目录
一、项目背景
二、数据准备
三、数据预处理及描述性统计
四、数据分析
1.聊天小时、日、月分别汇总分布图
2.聊天时间序列分布图
3.高频词汇统计
4.词云图展示
五、其它探索性分析
一、项目背景
2021年2月20日我和我女朋友第一次见面,之后开启了我们两个人的故事,时隔一年我想将我们的聊天记录提取出来进行简单的数据分析一下。微信里面有2021年4月20日至2022年2月19日的聊天记录,一共十个月的数据。
二、数据准备
在网上有许多文章关于可以找到关于如何将微信里面的聊天记录导出成CSV或者txt格式,大家可以去参考。以下就简单的写一下如何将微信的聊天记录提取出来的步骤:
1.用电脑版微信将手机微信聊天记录备份到电脑上
2.安装模拟器,将手机微信登录到模拟器的微信上(模拟器本身有root权限)
3.然后电脑版微信重新登录,恢复聊天记录到模拟器的微信里
4.模拟器安装RE文件管理器,在文件管理器找到指定文件夹 /data/data/com.tencent.mm/MicroMsg
5.在MicroMsg文件中找到EnMicroMsg.db复制到/mnt/shell/emulated/0/others中,现在访问windows的 C:\Users\你的用户名\Nox_share\OtherShare 获取该数据库文件EnMicroMsg.db
6.找微信的uid,/data/data/com.tencent.mm/shared_prefs/ 找到文件auth_info_key_prefs.xml,找到default_uin后面的数字就是微信UID,模拟器里面可以直接看到IMEI
7.计算数据库查询密码,模拟器IMEI+微信UID在免费MD5在线计算得到的32位小写MD5的前七位就是密码
8.下载 sqlcipher 的软件,输入密码就可以打开 EnMicroMsg.db 数据库了
9.之后再软件上直接导出CSV或者txt格式就行啦
注意:数据库查询密码和微信的版本有关系,不同的坂本解码方法不一样,现在的最新版本 IMEI (手机序列号)为固定值为1234567890ABCDEF,大家可以都去试一下。
三、数据预处理及描述性统计
原始数据一共有22列,74019行,说明我们两在10个月的时间里面发了74018条消息,一共306天,平均每天发了241.89条消息,还处于热恋期,嘿嘿。本文用的python进行的数据分析,并附上代码。
1.要将时间戳转换为北京时间
2.处理图片和链接等非文字聊天记录
…
import pandas as pd
chat = pd.read_csv('D:/chat.csv', sep=',', usecols=[4,6,7,8],encoding="gbk")
chat.head()| isSend | createTime | talker | content | |
|---|---|---|---|---|
| 0 | 1 | 1.629640e+12 | wxid_mbw5g1awfkvj22 | 我看看 |
| 1 | 0 | 1.629640e+12 | wxid_mbw5g1awfkvj22 | 好可怜,有这样的爹 |
| 2 | 0 | 1.629640e+12 | wxid_mbw5g1awfkvj22 | 这五个娃命途多舛 |
| 3 | 1 | 1.629640e+12 | wxid_mbw5g1awfkvj22 | 又是白宇和毛晓彤合作 |
| 4 | 1 | 1.629640e+12 | wxid_mbw5g1awfkvj22 | 之前有一部,他们俩合作的挺火的剧叫什么来着 |
chat.shape(74018, 4)
print(chat.isSend.value_counts())0 38269
1 35749
Name: isSend, dtype: int64
isSend中为1的是我发的消息,为0的是女朋友发的消息,结果统计一共74018条消息,我发了35749,女朋友发了38269条消息,我比女朋友少发了2520条消息,果真还是我输了。(手动哭哭表情包)
四、数据分析
1.聊天小时、日、月分别汇总分布图
import pandas as pd
import time
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.font_manager import *#如果想在图上显示中文,需导入这个包
chat = pd.read_csv('D:/chat.csv', sep=',', usecols=[6,7,8],encoding="gbk")
myGirl = 'wxid_mbw5g1awfkvj22'
chat_time = []
chat_content = []
for i in range(len(chat)-1):content = chat[i:i+1]if content['talker'].values[0] == myGirl:t = content['createTime'].values[0]//1000#除以1000用以剔除后三位0c = content['content'].values[0]chat_time.append(t)chat_content.append(c)def to_hour(t):struct_time = time.localtime(t) # 将时间戳转换为struct_time元组hour = round((struct_time[3] + struct_time[4] / 60), 2)return hour
hour_set = [to_hour(i) for i in chat_time]
myfont = FontProperties(fname=r'C:\Windows\Fonts\MSYH.TTC',size=22)#标题字体样式
myfont2 = FontProperties(fname=r'C:\Windows\Fonts\MSYH.TTC',size=18)#横纵坐标字体样式
sns.set_style('darkgrid')#设置图片为深色背景且有网格线
sns.distplot(hour_set, 24, color='lightcoral')
plt.xticks(np.arange(0, 25, 1.0), fontsize=15)
plt.yticks(fontsize=15)
plt.title('聊天时间分布', fontproperties=myfont)
plt.xlabel('时间段', fontproperties=myfont2)
plt.ylabel('聊天时间分布', fontproperties=myfont2)
fig = plt.gcf()
fig.set_size_inches(15,8)
fig.savefig('chat_time.png',dpi=100)
plt.show()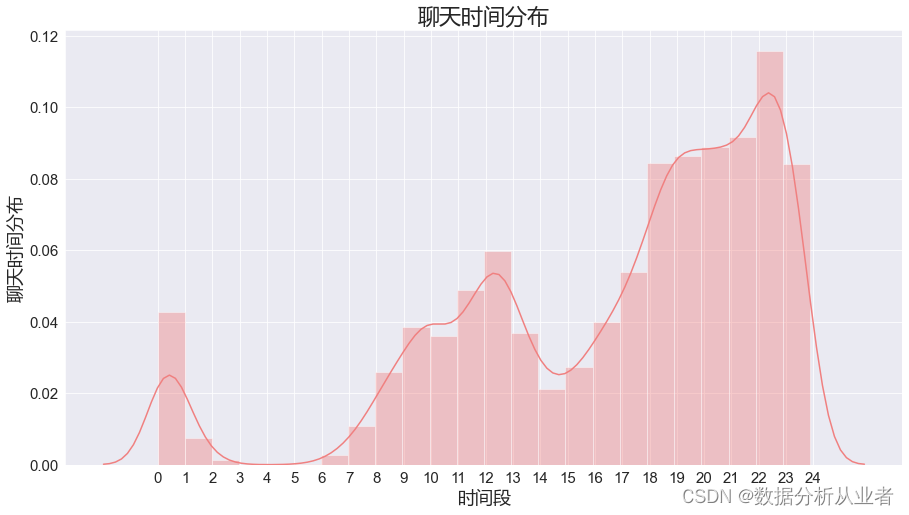
从图中我们可以看到聊天最多的时间段为22点到23点,达到了11%以上,一般晚上聊的比较多,其次就是早饭前后和午饭前后聊的也比较多。发现在0点以后还有些聊天记录,下次再分析的时候希望这部分的百分比降低,早睡才能变美哦。
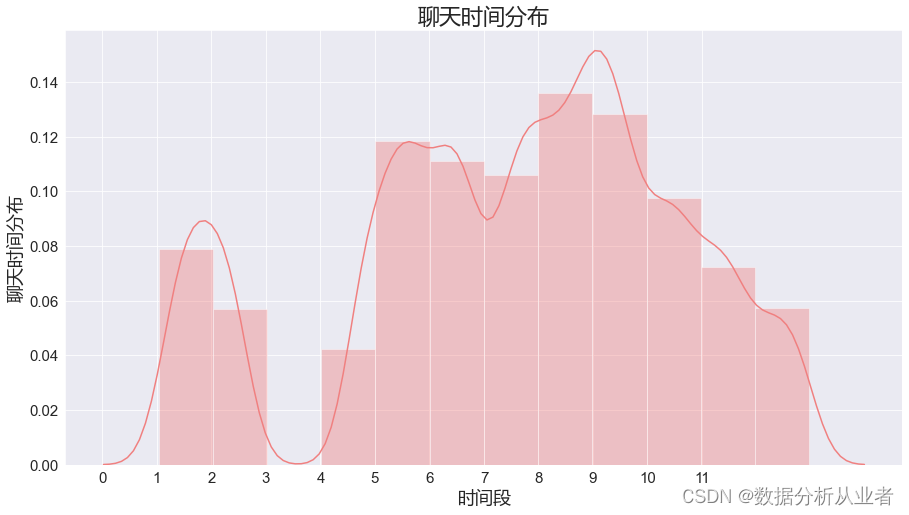
类似的思想可以绘制出每月的聊天记录,因为图中4月只有10天,2月有19天聊天记录所以比例会小一点,8月和9月聊天记录最多,往后的聊天记录就有略有下降 。
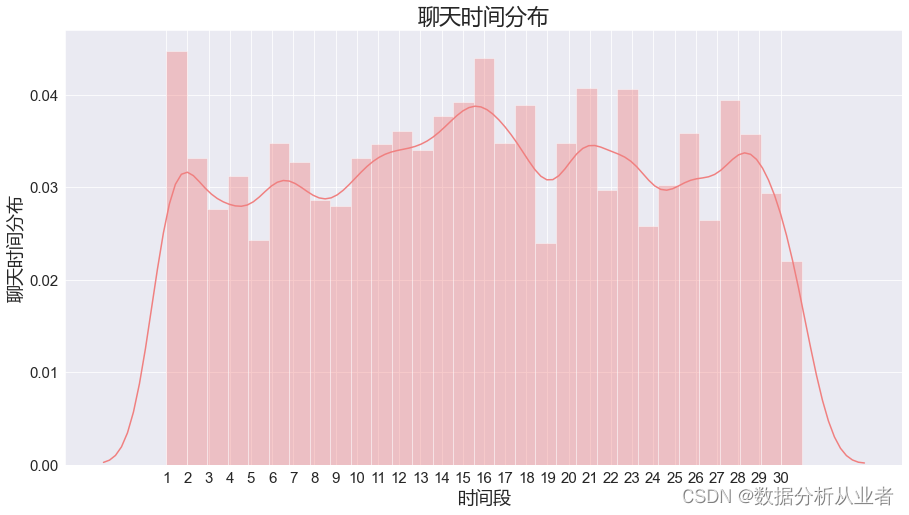
类似的思想可以绘制每日汇总的柱线图,可以看到1号和16号的聊天记录较多,5号和19号的聊天记录较少,总体分布较均匀。
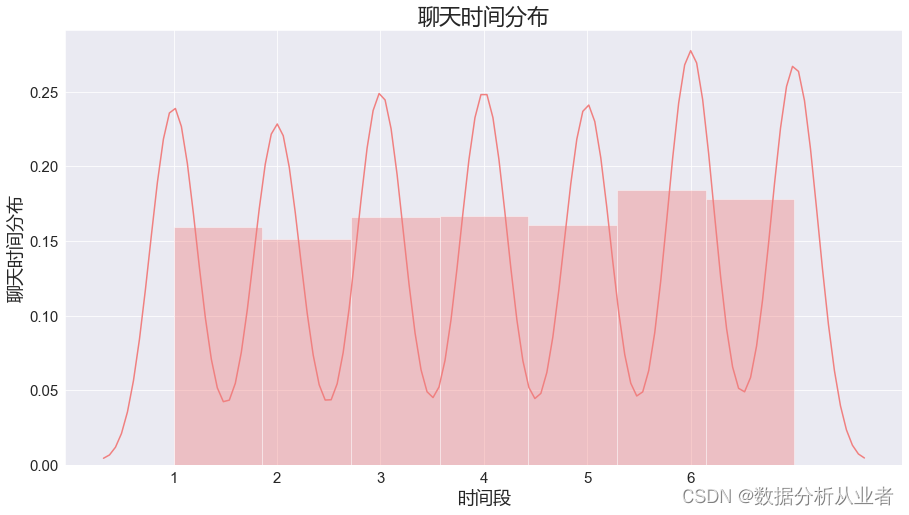
图中横坐标为星期几,可以看出分布较均匀,在周末略比工作日的聊天记录多一点。
2.聊天时间序列分布图
def to_date(t):timeArray = time.localtime(t)otherStyleTime = time.strftime("%Y-%m-%d", timeArray)return otherStyleTime
date_set = [to_date(i) for i in chat_time]
a=pd.Series(date_set)
b=a.value_counts()
data=pd.Series(b)
data=data.sort_index()import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
import datetime#这个包很关键
#设定开始和结束时间
start=datetime.datetime(2021,4,20)
stop=datetime.datetime(2022,2,20)
delta=datetime.timedelta(1)#设定日期的间隔
dates=mpl.dates.drange(start,stop,delta)# 返回浮点型的日期序列,这个是生成时间序列,同理如果是将序列转成日期呢?
#存在两个问题,一个是坐标轴没有按照日期的形式去标注,另一个是刻度的数量和位置也不合适
fig=plt.figure(figsize=(24,12))#调整画图空间的大小
plt.plot(dates,data,linestyle='-',marker='*',c='r',alpha=0.5)#作图
ax=plt.gca()
date_format=mpl.dates.DateFormatter('%Y-%m-%d')#设定显示的格式形式
ax.xaxis.set_major_formatter(date_format)#设定x轴主要格式
ax.xaxis.set_major_locator(mpl.ticker.MultipleLocator(30))#设定坐标轴的显示的刻度间隔
fig.autofmt_xdate()#防止x轴上的数据重叠,自动调整。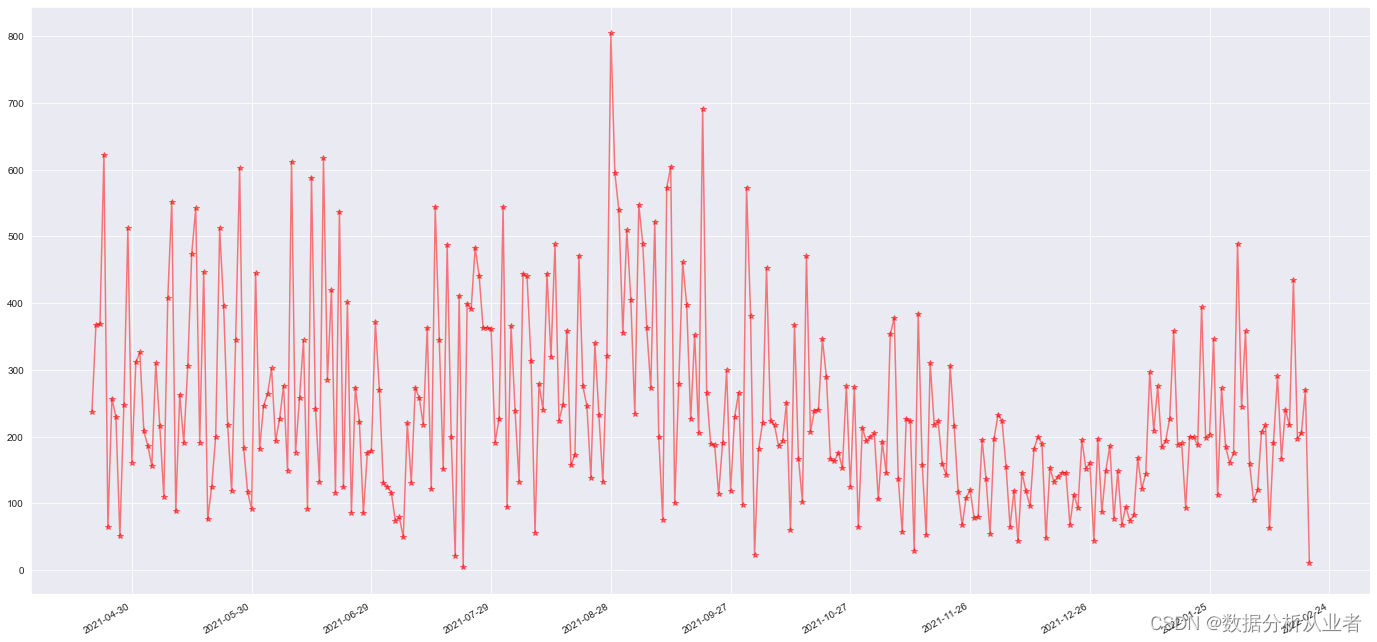
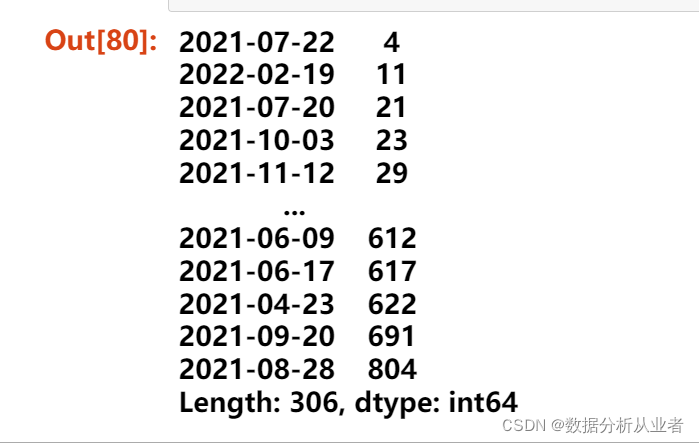
图中可以明显的看出聊天的数据量随时间的变化而变化,消息数量呈显波动的趋势。12月份左右数据量明显较少。表格中列出了数据量最多的5天和最少的5天,最多的一天是2021年8月28日,这一天刚好我我去武汉上学在火车上所以发的消息较多,发了804条。最少的是2021年7月22日这一天只发了4条聊天记录,查看了一下改天4条聊天记录都是我发的,那天确实是特殊情况,具体什么情况宝宝应该知道,一共306天每天都有聊天记录。
3.高频词汇统计
import pandas as pd
import time
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import datetime
import re
from matplotlib.font_manager import *#如果想在图上显示中文,需导入这个包
chat = pd.read_csv('D:/chat.csv', sep=',', usecols=[6,7,8],encoding="gbk")
myGirl = 'wxid_mbw5g1awfkvj22'
chat_time = []
chat_content = []
for i in range(len(chat)-1):content = chat[i:i+1]if content['talker'].values[0] == myGirl:t = content['createTime'].values[0]//1000#除以1000用以剔除后三位0c = content['content'].values[0]chat_time.append(t)chat_content.append(c)def to_hour(t):struct_time = time.localtime(t) # 将时间戳转换为struct_time元组hour = round((struct_time[3] + struct_time[4] / 60), 2)return hour
pattern_1 = '.*?(宝宝).*?'
pattern_2= '.*?(晚安).*?'
pattern_3 = '.*?(吃饭).*?'
pattern_4 = '.*?(干嘛).*?'
pattern_5= '.*?(嗯嗯).*?'
pattern_6='.*?(喜欢).*?'
pattern_7='.*?(哈哈).*?'
pattern_8='.*?(早安).*?'
pattern_9='.*?(爱).*?'
pattern_set = [pattern_1, pattern_2, pattern_3, pattern_4,pattern_5, pattern_6, pattern_7, pattern_8,pattern_9]start = datetime.datetime.now()
statistic = [0,0,0,0,0,0,0,0,0]
for i in range(len(chat_content)):for j in range(len(pattern_set)):length = len(re.findall(pattern_set[j], str(chat_content[i])))statistic[j] += length
result = {'宝宝': statistic[0],'晚安': statistic[1],'吃饭': statistic[2],'干嘛': statistic[3],'嗯嗯': statistic[4],'喜欢': statistic[5],'哈哈': statistic[6],'早安': statistic[7],'爱': statistic[8]}
print(result)
end = datetime.datetime.now()
print('\n..........\n字符统计结束,用时: {}\n............\n'.format(end-start)){'宝宝': 627, '晚安': 645, '吃饭': 907, '干嘛': 472, '嗯嗯': 2280, '喜欢': 730, '哈哈': 1674, '早安': 9, '爱': 821}
.......... 字符统计结束,用时: 0:27:56.019124 ............
可以将自己想要了解的词汇输入上去,然后就能得出一共发了多少条这样的词汇,本文中可以看到晚安一共有645条,一共大概300天的时间,可以看出几乎每天每个人都发了晚安。宝宝也有627次,聊吃饭的话题也挺多的哈,哈哈发了1674次,说明聊天的氛围还是蛮开心的,嘿嘿!
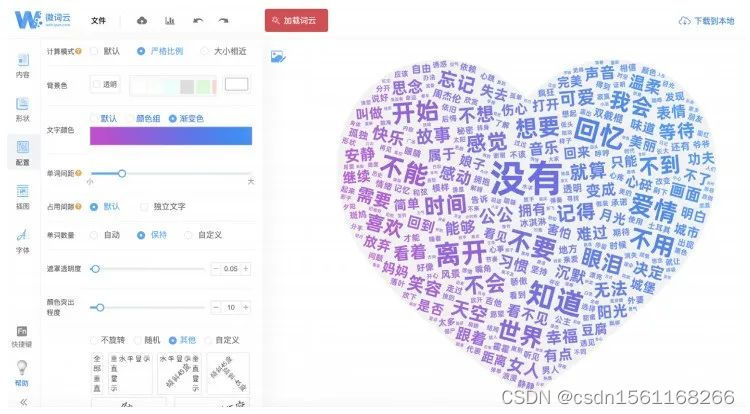
4.词云图展示
#因为代码太长,这里只放部分代码,具体的可以自己研究
def main(input_filename):content = '\n'.join([line.strip()for line in codecs.open(input_filename, 'r', 'utf-8')if len(line.strip()) > 0])stopwords = set([line.strip()for line in codecs.open(stopwords_filename, 'r', 'utf-8')])segs = jieba.cut(content)words = []for seg in segs:word = seg.strip().lower()if len(word) > 1 and word not in stopwords:words.append(word)

因为是和女朋友的聊天记录所以我采用了粉粉的心形作为词云的底层图案,似乎更加好看而且怀念呢。我们可以看到上面两幅图词云图都可以看出晚安、回来、吃饭、亲亲等词比较明显的出现在图上,看的越清晰说明改词出现的频率越高,在边上也有些关于工作,家庭,生活的话题,几乎覆盖了所有的聊天话题。
五、其它探索性分析
因为时间比较有限,除了本文的一些分析外还可以对数据进行预测建模,就是对女朋友的聊天记录的词汇进行预测,预测未来女朋友的一些聊天词汇或者说心情的变化。也可以借助机器学习或者人工智能的手段对数据进行挖掘,通过判断心情词汇,可以更好的知道如何回女朋友的消息才能让女朋友更开心。本文就到此结束了,欢迎大家继续往后面进行研究。