周董的夕阳红粉丝团“被迫营业”,把蔡徐坤拉下了盘踞许久的微博超话人气榜第一,还一举破了亿。
当然,等我知道的时候,都战局已定了……作为当年会唱前三张专辑里所有歌曲的老粉,不想就这么躺赢,我今天也来给周杰伦做一把数据:
这是我们从酷我音乐上获取了周杰伦32张专辑,共189首歌曲(去除重复)的歌词,对其中的歌词进行了分词统计,得到了歌词中频率最高的词汇。
具体的前十名数据:
爱、回忆、微笑、世界……看得出来,周董的歌还是充满青涩和小清新的。难怪人说:周杰伦的歌里,有我们的青春。
下次有机会,咱也来做做其他想把重心放在作品上的小鲜肉的数据。但前提是,样本量得够啊……
代码实现
通过歌词做词云,这个你们可能在网上看到过很多了。其实我在两年多前就已经做过:
数据分析:当赵雷唱民谣时他唱些什么?
基本思路都是一样的。这里我再简单说一下:
1. 在酷我的页面上,找到专辑列表的接口:
http://www.kuwo.cn/api/www/artist/artistAlbum?artistid=336&pn=1&rn=50
通过 requests 库获取结果(JSON格式数据),得到专辑 id。
2. 通过专辑 id,获取歌曲 id 列表:
http://www.kuwo.cn/album_detail/555949
再通过歌曲 id,进入歌曲详细页面获取歌词:
http://m.kuwo.cn/newh5/singles/songinfoandlrc?musicId=7119717
3. 使用 jieba 分词库,对歌词进行分词,并统计计数。
为避免某些歌里不断重复的词汇影响数据,我们对于每首歌中出现的词汇仅计数一次。
4. 去除一些没有特别含义的助词、副词、介词,选取结果前300的词汇,使用wordcloud 库绘制图云,便得到开头的那张图。
注意:要用 wordcloud 显示中文的话,需要附加中文字体,否则会显示为 □。
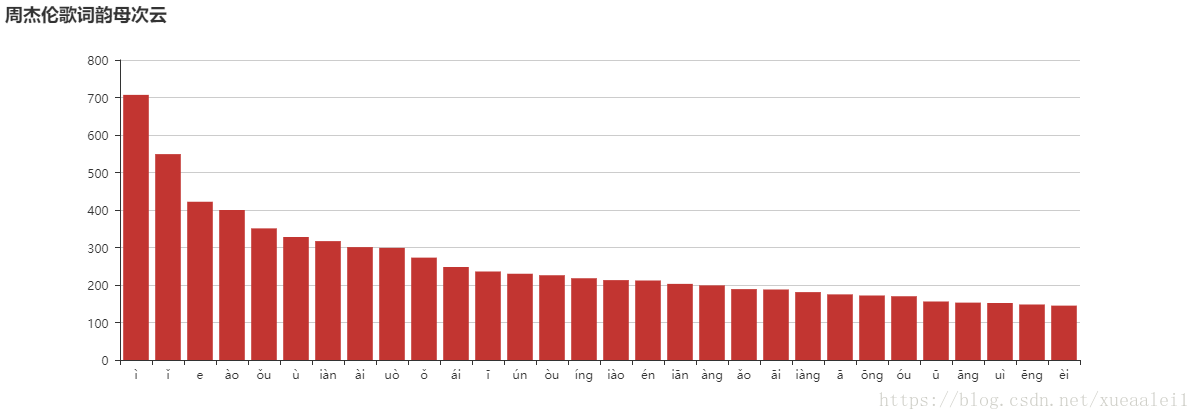
5. 用 matplotlib 库的 bar 函数 绘制一张最高频词汇的柱状图。
代码及文档:
https://github.com/spiderbeg/Kuwo_Jay