微信聊天记录数据分析
或许每个人的微信列表里都有几个不舍删除的聊天记录,经年累月,这些聊天记录越积越多,终将成为你和这个人之间的美好回忆。这些回忆中有许多信息值得挖掘,尤其是情侣之间,将这些信息统计出来做一份“爱情报表”,一定会给自己的另一半带去一份惊喜。
工作内容
- 获取微信聊天数据库
- 解密数据库获取聊天数据
- 使用Python分析数据
- ECharts(或者pyecharts)做数据可视化
获取聊天数据库
这个教程主要是针对安卓手机用户的,对于IOS系统,不太清楚如何获取聊天数据库,毕竟IOS系统生态非常封闭。安卓用户获取微信聊天数据库的方法很简单:
-
首先需要获取手机root权限
-
安装RE文件管理器(Root Explorer)
-
打开RE文件管理器,在路径/data/data/com.tencent.mm/MicroMsg下找到一个由32位字符串命名的文件夹,比如我的文件夹如下,这个32位字符串是mm+uin码进行md5加密后得到的(uin码后面会说)
-
进入该文件夹,找到EnMicroMsg.db,即为你的微信聊天数据库,将其复制出来并传到电脑上

解密数据库获取聊天数据
解密微信数据库,在网上有很多的教程,归结起来就是,数据库密码=md5(IMEI+uin)[0:7],意思就是,将你手机的IMEI码和你微信的uin码加起来用md5加密后得到一串32位的字符串,取其前7位即为数据库的密码。但是在操作的过程中会有一些坑。
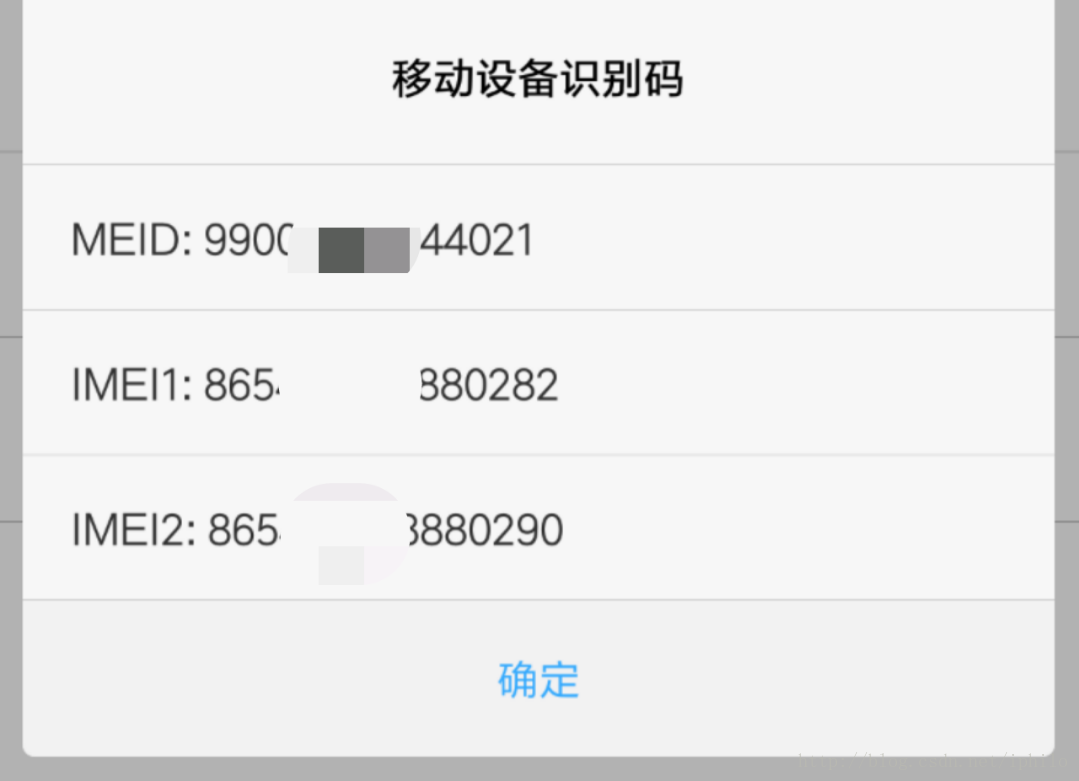
- 获取IMEI码,即打开手机的拨号界面,输入* #06#,这时就会自动弹出你的IMEI码,但是对于双卡用户,操作的时候会有些懵,比如我用的小米6,输入* #06#后会出来3个码……其实也不用懵,MEID码直接无视,下面两个IMEI码的话,一般都是取第一个,当然不放心的话可以两个都试试。
- 获取uin码,再次打开RE文件管理器,在路径/data/data/com.tencent.mm/shared_prefs下找到auth_infokey_prefs.xml文件并打开,找到如下文字,其中value后面跟着的就是你的uin码了,我的是8位,每个人uin码的位数可能不一样。
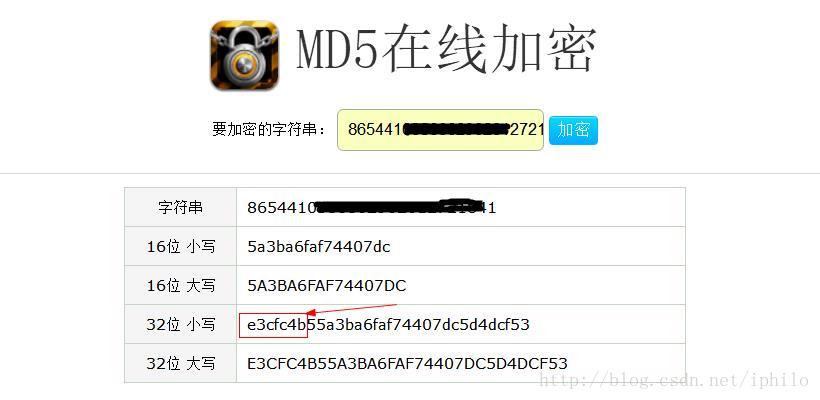
- 在获取到IMEI码和uin码之后就可以相加后使用md5加密得到密码了。加密可以使用在线md5工具,密码是小写32位md5值的前7位。
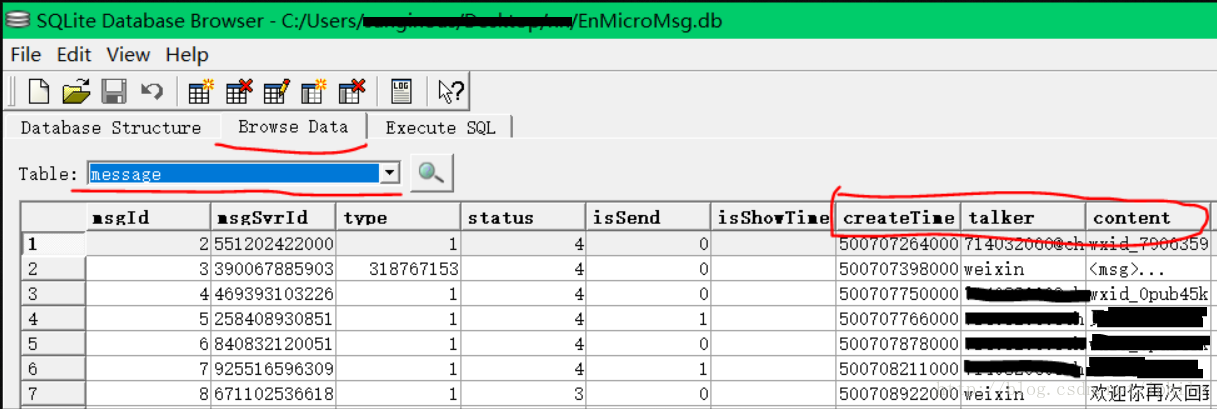
- 获取到密码后就是解密数据库了。工具是sqlcipher.exe,我在网上找了很多版本,这个是最好用的:https://pan.baidu.com/s/1pLlLOA6ZDV5Nl0beMFvM4A (密码:kfe2)。打开后找到message表,这里就是全部的聊天记录了,关键的信息就是createTime、talker以及content这三列了,值得注意的是,数据库中保存的时间数据是时间戳,并且每一个数据后面都多出了三位0,在进行数据分析时需要把这三个0剔除。然后我们依次点击File–>Export–>Table as CSV file,将message表导出,我们就可以开始进行数据分析了。导出的文件默认有.csv和.txt两种,后缀需要手动写上去。此外,如果直接读取这个文件的话可能会存在编码错误的问题,建议在保存csv文件以后,右键使用记事本打开,然后再另存为一个新的文件,编码使用utf-8。


使用Python分析数据
呼……终于进入正题了。聊天记录包含了非常丰富的数据,这里我只做了两个比较简单的例子,一个是针对时间做聊天时间段分布的统计;一个是针对内容做字符匹配,统计一些高频词汇出现的次数,比如“早安”、“晚安”、“想你”、“爱”等等(你懂的)。
读取数据
使用pandas读取csv文件里的数据,我们需要的数据在6、7、8三列:
chat = pd.read_csv('chat.csv', sep=',', usecols=[6,7,8])
然后定义两个list,分别用来存储聊天记录的时间和内容,定义变量myGirl,赋值为想要提取出来的联系人的微信号:
myGirl = 'wxid_xxxxxxxx'
chat_time = []
chat_content = []
for i in range(len(chat)-1):content = chat[i:i+1]if content['talker'].values[0] == myGirl:t = content['createTime'].values[0]//1000#除以1000用以剔除后三位0c = content['content'].values[0]chat_time.append(t)chat_content.append(c)
这时chat_time和chat_content里就存储着你和女(男)朋友所有的聊天数据了。接下来需要定义一个函数to_hour()将时间戳转换为24h进制,然后用列表推导式批量进行转换:
def to_hour(t):struct_time = time.localtime(t)#将时间戳转换为struct_time元组hour = round((struct_time[3] + struct_time[4] / 60), 2)return hourhour_set = [to_hour(i) for i in chat_time]
绘图
聊天时段的分布可以使用seaborn绘制核密度图,非常简洁,一句话搞定,当然如果想让图片好看些的话还需要做额外的配置:
import seaborn as sns
from matplotlib.font_manager import *#如果想在图上显示中文,需导入这个包
myfont = FontProperties(fname=r'C:\Windows\Fonts\MSYH.TTC',size=22)#标题字体样式
myfont2 = FontProperties(fname=r'C:\Windows\Fonts\MSYH.TTC',size=18)#横纵坐标字体样式
sns.set_style('darkgrid')#设置图片为深色背景且有网格线
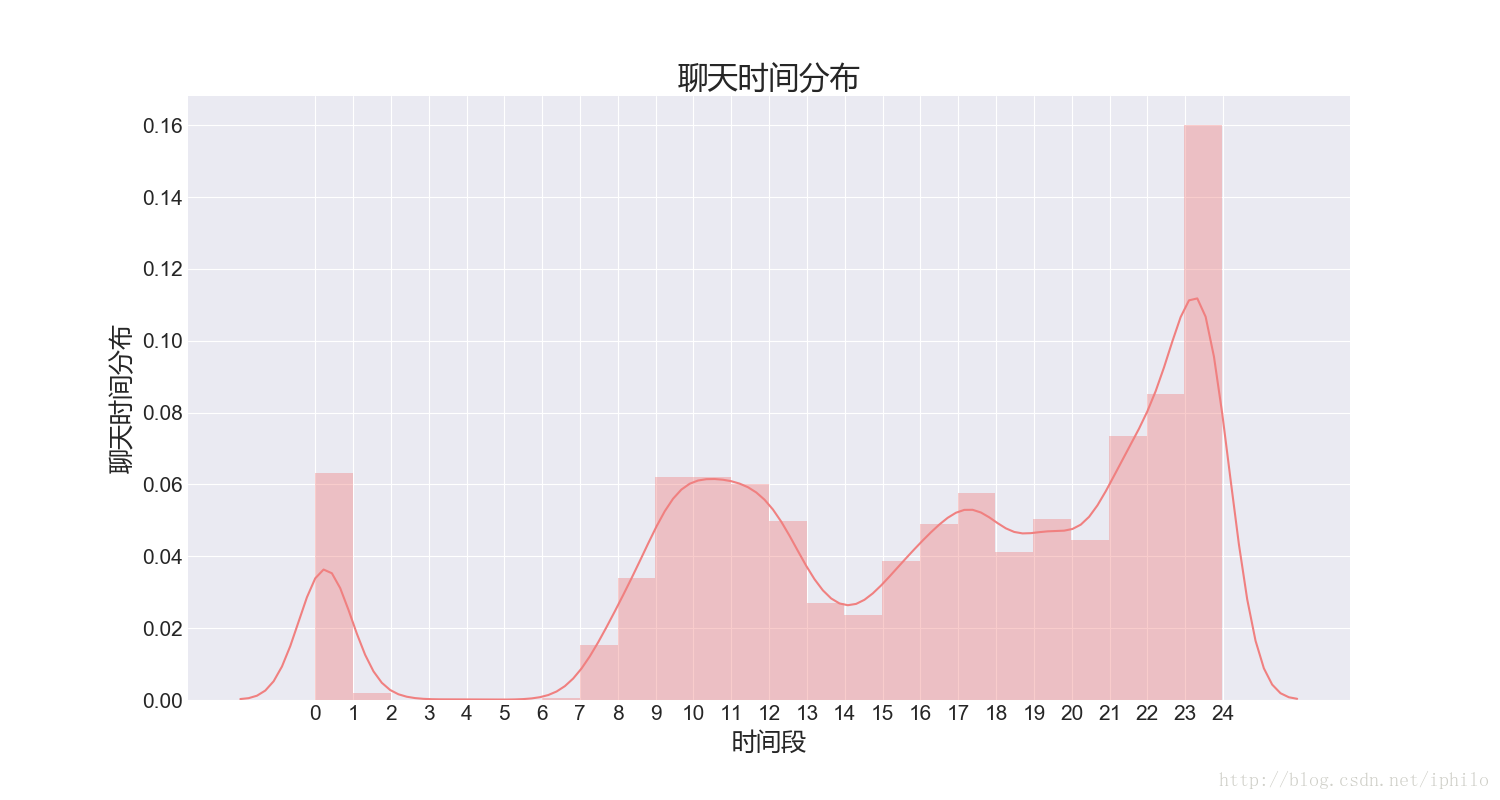
sns.distplot(hour_set, 24, color='lightcoral')
plt.xticks(np.arange(0, 25, 1.0), fontsize=15)
plt.yticks(fontsize=15)
plt.title('聊天时间分布', fontproperties=myfont)
plt.xlabel('时间段', fontproperties=myfont2)
plt.ylabel('聊天时间分布', fontproperties=myfont2)
fig = plt.gcf()
fig.set_size_inches(15,8)
fig.savefig('chat_time.png',dpi=100)
plt.show()
上面是我经常使用的一些配置方案。通过核密度图可以看出,我和我女朋友属于夜猫子类型的,经常在半夜聊天,23点至24点的峰值特别高。
不过虽然“lightcoral”的配色非常少女,但是如果你的女(男)朋友并不了解数据分析和统计学的话,上面的图片还是显得有些过于“专业”了,可能只会得到一个“哦(冷漠脸)”字作为回应。因此,一个合适的数据展示方式就显得尤为重要了。
使用ECharts
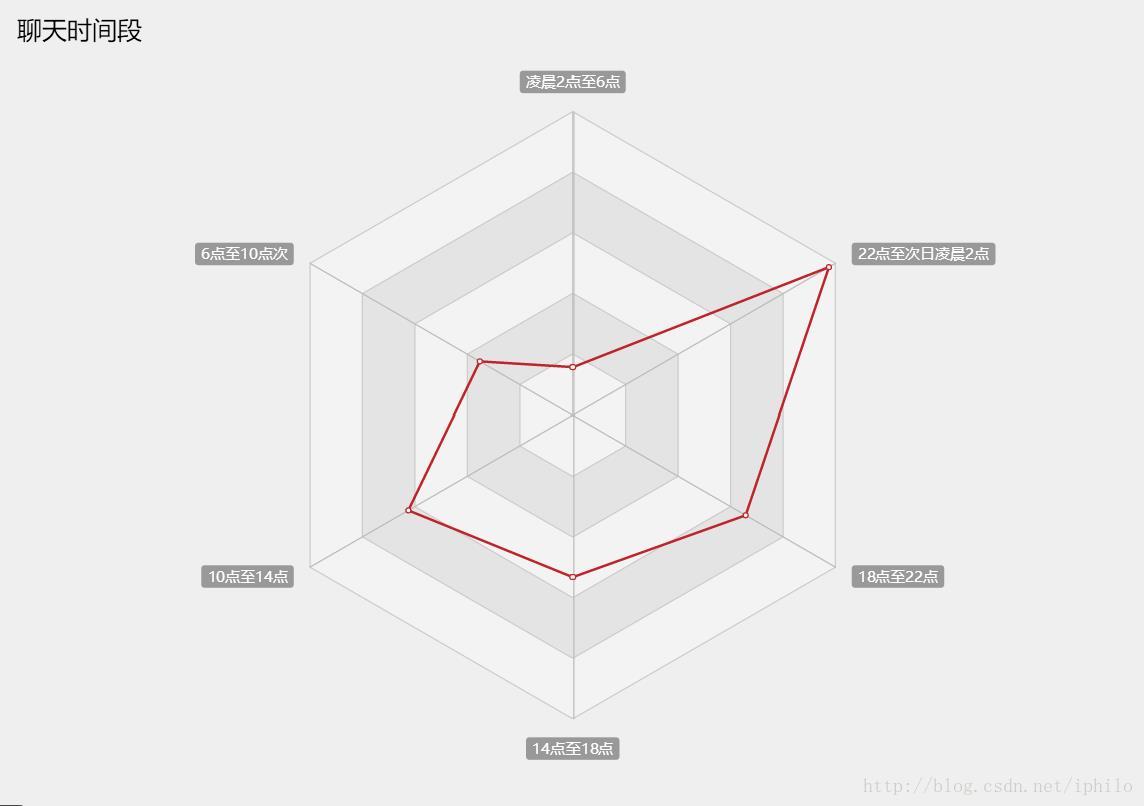
ECharts(http://echarts.baidu.com/)是一个开源的js组件,绘制的图表种类繁多而且很好看,使用起来也很方便,当然如果你并没有接触过js甚至对其有些抵触,那么也可以安装pyecharts(https://github.com/pyecharts/pyecharts),可以看做是ECharts的Python版,操作更为简洁。这里我使用的是ECharts。首先我们需要在Python中统计hour_set里不同时间段的聊天记录条数,时间段可以任意划分,然后打开ECharts官网,找到官方实例中的雷达图,将统计出的各时间段聊天数据直接替换进去就可以了:
option = {title: {text: '聊天时间段',textStyle: {color: '#000',fontSize: 20}},//toolbox配置项可以在网页上直接生成下载图片的按钮而不用截图toolbox: {show: true,feature: {saveAsImage: {show:true,excludeComponents :['toolbox'],pixelRatio: 2}}},tooltip: {},radar: {// shape: 'circle',name: {textStyle: {color: '#fff',backgroundColor: '#999',borderRadius: 3,padding: [3, 5]}},indicator: [{ name: '凌晨2点至6点', max: 400},{ name: '6点至10点次', max: 400},{ name: '10点至14点', max: 400},{ name: '14点至18点', max: 400},{ name: '18点至22点', max: 400},{ name: '22点至次日凌晨2点', max: 400}]},series: [{name: '聊天时间段',type: 'radar',// areaStyle: {normal: {}},data : [{value : [63, 141, 250, 213, 263, 390],name : '聊天时段'}]}]
};
雷达图的显示方式比上面的核密度图要友善的多,如果是在网页上浏览的话效果更好,因为是可以动的。
统计特殊数据绘制字符云
对于所有夜猫子类型的人来说,可能都会有深夜聊天的经历,比如上面的雷达图中,凌晨2点至清晨6点之间还存在少量的聊天记录,那些不眠的夜晚你可能已经遗忘,但数据会帮你回忆起一切。我们定义一个deep_night列表,在统计hour_set中的时间时,将位于2-6之间的时间数据和对应的聊天数据存进deep_night中,然后将数据写进Excel表中:
import xlwt
wbk = xlwt.Workbook()
sheet = wbk.add_sheet('late')
for i in range(len(deep_night)):sheet.write(i,0,time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(deep_night[i][0])))sheet.write(i,1,deep_night[i][1])
wbk.save('聊得很晚.xls')
然后再次祭出ECharts,进入官网,找到字符云实例,将Excel中的深夜聊天内容直接替换上去就可以了。
option = {tooltip: {},series: [{type: 'wordCloud',gridSize: 20,sizeRange: [12, 50],rotationRange: [0, 45],shape: 'circle',textStyle: {normal: {color: function() {return 'rgb(' + [Math.round(Math.random() * 200),Math.round(Math.random() * 200),Math.round(Math.random() * 200)].join(',') + ')';}},emphasis: {shadowBlur: 10,shadowColor: '#333'}},data: [{name: '呵呵',value: 800,textStyle: {normal: {color: 'black'},emphasis: {color: 'red'}}}, {name: '别傻了,这是假数据',value: 618}, {name: 'ECharts好用',value: 438}, {name: '哈哈。。',value: 405}, {name: '点个赞',value: 246}, {name: '世界人民大团结万岁',value: 224}, {name: 'naive',value: 189}, {name: '还得学习一个',value: 148}, {name: '闷声发大财!',value: 111}, {name: '学习使我快乐',value: 965}, {name: '葡萄牙1:0!!!',value: 582}, {name: '+1s',value: 555}, {name: '两点半的夜晚 哈哈哈哈',value: 550}]}]
};
这个官方实例很简单,字符云的形状是杂乱、随机的,不过我们可以设置maskImage,即整个字符云可以摆成maskImage的形状,大家可以去社区里找找别人做的方案(想想把你和女(男)朋友的聊天记录用字符云的形式摆成一个心形。。。还要啥自行车啊)。

匹配高频字符
这一部分也不难,说白了就是对所有聊天记录做一个字符的正则匹配。正则表达式在爬虫中经常使用,虽然语法很多很繁杂,但是对于匹配字符来说就很简单了,写法很固定。比如我想匹配一句话中“爱”字出现的次数,定义一个pattern=’. * ?(爱). * ?’,这里.*?代表匹配任意字符,“爱”字一定要打括号,然后调用re模块的findall()方法进行匹配,得到的结果是全由“爱”字组成的list,取其长度就是“爱”字出现的次数了:
import re
pattern = '.*?(爱).*?'
string = '我爱吃西瓜,你爱不爱吃。'
result = re.findall(pattern, string)
result
Out[5]: ['爱', '爱', '爱']
len(result)
Out[6]: 3
接下来我们要写若干个pattern,即你想要匹配哪几个词,然后将这几个pattern放进一个list中:
pattern_love = '.*?(爱).*?'
pattern_morning= '.*?(早安).*?'
pattern_night = '.*?(晚安).*?'
pattern_miss = '.*?(想你).*?'
pattern_set = [pattern_love, pattern_morning, pattern_night, pattern_miss]
最后写一个循环嵌套,外层遍历聊天内容,内层遍历pattern_set:
start = datetime.datetime.now()
statistic = [0,0,0,0]
for i in range(len(chat_content)):for j in range(len(pattern_set)):length = len(re.findall(pattern_set[j], str(chat_content[i])))static[j] += length
result = {'爱': static[0],'早安': static[1],'晚安': static[2],'想你': static[3]}
print(result)
end = datetime.datetime.now()
print('\n..........\n字符统计结束,用时: {}\n............\n'.format(end-start))
用同样的方法还可以匹配各种字符,字符越多时间越久,我在12万多条记录中匹配15个字符,大概耗时4分钟,CPU为i7-6700K,在真正的做大数据分析的在时候,这一步是最耗时的,基本都需要进行分布式运算了。数据展示方面可以使用字符云,不同字符的value值就是其出现的次数,出现次数较多的字符自然就会大一些。当然也可以学习前段时间网易云音乐展示数据的方式:
这一年
你一共说了999次爱你热衷聊天
喜欢在午夜倾诉衷肠11月11日大概是很特别的一天这一天里你把“早安”反复说了11次(早安怪???)
……
呃呃,总之大家可以发挥自己的想象。如果想要写的像网易云音乐那样详细的话,就必须把聊天内容和聊天时间一一对应起来,而不能像上面的例子一样将内容和时间分开讨论。当然操作也很简单,只需要定义一个二维list就可以了,第一维是时间,第二维是内容,不过数据库中存储的数据时间是混乱的,并不是按时间递增的,所以我们还需要自己处理一下,也即以list第一维为对象进行排序带动第二维跟着排序:
from operator import itemgetter
chat_all = []
myGirl = 'wxid_xxxxxxxx'
for i in range(len(chat)-1):content = chat[i:i+1]if content['talker'].values[0] == myGirl:t = content['createTime'].values[0]//1000c = content['content'].values[0]chat_all.append([t,c])
chat_all = sorted(chat_all, key=itemgetter(0))#以第一维为索引排序
这个时候chat_all里就是按照时间顺序排序好的数据了,剩下的就是按照上面的方法进行字符匹配等等操作,也可以挖掘其他好玩的信息,比如结合机器学习算法进行某些信息的预测,对于时间序列数据使用LSTM网络进行预测再合适不过了,当然聊天行为属于社会活动,想要做出更加准确的预测还需要涉及博弈……总之,对上面的一些数据分析来说,编程的难度并不大,主要是发挥自己的想象力,能够在同样的数据中挖掘出独特且有意义的信息是数据分析很重要的一点,同样重要的还有数据的展示方式,毕竟多数人都是外貌协会,好看的展示方式才更得人心。完整代码如下github链接(https://github.com/SunGinous/WeChat_Analysis):
import pandas as pd
import time
import seaborn as sns
import matplotlib.pyplot as plt
import datetime
import numpy as np
import re
from operator import itemgetter
from matplotlib.font_manager import *#导入这个包,可以添加中文字体
import xlwtchat_file = '自己的csv文件'
myGirl = '目标联系人的微信号'''' 读取原数据 '''
chat = pd.read_csv(chat_file, sep=',', usecols=[6,7,8])
chat_time = []
chat_content = []
chat_all = []
for i in range(len(chat)-1):content = chat[i:i+1]if content['talker'].values[0] == myGirl:t = content['createTime'].values[0]//1000c = content['content'].values[0]chat_time.append(t)chat_content.append(c)chat_all.append([t,c])
chat_all = sorted(chat_all, key=itemgetter(0))#以第一维为索引排序''' 转换时间格式 '''
def to_hour(t):struct_time = time.localtime(t)hour = round((struct_time[3] + struct_time[4] / 60), 2)return hour
hour_set = [to_hour(i) for i in chat_time]print('\n.......................\n开始画图\n.......................')
from matplotlib.font_manager import *#如果想在图上显示中文,需导入这个包
myfont = FontProperties(fname=r'C:\Windows\Fonts\MSYH.TTC',size=22)#标题字体样式
myfont2 = FontProperties(fname=r'C:\Windows\Fonts\MSYH.TTC',size=18)#横纵坐标字体样式
sns.set_style('darkgrid')#设置图片为深色背景且有网格线
sns.distplot(hour_set, 24, color='lightcoral')
plt.xticks(np.arange(0, 25, 1.0), fontsize=15)
plt.yticks(fontsize=15)
plt.title('聊天时间分布', fontproperties=myfont)
plt.xlabel('时间段', fontproperties=myfont2)
plt.ylabel('聊天时间分布', fontproperties=myfont2)
fig = plt.gcf()
fig.set_size_inches(15,8)
fig.savefig('chat_time.png',dpi=100)
plt.show()
print('\n.......................\n画图结束\n.......................')''' 聊天时段分布 '''
print('\n.......................\n开始聊天时段统计\n.......................')
time_slice = [0,0,0,0,0,0]
deep_night = []
for i in range(len(hour_set)):if hour_set[i]>=2 and hour_set[i]<6:time_slice[0] += 1deep_night.append([chat_time[i], chat_content[i]])elif hour_set[i]>=6 and hour_set[i]<10:time_slice[1] += 1elif hour_set[i]>=10 and hour_set[i]<14:time_slice[2] += 1elif hour_set[i]>=14 and hour_set[i]<18:time_slice[3] += 1elif hour_set[i]>=18 and hour_set[i]<22:time_slice[4] += 1else:time_slice[5] += 1
labels = ['凌晨2点至6点','6点至10点','10点至14点','14点至18点','18点至22点','22点至次日凌晨2点']
time_distribution = {labels[0]: time_slice[0],labels[1]: time_slice[1],labels[2]: time_slice[2],labels[3]: time_slice[3],labels[4]: time_slice[4],labels[5]: time_slice[5]}
print(time_distribution)''' 深夜聊天记录 '''
wbk = xlwt.Workbook()
sheet = wbk.add_sheet('late')
for i in range(len(deep_night)):sheet.write(i,0,time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(deep_night[i][0])))sheet.write(i,1,deep_night[i][1])
wbk.save('聊得很晚.xls')
print('\n.......................\n聊天时段统计结束\n.......................')''' 字符统计 '''
print('\n..........\n开始字符统计\n............\n')
start = datetime.datetime.now()
pattern_love = '.*?(爱).*?'
pattern_morning = '.*?(早安).*?'
pattern_night = '.*?(晚安).*?'
pattern_miss = '.*?(想你).*?'
pattern_set = [pattern_love, pattern_morning, pattern_night, pattern_miss]
statistic = [0,0,0,0]
for i in range(len(chat_content)):for j in range(len(pattern_set)):length = len(re.findall(pattern_set[j], str(chat_content[i])))statistic[j] += length
result = {'爱': statistic[0],'早安': statistic[1],'晚安': statistic[2],'想你': statistic[3]}
print(result)
end = datetime.datetime.now()
print('\n..........\n字符统计结束,用时: {}\n............\n'.format(end-start))