⬆️ 点击图片,与专业的解决方案架构师聊一聊
在金融量化交易场景中,每天都会产生大量的交易记录和交易信息需要存储,同时对数据也有较高要求的查询需求,整体需求概括起来就是历史数据的存储、实时数据的接收以及数据的监控和分析。对于这类有典型时序特征的数据,很多企业在业务初期选择了团队熟悉的 HBase、MySQL、MongoDB 等数据库。但是随着业务的快速发展,这些数据库已经无法满足大体量数据的写入、存储、分析监控等业务需求。
为了帮助一众金融企业寻找到合适的数据库解决方案,我们汇总了几个比较有代表性的企业客户案例,希望他们的相关实践经验应该能够给到行业从业者一些解决思路。
TDengine x 同花顺
“目前从大数据监控这个场景看,TDengine 在成本、性能和使用便利性方面都显示出非常大的优势,尤其是在节省成本方面给我们带来了很大惊喜。在预研和项目落地过程中,涛思数据的工程师也提供了专业、及时的帮助,后续我们也将在同花顺的更多场景中尝试应用 TDengine。”
业务背景
同花顺每天需要接收海量交易所行情数据,确保行情数据的数据准确。但由于该部分数据过于庞大,而且使用场景颇多,每天会产生很多的加工数据,整个系统除了对实时数据的读写性能及延时有较高要求外,还需要聚焦历史日级别数据做投资组合的各种分析,在整个分析过程中,涉及巨量的数据集,这对历史数据库的读写性能也提出了很高的要求。之前采用的 Postgres+LevelDB 数据存储方案,除了依赖多、稳定性较差外,性能方面也无法满足需求(点击下方案例链接获取具体业务痛点问题)。通过对 ClickHouse、InfluxDB、TDengine 等时序数据存储方案的调研,最终其选择了 TDengine。
架构图
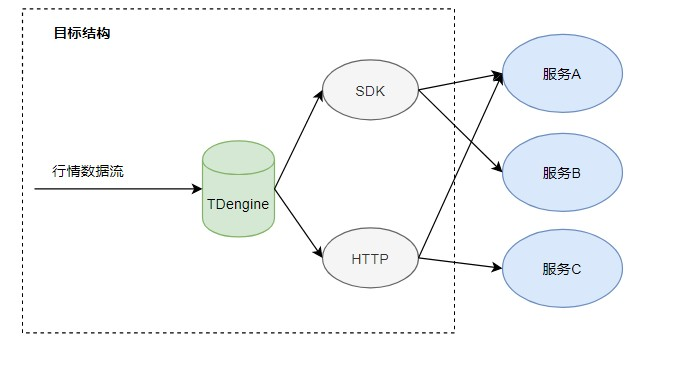
改造后性能对比

👉 点击案例查看更多技术细节
TDengine x 弘源泰平
“在写入上,单节点TDengine可以轻松实现每秒大概 3 万行数据的写入量,同时消耗服务器资源又比 InfluxDB 与 MySQL 要小很多。目前我们通过 TDengine 录入的两个信号表已经写入了 82 亿条数据,原数据大概为 92GB,实际占用存储空间为 20G 左右,压缩率高达 23%。除了写入与存储,TDengine 进行日常查询的速度也十分优秀,面对几十亿级别的大表,也能实现毫秒级响应。”
业务背景
弘源泰平的量化交易系统每天要接收大量的行情数据,也要基于行情产生大量的决策信号。这些数据都需要及时存下来,供盘中和盘后使用。传统存放行情数据的方式有文件系统、关系型数据库或者文档数据库。此前他们分别尝试了 MySQL 和知名的时序数据库(Time Series Database)InfluxDB,但是性能都没有达到预期,出现了响应时间长、资源浪费等诸多问题(点击下方案例链接获取具体业务痛点问题)。最终,其改用 TDengine 彻底解决了实时写入大量数据点和快速查询的问题。
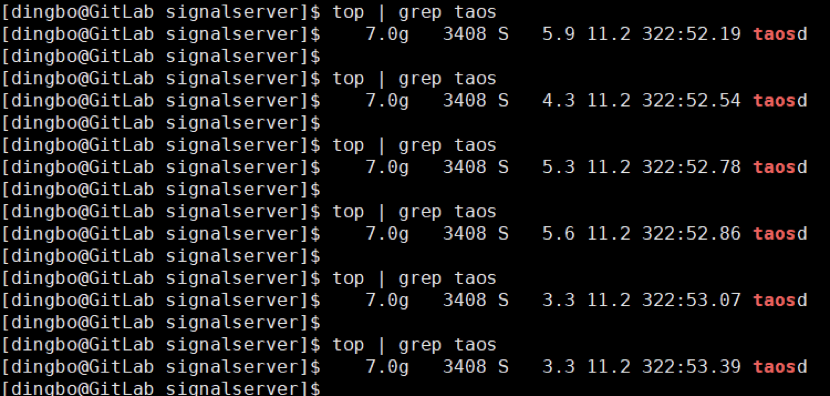
资源消耗
服务器配置如下:64G内存+40核 1.8GHz CPU+机械硬盘。在业务运行期间,taosd 的 CPU 在 4% 上下浮动,进程使用的物理内存百分比为 11.2%。由于其 vnode 配置较多,而每个 vnode 都有自己固定的内存缓冲区,因此内存占用稍多,但后续即便是继续大量增加新表或者加大写入量,内存占用也不会再有明显的浮动了。
👉 点击案例查看更多技术细节
TDengine x 同心源(三亚)基金
“对入库的总数据量进行下估算,粗略计算为 408*320 亿行,大概 12TB 左右,后面经过统计最终实际占用磁盘空间却只有2T左右,这令我们十分震惊——压缩率高达 16.7%。在查询方面,从TDengine客户端服务器使用Python从服务端拉取连续两个月的期货行情数据,耗时仅需 0.16 秒。”
业务背景
从同心源的业务模式出发,业务人员主要通过数据挖掘和自动模式识别这两种方式来发现市场的交易规律,其工作场景基于大量的金融数据之上。经过多年发展,股票市场数据量越发庞大,随着每日新数据的清洗写入,总量变得更加水涨船高。对于十几 TB 的数据量,单是进行存储已经不易,如果还要对数据进行查询下载等操作,更是难上加难。种种问题叠加,同心源对市面上的主流数据库逐渐丧失信心,尝试使用更有针对性的时序数据库,TDengine 便是他们的选择之一。
👉 点击案例查看更多技术细节
TDengine x 青岛金融研究院
“根据不同类型的业务,我们创建了 7 张不同的超级表,子表数量为 33076 张,目前我们导入的数据总量已经达到了 46 亿之多,其中最大的一张超级表达到了 26 亿行,实际磁盘占用大概在 130GB 左右。”
业务背景
在其业务场景中,TDengine 主要负责三点:一是对回测的数据支持,二是基于以上数据进行的回测数据分析,三是部分盘中策略的数据预加载。目前其数据入库方式是使用 Python 连接器直接写入 TDengine(6030 端口)。具体方式为:会通过券商的直连接口将他们提供的数据做一个 SQL 拼接,利用拼接 SQL 的方式,单个 SQL 写入几千行数据,将大批数据一次性写入到一个表中。
👉 点击案例查看更多技术细节
写在最后
从上述案例中我们也能看到,看似简单的数据处理需求,但由于数据记录条数巨大,导致数据的实时写入成为瓶颈,查询分析极为缓慢,数据存储成本显著,技术挑战层出不穷。而传统的关系型数据库、NoSQL Database 没有针对性去对应时序数据特点,在性能提升上极为有限,只能依靠集群技术,投入更多的计算资源和存储资源来处理,系统的运营维护成本也因此急剧上升。从他们的改造实践出发,选择时序数据库也是真正的实现了“对症下药”。
👇 点击“阅读原文”填写表单,与专业的解决方案架构师聊一聊