V-Net 《Multi-Passage Machine Reading Comprehension with Cross-Passage Answer Verification》
这篇文章是发表在2018年ACL上的,是抽取式的。在微软发布的MS MARCO数据集和百度发布的中文数据集DuReader上得到了SOTA效果。
分以下四部分介绍:
- Motivation
- Model
- Experiment
- Discussion
1、Motivation
在MARCO和DuReader这样多文档的阅读理解当中,我们有可能会从多个passage中得到多个疑惑的答案候选(这些答案可能是正确的,也可能是错误的)。
人往往通过比较多个候选答案归结出最终答案,我们希望机器也可以。
为了解决这个问题提出了一个神经网络模型能够让答案选集去彼此验证。
下面是一个例子,答案1是不太好的;6是可以作为答案;3,4,5是可以佐证6的。(但是3,6好像是一样的,笑哭)

2、Model
模型是基于一个这样的假设。在候选里面大部分的候选答案都是和参考答案比较相似的。这样我们可以通过候选里面的语义相似性来佐证彼此。
2.1 overview
- 输入:问题和文档
- 输出:从某一篇文档中抽取的答案片段

该模型主要获得三部分的得分,然后把这三部分的得分乘起来,取一个最高的得分对应的那一个文档抽取的片段,作为最后的输出答案。
2.2 Answer Boundary Prediction
同样获得词向量和字符向量,通过双向LSTM获得问题和文章的表示。
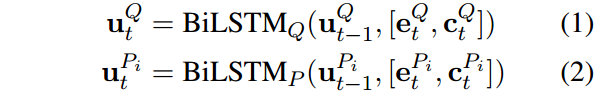
在使用BI-DAF,获得融合问题的文章的表示。
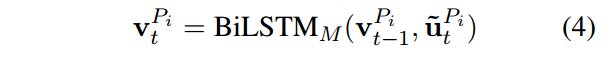
然后类似的,使用一个指针网络去计算开始和结束位置的概率分布。

t 表示指针网络的某个时刻,k 表示某个词。 V k P V_k^P VkP 这个P 也没有角标,是指passage的concatenation还是指一篇文档。(我觉得看图把,就是一篇文章一个预测的位置,在计算loss的时候,把所有的log似然损失都加起来。)
文章说道:It should be noted that the pointer network is applied to the concatenation of all passages, which is denoted as P so that the probabilities are comparable across passages.
指称网络应用到所有文章的串联,不太理解。难道不应该是每一个段落都会预测一个位置吗?
2.3 Answer Content Modeling
定位了候选答案之后,为了执行候选答案之间的验证,我们需要去得到候选答案表示。通过下面这个公式计算某个词的概率:
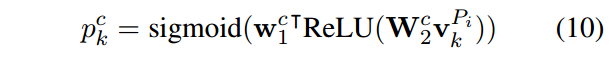
其实就是对每个词进行二分类。
为了能够去更好的训练,如果这个词在参考答案当中出现了,那么他的标签是1,否则0。这样我们可以算一个损失函数: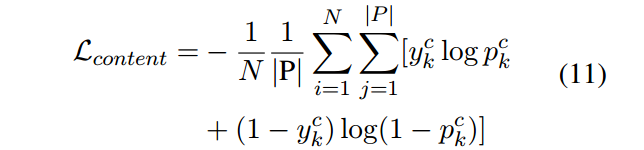
算到概率之后,我们可以用这个概率和词向量做一个加权求和得到候选的表示。
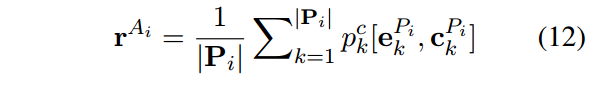
2.4 Cross-Passage Answer Verification
得到表示之后下面感觉上就像是做了一个self attention。用每一个表示彼此去做一下点积,然后计算得分。

类似于attention的原理,将得分和表示做加权求和。得到了一个新的表示记为 r ~ A j \widetilde r^{A_j} r Aj
然后将这个表示和表示过一个全连接:
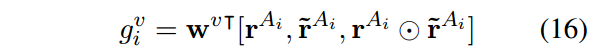 再进行归一化得到候选答案的得分:
再进行归一化得到候选答案的得分:
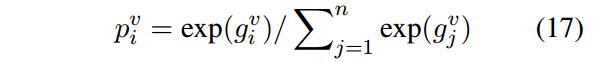
训练时计算log似然:
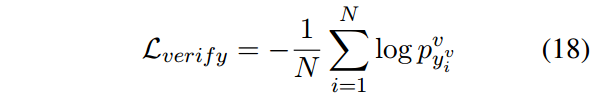
2.5 Joint Training and Prediction
Training
将上面三个部分的损失联合进行训练,实验证明效果也比较好:
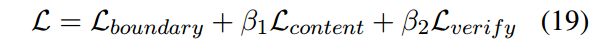
Prediction
在预测的时候首先可以算到一个边界的得分,第2部分每一个词的概率求平均以及最后一部分的得分。把这三部分的得分乘起来,然后选最大的那个对应的片段作为答案。
3、Experiment
1、先用斯坦福的NLP工具进行预处理,并且选择有着Rouge最高得分的片段作为参考答案。
2、在训练过程当中提出了两个有效的方法。第1个方法是针对英文数据集,通过训练一个简单的是/否分类器去回答那些有着特定模式的问题。
第2个方法是针对中文数据集,因为该数据集的段落非常的多,原始论文的使用一个简单的启发式规则,选择一个有代表性的段落。我们则是去训练一个段落排序模型(PR)。


3、从下面实验结果来说也可以说明,答案的内容确实和得分是在一定程度上有所联系的。对于那些彼此语义相似的答案,如3,4,6,在验证模型上的得分都比较高。

4、答案候选往往有着相同的边界,如果用边界模型直接计算概率的话,那么所有的候选答案的Content probability就一样了,也无法分辨这些候选答案。从图中也可以看到,content model还是很有必要的。

4、Discussion
优点:
- 充分的利用了候选答案的信息,在答案验证模型借鉴了gate self attention思路。
- 运用三个模块,不仅仅有边界模型,而且对文章的内容去进行建模还在此基础上对答案候选相互验证。
- 通过多任务学习是相互的促进而不是分开训练。
缺点:
- 缺点就是回答的问题一定是有多个候选答案的集合。否则的话没有办法进行cross passage answer verification(就是说每篇文档最后都有答案的相关部分,可以是错的,但是一定要多数都是正确答案)
问题就是这个,上面说过。
文章说道:It should be noted that the pointer network is applied to the concatenation of all passages, which is denoted as P so that the probabilities are comparable across passages.
指称网络应用到所有文章的串联,不太理解。难道不应该是每一个段落都会预测一个位置吗?