本文转载自: 2023大型语言模型推荐技术进展综述: 分类、进展、问题、趋势.
原文链接:https://arxiv.org/pdf/2305.19860.pdf
A Survey on Large Language Models for Recommendation
文章目录
- 内容摘要
- 1. 内容引言
- 2. LLM推荐建模范式
- 3. 用于推荐的判别式LLM
- 3.1 微调(Fine-tuning)
- 3.2 提示调整(Prompt Tuning)
- 4. 用于推荐的生成式LLM
- 4.1 非调谐(Non-tuning)范式
- 提示学习(Prompting)
- 情境学习(in-context learning)
- 4.1 调谐(Tuning)范式
- 提示调优(Prompt Tuning)
- 指令调优(Instruction Tuning)
- 5. 发现总结
- 5.1. 模型偏差(Model Bias)
- 5.2. 推荐提示(Prompt)设计
- 5.3 有前途的能力
- 5.4 评估问题
- 6. 结论
- 参考文献
内容摘要
大型语言模型(LLM)已成为自然语言处理(NLP)领域的强大工具,最近在推荐系统(RS)领域获得了极大关注。这些模型通过自监督学习在海量数据上进行训练,在学习通用表征方面取得了显著的成功,并有可能通过一些有效的转移技术(如微调和及时调整等)来增强推荐系统的各个方面。利用语言模型的力量提高推荐质量的关键在于利用其高质量的文本特征表征和广泛的外部知识覆盖来建立项目和用户之间的相关性。为了全面了解现有的基于 LLM 的推荐系统,本综述提出了一种分类法,将这些模型分为两大范式,分别是用于推荐的判别式 LLM(DLLM4Rec)和用于推荐的生成式 LLM(GLLM4Rec),并首次对后者进行了系统梳理。此外,我们还系统地回顾和分析了每种范式中现有的基于 LLM 的推荐系统,深入探讨了它们的方法、技术和性能。此外,我们还指出了关键挑战和一些有价值的发现,为研究人员和从业人员提供启发。
1. 内容引言
推荐系统在帮助用户查找相关的个性化项目或内容方面发挥着至关重要的作用。随着大型语言模型(LLM)在自然语言处理(NLP)领域的出现,人们对利用这些模型的力量来增强推荐系统的兴趣与日俱增。
将 LLM 纳入推荐系统的关键优势在于它们能够提取高质量的文本特征表征,并利用其中编码的大量外部知识。本研究将 LLM 视为基于 Transformer 的模型,具有大量参数,使用自我/半监督学习技术在海量数据集上进行训练,例如 BERT、GPT 系列、PaLM 系列等。与传统的推荐系统不同,基于 LLM 的模型擅长捕捉上下文信息,能更有效地理解用户查询、项目描述和其他文本数据。通过理解上下文,基于 LLM 的 RS 可以提高推荐的准确性和相关性,从而提高用户满意度。同时,面对历史交互有限这一常见的数据稀疏性问题,LLM也通过零/少量推荐功能为推荐系统带来了新的可能性。由于使用事实信息、领域专业知识和常识推理进行了大量的预训练,这些模型可以泛化到未见过的候选对象,从而使它们即使在没有事先接触过特定项目或用户的情况下也能提供合理的推荐。
上述策略已在判别模型中得到广泛应用。然而,随着人工智能学习范式的发展,生成式语言模型开始崭露头角。ChatGPT 和其他类似模型的出现就是一个最好的例子,它们极大地颠覆了人类的生活和工作模式。此外,生成模型与推荐系统的融合为更多创新和实际应用提供了可能。例如,可以提高推荐的可解释性,因为基于 LLM 的系统能够根据其语言生成能力提供解释,帮助用户理解影响推荐的因素。此外,生成式语言模型还能实现更加个性化和情境感知的推荐,例如在基于聊天的推荐系统中,用户可以自定义提示,从而提高用户的参与度和对结果多样性的满意度。
上述范式在解决数据稀缺性和效率问题方面效果显著,在此激励下,将语言建模范式应用于推荐已成为学术界和工业界的一个有前途的方向,极大地推动了推荐系统研究的最新发展。
到目前为止还缺乏对生成式大型语言模型在推荐领域的最新进展和系统介绍的全面概述。为了解决这个问题,我们深入研究了基于 LLM 的推荐系统,将其分为用于推荐的判别式 LLM 和用于推荐的生成式 LLM,我们的综述重点是后者。本综述的主要贡献概述如下:
-
我们对基于 LLM 的推荐系统的现状进行了系统的调查,重点是扩展语言模型的容量。通过分析现有方法,我们对相关进展和应用进行了系统性概述。
-
据我们所知,我们的调查是第一份专门针对用于推荐系统的生成式大型语言模型的全面、最新综述。
-
我们的调查批判性地分析了现有方法的优缺点和局限性。我们确定了基于 LLM 的推荐系统所面临的主要挑战,并提出了有价值的发现,这些发现可以激发这一潜在领域的进一步研究。
2. LLM推荐建模范式
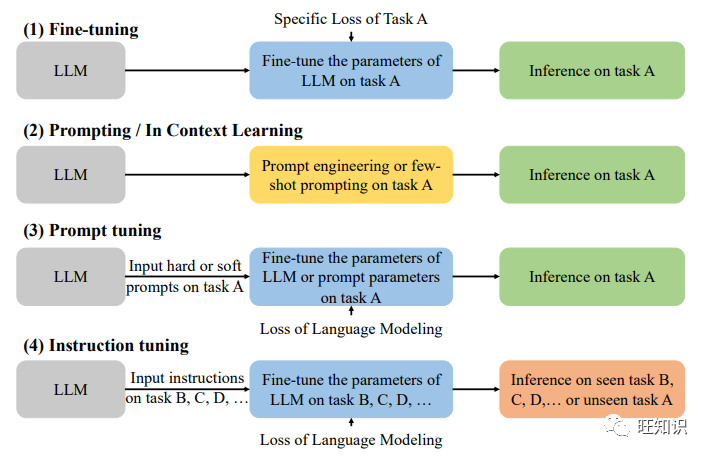
所有大型语言模型的基本框架都是由多个转换模块组成的,如 GPT、PaLM、LLaMA 等。这种架构的输入一般由标记嵌入或位置嵌入等组成,而预期的输出嵌入或标记可在输出模块中获得。这里的输入和输出数据类型都是文本序列。如图1中的(1)-(3)所示,对于推荐中语言模型的适配,即建模范式,现有的工作大致可以分为以下三类:

-
LLM 嵌入+RS(LLM Embeddings + RS):这种建模范式将语言模型视为特征提取器,将项目和用户的特征输入 LLM,并输出相应的嵌入。传统的 RS 模型可以利用知识感知嵌入来完成各种推荐任务。
-
LLM 标记+RS(LLM Tokens + RS):与前一种方法类似,这种方法根据输入的物品和用户特征生成标记。生成的标记通过语义挖掘捕捉潜在的偏好,并将其整合到推荐系统的决策过程中。
-
LLM 作为 RS(LLM as RS):与(1)和(2)不同,这种模式旨在将预先训练好的 LLM 直接转化为功能强大的推荐系统。输入序列通常由档案描述、行为提示和任务指令组成。输出序列有望提供合理的推荐结果。
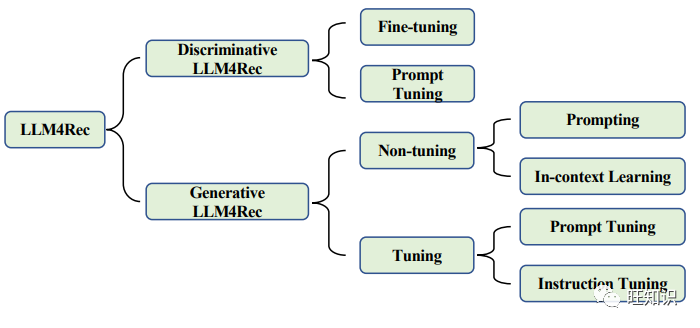
在实际应用中,语言模型的选择在很大程度上影响着推荐系统中建模范式的设计。如图2所示,本文将现有工作分为两大类,分别是用于推荐的判别式 LLM 和生成式 LLM。根据训练方式的不同,推荐用 LLM 的分类法还可以进一步细分,不同训练方式的区别如图3所示。一般来说,判别式语言模型非常适合嵌入范式(1),而生成式语言模型的响应生成能力则进一步支持范式(2)或(3)。
3. 用于推荐的判别式LLM
事实上,推荐领域所谓的判别式语言模型主要是指 BERT 系列的模型。由于鉴别性语言模型在自然语言理解任务中的专业性,它们通常被视为下游任务的嵌入骨干。推荐系统也是如此。大多数现有研究都通过微调将 BERT 等预训练模型的表征与特定领域的数据相一致。此外,一些研究还探索了及时调整等训练策略。表1和表2列出了具有代表性的方法和常用数据集。
3.1 微调(Fine-tuning)
微调(Fine-tuning)预训练语言模型是一种通用技术,在包括推荐系统在内的各种自然语言处理(NLP)任务中受到了广泛关注。微调背后的理念是将已经从大规模文本数据中学习到丰富语言表征的语言模型,通过在特定任务数据上的进一步训练使其适应特定任务或领域。

微调过程包括使用预训练语言模型的已学参数对其进行初始化,然后在特定的推荐数据集上对其进行训练。该数据集通常包括用户与物品的交互、物品的文字描述、用户资料以及其他相关的上下文信息。在微调过程中,模型的参数会根据特定任务的数据进行更新,使其能够适应并专门用于推荐任务。在预训练和微调阶段,学习目标可以不同。
由于微调策略非常灵活,大多BERT增强推荐方法都可以归纳到这一轨道中。总之,将 BERT 微调整合到推荐系统中,融合了强大的外部知识和个性化的用户偏好,其主要目的是提高推荐的准确性,同时为历史数据有限的新项目获得一点冷启动处理能力。
3.2 提示调整(Prompt Tuning)
提示调优(Prompt Tuning)不是通过设计特定的目标函数使 LLM 适应不同的下游推荐任务,而是试图通过硬/软提示和标签词动词化器使推荐的调优对象与预先训练的损失相一致。
实验发现,通过使用多提示组合,推荐系统的性能明显提高,超过了在离散和连续模板上使用单一提示所取得的结果。这凸显了提示组合在结合多个提示做出更明智决策方面的有效性。
4. 用于推荐的生成式LLM
与判别模型相比,生成模型具有更好的自然语言生成能力。因此,与大多数基于判别模型的方法将 LLM 学习到的表征与推荐领域相匹配不同,大多数基于生成模型的工作都是将推荐任务转换为自然语言任务,然后应用上下文学习、提示调整和指令调整等技术来调整 LLM,使其直接生成推荐结果。此外,随着 ChatGPT 所展示的令人印象深刻的能力,这类工作最近也受到了越来越多的关注。
如图2所示,根据是否调整参数,这些基于生成式 LLM 的方法可以进一步细分为两种范式: 非调谐范式和调谐范式。下面两个小节将分别讨论它们的细节。表1和表2中还列出了具有代表性的方法和常用数据集。
4.1 非调谐(Non-tuning)范式
LLMs 在许多未见任务中都表现出了很强的零样本/小样本学习能力。因此,最近的一些研究假定 LLM 已经具备推荐能力,并试图通过引入特定的提示来触发这些能力。它们采用了最近的 “指导与情境学习”(Instruction and In-Context Learning)的做法,在不调整模型参数的情况下将LLMs应用于推荐任务。
根据提示是否包含示范示例,该范式的研究主要分为以下两类: 提示学习(prompting)和情境学习(in-context learning)。
提示学习(Prompting)
这类工作旨在设计更合适的指令和提示,以帮助LLM更好地理解和解决推荐任务。
文献[1]系统地评估了ChatGPT在五种常见推荐任务上的性能,即评分预测、顺序推荐、直接推荐、解释生成和评论总结。他们提出了一个通用的推荐提示构建框架,其中包括 (1) 任务描述,将推荐任务调整为自然语言处理任务;(2) 行为注入,结合用户与项目的交互,帮助 LLM 捕捉用户偏好和需求;(3) 格式指示器,约束输出格式,使推荐结果更易于理解和评估。同样,文献[2]对ChatGPT在点排序、对排序和列表排序等三种常见信息检索任务中的推荐能力进行了实证分析。他们针对不同类型的任务提出了不同的提示语,并在提示语开头引入了角色指令(如"你现在是一个新闻推荐系统"),以增强ChatGPT的领域适应能力。
一些作品没有提出通用框架,而是专注于为特定推荐任务设计有效的提示。文献[3]从 GPT-2 的预训练语料库中挖掘了电影推荐提示。文献[4] 引入了两种提示方法来提高 LLM 的顺序推荐能力:最近种序列重点提示(recency-focused sequential prompting)-使 LLMs 能够感知用户交互历史中的顺序信息;重采样技术(bootstrapping)-对候选项目列表进行多次洗牌,取平均分进行排序,以缓解位置偏差问题。
由于 LLM 允许的输入标记数量有限,因此很难在提示符中输入很长的候选列表。当对长的候选列表进行排序时,LLMs 的上下文长度限制将成为一个问题。为了解决这个问题,文献[5]提出了一种滑动窗口提示策略,即每次只对窗口中的候选词进行排序,然后按从后到前的顺序滑动窗口,最后多次重复这个过程,得到总的排序结果。
除了将LLMs作为推荐系统,一些研究还利用LLMs构建模型特征。GENRE[6]引入了三个提示,利用 LLMs 进行新闻推荐的三个特征增强子任务。具体来说,它使用 ChatGPT 根据摘要提炼新闻标题,从用户阅读历史中提取特征关键词,并生成合成新闻以丰富用户历史交互。通过结合这些由 LLMs 构建的特征,传统的新闻推荐模型可以得到显著改善。同样,NIR[7]设计了两种提示方式来生成用户偏好关键词,并从用户交互历史中提取有代表性的电影来改进电影推荐。
在实际应用中,除了排名模型之外,整个推荐系统一般还包括多个导入组件,如内容数据库、候选检索模型等。因此,使用 LLMs 进行推荐的另一条思路是将其作为整个系统的控制器。ChatREC[8]围绕ChatGPT设计了一个交互式推荐框架,通过多轮对话了解用户需求,并调用现有推荐系统提供结果。此外,ChatGPT还能控制数据库检索相关内容以补充提示,解决冷启动项目问题。GeneRec[9]提出了一个生成式推荐框架,并使用LLMs控制何时推荐现有项目或通过AIGC模型生成新项目。
总之,这些研究利用自然语言提示激活了 LLM 在推荐任务中的零点能力,提供了一种低成本、实用的解决方案。
情境学习(in-context learning)
情境学习(in-context learning)是 GPT-3 和其他 LLM 用来快速适应新任务和新信息的一种技术。通过一些示范输入-标签对,它们可以预测未见输入的标签,而无需额外的参数更新。因此,一些工作尝试在提示中添加示范示例,以使 LLM 更好地理解推荐任务。
对于顺序推荐,文献[4]通过增强输入交互顺序本身来引入示范示例。具体来说,他们把输入交互序列的前缀和相应的后缀配对起来作为示例。文献[1] 和 [2]设计了各种推荐任务的示范示例模板,实验结果也表明,上下文学习方法将提高 LLM 在大多数任务上的推荐能力。
然而,与提示学习(Prompting)相比,只有少数研究探讨了在推荐任务中使用语言模型(LLMs)的情境学习(In-context Learning of Language Models)。目前仍有许多悬而未决的问题,包括示范示例的选择以及示范示例的数量对推荐性能的影响。
4.1 调谐(Tuning)范式
如上所述,LLMs 具有很强的零样本/小样本学习能力,如果设计适当的提示,其推荐性能可以大大超过随机猜测。然而,以这种方式构建的推荐系统无法超越针对特定任务在特定数据上专门训练的推荐模型的性能,也就不足为奇了。因此,许多研究人员希望通过进一步微调或提示学习来提高 LLM 的推荐能力。本文按文献[10]的方法,将调优方法的范式分为两种不同的类型,分别是提示调优(prompt tuning)和指令调优(instruction tuning)。具体来说,在提示调整范式下,LLMs 或软提示的参数是针对特定任务(如评分预测)进行调整的;而在指令调整范式下,LLMs 则是针对不同指令类型的多个任务进行微调的。因此,LLMs 可以通过指令调整获得更好的归零能力。然而,我们认为目前对这两种微调范式还没有明确的划分或公认的定义。
提示调优(Prompt Tuning)
在这一范例中,LLM 通常将用户/项目信息作为输入,并输出用户对项目的偏好(如喜欢或不喜欢)或评分。例如,文献[11]提出将用户历史交互格式化为提示,其中每次交互都由物品信息表示,并将评分预测任务制定为两个不同的任务,分别是多类分类和回归。作者进一步研究了不同大小的 LLM,参数范围从 250M 到 540B 不等,并评估了它们在零拍中的性能。发现微调的 FLAN-T5-XXL (11B) 模型可以达到最佳效果。文献[12]提出的TALLRec通过两个调整阶段进行训练。具体来说,TALLRec 首先根据 Alpaca[13]的自我指导数据进行微调。然后,TALLRec 通过推荐调整进一步微调,其中输入是用户的历史序列,输出是 "是或否 "的反馈。
文献[14]提出将推荐任务格式化为下一个标记预测问题,并在电影推荐数据集上对所提出的方法进行了零拍摄和微调设置的评估。和微调设置下评估了所提出的方法。文章也观察到语言模型在推荐时表现出明显的语言偏差。此外,经过微调的 LLMs 可以学会如何推荐,但对于底层预测来说,语言偏差仍然存在。
除了直接对LLM进行微调外,一些研究还提出利用提示学习(Prompt Learning)来获得更好的性能。例如,文献[15]基于知识增强的提示学习设计了一个名为UniCRS的统一会话推荐系统。在这篇论文中,作者提出冻结LLMs的参数,并通过提示学习训练软提示来实现响应生成和项目推荐。文献[16]提出基于LLMs的生成能力提供用户可理解的解释。作者尝试了离散提示学习和连续提示学习,并进一步提出了两种训练策略,分别是顺序调整和推荐作为正则化。
指令调优(Instruction Tuning)
在这一范例中,LLM 针对具有不同指令类型的多种任务进行了微调。这样,LLMs 就能更好地与人类意图保持一致,实现更好的归零能力。例如,文献[17]提出针对五种不同类型的指令对T5模型进行微调,分别是顺序推荐、评分预测、解释生成、评论总结和直接推荐。在对推荐数据集进行多任务指令调整后,该模型可以实现对未见个性化提示和新项目的零点泛化能力。同样,文献[18]提出在三类任务上对M6模型进行微调,分别是评分任务、生成任务和检索任务。文献[19]首先从偏好、意图和任务形式三类关键方面设计了通用指令格式。然后,作者手工设计了39个指令模板,并在3B FLAN-T5-XL模型上自动生成了大量用户个性化指令数据用于指令调优。实验结果表明,这种方法优于包括 GPT-3.5 在内的几种竞争基线。
5. 发现总结
在本文中,我们系统地回顾了大型语言模型在推荐系统中的应用范例和适应策略,尤其是生成式语言模型。我们发现了它们在特定任务中提高传统推荐模型性能的潜力。**不过,有必要指出的是,这一领域的整体探索仍处于早期阶段。**研究人员可能会发现,确定最值得研究的问题和痛点具有挑战性。为了解决这个问题,我们总结了许多关于大规模模型推荐的研究得出的共同结论。这些发现凸显了某些技术挑战,并为该领域的进一步发展提供了潜在机遇。
5.1. 模型偏差(Model Bias)
-
位置偏差(Position Bias). 在推荐系统的生成式语言建模范式中,用户行为序列和推荐候选项等各种信息都是以文本顺序描述的形式输入语言模型的,这可能会引入语言模型本身固有的一些位置偏差。例如,候选项的顺序会影响基于 LLM 的推荐模型的排序结果,即 LLM 通常会优先考虑排序靠前的项目。文献[20]使用基于随机抽样的引导法来减轻候选项的位置偏差,并强调最近交互的项目以增强行为顺序。然而,这些解决方案的适应性还不够强,未来还需要更稳健的学习策略。
-
流行度偏差(Popularity Bias). LLM的排名结果会受到候选者受欢迎程度的影响。在 LLM 的预训练语料库中经常被广泛讨论和提及的热门项目往往会被排在较高的位置。解决这个问题具有挑战性,因为它与预训练语料库的组成密切相关。
-
公平性偏差(Fairness Bias). 预先训练好的语言模型会表现出与敏感属性相关的公平性问题,这些敏感属性会受到训练数据或某些任务注释所涉及的个人人口统计数据的影响。这些公平性问题可能导致模型在进行推荐时假定用户属于某个特定群体,从而在商业部署时可能引发争议问题。性别或种族导致的推荐结果偏差就是一个例子。解决这些公平性问题对于确保公平公正的推荐至关重要。
5.2. 推荐提示(Prompt)设计
-
用户/Item表征. 在实践中,推荐系统通常使用大量离散和连续特征来表示用户和项目。然而,大多数现有的基于 LLM 的工作仅使用名称来表示项目,并使用项目名称列表来表示用户,这不足以对用户和项目进行准确建模。此外,将用户的异构行为序列(如电子商务领域中的点击、加入购物车和购买)转化为自然语言进行偏好建模也至关重要。在传统的推荐模型中,ID 类特征已被证明是有效的,但将其纳入提示以提高个性化推荐性能也具有挑战性。
-
有限的上下文长度. LLM的上下文长度限制会制约用户行为序列的长度和候选项的数量,导致性能不理想。现有工作提出了一些技术来缓解这一问题,例如从用户行为序列中选择有代表性的项目[7]和候选列表的滑动窗口策略[21]。
5.3 有前途的能力
-
零样本/小样本推荐能力. 在多个领域数据集上的实验结果表明,LLMs在各种推荐任务中都具有令人印象深刻的零/少次推荐能力[4,1]。值得注意的是"小样本学习"(few-shot learning),等同于 “情境学习”(in-context learning)的 不会改变 LLMs 的参数。这表明 LLMs 有可能在数据有限的情况下缓解冷启动问题。不过,仍有一些问题有待解决,例如需要更明确的指导来选择具有代表性和有效的示范示例进行少次学习,以及需要更多领域的实验结果来进一步支持有关零次/少次推荐能力的结论。
-
可解释能力. 生成式 LLM 在自然语言生成方面表现出非凡的能力。因此,利用 LLMs 通过文本生成方式进行可解释的推荐是一种自然的想法。文献[1]进行了 ChatGPT 和一些基线在解释生成任务上的对比实验。结果表明,即使不进行微调,在上下文学习设置下,ChatGPT 的表现仍然优于一些有监督的传统方法。此外,根据人工评估,ChatGPT 的解释甚至比基本事实更清晰、更合理。在这些令人兴奋的初步实验结果的鼓舞下,微调 LLM 在可解释推荐中的表现将大有可为。
5.4 评估问题
-
输出控制. 正如我们之前提到的,许多研究通过提供精心设计的指令,将大规模模型用作推荐系统。对于这些 LLM,输出应该严格遵守给定的指令格式,例如提供二进制回答(是或否)或生成排序列表。然而,在实际应用中,LLM 的输出可能会偏离所需的输出格式。例如,模型可能会生成格式不正确的回答,甚至拒绝提供答案[2]。因此,如何确保更好地控制 LLM 的输出是一个亟待解决的问题。
-
评估标准. 如果 LLM 执行的任务是标准的推荐任务,如评级预测或项目排名,我们可以采用现有的评价指标进行评估,如 NDCG、MSE 等。然而,LLM 也有很强的生成能力,使其适用于生成式推荐任务[9]。按照生成式推荐范式,LLM 可以生成从未在历史数据中出现过的项目,并将其推荐给用户。在这种情况下,评估 LLM 的生成推荐能力仍然是一个未决问题。
-
数据集. 目前,该领域的大部分研究主要使用 MovieLens、Amazon Books 和类似基准等数据集来测试 LLM 的推荐能力和零样本/小样本学习能力。然而,这可能会带来以下两个潜在问题。首先,与现实世界的工业数据集相比,这些数据集的规模相对较小,可能无法完全反映 LLM 的推荐能力。其次,这些数据集中的项目(如电影和书籍)可能与 LLM 的预训练数据中出现的信息相关。这可能会在评估 LLM 的零点学习能力时引入偏差。目前,我们还缺乏一个合适的基准来进行更全面的评估。
除了上述突出发现外,大型语言模型的能力也存在一些局限性。例如,在针对特定领域任务训练模型或更新模型知识时,可能会出现知识遗忘的挑战[22]。另一个问题是不同大小的语言模型参数会产生不同的性能,使用过大的模型会导致推荐系统的研究和部署计算成本过高[4]。这些挑战也为该领域带来了宝贵的研究机会。
6. 结论
本文回顾了用于推荐系统的大型语言模型(LLMs)的研究领域。我们将现有工作分为判别模型和生成模型,然后通过领域自适应方式对其进行了详细说明。为了避免概念混淆,我们对基于 LLM 的推荐中的微调、提示、提示调整和指令调整进行了定义和区分。据我们所知,这是第一份专门针对用于推荐系统的生成式 LLM 的系统性最新综述,它进一步总结了众多相关研究的共同发现和挑战。因此,这项调查为研究人员全面了解 LLM 推荐和探索潜在研究方向提供了宝贵的资源。
参考文献
-
Junling Liu, Chao Liu, Renjie Lv, Kang Zhou, and Yan Zhang. Is chatgpt a good recommender? A preliminary study. CoRR, abs/2304.10149, 2023.
-
Sunhao Dai, Ninglu Shao, Haiyuan Zhao, Weijie Yu, Zihua Si, Chen Xu, Zhongxiang Sun, Xiao Zhang, and Jun Xu. Uncovering chatgpt’s capabilities in recommender systems. CoRR, abs/2305.02182, 2023.
-
Damien Sileo, Wout Vossen, and Robbe Raymaekers. Zero-shot recommendation as language modeling. In ECIR (2), volume 13186 of Lecture Notes in Computer Science, pages 223–230. Springer, 2022.
-
Yupeng Hou, Junjie Zhang, Zihan Lin, Hongyu Lu, Ruobing Xie, Julian J. McAuley, and Wayne Xin Zhao. Large language models are zero-shot rankers for recommender systems. CoRR, abs/2305.08845, 2023.
-
Weiwei Sun, Lingyong Yan, Xinyu Ma, Pengjie Ren, Dawei Yin, and Zhaochun Ren. Is chatgpt good at search? investigating large language models as reranking agent. CoRR, abs/2304.09542, 2023.
-
Qijiong Liu, Nuo Chen, Tetsuya Sakai, and Xiao-Ming Wu. A first look at llm-powered generative news recommendation. CoRR, abs/2305.06566, 2023.
-
Lei Wang and Ee-Peng Lim. Zeroshot next-item recommendation using large pretrained language models. CoRR, abs/2304.03153, 2023.
-
Yunfan Gao, Tao Sheng, Youlin Xiang, Yun Xiong, Haofen Wang, and Jiawei Zhang. Chat-rec: Towards interactive and explainable llms-augmented recommender system. CoRR, abs/2303.14524, 2023.
-
Wenjie Wang, Xinyu Lin, Fuli Feng, Xiangnan He, and Tat-Seng Chua. Generative recommendation: Towards next-generation recommender paradigm. CoRR, abs/2304.03516, 2023.
-
Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. Finetuned language models are zero-shot learners. In ICLR. OpenReview.net, 2022.
-
Wang-Cheng Kang, Jianmo Ni, Nikhil Mehta, Maheswaran Sathiamoorthy, Lichan Hong, Ed H. Chi, and Derek Zhiyuan Cheng. Do llms understand user preferences? evaluating llms on user rating prediction. CoRR, abs/2305.06474, 2023.
-
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. Tallrec: An effective and efficient tuning framework to align large language model with recommendation. CoRR, abs/2305.00447, 2023.
-
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/ tatsu-lab/stanford alpaca, 2023.
-
Yuhui Zhang, Hao Ding, Zeren Shui, Yifei Ma, James Zou, Anoop Deoras, and Hao Wang. Language models as recommender systems: Evaluations and limitations. 2021.
-
Xiaolei Wang, Kun Zhou, Ji-Rong Wen, and Wayne Xin Zhao. Towards unified conversational recommender systems via knowledge-enhanced prompt learning. In KDD, pages 1929–1937. ACM, 2022.
-
Lei Li, Yongfeng Zhang, and Li Chen. Personalized prompt learning for explainable recommendation. ACM Transactions on Information Systems, 41(4):1– 26, 2023.
-
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. Recommendation as language processing (RLP): A unified pretrain, personalized prompt & predict paradigm (P5). In RecSys, pages 299–315. ACM, 2022.
-
Zeyu Cui, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. M6-rec: Generative pretrained language models are open-ended recommender systems. CoRR, abs/2205.08084, 2022.
-
Junjie Zhang, Ruobing Xie, Yupeng Hou, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen. Recommendation as instruction following: A large language model empowered recommendation approach. CoRR, abs/2305.07001, 2023.
-
Yupeng Hou, Shanlei Mu, Wayne Xin Zhao, Yaliang Li, Bolin Ding, and Ji-Rong Wen. Towards universal sequence representation learning for recommender systems. In KDD, pages 585–593. ACM, 2022.
-
Weiwei Sun, Lingyong Yan, Xinyu Ma, Pengjie Ren, Dawei Yin, and Zhaochun Ren. Is chatgpt good at search? investigating large language models as reranking agent. CoRR, abs/2304.09542, 2023.
-
Joel Jang, Seonghyeon Ye, Sohee Yang, Joongbo Shin, Janghoon Han, Gyeonghun Kim, Stanley Jungkyu Choi, and Minjoon Seo. Towards continual knowledge learning of language models. In ICLR, 2022.