Spring中Bean的生命周期
Spring Bean的生命周期全过程分为5个阶段,创建前准备阶段、创建实例阶段、依赖注入阶段和容器缓存阶段以及销毁实例阶段。
阶段1:创建前准备阶段这个阶段主要是在开始Bean加载之前,从Spring上下文中去获取相关的配置并且解析,然后找到Bean有关的配置内容,比如说"init-method"容器在初始化Bean的时候去调用这个方法。"destory-method"容器在销毁Bean的时候去调用这个方法以及BeanFactoryPostProcessor这个类的Bean加载过程中的前置和后置的处理,这些类或者配置是Spring提供给开发者用来实现Bean加载过程中的一个扩展的机制。在很多和Spring集成的中间件中也经常使用到,比如Dubbo。
阶段2:创建实例阶段这个阶段主要是通过反射来创建Bean的实际对象,并且扫描和解析Bean的声明的一些属性。
阶段3:依赖注入阶段在这个阶段会检测被实例化的Bean是否存在其他依赖,如果存在其他依赖的话,就需要将这些依赖注入到Bean里面,比如说通过读取"@Autowired", “@Setter” 等注解去完成依赖注入的配置,这个阶段会触发一些扩展的调用,如常见的扩展类BeanPostProcessors它用来实现Bean初始化前后的一个回调。如InitializingBean的afterPropertiesSet()方法,它可以给属性赋值。还有BeanFactoryAware等等。
阶段4:容器缓存阶段容器缓存阶段主要是把Bean保存到IoC容器中缓存起来,到了这个阶段Bean就可以去被开发者使用了,这个阶段涉及到的操作有常见的“init-method”属性配置的方法会在这个阶段被调用,比如BeanPostProcessors它的后续处理方法postProcessAfterInitialization也会在这个阶段被触发。
步骤一:执行前置处理方法,当正在初始化的Bean对象被传递进来,postProcessBeforeInitialization()会吸纳与执行初始化调用方法执行,所有xxxAware接口的注入,即对引用的容器级别对象的属性的赋值/依赖注入操作,就是在这一步完成的。
步骤二:执行初始化调用方法–invokeInitMethods:
如果在Spring配置文件中配置了init-method 属性,会自动对该Bean进行增强实现步骤中的初始化步骤。“执行初始化调用方法”这一个步骤在Java 语言里边其实是没有多大实际意义的。 因为在其他编程语言里边比如说Python 里边,会在这一个步骤中进行属性赋值工作,但是在Java里边,刚才已经刚刚完成了属性赋值的工作了。
步骤三:该后置处理器的执行是在 “执行初始化调用方法” 后面进行执行,主要是判断该bean是否需要被AOP代理增强,如果需要的话,则会在该步骤返回一个代理对象。这个函数会在 “执行初始化调用方法” 完成后执行,因此称为后置处理方法。
这一步完成以后,就可以正常使用这个 Bean 了。
(5)销毁 Destruction
详解:
(1)通过xml配置或者注解配置的类,得到BeanDefinition;
(2)通过BeanDefinition反射创建Bean对象
(3)对Bean对象的属性进行填充。
(4)回调实现了Aware接口的方法,如BeanNameAware;
(5)调用BeanPostProcessor的初始化前方法。
(6)调用inti初始化方法。
(7)调用BeanPostProcessor的初始化方法,此处会进行AOP;
(8)将创建的Bean对象放入一个Map。
(9)业务使用Bean对象。
(10)Spring 容器关闭时调用DisposableBean的destory()方法。
Spring如何解决循环依赖问题
一级缓存:singletonObjects存储的是所有创建好了的单例Bean(实例化、依赖注入、初始化完成的bean实例)。
二级缓存:earlySingletonObjects保存的是完成实例化,但是还未进行属性注入以及初始化的对象。
三级缓存:singletonFactories提前暴露的一个单例工厂,二级缓存中存储的就是从这个工厂中获取到的对象。
三级缓存解决循环依赖流程:‘
(1)获取A时首先会尝试从一级缓存sigletonOjects中获取,有就返回,没有就找“二级缓存”;
(2)获取不到就从二级缓存中获取,有就返回,没有就找“三级缓存”;
(3)若还没有则从三级缓存singletonFactories中获取,找到了,就获取对象,放到“二级缓存”,从“三级缓存”移除。
(4)还有没有则再次创建该对象。
(5)会依次执行doGetBean->createBean->createBeanInstance并使用构造器实例化。
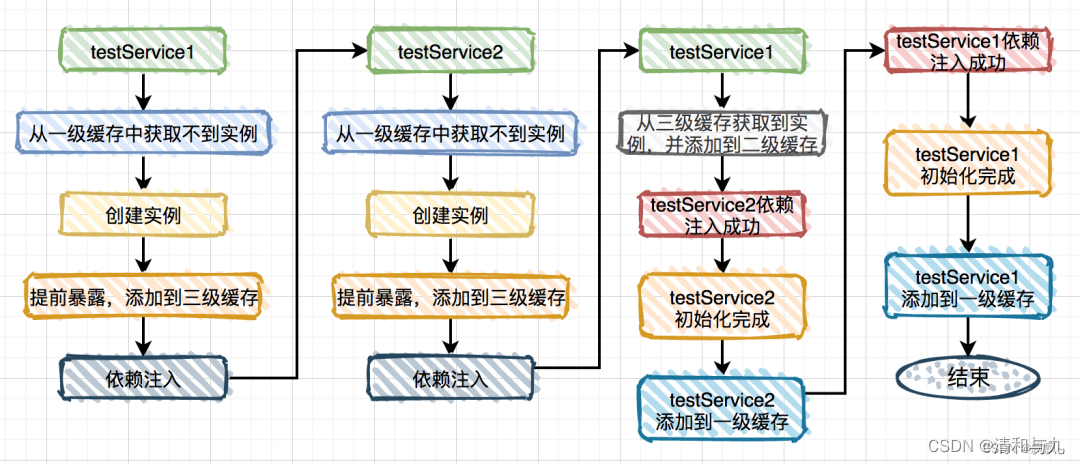
(6)在尝试给A进行初始化时,由于B不存在无法完成初始化,则将A的代理工厂放入三级缓存中,进行创建B的创建流程。
(7)与之前的过程相似,在第三级缓存中放入beanName和表达式sharedInstance,进入B的初始化过程。
(8)由于在第三级缓存中可以找到A的代理工厂,直接从“三级缓存”中拿到 A 的代理工厂,获取 A 的代理对象,放入“二级缓存”,并清除“三级缓存”;
(9)则B可以完成初始化,完成A对象的属性注入,将B放入一级缓存,然后再填充A的其他属性,以及A的其他步骤(包括AOP),完成A的初始化功能(包括AOP),完成对A的初始化功能。
(9)同时完成A的初始化,并删除二级缓存中的半成品A,将A放入一级缓存。
总结:
Spring通过三级缓存解决了循环依赖,其中一级缓存是单例池,二级缓存是早期曝光对象earlySingletonObjects,三级缓存为早期曝光对象工厂(singletonFactories)。当A、B两个类发生循环依赖时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,添加到三级缓存中,如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么这个工厂获取到的就是A实例化后的对象。当A进行属性注入时,回去创建B,同时B有依赖了A,所以创建B的同时又去调用getBean(a)来获取所需要的依赖,此时的getBean(a)会从缓存中获取:
(1)先获取到三级缓存中的工厂。
(2)调用对象工厂的getObject方法来获取到对应的对象,得到这个对象后将其注入到B中,紧接着B就会走完它的声明周期流程,包括初始化、后置处理器。
(3)当B创建完成后,会将B再次注入到A中,此时A再完成它的整个生命周期,至此,循环依赖结束。
Spring AOP的实现原理
Spring的AOP是通过动态代理实现的,如果我们为Spring的某个bean配置了切面,那么Spring在创建这个bean的时候,实际上创建的就是这个bean的一个代理对象,我们后续对bean中的方法的调用,实际上调用的就是代理类重写的代理方法。而Spring的AOP使用了两种动态代理,分别是JDK的动态代理,以及CGLib的动态代理。
JDK动态代理:
如果目标类实现了接口,Spring AOP会选择使用JDK动态代理目标类。JDK动态代理的代理类根据根据目标类实现的接口动态生成,不需要自己编写。生成的动态代理类和目标类都实现相同的接口。JDK动态代理的核心是InvocationHandler接口和Proxy类。JDK动态代理的缺点是目标类必须有实现的接口。如果这个类没有实现接口,那么这个类就不能使用JDK动态代理。
CGLIB动态代理:
如果目标类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。CGLIB英文全称是Code Generation Library,可以再运行时动态生成类的字节码,动态创建目标类的子类对象,在子类对象中增强目标类。CDLIB是通过继承的方式实现的动态代理,因此如果某个类被标记为final,那么它无法使用CGLIB做动态代理。相对于JDK动态代理,CGLIB动态代理的优点是:目标类不需要实现特定的几口,更加灵活。
如果目标对象实现了接口,默认情况下会使用JDK动态代理实现AOP,但是也可以强制使用CGLIB实现AOP。如果目标对象没有实现接口,必须采用CGLIB做动态代理。
动态代理的作用
动态代理是设计模式的一种:
(1)调用方不用知道具体目标类是什么(安全、解耦),只需要知道统一的代理类。
(2)可以对目标类做增强(在方法运行:前、后、成功、异常时,做额外处理,并且代码相对独立,也是为了解耦)
java如何删除list中的元素
(1)正序删除
使用正序删除,如果只删除至多一个元素,那只需要在删除这个元素后使用break语句跳出循环即可,如果要删除多个元素,若不注意控制当前列表的size和下一个元素的index,容易报java.lang.IndexOutOfBoundsException异常。
public static void remove(List<String> list, String target) {
for(int i = 0, length = list.size(); i < length; i++){String item = list.get(i); if(target.equals(item)){list.remove(item);length--;i--;}}
}
(2)倒序删除
倒序删除可以客服正序删需要额外管理列表size和下一个元素index的问题。
public static void remove(List<String> list, String target) {
for(int i = list.size() - 1; i >= 0; i--){String item = list.get(i);if(target.equals(item)){list.remove(item);}}
}
(3)迭代器remove()方法删除
public static void remove(List<String> list, String target) {Iterator<String> iter = list.iterator();while (iter.hasNext()) {String item = iter.next();if (item.equals(target)) {iter.remove();}}
}
(4)CopyOnWriteArrayList线程安全删除
利用CopyOnWrite容器。CopyOnWrite容器就是写时复制容器。通俗的理解就是当我们往一个容器添加元素的时候,不直接往当前元素添加,而是先将当前容器进行cooy,复制出一个新的容器,然后往新的容器里面添加元素,添加完元素后,再讲原来的容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读与写不同的容器。
public static List<String> remove(ArrayList<String> list, String target) {CopyOnWriteArrayList<String> cowList = new CopyOnWriteArrayList<String>(list);for (String item : cowList) {if (item.equals(target)) {cowList.remove(item);}}return cowList;
}
(5)增强for循环删除
增强for循环中删除元素后继续循环会报java.util.ConcurrentModification异常,因为元素在使用的时候发生了并发的修改,导致异常抛出,但是删除完毕马上使用break语句跳出循环,则不会触发报错,所以它只适合删除一个元素。
public static void remove(List<String> list, String target) {for (String item : list) {if (item.equals(target)) {list.remove(item);break;}}
}
(6)stream API filter
java8引入的stream API带来了新的比较简洁的删除List元素的方法filter,该方法不会改变原List对象,会返回新的对象。
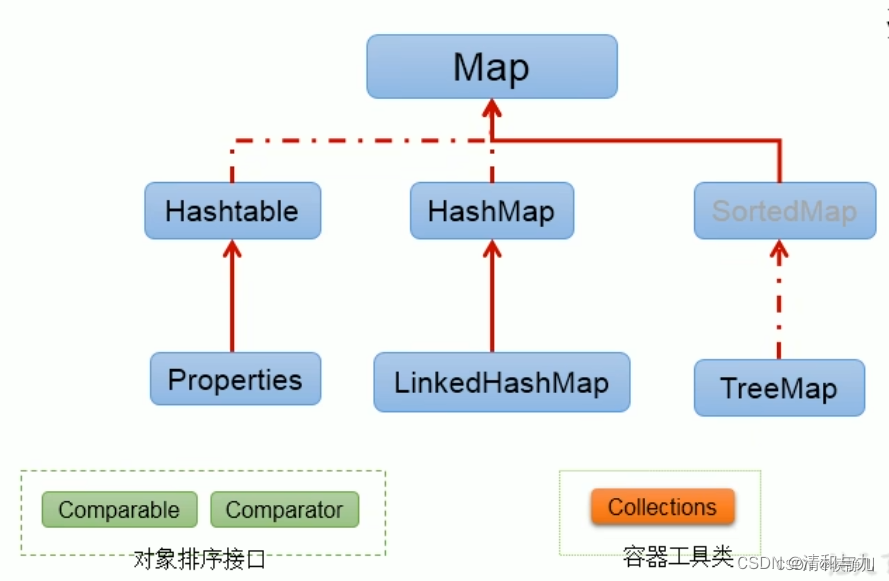
HashMap与HashTable的区别
(1)线程安全:HashMap是非线程安全的,HashTable是线程安全的。
(2)效率: 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
(3) 对Null key 和Null value的支持: HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。但是在HashTable 中 put 进的键值只要有一个 null,直接抛NullPointerException。
(4)4. 初始容量大小和每次扩充容量大小的不同 : ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你
给定的大小,而 HashMap 会将其扩充为2的幂次方大小。也就是说 HashMap 总是使用2的幂作为哈希表的大小。
5. 底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
说一下HashMap的实现原理
HashMap概述:HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选地映射操作,并且允许使用null值和null键。此类并不保证映射的顺序,特别是它不保证顺序恒久不变。
HashMap的数据结构:在java编程语言中,基本的数据结构就是两种,一个是数组,另一个是模拟指针(引用),所有数据结构都可以用这两种基本结构来进行构造,Hashmap也不例外。HashMap实际上是一个链表散列的数据结构,即数组和链表的集合。
HashMAP是基于Hash算法实现的:
(1)当我们向Hashmap中put元素的时候,利用key的hashcode重新hash出当前对象的元素在数组中的下标。
(2)存储时,如果出现hash值相同的key,此时有两种情况。如果key相同,此时覆盖原值。如果key不相同,也就是出现hash冲突,则将key-value放入链表中。
(3)获取时,之际找到hash值对应的下标,再进一步判断key是否相同,从而找到对象的值。
(4) 理解了以上过程就不难明白HashMap是如何解决hash冲突的问题,核心就是使用了数组的存储方式,然后将冲突的key的对象放入链表中,一旦发现冲突就在链表中做进一步的对比。
jdk1.8中对HashMap实现了优化,当链表中的节点超过8个之后,该联保转化为红黑树来提高查询效率,由曾经的O(N)转化为O(logn)
简单总结下HashMap是使用了哪些方法来有效解决哈希冲突的:
(1)使用链地址法(散列表)来链接具有相同哈希值的数据。
(2)使用二次扰动函数(hash函数)来降低哈希冲突的概率,使得数据分布更加均匀。
(3)当链表长度超过八个节点时,使用红黑树来降低时间复杂度,使得遍历更快。
ConcurrentHashMap
Segment段:
整个ConcurrentHashMap是由一个个的Segment组成,Segment代表部分或者一段的意思,很多地方会将其描述非分段锁。
线程安全:
JDK1.7版本:ReentrantLock+Segment+HashEntry
JDK1.8版本:synchronized+CAS+HashEntry+红黑树
1.JDK1.8降低锁的粒度,JDK1.7锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry
2.JDK1.8使用红黑树来优化链表
3.JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock(synchronized支持锁升级,偏向锁->CAS轻量级锁
->自旋锁->重量级锁)
HashMap为什么线程不安全
jdk1.7:
因为hashMap在jdk1.7中的扩容使用的是头插法,当发生哈希冲突时存储结构为链表,当多线程调用同一个hashmap时,A线程B线程同时使用,都需要扩容,此时A线程获取cpu时间片,扩容完毕后,B线程认为当前链表为扩容前的结构,但实际已经是扩容后的存储结构,从而导致链表中两个节点发生死循环。
解决办法:多线程下建议使用ConcurrentHashMap替代。在JDK1.8中,HashMap扩容改为尾插法,解决了链表死循环的问题。
jdk1.8
JDK1.8 中,由于多线程对HashMap进行put操作,调用了HashMap#putVal(),具体原因:假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
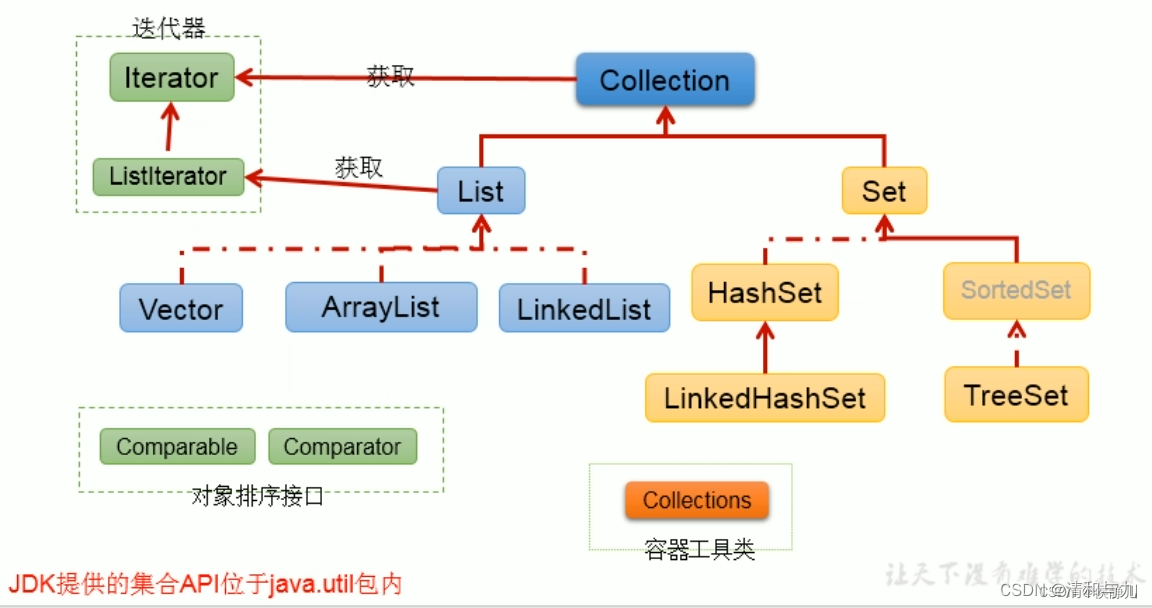
Collection接口继承树
Map接口继承树
Vector,ArrayList,LinkedList的区别是什么?
(1)Vector、ArrayList都是以类似数组的形式存储在内存之中,LinkedList则以链表的形式存储。
(2)List中的元素有序,允许重复,Set中无序、不允许重复。
(3)Vector线程同步,ArrayList、LinkedList线程不同步。
(4)LinkedList适合指定位置插入、删除,不适合查找。ArrayList、Vector适合查找,不适合指定位置的插入、删除操作。
(5)ArrayList在元素填满容器时会自动扩充50%,而Vector则是百分之百,因此ArrayList更节省空间。