算法、算力和数据作为人工智能发展的三大支柱,而获取高质量的数据已经成为人工智能工程化进程中的难题。
如何能够寻找到与算法训练完美适配的数据集,在数据生产过程中有哪些常见的痛点?5月12日,由整数智能与格拉斯哥大学合作举办了一场人工智能领域的开放性讲座。曾参与编辑《人工智能研发运营一体化(Model/MLOps)能力成熟度模型》标准的核心编写专家刘明皓作为本次的分享嘉宾,不仅帮助同学们更好地理解人工智能行业的现况,还分享了数据生产知识等专业性干货,同时讲述了标准制定过程中的“内幕细节”。

讲座现场
整数智能的核心价值是什么?借着这个问题,讲座在同学们中间拉开了帷幕。“如果说过往更多是模型驱动,那么当前数据驱动在产业界和学术界中声量越发得大,无论是自动驾驶还是智能安防的应用落地,都离不开海量的多样性数据集。”
作为以结构化数据服务为主营业务的企业,整数智能坚持为合作伙伴提供高质量的数据。既然所有的算法工程师的梦想都是有一份完美数据,或者潜意识里认为提供给我的数据应该是完美的,那么这个问题该怎么样去解决?形成一整套科学可控可解释的数据生产工作流便被提上了日程。
“在大规模数据生产的过程中我们会发现很多的问题,这种情况下,我们需要进行数据清洗,检测数据集中存在的不符合规范的数据,并进行数据修复,以提高数据质量。”刘明皓介绍,在实际数据标注工作任务下,快速、高质量成为了关键词。“目前我们探索出来了一整套从需求明确到数据交付的全链路质量和进度把控的工作流。”
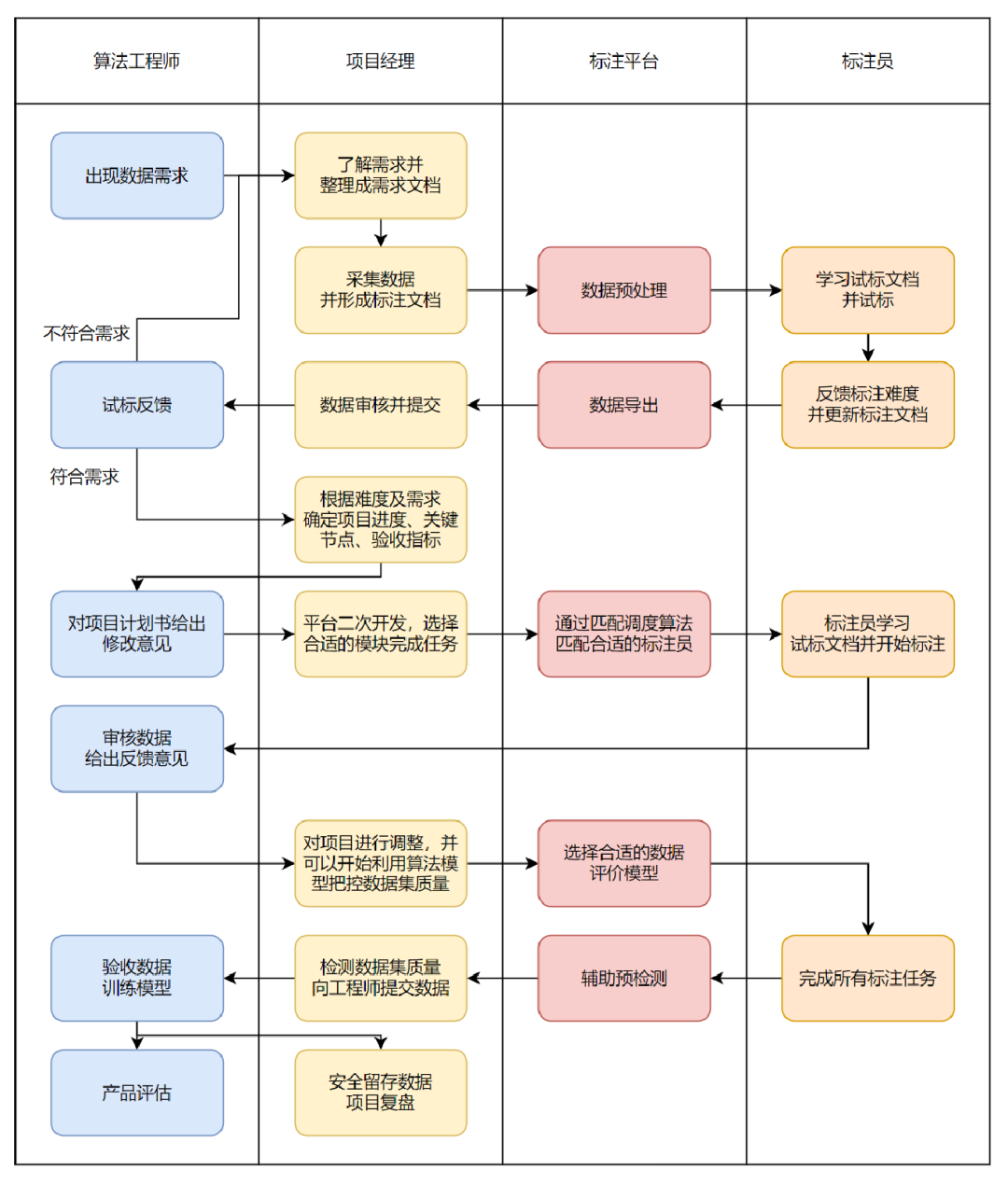
数据标注质量管理流程
在互动环节,格拉斯哥大学与整数智能的伙伴也就数据生产的不同模式、数据安全问题以及人工智能的未来发展趋势等方面进行了交流互动,同时讨论了学术和产业等方面合作的意向。
END