整理 | 屠敏
出品 | CSDN(ID:CSDNnews)
据外媒报道,上周四,Google、微软、OpenAI 几家公司的 CEO 受邀去白宫,共论关于人工智能发展的一些重要问题。然而,让人有些想不通的是,深耕 AI 多年的 Meta 公司(前身为 Facebook)却没有在受邀之列。
没多久,更让 Meta CEO 扎克伯格扎心的是,一位官员对此解释称,本次会议“侧重的是目前在 AI 领域,尤其是面向消费者的产品方面,处于领先地位的公司。”
显然对于这样的解释,并不能让人信服,毕竟这一次受邀名单中还有一家由 OpenAI 的前成员创立的美国人工智能初创和公益公司 Anthropic。
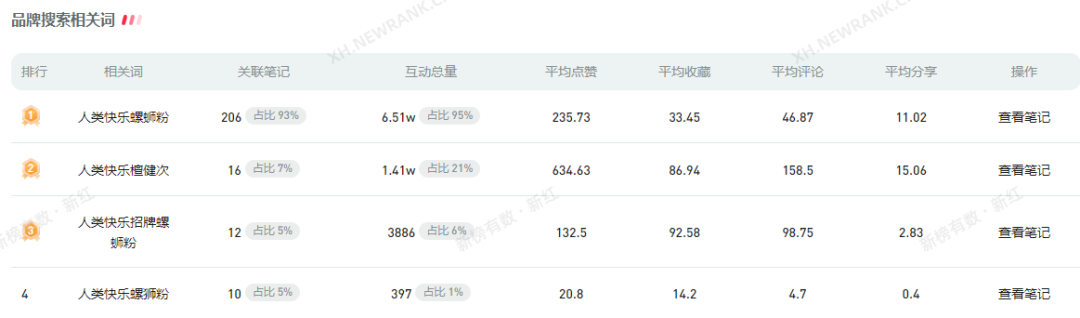
似乎是为了出一口“气”,也为证明自家的实力,相比 OpenAI、Google 推出闭源的 GPT-4、Bard 模型,Meta 在开源大模型的路上一骑绝尘,继两个月前开源 LLaMA 大模型之后,再次于 5 月 9 日开源了一个新的 AI 模型——ImageBind(https://github.com/facebookresearch/ImageBind),短短一天时间,收获了 1.6k 个 Star。
这个模型与众不同之处便是可以将多个数据流连接在一起,包括文本、图像/视频和音频、视觉、IMU、热数据和深度(Depth)数据。这也是业界第一个能够整合六种类型数据的模型。
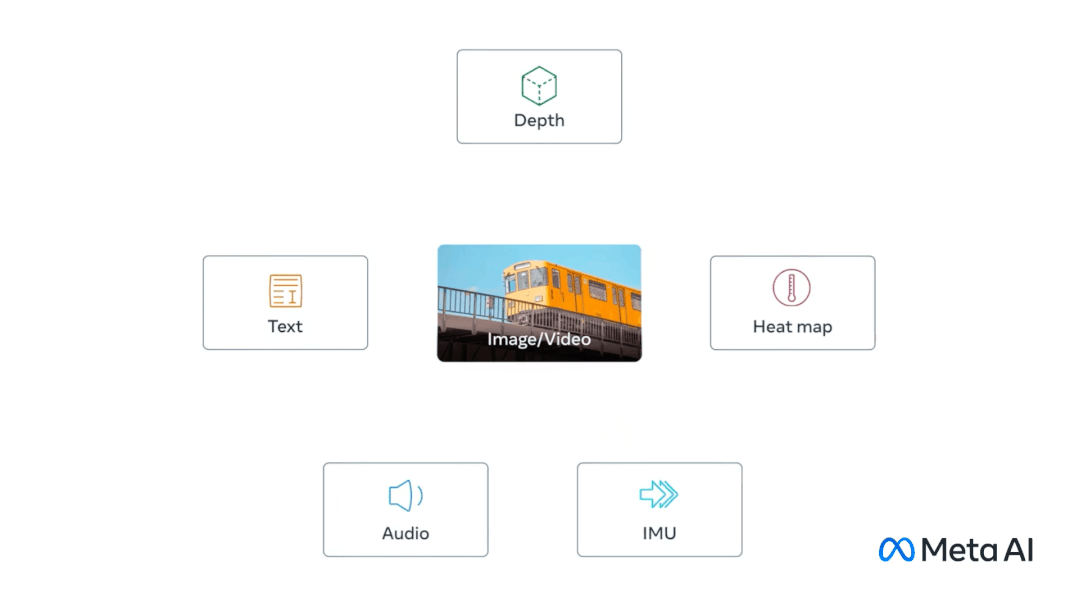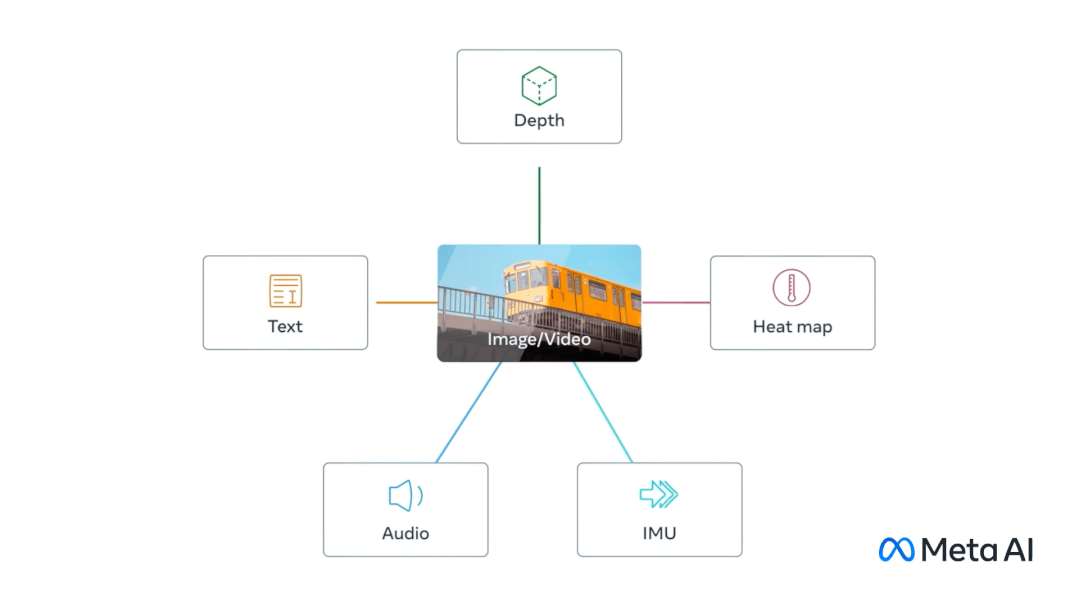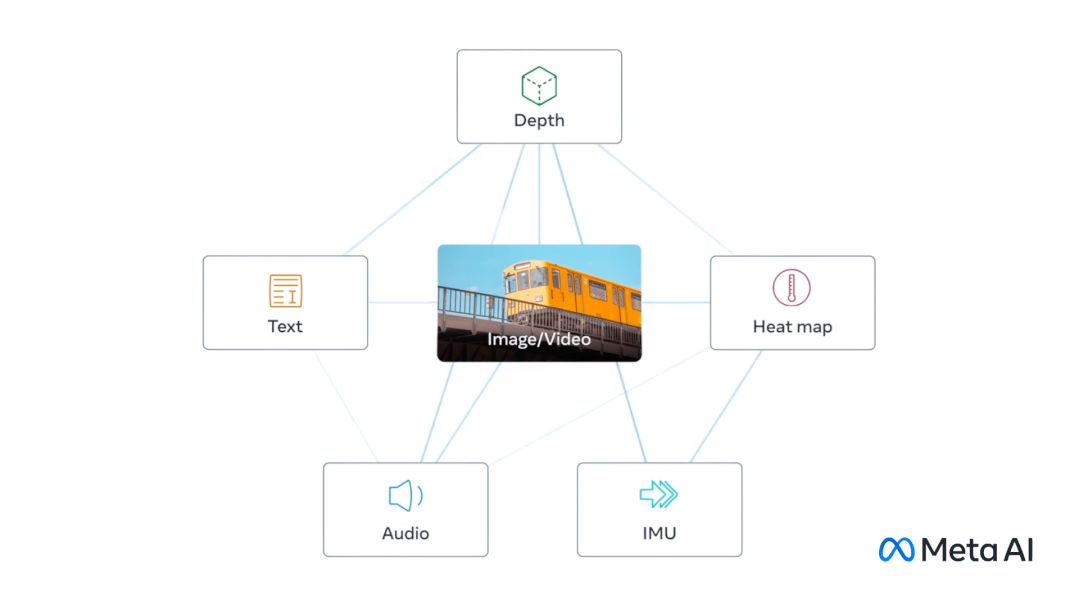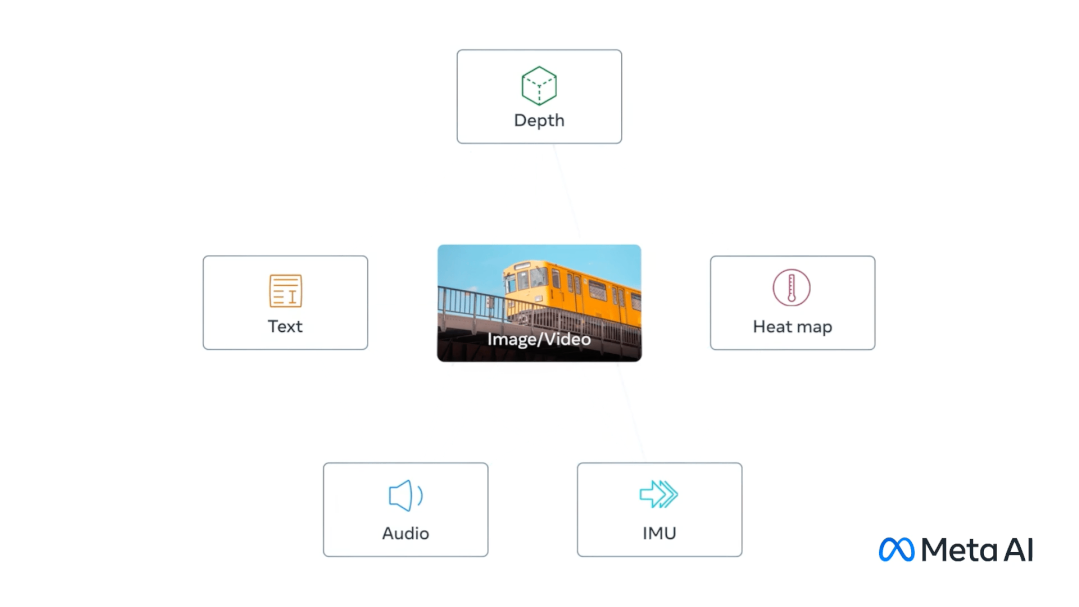

ImageBind 用图像对齐六模态,旨在实现感官大一统
简单来看,相比 Midjourney、Stable Diffusion 和 DALL-E 2 这样将文字与图像配对的图像生成器,ImageBind 更像是广撒网,可以连接文本、图像/视频、音频、3D 测量(深度)、温度数据(热)和运动数据(来自 IMU),而且它无需先针对每一种可能性进行训练,直接预测数据之间的联系,类似于人类感知或者想象环境的方式。

对此,Meta 在其官方博客中也说道,“ImageBind 可以胜过之前为一种特定模式单独训练的技术模型。但最重要的是,它能使机器更好地一起分析许多不同形式的信息,从而有助于推进人工智能。”
打个比喻,人类可以听或者阅读一些关于描述某个动物的文本,然后在现实生活中看到就能认识。
你站在繁忙的城市街道等有刺激性环境中,你的大脑会(很大程度上应该是无意识地)吸收景象、声音和其他感官体验,以此推断有关来往的汽车、行人、高楼、天气等信息。
在很多场景中,一个单一的联合嵌入空间包含许多不同种类的数据,如声音、图像、视频等等。
如今,基于 ImageBind 这样的模型可以让机器学习更接近人类学习。
在官方博客中,Meta 分享 ImageBind 是通过图像的绑定属性,只要将每个模态的嵌入与图像嵌入对齐,即图像与各种模式共存,可以作为连接这些模式的桥梁,例如利用网络数据将文本与图像连接起来,或者利用从带有 IMU 传感器的可穿戴相机中捕获的视频数据将运动与视频连接起来。

ImageBind 整体概览
从大规模网络数据中学到的视觉表征可以作为目标来学习不同模态的特征。这使得 ImageBind 能够对齐与图像共同出现的任何模式,自然地将这些模式相互对齐。与图像有强烈关联的模态,如热学和深度,更容易对齐。非视觉的模态,如音频和 IMU,具有较弱的关联性。
ImageBind 显示,图像配对数据足以将这六种模式绑定在一起。该模型可以更全面地解释内容,使不同的模式可以相互 "对话",并在不观察它们的情况下找到联系。
例如,ImageBind 可以在没有看到它们在一起的情况下将音频和文本联系起来。这使得其他模型能够 "理解 "新的模式,而不需要任何资源密集型的训练。

不过,该模型目前只是一个研究项目,没有直接的消费者和实际应用,但是它展现了生成式 AI 在未来能够生成沉浸式、多感官内容的方式,也表明了 Meta 正在以与 OpenAI、Google 等竞争对手不同的方式,趟出一条属于开源大模型的路。

ImageBind 强大的背后
与此同时,作为一种多模态的模型,ImageBind 还加入了 Meta 近期开源的一系列 AI 工具,包括 DINOv2 计算机视觉模型,这是一种不需要微调训练高性能计算机视觉模型的新方法;以及 Segment Anything(SAM),这是一种通用分割模型,可以根据任何用户的提示,对任何图像中的任何物体进行分割。
ImageBind 是对这些模型的补充,因为它专注于多模态表示学习。它试图为多种模式学习提供一个统一的特征空间,包括但不限于图像和视频。在未来, ImageBind 可以利用 DINOv2 的强大视觉特征来进一步提高其能力。

ImageBind 的性能
针对 ImageBind 性能,Meta 研究科学家还发布了一篇《IMAGEBIND: One Embedding Space To Bind Them All》(https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf)论文,分享了技术细则。

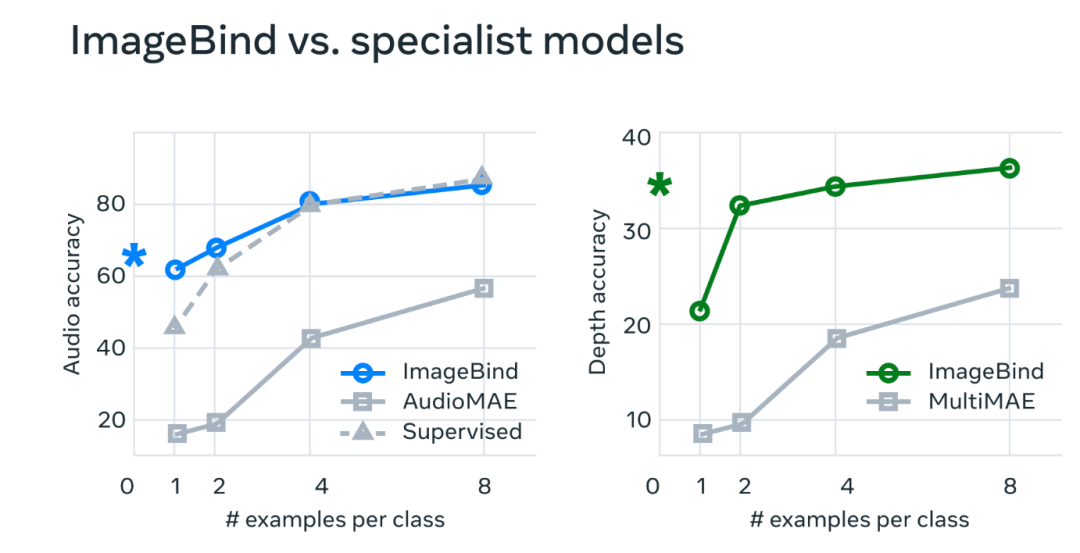
通过分析表明,ImageBind 模型的性能实际上可以通过使用很少的训练实例来提高。这个模型有新的出现的能力,或者说是扩展行为--也就是说,在较小的模型中不存在的能力,但在较大的版本中出现。这可能包括识别哪种音频适合某张图片或从照片中预测场景的深度。
而 ImageBind 的缩放行为随着图像编码器的强度而提高。
换句话说,ImageBind 对准各种模式的能力随着视觉模型的强度和大小而增加。这表明,较大的视觉模型有利于非视觉任务,如音频分类,而且训练这种模型的好处超出了计算机视觉任务。
在实验中,研究人员使用了 ImageBind 的音频和深度编码器,并将其与之前在 zero-shot 检索以及音频和深度分类任务中的工作进行了比较。
结果显示,ImageBind 可以用于少量样本的音频和深度分类任务,并且优于之前定制的方法。
最终,Meta 认为 ImageBind 这项技术最终会超越目前的六种“感官”,其在博客上说道,“虽然我们在当前的研究中探索了六种模式,但我们相信引入连接尽可能多的感官的新模式——如触觉、语音、嗅觉和大脑 fMRI 信号——将使更丰富的以人为中心的人工智能模型成为可能。”

ImageBind 可以用来干什么?
如果说 ChatGPT 可以充当搜索引擎、问答社区,Midjourney 可以被用来当画画工具,那么用 ImageBind 可以做什么?
根据官方发布的 Demo 显示,它可以直接用图片生成音频:
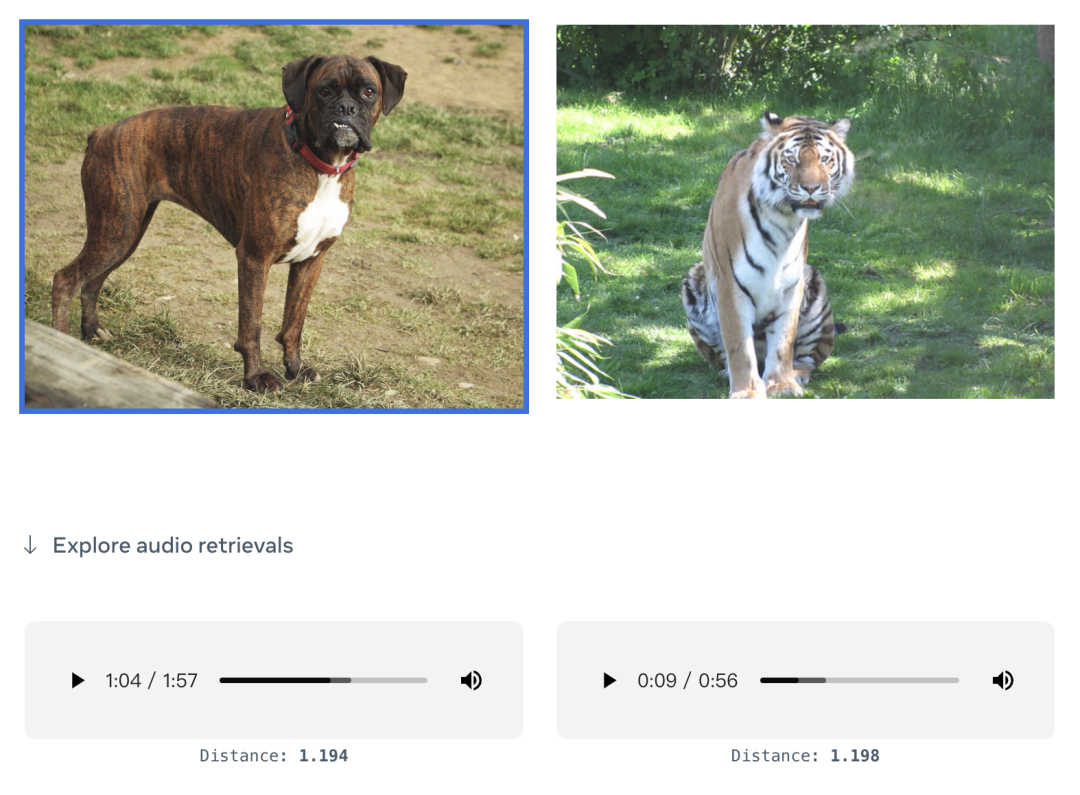
也可以音频生成图片:
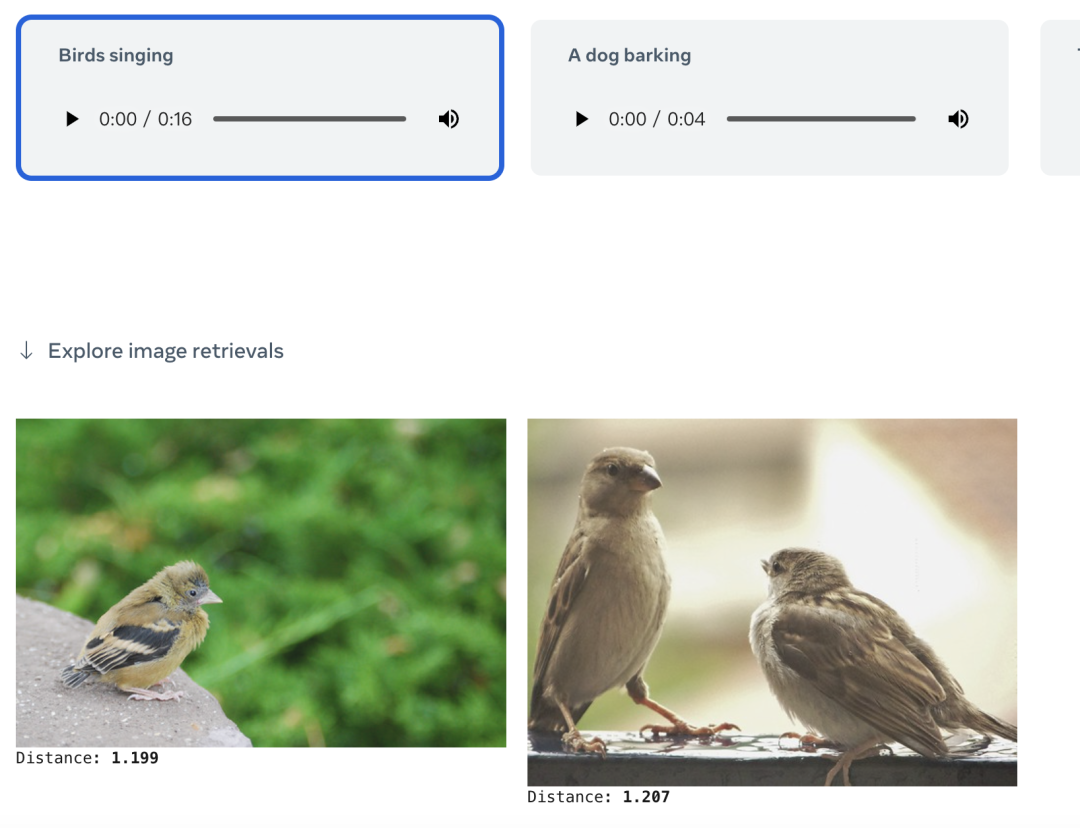
亦或者直接给一个文本,就可以检索相关的图片或者音频内容:
当然,基于 ImageBind 也可以给出一个音频+一张图,如“狗叫声”+海景图:
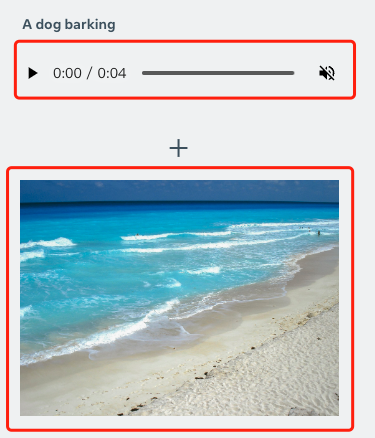
可以直接得到一张“狗在看海”的图:

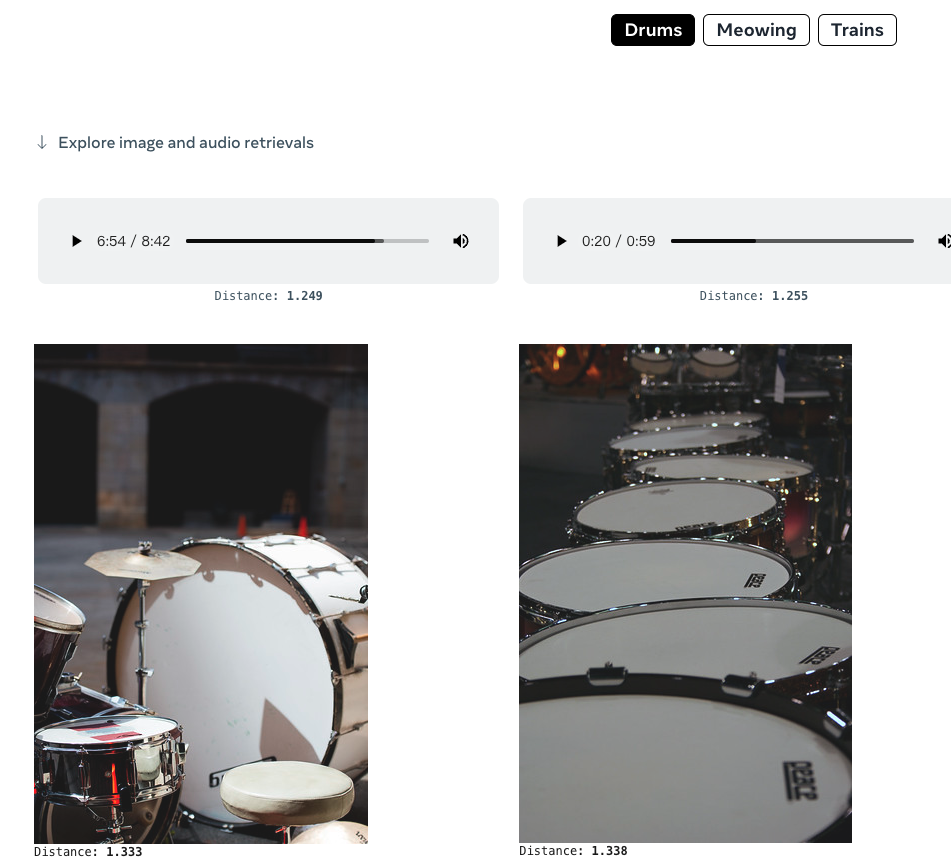
也可以给出音频,生成相应的图像:
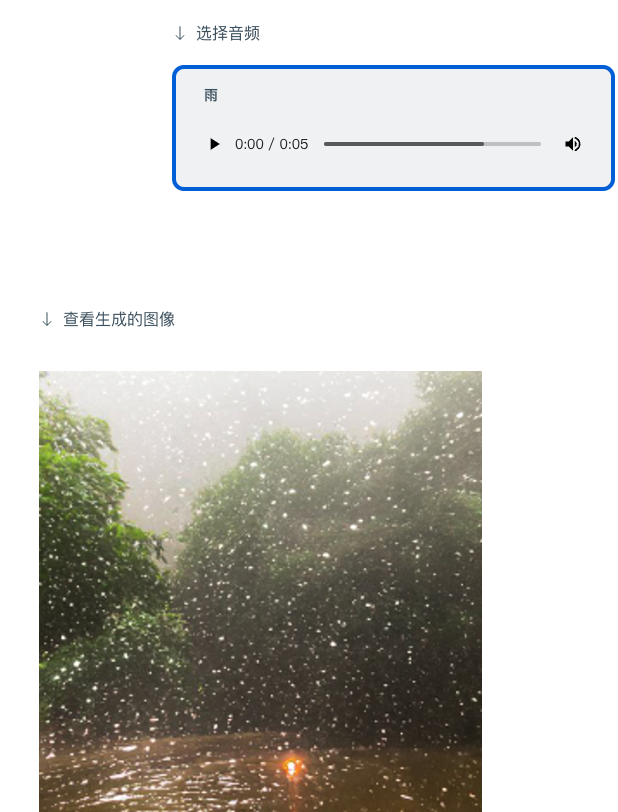
正如上文所述, ImageBind 给出了未来生成式 AI 系统可以以多模态呈现的方式,同时,结合 Meta 内部的虚拟现实、混合现实和元宇宙等技术和场景结合。
可以想象一下未来的头显设备,它不仅可以生成音频和视频输入,也可以生成物理舞台上的环境和运动,即可以动态构建 3D 场景(包括声音、运动等)。
亦或者,虚拟游戏开发人员也许最终可以使用它来减少设计过程中的大量跑腿工作。
同样,内容创作者可以仅基于文本、图像或音频输入制作具有逼真的音频和动作的沉浸式视频。
也很容易想象,用 ImageBind 这样的工具会在无障碍空间打开新的大门,譬如,生成实时多媒体描述来帮助有视力或听力障碍的人更好地感知他们的直接环境。
“在典型的人工智能系统中,每个模态都有特定的嵌入(即可以表示数据及其在机器学习中的关系的数字向量),”Meta 说。“ImageBind 表明可以跨多种模态创建联合嵌入空间,而无需使用每种不同模态组合对数据进行训练。这很重要,因为研究人员无法创建包含例如来自繁忙城市街道的音频数据和热数据,或深度数据和海边文本描述的样本的数据集。”
当前,外界可以通过大约 30 行 Python 代码就能使用这个多模式嵌入 API:


开源大模型是好事还是坏事?
ImageBind 一经官宣,也吸引了很多 AI 专家的关注。如卷积网络之父 Yann LeCun 也在第一时间分享了关于 ImageBind 的资料:
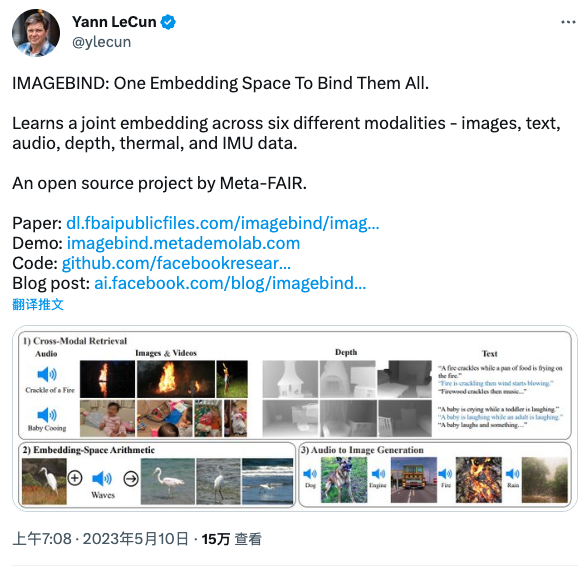
NVIDIA AI 科学家 Jim Fan 在 Twitter 上表示:
自从 LLaMA 以来,Meta 就在开源领域大放异彩。
ImageBind:Meta 最新的多模态嵌入,不仅涵盖了常规数据类型(文本、图像、音频),还包括深度、热量(红外)和 IMU 信号!
OpenAI Embedding 是 AI 驱动搜索和长期记忆的基础。ImageBind 是 Meta 的 Embedding API,用于丰富的多媒体搜索、虚拟现实甚至机器人技术。元宇宙将建立在向量的基础上。
通过对齐 6 种模态,你可以实现一些仅靠文本的 GPT-4 无法实现的花式功能:
跨模态检索:将其视为多媒体谷歌搜索
嵌入空间算术:无缝地组合不同的数据格式。
生成:通过扩散将任何模态映射到其他任何模态。
当然,这种通用的多模态嵌入在性能上优于领域特定的特征。
ImageBind:将它们全部绑定到一个嵌入空间。
也有网友评价道,「这项创新为增强搜索、沉浸式 VR 体验和高级机器人技术铺平了道路。对于 AI 爱好者和专业人士来说,激动人心的时刻即将到来!」。

不过,对于 Meta 采取开源的做法,也有人提出了质疑。
据 The Verge 报道,那些反对开源的人,如 OpenAI,表示这种做法对创作者有害,因为竞争对手可以复制他们的作品,并且可能具有潜在的危险,允许恶意行为者利用最先进的人工智能模型。
与之形成对比的是,支持开源的人则认为,像 Meta 开源 ImageBind 的做法有利于生态的快速建立与发展,也能集结全球的力量,帮助 AI 模型快速迭代和捕捉 Bug。
早些时候,Meta 开源的 LLaMA 模型只能用于研究用途,但是期间 LLaMA 模型在 4chan 上被泄露,有匿名用户通过 BT 种子公开了 LLaMA-65B—— 有 650 亿个参数的 LLaMA,容量为 220GB。
随着 LLaMA “被公开”,一大批基于这款大模型的衍生品,号称是 ChatGPT 开源替代品的工具在短时间内快速涌现,如跟着 LLaMA(美洲驼)名字走的“驼类”家族包含了:斯坦福大学发布的 Alpaca(羊驼,https://github.com/tatsu-lab/stanford_alpaca),伯克利、卡内基梅隆大学等高校研究人员开源的 Vicuna(骆马),还有基于 LLaMA 7B 的多语言指令跟随语言模型 Guanaco(原驼,https://guanaco-model.github.io/)等等。
面对这股新兴的力量,近日,在一位谷歌内部的研究人员泄露的一份文件中显示,在大模型时代,「Google 没有护城河,OpenAI 也没有」。其主要原因就是第三股——开源大模型的力量与生态正在崛起。
所以,OpenAI 和 Google 两家在 AI 大模型上你追我赶的竞争中,谁能笑到最后,也未必就不会是 Meta,我们也将拭目以待。对此,你是否看好开源大模型的发展?
相关阅读
论文地址:https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
GitHub 地址:https://github.com/facebookresearch/ImageBind
Demo:https://imagebind.metademolab.com/
参考
https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
https://www.theverge.com/2023/5/9/23716558/meta-imagebind-open-source-multisensory-modal-ai-model-research