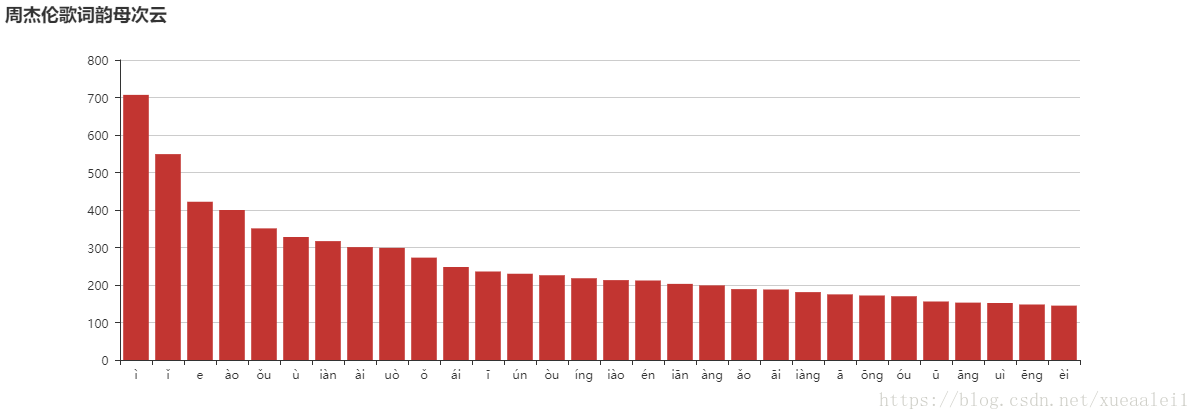
周杰伦几乎陪伴了每个90后的青春,那如果AI写杰伦风格的歌词会写成怎样呢?
首先当然我们需要准备杰伦的歌词,这里一共收录了他的十几张专辑,近5000多行歌词。
原文档格式:
第一步数据预处理
def preprocess(data):"""对文本中的字符进行替换,空格转换成逗号;换行变为句号。"""data = data.replace(' ', ',')data = data.replace('\n', '。')words = jieba.lcut(data, cut_all=False) # 全模式切词return words处理后结果:
前10个词: ['想要', '有', '直升机', '。', '想要', '和', '你', '飞到', '宇宙', '去']将处理完的数据写入内存并将文本转换完数字
# 构造词典及映射vocab = set(text)vocab_to_int = {w: idx for idx, w in enumerate(vocab)}int_to_vocab = {idx: w for idx, w in enumerate(vocab)}# 转换文本为整数int_text = [vocab_to_int[w] for w in text]构建神经网络
a. 构建输入层
def get_inputs():inputs = tf.placeholder(tf.int32, [None, None], name='inputs')targets = tf.placeholder(tf.int32, [None, None], name='targets')learning_rate = tf.placeholder(tf.float32, name='learning_rate')return inputs, targets, learning_rateb. 构建堆叠RNN单元
其中rnn_size指的是RNN隐层神经元个数
def get_init_cell(batch_size, rnn_size):lstm = tf.contrib.rnn.BasicLSTMCell(rnn_size)cell = tf.contrib.rnn.MultiRNNCell([lstm])initial_state = cell.zero_state(batch_size, tf.float32)initial_state = tf.identity(initial_state, 'initial_state')return cell, initial_statec. Word Embedding
因为单词太多,所以需要进行embedding,模型中加入Embedding层来降低输入词的维度
def get_embed(input_data, vocab_size, embed_dim):embedding = tf.Variable(tf.random_uniform([vocab_size, embed_dim], -1, 1))embed = tf.nn.embedding_lookup(embedding, input_data)return embedd. 构建神经网络,将RNN层与全连接层相连
其中cell为RNN单元; rnn_size: RNN隐层结点数量;input_data即input tensor;vocab_size:词汇表大小; embed_dim: 嵌入层大小
def build_nn(cell, rnn_size, input_data, vocab_size, embed_dim):embed = get_embed(input_data, vocab_size, embed_dim)outputs, final_state = build_rnn(cell, embed)logits = tf.contrib.layers.fully_connected(outputs, vocab_size, activation_fn=None)return logits, final_statee. 构造batch
这里我们根据batch_size和seq_length分为len//(batch_size*seq_length)个batch,每个batch包含输入和对应的目标输出
def get_batches(int_text, batch_size, seq_length):'''构造batch'''batch = batch_size * seq_lengthn_batch = len(int_text) // batchint_text = np.array(int_text[:batch * n_batch]) # 保留能构成完整batch的数量int_text_targets = np.zeros_like(int_text)int_text_targets[:-1], int_text_targets[-1] = int_text[1:], int_text[0]# 切分x = np.split(int_text.reshape(batch_size, -1), n_batch, -1)y = np.split(int_text_targets.reshape(batch_size, -1), n_batch, -1)return np.stack((x, y), axis=1) # 组合模型训练
from tensorflow.contrib import seq2seqtrain_graph = tf.Graph()with train_graph.as_default():vocab_size = len(int_to_vocab) # vocab_sizeinput_text, targets, lr = get_inputs() # 输入tensorinput_data_shape = tf.shape(input_text)# 初始化RNNcell, initial_state = get_init_cell(input_data_shape[0], rnn_size)logits, final_state = build_nn(cell, rnn_size, input_text, vocab_size, embed_dim)# 计算softmax层概率probs = tf.nn.softmax(logits, name='probs')# 损失函数cost = seq2seq.sequence_loss(logits,targets,tf.ones([input_data_shape[0], input_data_shape[1]]))# 优化函数optimizer = tf.train.AdamOptimizer(lr)# Gradient Clippinggradients = optimizer.compute_gradients(cost)capped_gradients = [(tf.clip_by_value(grad, -1., 1.), var) for grad, var in gradients if grad is not None]train_op = optimizer.apply_gradients(capped_gradients)训练结果
Epoch 72 Batch 24/33 train_loss = 0.108Epoch 75 Batch 25/33 train_loss = 0.104Epoch 78 Batch 26/33 train_loss = 0.096Epoch 81 Batch 27/33 train_loss = 0.111Epoch 84 Batch 28/33 train_loss = 0.119Epoch 87 Batch 29/33 train_loss = 0.130Epoch 90 Batch 30/33 train_loss = 0.141Epoch 93 Batch 31/33 train_loss = 0.138Epoch 96 Batch 32/33 train_loss = 0.153Model Trained and Savedtrain_loss还不错,不过可能过拟合了。
最后让我们加载模型,看看生成情况
# 加载模型loader = tf.train.import_meta_graph(save_dir + '.meta')loader.restore(sess, save_dir)# 获取训练的结果参数input_text, initial_state, final_state, probs = get_tensors(loaded_graph)# Sentences generation setupgen_sentences = [prime_word]prev_state = sess.run(initial_state, {input_text: np.array([[1]])})# 生成句子for n in range(gen_length):dyn_input = [[vocab_to_int[word] for word in gen_sentences[-seq_length:]]]dyn_seq_length = len(dyn_input[0])# 预测probabilities, prev_state = sess.run([probs, final_state],{input_text: dyn_input, initial_state: prev_state})# 选择单词进行文本生成,用来以一定的概率生成下一个词pred_word = pick_word(probabilities[0][dyn_seq_length - 1], int_to_vocab)gen_sentences.append(pred_word)哎哟不错哦!
最后的最后我还扩大了歌词库,这次引入了更多流行歌手,来看看效果吧。
好像更不错了!
如果你也喜欢杰伦,请点赞并分享生成的歌词。
点击这里→了解更多精彩内容