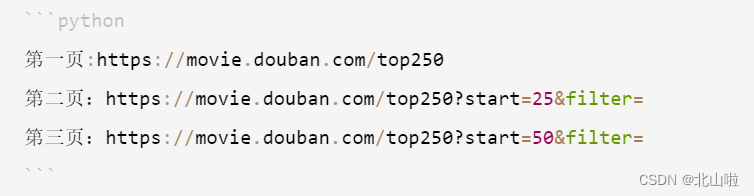
确定目标网址:豆瓣电影排行榜
使用Google浏览器打开目标网址,右侧选择分类“传记”,按F12打开开发者工具,会打开如下界面:左侧是数据内容,右侧是网页源代码信息。注:由于该页面是动态的,我们需要将右侧页面内容滚动到最后,然后单击"Name"中的最后一个数据包。
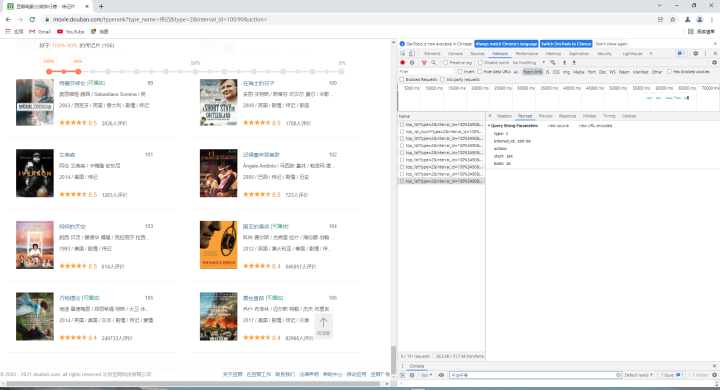
接着,按如下顺序依次操作,其中“Request URL”是我们后面需要的请求页面地址。


完成基本的网页分析和相关参数后,下面我们进入正题:
第一步:导入requests包和json,代码如下:
import requests
import json # 用于处理json格式数据的模块url = 'https://movie.douban.com/j/chart/top_list' # 数据目标地址
params = { # 需要携带的动态参数
'type': '2',
'interval_id': '100:90',
'action':'' ,
'start': '0',
'limit':'106'
}'''
模拟浏览器的身份验证信息,防止反爬
'''
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4750.0 Safari/537.36'}注:json是一种轻量级的数据存储格式,与开发语言无关。
第二步:使用get()函数发起请求,获取响应对象;再使用json()函数提取响应对象中json格式数据。代码如下:
response = requests.get(url=url, params=params, headers=headers)
content = response.json() # 提取json格式数据
print(content)第三步:在控制台将content内容打印出来,会得到一个含有大量数据的列表。但是这种结果显示并不适合查看,下面我们进行优化。

第四步:将json数据结构化显示,以便我们找到片名和评分存储在字典结构中的位置:
for i in content:'''ensure_ascii设置将数据编码后显示文本内容,spearators设置键之间、键和值之间的分隔符,indent设置缩进量'''print(json.dumps(i, indent=4, ensure_ascii=False, separators=(', ', ':')))break # 只需要打印第一条json数据用于查看,因此主动借结束循环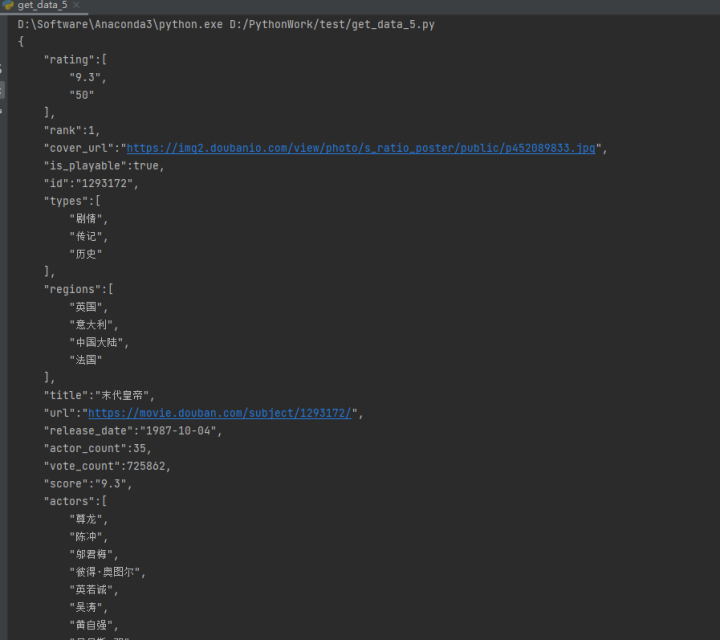
通过上图,我们可以看到,片名和评分分别存储在title和score这两个key中,下面我们利用for语句遍历json数据,提取这两个key的值,并存储在文本文件中。
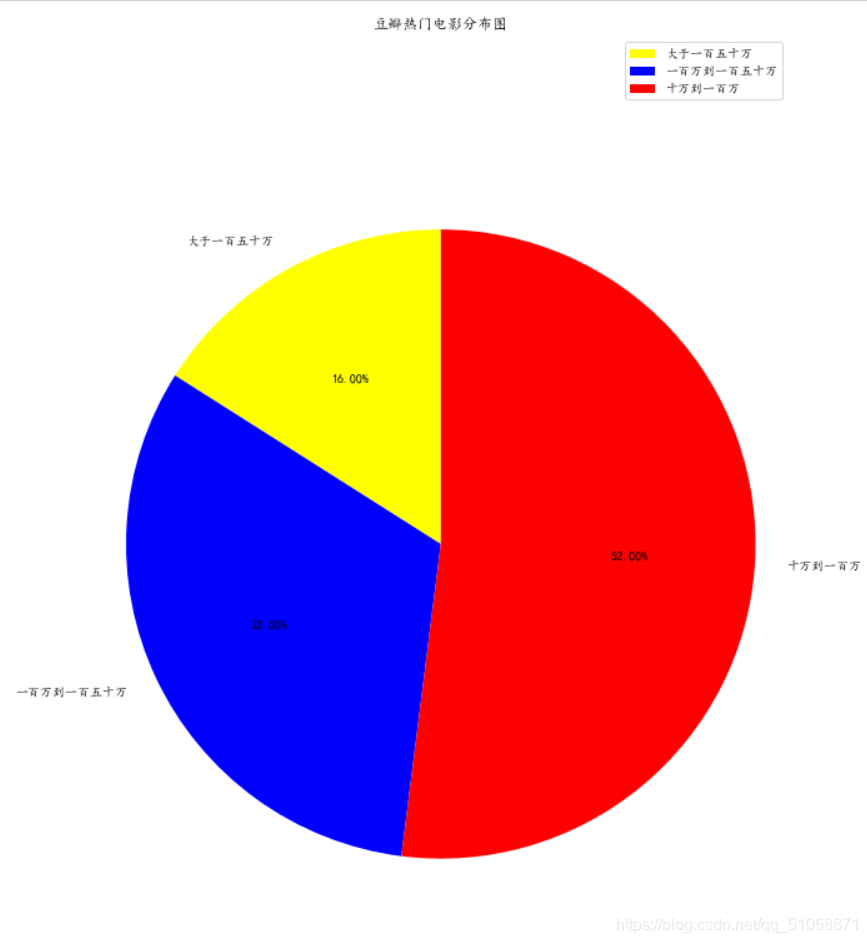
with open('豆瓣电影传记片排行榜.txt', 'w', encoding='utf-8') as fp:for i in content:title = i['title']score = i['score']fp.write(title + ' ' + score + '\n')【最终效果】

好了,这个简单的案例就分享到这里,希望对新手有所帮助!!!觉得有帮助的话,记得点个赞哦!!!