安装:
在电脑上安装环境依赖

继续安装

把下面这两个文件复制到stable-diffusion-webui 下面
点击A启动器,启动stable-diffusion,然后点击~运行中~

然后看到弹出控制台后,等待~ 第一次会等待时间会稍微久一点(这个是单机版本 所以不联网也可以运行)

然后就可以看到启动起来了~ 可以使用了

使用:
一些好的资源网站:
模型下载(在公司打开时候不要点右上角那个小眼睛 - - ) https://civitai.com/
提示词prompt生成网站 https://promptomania.com/stable-diffusion-prompt-builder/
好的范例的提示词参考网站 https://www.krea.ai/
好的范例的提示词参考网站 https://lexica.art/
模型训练
模型类型:
Textual Inversion、Hypernetwork、Dreambooth 和 LoRA 是四种不同的 Stable Diffusion 模型训练方法
ckpt是大模型,是完整的,pt文件只是其中一个部件,pt文件也有很多种的,embedding是pt文件,hypernetwork也是pt文件,美学梯度也是pt文件但是作用不一样的
Textual Inversion
Textual Inversion(也称为 Embedding)是一种使用文本提示来训练模型的方法。它根据模型引用给定的图像并选择最匹配的图像。你做的迭代越多越好,能够在保持图像质量的同时,快速生成大量图像。这种方法对计算资源要求较低,适用于需要快速生成大量高质量图像的场景。(生成特定角色比如:郭德纲)
训练好是一个PT文件,比较小,就是一个embedding~
特点:
生成的模型文件小,大约几十KB
通常适用于转换图像风格
使用时不需要加载模型,只需要在提词中embeddings中的关键tag
本地训练时对计算资源要求不高
可以通过生成的PT文件覆盖在原有基础上继续训练
模型关键字尽量是不常见的词语
推荐训练人物
训练时关键参数设定:
learning_rate: 0.05:10, 0.02:20, 0.01:60, 0.005:200, 0.002:500, 0.001:3000, 0.0005
number of vectors per token:按图片数量设置(图片数量小于10设置为2,10-30张设置范围2~3,40-60张设置范围5~6,60-100张设置范围8-12,大于100张设置范围12~16)
max_train_steps: 3000(起步3000步)
Hypernetwork
Hypernetwork 是一种使用神经网络来生成模型参数的方法。它可以用来从模型内部找到更多相似的东西,使得生成为近似内容图像, 如果你想训练人脸或特定的风格,并且如果你用Hypernetwork生成的 "一切 "看起来都像你的训练数据,那么Hypernetwork是一个不错的选择。你不能生成混合训练的图像,比如一组非常不同风格各异的猫。不过,你可以使用超网络进行绘画,将不同的训练数据纳入一个图像,改变图像的整个输出。(生成特定风格:比如梵高,宫崎骏画风)
特点:
生成的模型文件比Embedding大,大约几十MB
通常训练艺术风格
推荐训练画风
训练时关键参数设定:
learning_rate: 0.000005:1000,0.0000025:10000,0.00000075:20000,0.0000005:30000,0.00000025:-1
prompt template file: 对应风格类型文件可以编辑只留下一个 [fileword],[name] 在那里,删除多余的描述
Dreambooth
Dreambooth 是一种使用少量图像来训练模型的方法,是一种基于深度学习的图像风格转换技术。它可以将一张图片的风格应用到另一张图片上,以生成新的图像,Dreambooth 的一个优点是它可以生成高质量的艺术作品,而无需用户具备专业艺术技能。
训练完会生成一个比较大的ckpt文件,可以让SD直接加载进来~ 只能训练物体,效果比Textual Inversion要好~ 不仅仅是训练了embedding,还训练了扩散模型~ 所以训练效果比Textual Inversion要好~
特点:
模型文件很大,2-4GB
适于训练人脸,宠物和物件
使用时需要 加载模型
可以进行模型融合,跟其他模型文件融合成新的模型
本地训练时需要高显存,>=12GB
推荐训练人物*画风
训练时关键参数:
高学习率和过多的训练步骤将导致过度拟合(换句话说,无论提示如何,模型只能从训练数据生成图像)。
低学习率和过少的步骤会导致学习不足,这是因为模型无法生成训练过的概念。
物件:400步,2e-6
人脸:1500步,1e-6或2e-6
Training Steps Per Image (Epochs):(根据你图片的数量设定,大概值为你想训练的总步数/图片数量)
Sanity Sample Prompt: 是否过度训练参数设定,我们可以加上一些特征从而去判断训练过程中是否出现过度拟合如填入 person of XX red hair (说明:XX替换为你的关键字,我们在这里加入了红头发的特征,如果出训练输出图像出现了非红头发此时我们就知道过度拟合了,训练过度了)
Lora
Lora是一种使用少量图像来训练模型的方法。与 Dreambooth 不同,LoRA 训练速度更快:当 Dreambooth 需要大约二十分钟才能运行并产生几个 GB 的模型时,LoRA 只需八分钟就能完成训练,并产生约 5MB 的模型,推荐使用kohya_ss GUI 进行lora训练。
特点:
模型大小适中,8~140MB
使用时只需要加载对应的lora模型,可以多个不同的(lora模型+权重)叠加使用
可以进行lora模型其他模型的融合
本地训练时需要显存适中,>=7GB
推荐训练人物
Aesthetic Gradients
personalizing text-to-image Generation via Aesthetic Gradients
训练风格上会比Textual Inversion要好~
需要大量的相同美学风格的图片进行训练
训练好的是一个小的pt 文件,但是这个PT文件使用 必须使用在 SD的Open for clip Aesthetic插件里
训练模型:(使用Dreambooth)
1安装dreambooth插件
在扩展里找到插件并安装,然后重启sd
2准备训练图片
1尺寸相同512*512 或其他2的倍数
3在dreambooth里设置
1创建模型

名称:希望训练的模型名称
source chekpoint:训练的原始模型
scheduler 调节器: 选择euler-ancestral
设置好上面的以后,点击create创建~
2选择创建好的模型
下图位置选择好刚创建好的空的模型

3训练设置
开始训练前的参数设置,如果想训练Lora模型就需要勾选Lora
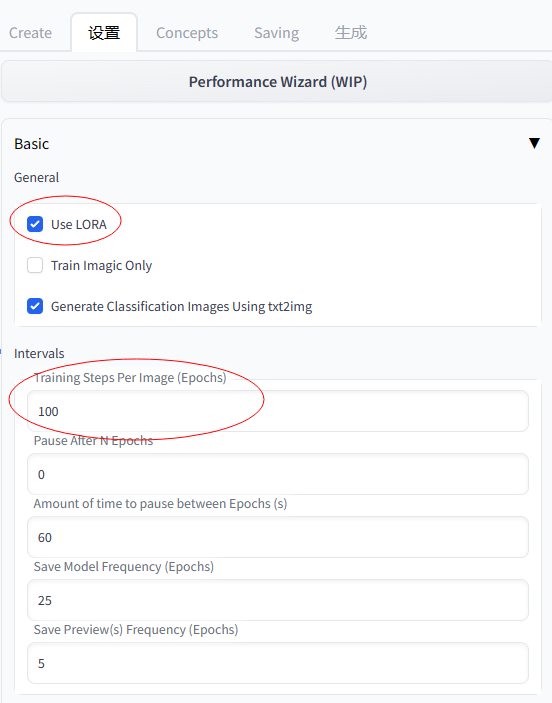


Training Steps Per Image (Epochs):每张图的训练步数,训练图片数量*10
想训练lora模型就需要勾选use lora
learning rate:学习速率 推荐0.0001(值越小速度越慢)

Training Wizard(Person)/Training Wizard(Object/Style)训练角色模型还是场景或物件模型 , 点击对应按钮 会自动设置一些预制的训练步数。
dataset directory:训练目录 填写训练图片的路径(这里图片需要图像需要先进行预处理才行)
训练----图像预处理
instance token:[filewords]
instance prompt:[filewords]
sample image prompt:[filewords]
[filewords]:代表来自数据集图像文件名的单词
classification image Negative prompt:反向提示词
sample Negative Prompt:方向提示词
都设置好后,点击下图按钮进行训练~ training 按钮~

训练完成后,点击下图按钮Generate Ckpt 训练彻底完成~

训练完成~
训练模型:(训练hypernetwork模型)
1 需要训练的图片,需要进行图像预处理 ~

2 创建一个空白的hypernetwork

3 训练参数设置,然后训练~
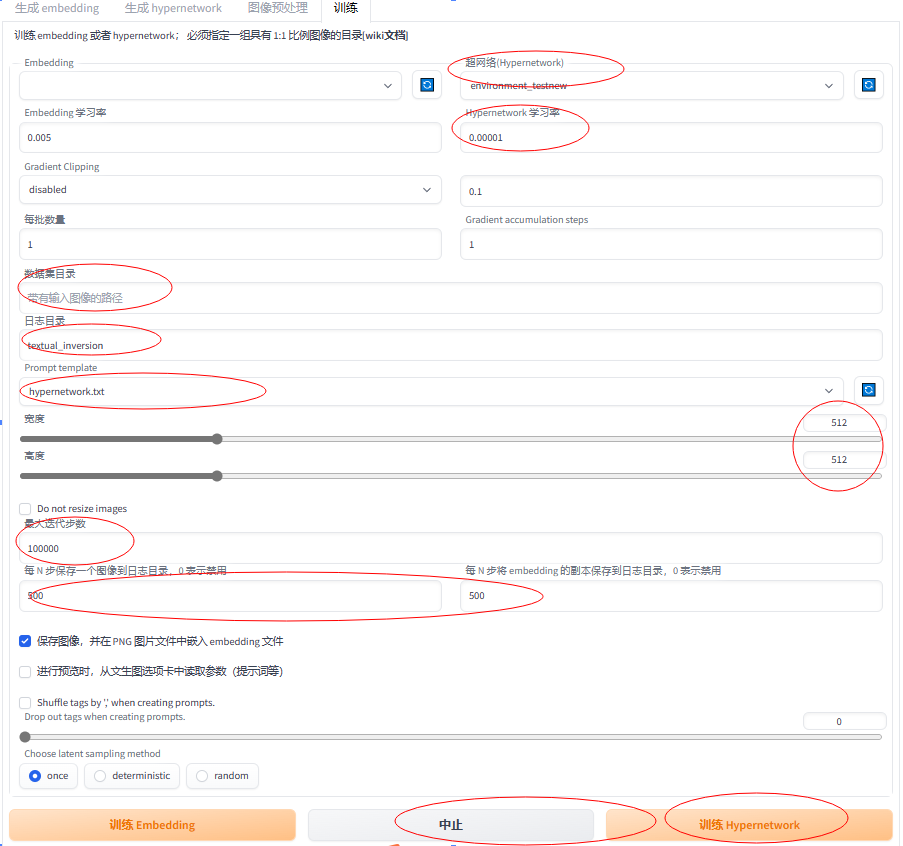
数据集目录:选择数据集的目录(需要训练图片的路径)
日志目录:生成日志的文件目录名字
Prompt template:需要选择hypernetwork (如果是训练embedding模型则选择对应的选项~ )
每N步保存一个图像~ 这个如果是hypernetwork则需要设置的参数大一些~ 因为生成文件比较大
设置好以后点击训练~ 可以中止 也可以继续训练~
训练的时候需要去掉自己设置的VAE
4 训练结束~ 设置sd使用上面训练好的hypernetwork,在sd设置里选~ 下图

5 ~ok enjoy~
训练embedding 模型
1 创建embedding空模型

名称:如果是角色就创建一个角色的名字
初始化文字:可以用*号代替
token向量数:如果训练图片数量不是很多(100以内)设置不超过10就可以~
然后点击生成embedding~ 按钮
2数据集

1选择需要训练模型的基础模型~
2设置训练图片路径和训练后输出图片的路径
3训练的图片尺寸(需要提前设置好 统一尺寸 2的倍数)
可以使用https://www.birme.net/这个网站操作
4勾选生成镜像 和 使用BLIP生成说明文字(如果是hypernetwork就不要勾选这个,而勾选使用deepbooru生成说明文字)
5点击处理~
3训练

注意下训练时候一定要确定VAE文件~
embedding 选择前面创建的embedding模型
prompt template:根据训练内容需求 选择对应的训练魔板

风格模型魔板位置
都设置好然后点击训练embedding就可以了~
训练完成后可以看看下面目录下~ 生成训练的图片效果~ 检验训练效果是否OK

和hypernetwork一样,模型可以训练一半停止,然后再次继续训练~ 也可以针对过去的模型继续训练~
使用stable diffusion制作短视频
使用软件:
1 krita 把视频转成单帧的序列图片
2 stable diffusion 利用ai批量修改图片
3 premierePro 重新把图片导出成视频
虚拟数字人制作
sd mj生成角色图片
chatGPT 生成演讲稿
IIElevenLabs生成音频
DID创建视频
metahuman 创建模型
controlnet 开启多个

图片放大:
1方法一:使用hires.fix

这样的方法更多是类似图片细节的放大~ 但是对于图片放大后的原本缺失细节重绘会稍微差一些
2 发放二:使用图生图,对已有图片进行二次生成并同时修改生成尺寸进行放大
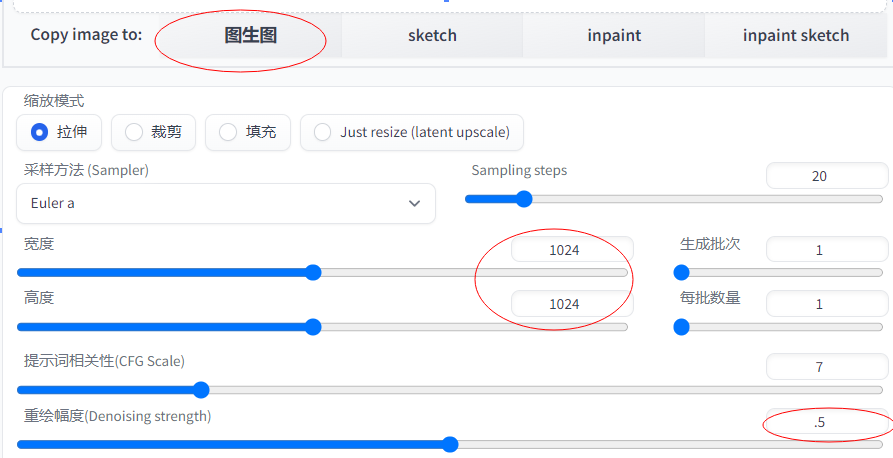
注意图片尺寸需要是原图片需要放大后的尺寸
重绘幅度0.5,ai会自动计算补充放大后的细节。
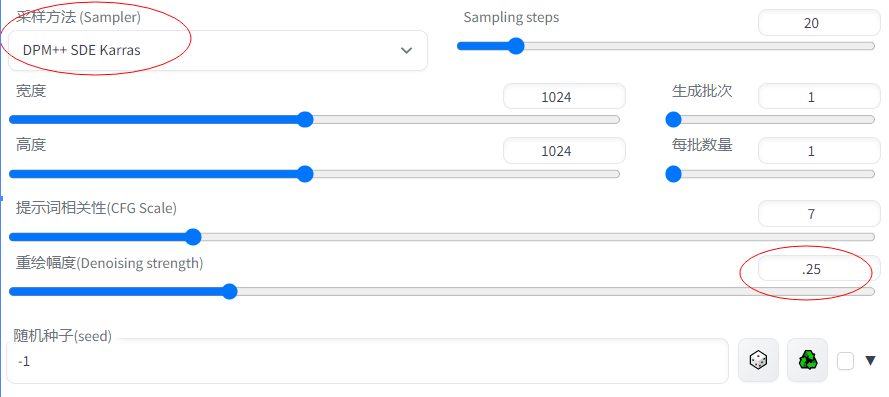
或者使用重绘幅度0.25,然后切换别的采样方式来获得不同的放大后细节的变化~ (因为重绘强度比较低所以ai只会根据不同采样方式的特点来重绘补充放大后的细节部分)
3 方法三:在使用图生图放大后,可以再使用放大功能进行再次放大

如果想放大到原图的4倍,可以先用图生图放到2倍,然后用缩放功能再放大2倍
生成UI界面:

参数:



X/Y/Z plot的使用
X/Y/Z Plot脚本可以实现方便的对比不同的参数间的效果,并生成这样的一张图,方便对比各种参数组合生成图片的效果。
参数:
Draw legend:是否显示标注。
Keep -1 for seeds:每次生成时是否重新随机。按需使用,如果为了横向比较效果,最好不勾选。
Include Sub Images:是否显示单张图。
include Sub Grids: 是否Batch
字符串类型/列表选项类型:
例如Sampler ,你可以设置成Euler a, Euler, LMS, Heun, DPM2, DPM2 a, DPM++ 2S a, DPM++ 2M, DPM++ SDE ,这样配置的效果是按照这9个不同的Sampler进行生成。如果升级到最新版的WebUI的话,也可以点击value输入框右侧的 图标,快速输入所有的选项,再进行编辑。
数值型:这个写法比较灵活,大概有三种:
区间写法1 单调递增1:1-5 = 1, 2, 3, 4, 5
区间写法2 修改默认递增值:
1-5 (+2) = 1, 3, 5
10-5 (-3) = 10, 7
1-3 (+0.5) = 1, 1.5, 2, 2.5, 3
区间写法3 生成范围内n个数值
1-10 [5] = 1, 3, 5, 7, 10
0.0-1.0 [6] = 0.0, 0.2, 0.4, 0.6, 0.8, 1.0
特殊写法:
Prompt S/R:
第一个逗号前是用来匹配的目标字符,后面每个逗号隔开的是需要进行替换的字符,从而组成不同的prompts进行生成
darkness, light, green, heat = 4项组合 : darkness, light, green, heat
darkness,"light, green",heat = 3项组合 : darkness, light, green, heat
其中有一个参数是“提示词顺序”,并声称“给它若干个prompt,它可以给你每一种排列组合情况。”



设置好以后点击 生成图片按钮就可以了~ 生成时间会比较慢

stable Diffusion设置远程访问解决本地算力不足
1在你朋友webui启动器里点开 开放远程连接选项 并启动

2先关掉Stable Diffusion;
找到Stable Diffusion项目代码下的launch.py文件,在第13行的位置,你的应该是这样子:
commandline_args = os.environ.get('COMMANDLINE_ARGS', "")要设置远程访问,只需要改为:
commandline_args = os.environ.get('COMMANDLINE_ARGS', "--listen")因为远程存在安全问题,可以设置密码登录,像下面这样
commandline_args = os.environ.get('COMMANDLINE_ARGS', "--listen --gradio-auth 用户名:密码")重新运行即可
3看下你朋友机器的ip地址 cmd ipconfig
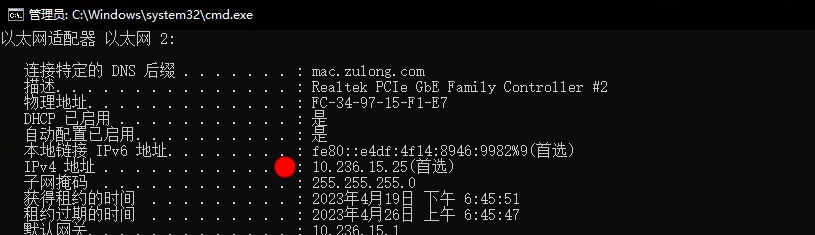
4 在你自己机器的浏览器地址栏上输入 你朋友ip地址+端口号 比如:10.236.15.25:7860
5 enjoy~