CNN-GRU卷积门控循环单元时间序列预测(Matlab完整源码和数据)
目录
- CNN-GRU卷积门控循环单元时间序列预测(Matlab完整源码和数据)
- 预测效果
- 基本介绍
- CNN-GRU卷积门控循环单元时间序列预测
- 一、引言
- 1.1、研究背景与意义
- 1.2、研究现状
- 1.3、研究目的与内容
- 二、理论基础
- 2.1、卷积神经网络(CNN)
- 2.2、门控循环单元(GRU)
- 2.3、CNN-GRU模型
- 三、模型构建与实现
- 3.1、数据预处理
- 3.2、模型结构设计
- 3.3、模型训练与优化
- 四、实验与分析
- 4.1、实验数据与设置
- 4.2、结果展示
- 五、结论与展望
- 5.1、研究总结
- 5.2、研究限制
- 5.3、未来研究方向
- 程序设计
- 参考资料
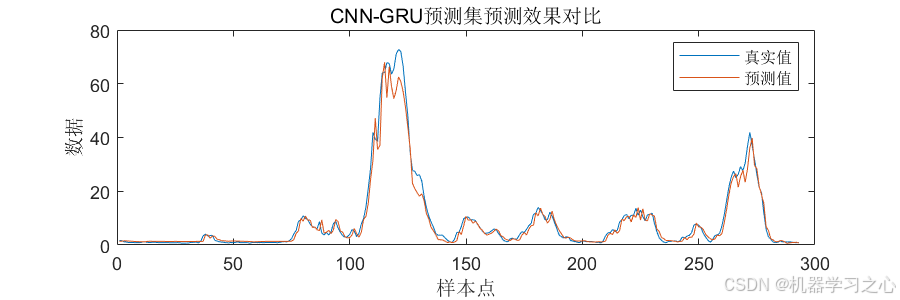
预测效果

基本介绍
1.Matlab实现CNN-GRU卷积门控循环单元时间序列预测(Matlab完整源码和数据)。
2.输出MAE 、 MAPE、MSE、RMSE、R2多指标评价,运行环境Matlab2023及以上。
3.代码特点:参数化编程、参数可方便更改、代码编程思路清晰、注释明细。
CNN-GRU卷积门控循环单元时间序列预测
一、引言
1.1、研究背景与意义
时间序列预测是数据分析中的一个重要分支,它涉及对按时间顺序排列的数据进行建模和分析,以预测未来的趋势和变化。这种技术在金融、经济、气象、医疗等多个领域具有广泛的应用,例如股票价格预测、天气预报、疾病传播趋势分析等。随着数据量的增加和计算能力的提升,利用深度学习技术进行时间序列预测已成为研究的热点。
1.2、研究现状
目前,时间序列预测的方法主要包括传统统计模型如ARIMA(自回归积分滑动平均模型)和现代机器学习方法如LSTM(长短期记忆网络)和GRU(门控循环单元)。这些方法在处理不同类型的时间序列数据时各有优劣。例如,ARIMA模型在处理线性关系较强的时间序列时表现良好,但对于非线性、高度复杂的时间序列数据则力不从心。而LSTM和GRU虽然能够处理长期依赖关系,但在计算资源和训练时间上通常需求较高。
1.3、研究目的与内容
为了提高时间序列预测的准确性和效率,本文提出了一种结合卷积神经网络(CNN)和门控循环单元(GRU)的混合模型CNN-GRU。该模型利用CNN的强大特征提取能力和GRU的有效序列处理能力,旨在解决复杂时间序列预测问题。本文将详细介绍模型的架构设计、训练过程,并通过实验验证其在多种时间序列预测任务中的性能。
二、理论基础
2.1、卷积神经网络(CNN)
卷积神经网络(CNN)最初是为图像处理设计的,其核心在于通过卷积层自动提取输入数据的关键特征。在时间序列预测领域,CNN通过一维卷积核沿时间轴滑动,捕捉时间序列的局部模式。这种特性使得CNN非常适合于提取时间序列数据中的短期依赖关系和局部特征。
2.2、门控循环单元(GRU)
门控循环单元(GRU)是循环神经网络(RNN)的一种变体,旨在解决长期依赖问题和梯度消失问题。GRU通过更新门和重置门控制信息的流动,使得模型能够记住重要的长期信息,同时忽略不相关的短期信息。这使得GRU在处理序列数据时既高效又能保持较好的性能。
2.3、CNN-GRU模型
CNN-GRU模型结合了CNN和GRU的优点。首先,CNN层通过卷积操作提取时间序列的局部特征,然后将这些特征传递给GRU层进行处理。GRU层利用其门控机制捕捉这些特征中的长期依赖关系,从而实现更准确的时间序列预测。这种结合方式不仅提高了模型对复杂时间序列的处理能力,还增强了模型的泛化能力。
三、模型构建与实现
3.1、数据预处理
在构建CNN-GRU模型之前,首先需要对时间序列数据进行预处理。归一化是将数据按照一定的比例缩放,使得不同特征的数据能在相同的尺度上进行比较和计算。这些预处理步骤对于提高模型的训练效率和预测精度至关重要。
3.2、模型结构设计
CNN-GRU模型的结构设计主要包括卷积层、GRU层和全连接层。卷积层通过多个卷积核提取时间序列的不同尺度的局部特征。卷积层的输出经过池化层降维后,输入到GRU层。GRU层通过其门控机制学习时间序列的长期依赖关系,最终通过全连接层输出预测结果。
3.3、模型训练与优化
模型训练过程包括选择优化算法、损失函数和学习率等超参数。在本研究中,采用Adam优化算法来更新模型参数。
四、实验与分析
4.1、实验数据与设置
为了验证CNN-GRU模型的性能。实验环境设置为MATLAB2020b,利用其深度学习工具箱进行模型构建和训练。
4.2、结果展示
实验结果表明,CNN-GRU模型在多种时间序列预测任务中均表现出较高的预测精度和效率。具体来说,模型的均方根误差(RMSE)和平均绝对误差(MAE)均低于其他对比模型,显示出其在预测准确性上的优势。
五、结论与展望
5.1、研究总结
本文提出了一种基于CNN和GRU的混合模型CNN-GRU,用于时间序列预测。实验结果表明,该模型能够有效提高预测精度,特别是在处理具有复杂模式和长期依赖关系的时间序列数据时表现出色。CNN-GRU模型通过利用CNN提取时间序列的局部特征,再通过GRU建模长期依赖关系,实现了精确的预测。
5.2、研究限制
尽管CNN-GRU模型在多个数据集上表现出良好的性能,但其在处理极端事件预测和高度非线性数据时的能力还需进一步研究。此外,模型的训练时间较长,对于实时性要求高的应用可能是一个挑战。
5.3、未来研究方向
未来的研究可以探索更多的模型优化技术,如模型结构的调整和超参数的选择,以进一步提高预测性能和效率。同时,将CNN-GRU模型应用于更多领域的时间序列预测问题也是一个值得探索的方向。
程序设计
- CNN-GRU卷积门控循环单元时间序列预测(Matlab完整源码和数据)
%% 清空环境变量
layers0 = [ ...% 输入特征sequenceInputLayer([numFeatures,1,1],'name','input') %输入层设置sequenceFoldingLayer('name','fold') %使用序列折叠层对图像序列的时间步长进行独立的卷积运算。% CNN特征提取convolution2dLayer([2,1],4,'Stride',[1,1],'name','conv1') %添加卷积层,64,1表示过滤器大小,10过滤器个数,Stride是垂直和水平过滤的步长batchNormalizationLayer('name','batchnorm1') % BN层,用于加速训练过程,防止梯度消失或梯度爆炸reluLayer('name','relu1') % ReLU激活层,用于保持输出的非线性性及修正梯度的问题% 池化层maxPooling2dLayer([2,1],'Stride',2,'Padding','same','name','maxpool') % 第一层池化层,包括3x3大小的池化窗口,步长为1,same填充方式% 展开层sequenceUnfoldingLayer('name','unfold') %独立的卷积运行结束后,要将序列恢复%平滑层flattenLayer('name','flatten')gruLayer(25,'Outputmode','last','name','hidden1') dropoutLayer(0.2,'name','dropout_1') % Dropout层,以概率为0.2丢弃输入fullyConnectedLayer(1,'name','fullconnect') % 全连接层设置(影响输出维度)(cell层出来的输出层) %regressionLayer('Name','output') ];lgraph0 = layerGraph(layers0);
lgraph0 = connectLayers(lgraph0,'fold/miniBatchSize','unfold/miniBatchSize');%% Set the hyper parameters for unet training
options0 = trainingOptions('adam', ... % 优化算法Adam'MaxEpochs', 150, ... % 最大训练次数'GradientThreshold', 1, ... % 梯度阈值'InitialLearnRate', 0.01, ... % 初始学习率'LearnRateSchedule', 'piecewise', ... % 学习率调整'LearnRateDropPeriod',70, ... % 训练100次后开始调整学习率'LearnRateDropFactor',0.01, ... % 学习率调整因子'L2Regularization', 0.001, ... % 正则化参数'ExecutionEnvironment', 'cpu',... % 训练环境'Verbose', 1, ... % 关闭优化过程'Plots', 'none'); % 画出曲线
% % start training
% 训练
tic
net = trainNetwork(trainD,targetD',lgraph0,options0);
toc
%analyzeNetwork(net);% 查看网络结构
% 预测
t_sim1 = predict(net, trainD);
t_sim2 = predict(net, testD);
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/127626816
[2] https://blog.csdn.net/kjm13182345320/article/details/127179100