新应该在一个粒子位置苏都更新完后立即更新!!!% 若在当前迭代次数下所有粒子的位置和速度更新完毕后,再更新个体最优解,那么及其难以收敛!!!if CurrentFitness < PBestFitness(i)PBestFitness(i) = CurrentFitness;PBest(i, :) = X(i, :);% 更新当前迭代次数下的最优解if CurrentIterGbestFitness > CurrentFitnessCurrentIterGbestFitness = CurrentFitness;CurrentIterGbest = X(i, :);endendend% 依据当前迭代次数下的最优解更新全局最优解GBest = CurrentIterGbest;GBestFitness(iter + 1) = CurrentIterGbestFitness;% 展示进度条if mod(iter, WaitbarInter) == 0waitbar(iter / iter_Max, h, ['已完成:' num2str(iter / iter_Max * 100) ...'% 运算中...用时:', num2str(toc),'/',num2str(toc/(iter / iter_Max))])endendclose(h)% 结果展示
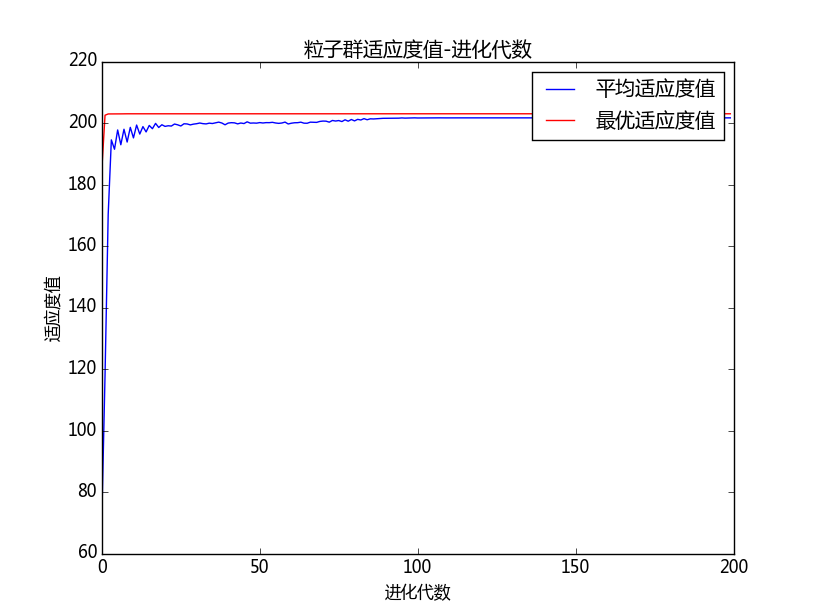
semilogy(GBestFitness(1:iter - 1), 'Color', 'r', 'linewidth', 1.2)
title('Convergence Curve')
xlabel('Iteration');
ylabel('Best score obtained so far');
axis tight
grid on
box on
legend('PSO')
display(['The best solution obtained by PSO is : ', num2str(GBest)]);
display(['The best optimal value of the objective funciton found by PSO is : ', num2str(GBestFitness(iter - 1))]);% 目标函数
function result = Fitness(X)result = sum(X.^2);end% 边界限制函数
function [result_X, result_V] = BoundaryLimit(X, V, X_Max, X_Min, V_Max, V_Min)for i_temp = 1:length(X(:, 1))if X(i_temp) > X_MaxX(i_temp) = X_Max;endif X(i_temp) < X_MinX(i_temp) = X_Min;endendfor i_temp = 1:length(V(:, 1))if V(i_temp) > V_MaxV(i_temp) = V_Max;endif V(i_temp) < V_MinV(i_temp) = V_Min;endendresult_X = X;result_V = V;end%% 关于粒子群算法的改进方法%% 1.基础粒子群算法 基本不用,效果太差
% V(i, :) = V(i, :) + c1 * rand * (PBest(i, :) - X(i, :)) + c2 * rand * (CurrentIterGbest - X(i, :));
% X(i, :) = X(i, :) + V(i, :);%% 2.标准粒子群算法 常用的粒子群更新方法
% w = w_Max - (w_Max - w_Min) * iter / iter_Max;
% V(i, :) = w * V(i, :) + c1 * rand * (PBest(i, :) - X(i, :)) + c2 * rand * (CurrentIterGbest - X(i, :));
% X(i, :) = X(i, :) + V(i, :);%% 3.压缩因子粒子群算法 需要迭代的次数更多,全局搜索性更高
% phi = c1 + c2; % 压缩因子粒子群算法相关参数
% lambda = 2/abs(2-phi-sqrt(phi^2-4*phi)); % 压缩因子粒子群算法相关参数
% lambda = 2/abs(2-phi-sqrt(phi^2-4*phi));
% V(i, :) = lambda * V(i, :) + c1 * rand * (PBest(i, :) - X(i, :)) + c2 * rand * (CurrentIterGbest - X(i, :));
% X(i, :) = X(i, :) + V(i, :);%% 4.结合自适应惯性权重的混合粒子群算法(上面所使用的)
% 结合了模拟退火的思想(运用了Metropolis准则),增加了全局搜索能力
% k = 0.6; % 控制因子,一般取0.6
% w = (w_Max-w_Min)*tan(0.875*(1-(iter/iter_Max)^k))+w_Min;
% V(i, :) = w * V(i, :) + c1 * rand * (PBest(i, :) - X(i, :)) + c2 * rand * (CurrentIterGbest - X(i, :));
% X(i, :) = X(i, :) + V(i, :);%% 5.动态调整惯性权重改进粒子群算法(IDWPSO)
% sigma = 0.1; % 惯性调整因子
% p = 1; q = 3; % 两个beta分布的参数
% w = w_Min + (w_Max-w_Min)*exp(-iter/iter_Max)+sigma*betarnd(p,q);