点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
君王掩面救不得,回看血泪相和流。
大家好,我是皮皮。
一、前言
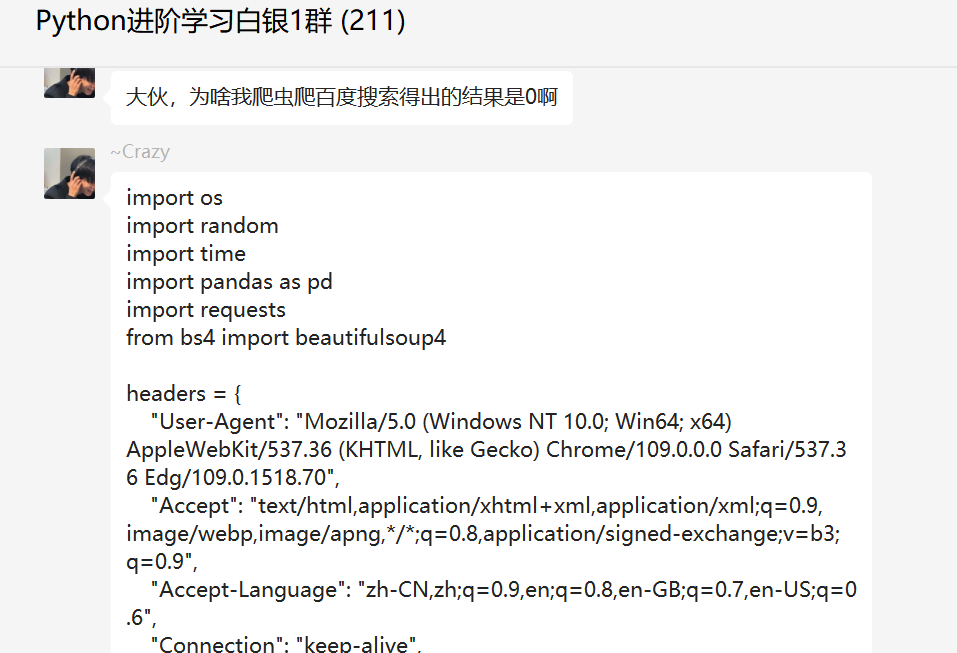
前几天在Python白银交流群【~Crazy】问了一个Python网络爬虫处理的问题,这里拿出来给大家分享下。
二、实现过程
这里【eric】给了一个指导,可能是网页结构变化。
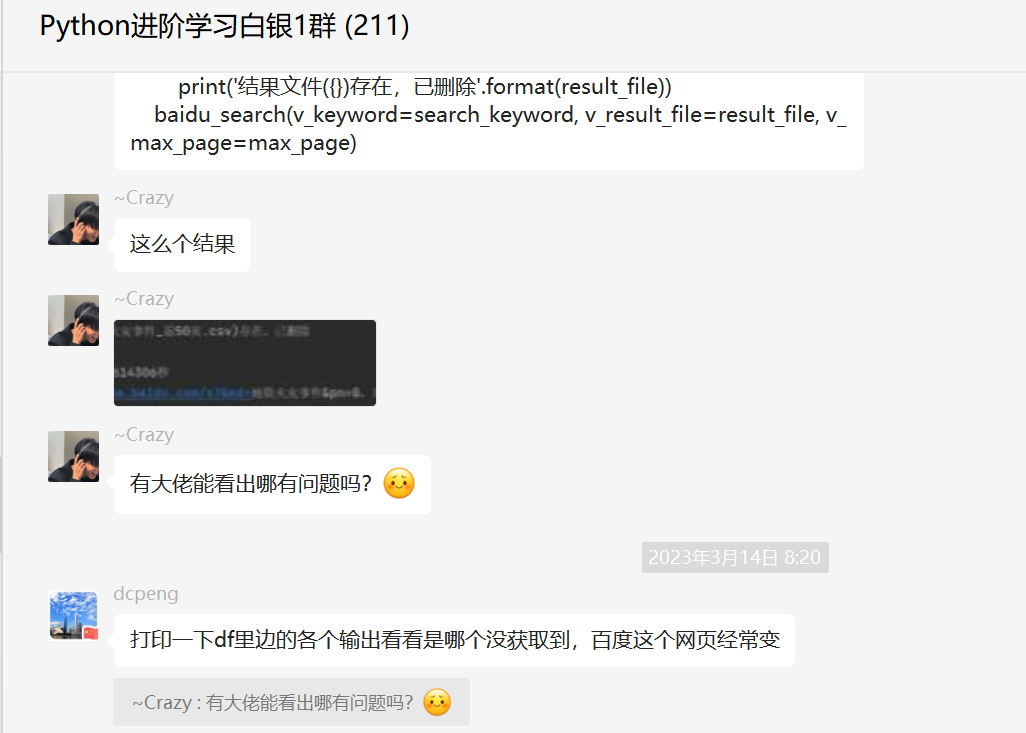
这里【甯同学】发现了问题所在,如下图所示:
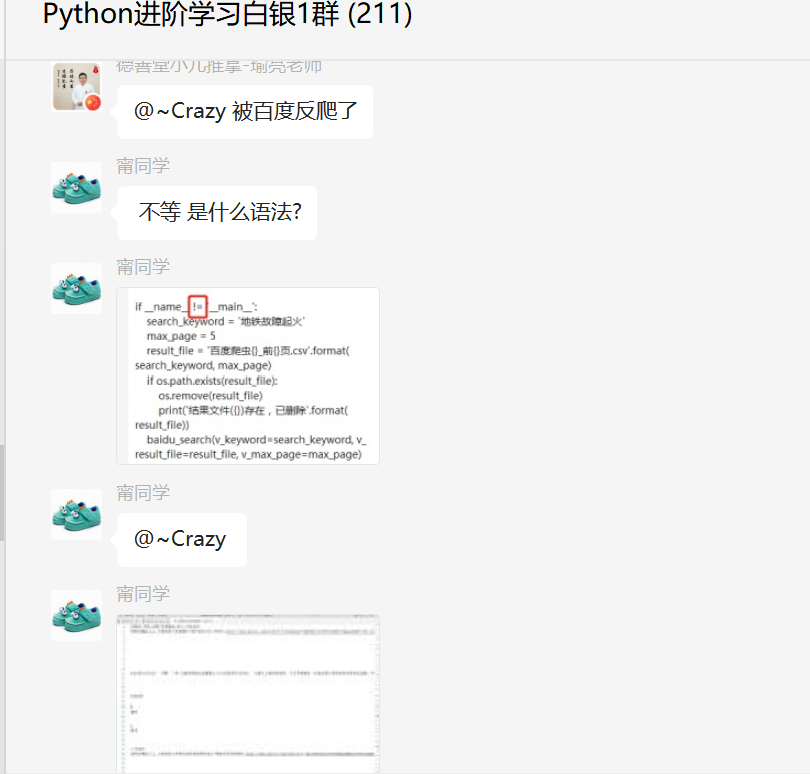
顺利地解决了粉丝的问题。
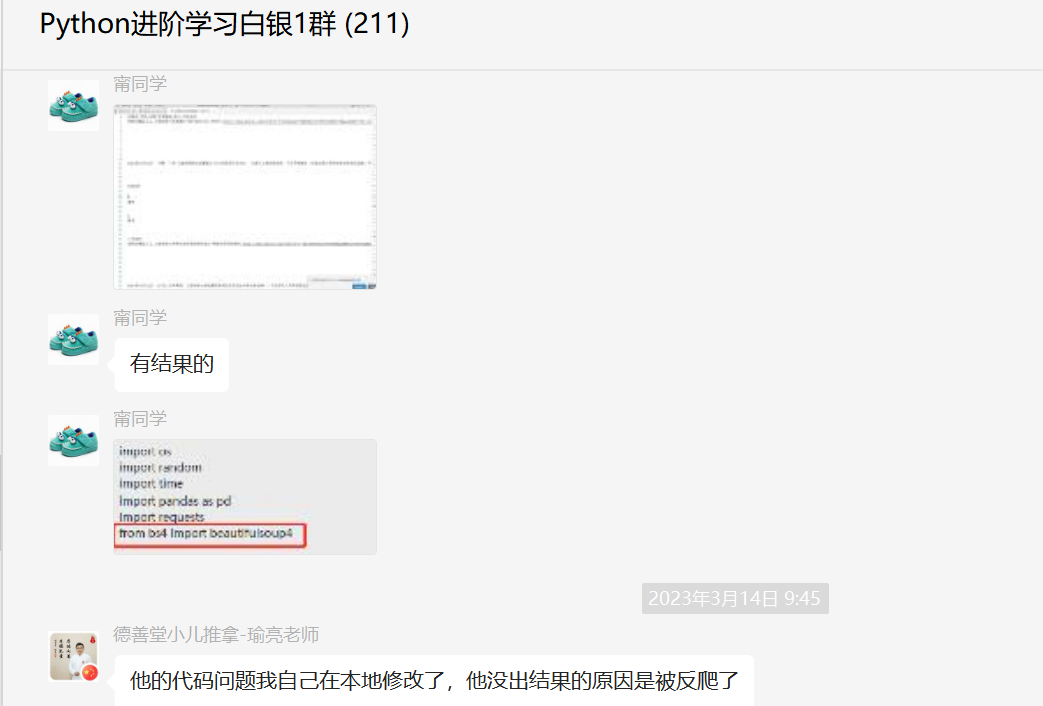
修改后的代码可以正常的爬出结果。
详细代码如下:
import os
import random
import time
import pandas as pd
import requests
from bs4 import BeautifulSoupheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.70","Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6","Connection": "keep-alive","Accept-Encoding": "gzip, deflate","Host": "www.baidu.com","Cookie": "BIDUPSID=E5DC3B4CB152A27DBF1D270E3503794B; PSTM=167872138 ZFY=DqhB1QpFu:APeJVy:AOeNNGsu1YREtMxYZgrqntwJNQlE:C; delPer=0; BD1"
}
def baidu_search(v_keyword, v_result_file, v_max_page):""":param v_keyword: 搜索关键词:param v_result_file: 保存文件名:param v_max_page: 爬取前几页:return:"""for page in range(v_max_page):print('开始爬取第{}页'.format(page + 1))# wait_seconds = random.uniform(5, 10)# print('开始等待{}秒'.format(wait_seconds))# time.sleep(wait_seconds)url = 'https://www.baidu.com/s?&wd=' + v_keyword + '&pn=' + str(page * 10)r = requests.get(url, headers=headers)html = r.textsoup = BeautifulSoup(html)result_list = soup.find_all(class_='result c-container xpath-log new-pmd')print('正在读取:{},共查询到{}个结果'.format(url, len(result_list)))kw_list = []page_list = []title_list = []href_list = []desc_list = []site_list = []for result in result_list:title = result.find('a').textprint('title is: ', title)href = result.find('a')['href']try:desc = result.find(class_="c-container").textexcept:desc = ""try:site = result.find(class_="c-color-gray").textexcept:site = ""kw_list.append(v_keyword)page_list.append(page + 1)title_list.append(title)href_list.append(href)desc_list.append(desc)site_list.append(site)df = pd.DataFrame({'关键词': kw_list,'页码': page_list,'标题': title_list,'百度链接': href_list,'简介': desc_list,'网站名称': site_list,})if os.path.exists(v_result_file):header = Noneelse:header = ['关键词', '页码', '标题', '百度链接', '简介', '网站名称']df.to_csv(v_result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')print('结果保存成功:{}'.format(v_result_file))if __name__ == '__main__':search_keyword = '地铁故障起火'max_page = 20result_file = '百度爬虫{}_前{}页.csv'.format(search_keyword, max_page)if os.path.exists(result_file):os.remove(result_file)print('结果文件({})存在,已删除'.format(result_file))baidu_search( search_keyword, result_file, max_page)三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【~Crazy】提问,感谢【甯同学】、【瑜亮老师】给出的思路和代码解析,感谢【eric】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting1),应粉丝要求,我创建了一些高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

------------------- End -------------------
往期精彩文章推荐:
if a and b and c and d:这种代码有优雅的写法吗?
Pycharm和Python到底啥关系?
都说chatGPT编程怎么怎么厉害,今天试了一下,有个静态网页,chatGPT居然没搞定?
站不住就准备加仓,这个pandas语句该咋写?

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~