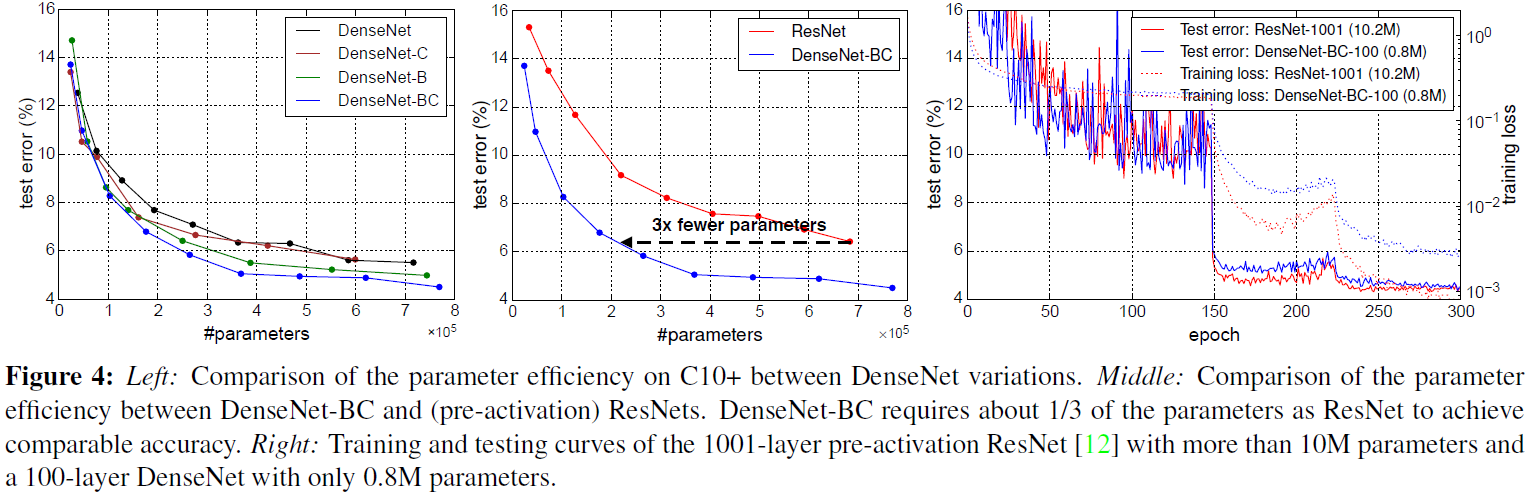
[持续更新]2019 智见 AI workshop in Beijing
- 前言
- 代季峰:卷积神经网络中的几何形变建模
- Deformable Conv V1
- Deformable Conv V2
- Tricks & Exprience
- 张士峰:物体检测算法的对比探索和展望
- Detector Algorithm Overview
- anchor-based
- anchor-free
- RefineDet
- 张祥雨:高效轻量级深度模型的研究和实践
- ShuffleNet
- A Little NAS and Pruning
- 黄高:面向快速推理的卷积神经网络设计
- Quick Overview of Convolution Model
- 胡杰:视觉注意力机制在模式设计中的发展与应用
- 俞刚:检测算法 Pipeline
前言
上周周末很幸运能参加旷视在北京的AI workshop,主题是物体识别和目标检测,跟我现在从事的方向十分贴合,大佬们的分享也让人收获不少。有人可能会说,他们主要都是在介绍自己的工作,在打广告希望更多人用他们的算法,增加影响力。我不否认,但是作为一个从业者这不就是我们的追求吗?而且,事实上很多内容是,就算你通读别人的代码和论文,都比不上听他亲口说他这个工作的来源、想法和创新点来得好。假使你是基于了解大牛们的想法和框架为目的的话,这些交流workshop肯定是一个很好的平台。当然啦,有不少谈话可能以前在别的地方发表过了,但是我觉得还是认为它的价值是存在的,
- 书非借不能读
- panel部分和提问可以了解学界和业界发展的大致方向
- 可以现场真人面对面提问啊好不好
废话不多说,先上当天日程:

简单介绍一下这8位,下面的记录方式会根据日程的顺序来进行,有些内容我不太了解或者当时刚好跳过了的见谅,discussion 和 insight会从比较靠近他们的近期有影响力的工作出发:
- 代季峰,MSRA研究员,Deformable-v1-v2 和 D-RFCN的作者
- 张士峰,CSAIR在读,RefineDet 作者
- 张祥雨,代表作 ResNet 和 ShuffleNet-v1-v2 作者
- 白翔,文字检测和识别国内最知名的学者之一
- 胡杰,Megvii,SEnet 作者
- 俞刚,Megvii,DetNet 和 light-head RCNN 作者
- 黄高,清华副教授,DenseNet 和 CondenseNet 作者
- 程明明,南开教授,Salient Object 系列作者
代季峰:卷积神经网络中的几何形变建模
这个 talk 主要介绍的还是他在 Deformable-v1 和 v2 中的工作。
Deformable Conv V1
工作的思路来源可以追溯到 SIFT 算子这类算法上,简单的介绍一下 SIFT,其实就是认为图片上的边缘和颜色信息可以通过一个二维向量记录下来,一个区域内二维向量的集合隐含的就是方向等特征。基于这个传统思想衍生到深度学习的第一个工作就是 STN。
STN:对传统卷积进行改进,加入一个新分支学习卷积核中每个像素(pixel)的偏移量(offset)。该分支的设计是,两个 conv 用作记录 localization 信息,后接一个 σ \sigma σ 将特征映射成一串偏移量offset后该分支合并回原来的分支用作指导后续卷积行为
Deformable_Conv-V1 就是在这种背景上设计出来的,它的设计思想是:
- efficiency,运行上效率要足够高,不能增加太多运算量
- no labels。不需要额外的数据指导训练
- significant increase。易部署且效果明显
就这三个维度的评判来看,显然 DCNv1 是能够达到这样的要求的。在 D-RFCN-v1 的论文中,DCNv1 的提升超过两个点但是菜鸡的我表示,RFCN 的训练本身让 DCNv1 的威力看起来不明显,还有就是 DCN 这种结构它有自己专门针对的数据,规整形状数据也不能显示出它的威力,这个按下不表】。DCNv1 的结构如下:

可以看到,DCNv1 的设计思路其实跟STN是一样的,都是新开一个分支做 offset 的计算,然后合并回去指导主支的卷积行为,不同的只是 offset 的设计。offset 分支中的三个部分,除了后面的 offset 回归层有不同的 tricks 外,最大的不同我认为是中间的 offset field layer。这里其实是一个 2N 输出的设计,思路应该就是跟 Openpose 的亲和场设计(Part Affine Field)中关于二维向量的表述类似了,就是一个向量利用两层分别去表示 X 分量 和 Y 分量,至于思路来源我是不清楚的,各位知道的欢迎留言告知。
Deformable Conv V2
然后是 Deformable-Conv-V2,作者介绍了他们对V1进行改进时使用的三个维度的工具:
- Effective Sample
- Effective Response Field
- Error-Based Saliency Region

其中前两个工具主要是对图片中不同区域和数值的 pixel 进行分析,看到底是哪些 pixel 引起了模型的注意和学习。第三个工具则是分析模型在学习具体的物体位置和识别时哪些区域产生响应以及区域的形状如何,例子如下:

根据这些分析工具和方法,DCN-V2 相对 V1 提出了以下的改进,具体我还没看论文,只作大致复述,
-
更多的 layer 使用 DCN 结构。在 V1 中作者只在第五层中加入了 DCN,并且没有对各层加 DCN 给出实验说明。在 V2 中,作者补完了这些工作,并认为 DCN 应该加在尽可能多的 ConvLayer 中,除了底层外(因为底层信息提出的信息与物体形状无关,更加基本,加入 DCN 于理不合)。实际上 V2 的设计就是将原本第五层加入 DCN 变成三至五层都加入了。
-
Modulate Deformable Conv。具体意思是加入蒙版(mask)训练。有人可能会问,这不就违反“no label”的设计初衷了吗?并没有。作者实际上加入的蒙版只是为了分开前景(foreground)和背景(background),用作 DCN 的训练知道罢了。具体加蒙版的方式采用的是传统算子做前处理加入。
-
Mimic RCNN design of ROI。这个部分是作者正在进行的相关工作,意思是大概是要引入类 RCNN 的 ROI 机制去进一步提高 DCN 的效果
需要注意的是,V2 的改进较 V1 有较明显的提高,但是耗时相对 V1 多了10%。另外,会后交流当中,作者认为对 offset 层的回归结果进行一定程度的控制会是一个好的改进方向,毕竟不同的物体虽然 scale 不一样,但是形状毕竟是连续的且只会出现在图片的某个区域,学习到远超物体范围的 offset 无论对训练还是结果都是没有意义的,而目前这些都是自行学习的。
Tricks & Exprience
总结一下 DCN 实际使用上的一些改进点,
- 引入 offset 的限制,可以作为一种先验知识控制学习方向
- 通过引入 DCN,在 two-stage detector 中可以减少 anchor 数量提升速度
- 实际使用中对规整形状的物体效果有限,比如交通标志,证件,logo等(本人项目经验…)
张士峰:物体检测算法的对比探索和展望
Detector Algorithm Overview
这个 talk 主要介绍了检测算法的一系列发展和脉络,比较基础。在传统算法阶段,经典的检测算法包括 VJ 算法和 DPM 算法等。单独拿出这两者来讨论是因为,VJ 算法代表的 Cascade 思想和 DPM 算法代表的 region 思想直到深度学习算法阶段依然起到了很大的启发作用。 Cascade 的代表有 FPN, SNIPER 等,Region 的代表毫无疑问就是 RCNN 系的 two-stage detector了。
与传统算法相对的是2012年起流行至今的深度学习算法,结合目前流行的研究方法,可以将这些算法大致分成两类,即 anchor-based 和 anchor-free。
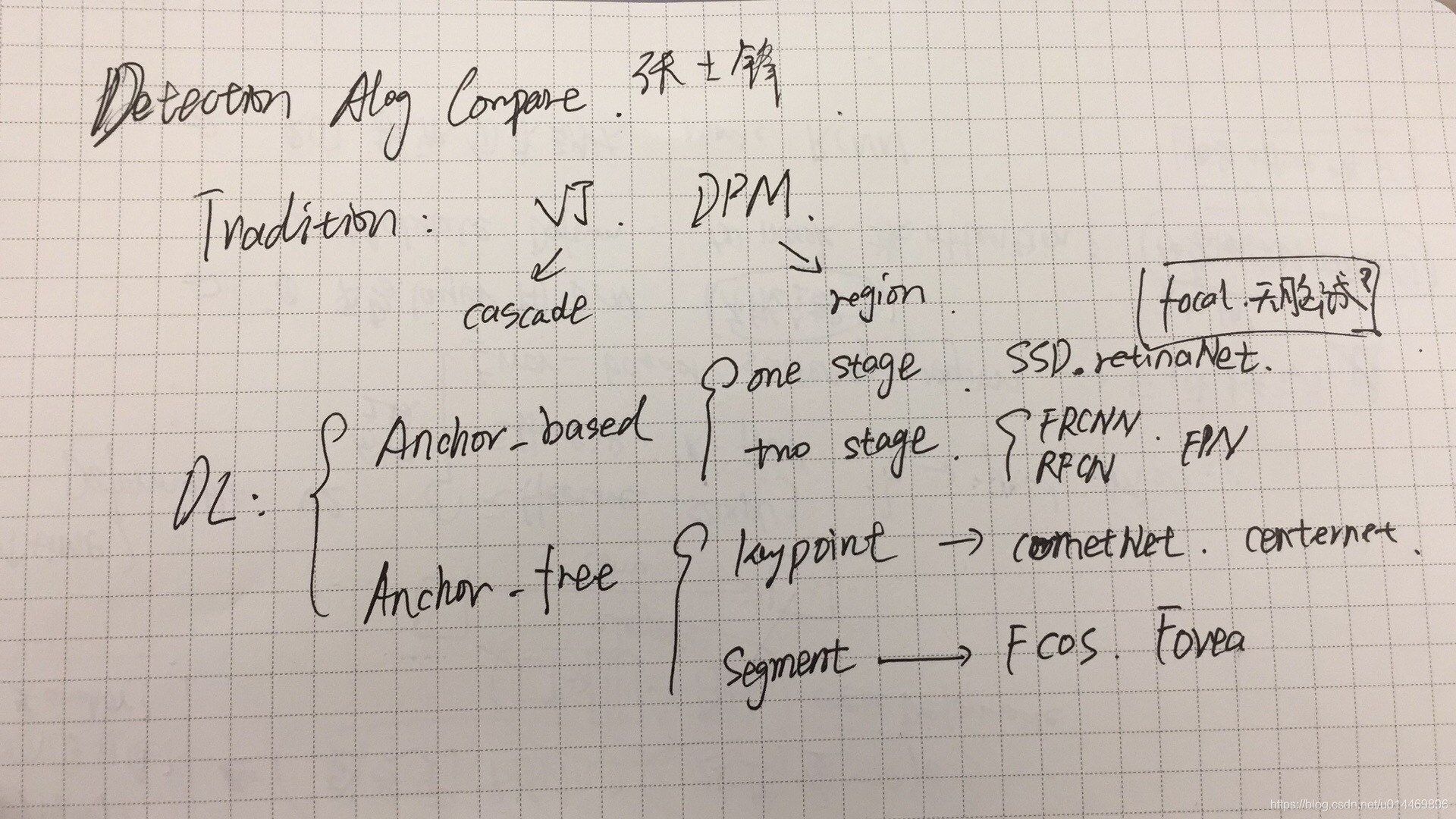
anchor-based
其中 anchor-based 就是我们传统意义上提到 one-stage detector 和 tow-stage detector 了。 其中 one-stage detector 其实可以看作是 RCNN 中的 RPN 结构(first stage)。一步法检测器的代表作是 Yolo, SSD, RetinaNet。二步法检测器的代表作自然就是 RCNN-series 了(RCNN -> Fast RCNN -> Faster RCNN -> RFCN -> Mask-RCNN)
对一步法检测器(One-Stage / RPN),设计上的思路其实都是
b a c k b o n e + [ L o s s c l a s s i f y + L o s s l o c a t i o n − r e g r e s s i o n + L o s s f e a t u r e s ] backbone + [ Loss_{classify} + Loss_{location-regression} + Loss_{features}] backbone+[Lossclassify+Losslocation−regression+Lossfeatures]
二步法检测器就是在一步法检测器的结果上将精细结果的输出放到 RPN 之后而已。
一步法对比二步法的缺点:
- 正负样本极度不平衡,学习困难
- 对小目标检测天然效果不好
- 精度平均会比二步法低 10%,上限不可能突破
由于一步法在全局中进行搜索,因此出框量一般都会很大,这就导致正样本和负样本的数量极度不平衡,因此专门针对一步法出现了“困难样本挖掘”或者 Focal Loss 这样的 tricks。注意,二步法是没必要用这种东西的,因为二步法的 RPN 设计天然的减少了搜索目标的空间,私以为,RPN 后接的两个分别分类正负样本的分类器也是导致困难样本挖掘必要性降低的原因。
基于上面提及的“正负样本极度不平衡”和“搜索空间大”两点,一步法的小目标检测容易被漏检和抑制(负样本数量过大,出现小目标的正样本置信度不高,自然就被抑制了)。这个问题基本上就不是“困难样本挖掘”之类的方法可以解决的了。
同样无解的是精度比二步法低,这是肯定,毕竟一步法只是二步法的一个 RPN 结构而已。
RefineDet 就是为一定程度缓解这些问题而诞生的(作者广告时间~),后面再详细讲。
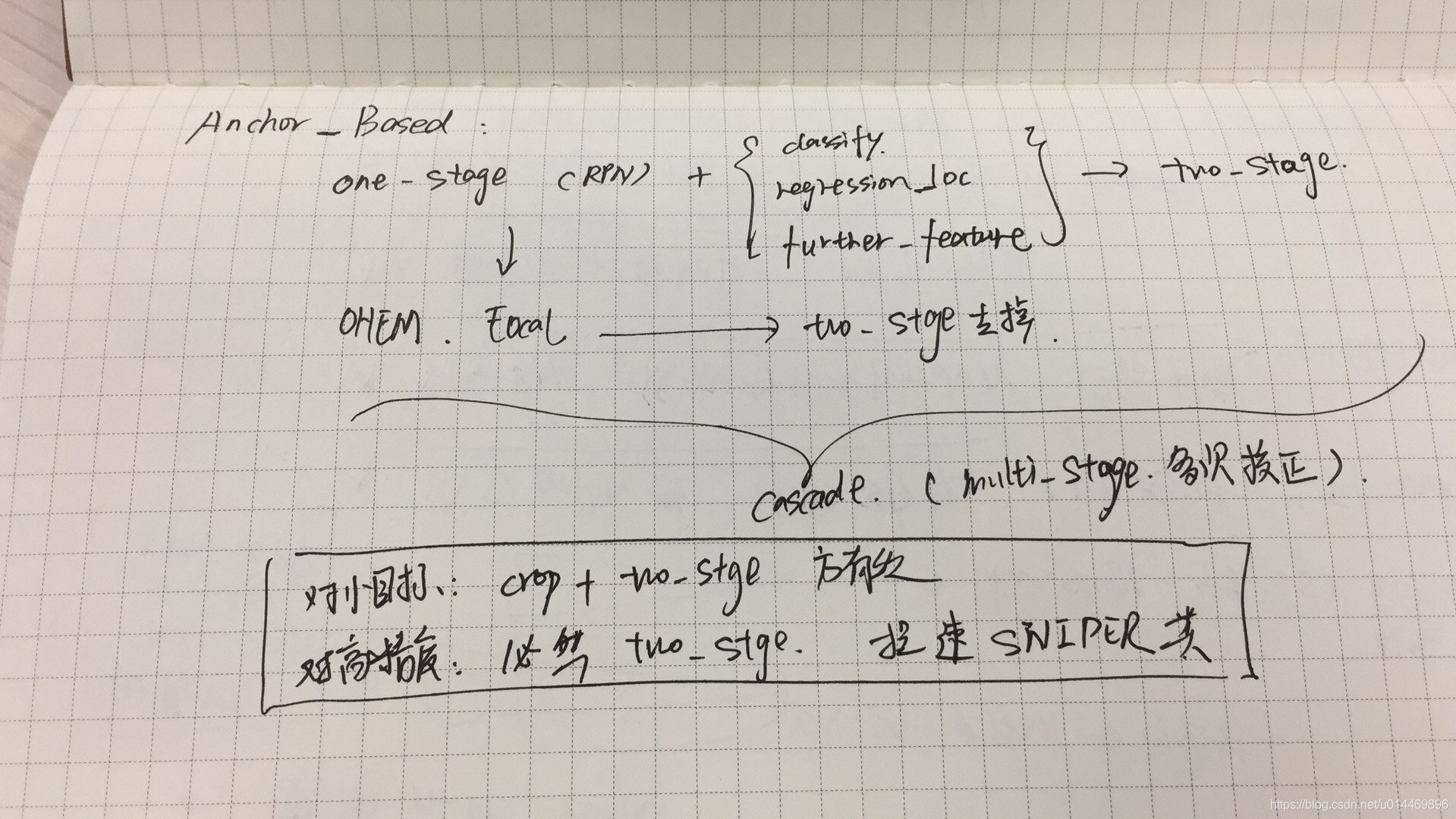

anchor-free
另一边,则是目前“死灰复燃”的 anchor-free 方法。在场几位 panel 部分也纷纷表示,
- anchor-free 和 anchor-based 严格上来说还是一个方法,都不过是检测框的一个映射函数而已,实际区分不大
- anchor-free 的重新兴起是基于 Focal Loss 对样本平衡的优秀性能。
与 anchor-based 类似,anchor-free 同样可以分为两种类型,即关键点法和分割法。
关键点法的其中一个例子是 CornetNet,其中算法的关键设置是三个模块 heatmap, embedding, offsets。它们分别负责关键点定位,对角点匹配,以及精细回归关键点偏移量。
分割法则有可通过使用不同的损失函数分成 Focal Loss 和 IOU Loss 两种,最近的几篇文章如 FCOS,Fovea 等,本质上都是 FPN + [class_box regression + SubNet-detector ]
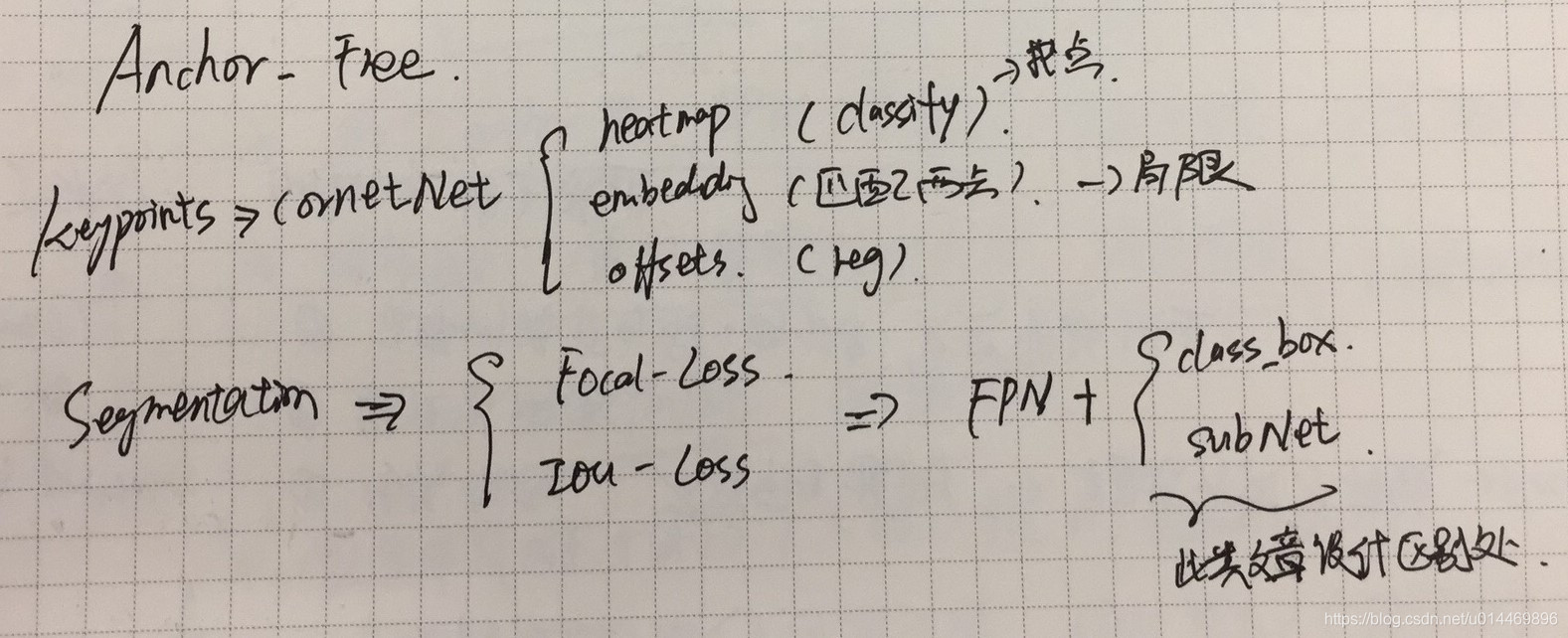
RefineDet
这一节主要介绍RefineDet的一些细节点。鉴于之前已经提及的一步法精度缺陷和二步法速度缺陷,refineDet 试图通过改进网络设计来寻找其中的平衡点。先上现场作的笔记,

为了提高模型的检测精度,二步法形式的网络是不可避免的,但如果按 faster-rcnn 这类经典二步法的设置方式,提高速度基本上不太可能。所以作者其实是试图通过在每一个尺度层上加入一个开关来判断是否需要在该层做目标检测,对比起原来的 FPN 形式的网络,每一层都要输出结果做目标检测,显然是会在理论上节省比 FPN 本身节省一半以上的时间。如果图所示,在 backbone 阶段后接的4个feature map 本身就是一种类 fpn 结构,在这之上加入简单的 softmax 分类器判断该 feature map 上是否存在目标,假如没有则 down-sameple 得到下一个 feature map,重复操作直到 down sample 四次(最小为原图尺寸的 1/32)。这样的设计,看上去跟后面黄高老师做的自适应网络的想法还挺像的。
另外,为了进一步提取特征层的特征,一旦 feature map 被确认有目标后,feature map 会输入到一个叫 TPC 的小卷积模块中。这个小卷积模块还有点像 RNN 的结构,对现在这层 feature map 卷积后会再跟上一层特征合在一起再卷积一次,具体设计就不细说了,文章都有。说几个作者实验过程中得到的小发现吧:
-
在 “two stage” 阶段,作者说只要减少 anchor 数量,就能比原版 ssd 更快,而 refinedet 本身的设计思路就导致 anchor 数量不需要像 ssd 那么多,因为 tpc 本身融合了尺度信息。
-
Synchronize Batch Normalization(同步bn)操作,使得大batch训练成为可能,并且能够提升模型精度,对小目标检测的精度提升有效果(但个人认为,解决小目标检测的本质问题还是需要依靠pixel-level处理的算法,例如分割,anchor-free+multi-scale,etc)
-
检测头输出是三个结果,分别是 特征,点回归和分类,三者对精度提升的贡献分别是 1.1%,2.2%,0.5%。
-
RefineDet 本身对小目标检测没什么效果,作者认为:
- 第二阶段的回归分支对小目标检测没有作用,因为损失函数的值过大,导致收敛困难
- 对小目标做检测时只保留浅层 feature 的检测可能会更有效
另外,张士峰还分享了关于 pretrain model 的看法,
-
一般 pretrain 都是在 ImageNet 上做识别任务获得的,实验证明,识别任务的特征对检测任务并没有太大的帮助,有些时候甚至比使用初始化方法从头训练还差
-
使用 pretrain 意味着没有办法根据实际需要更改 backbone 的网络设计
-
train from scratch 对性能基本没有影响(按第一点说,有时还会更好),只是收敛速度会比 pretain 慢两到三倍
大部分算是老生常谈了,但是结合后面俞刚的 DetNet 分享来思考还挺有意思的(俞刚 DetNet 就是为了在检测头部分能使用pretrain而设计的,他们的实验表明,在 Object365 pretrain 下,使用 DetNet 检测头会有 2% 的提升)。其实我对士峰的看法十分赞同,在实际生产和项目开发中,对 pretrain 的需求真的不高,实际应用中我们应该关注的也不应该是“使用 pretrain 获得更高性能”而是其他,这里打个广告,之后会出一个项目开发经验总结,欢迎各位关注。我在实际中其实也是 train from scratch 的。在时间充裕的情况下,我们确实不应该受 pretrain 束缚。
张祥雨:高效轻量级深度模型的研究和实践
祥雨大神前几年的工作,我想绝对值得各位“深度学习”从业人员去记住的,仅凭 ResNet 和 ShuffleNet 就完全影响了我们的工作了。个人印象很深刻的是,他在 ShuffleNet-V2 的文章中很详细的重新定义和阐述如何去衡量轻量模型,简直就是给各位做模型轻量化设计的人指出了一个具体方向。目前他的工作主要集中在 NAS 和分布式等方面,这些离我们炼丹相对来说比较远一点,我平常也没有机会和资源去实验这一块的内容,只能听个大概,这边我就不多说什么班门弄斧了,有兴趣各位可以去看扒他的演讲视频。下面是他这次演讲说到的六个方向。
- 轻量级架构
- 模型裁剪
- 模型搜索
- 低精度量化
- 知识蒸馏
- 高效实现

另外,附上这个报告部分的部分解读内容 点击这里
ShuffleNet
在 ShuffleNet 一节,祥雨简单介绍了设计思路。ShuffleNet-V1 的关键是引入了 group-conv (分组卷积)的设计,它主要想要解决的是网络设计中这样的一个矛盾,即时效和精度的不可兼得:
如果我们需要提升网络的识别效果或者是解决“问题”的能力,理论上来说我们应该增加 channel (通道)数,因为这样能够提高我们提取到的特征数量(尽管不可避免的造成冗余),而提取出来的特征越多越全面,就意味着我们的模型性能会越好,因为它“懂”得越多。但是这样处理的结果意味着增加很多计算量,速度会变慢,模型大小也会变得很大。
而且channel数越多,提取出来的信息冗余度越高,总会有某个平衡点是,多付出一分算力一分时间,我们能获得的非冗余有用信息很少,少到多付出的时间和资源显得没有意义(如何去衡量这个平衡点,也是我们算法从业人员应该要考虑的范畴)。那么我们是否可以在保留尽量多的通道数的情况下,减少运算量,使得我们算法的运行速度提升呢?ShuffleNet 应运而生。它的具体思路就是舍弃了之前卷积操作会对前一层的所有输入通道进行处理,然后一并输出(相当于输入通道所有信息全部融合),转而在每一次的卷积操作中,将所有通道随机分成 N 组,每组内做卷积操作分别输出一定数量的通道,然后所有输出通道再合并到一起。这样就相当于同组通道的信息会融合,而不同组的则互相不可见。为了尽可能模仿原来的卷积操作,让所有的通道信息都尽可能地融合起来,分组的方式采用了随机操作。这就是 ShuffleNet-V1 的主要思路了。缺点当然也很明显了,一是通道分组如何分分多少组才有效,这里引入了超参,也没有很好的衡量方式。二是随机分组操作本身就占用了大量的运行时间和算力。
也是基于这些人为设计的不确定性,现在越来的大佬和课题组都转向研究NAS (Neural Architecture Search) 了。祥雨的分享后半部分也是主要讲NAS方面的工作,这个我不太懂就先按下不表了,而且太耗卡,我估计我可能以后很难有机会了解这一块了。
说回 ShuffleNet-V2,正如前文所说,这篇文章最大的贡献点个人觉得不是模型结构的更新,而是这篇文章里面提到的快速网络设计的四个要点。这是在模型架构上自 ResNet 和 DenseNet 之后,个人认为最有价值的内容了。
至于模型架构近年一些新的进展和改进方法,可以移步下一个section看胡杰的分享。
A Little NAS and Pruning
Pruning 稍微接触过,以后会更新一篇关于剪枝和加速的文章。NAS 就真的相对了解比较少,只知道一些基本概念和大概思路流程,这里大致写写,详情建议看之前附上的网址。
目前祥雨组在NAS上的工作方向主要是以下三个:
- 轻量搜索,使用尽可能少的GPU运算资源进行搜索
- 直接搜索,对特定任务直接搜索合适的网络,尽可能最大化深度学习的威力,举例子,目标检测直接搜索backbone,不再直接使用分类任务搞出来的backbone了。
- 灵活搜索,这个主要想解决的是目前NAS搜索时还是要人为设定使用的最基础结构 (ConvLayer, Res-Block, Dense-Block) ,没办法探寻新的有效结构的问题。
这里主要为他们组的工作打了两个广告,大家有空可以去试试效果,我也很想知道到底是不是真的有用。
第一篇是 Single Path One-Shot NAS, 它的核心思想来自于 SuperNet, 主要是为了减少搜索使用的算力而设计的方法
第二篇是 DetNAS, 这篇就是上面提到的,特定任务直接搜索相应结构。据说性能效果比用市面上的主流Backbone都要高几个点。对此我是不怀疑的,对特定任务特定数据直接搜索网络,这肯定会比通用框架有更好的效果,只是实际应用中,需要用到的运力和搜索时间是否能够支撑我们在每个特定任务上都能使用,这个才是关键。貌似最近 Google 的一个工作跟这有相似之处,就是以后直接搜网络结构,不训练模型参数了。这个想法挺有意思,理论上也是有道理的,持续关注中
最后再加点剪枝的内容,在祥雨看来,剪枝这一块可以大致按下面三点去看:
-
稀疏化,本质上是一种信息的低阶转秩。
-
直接通道剪枝,这个方法最直接有效
-
Meta Pruning,这个做法是比较前沿了,他们在这方面的工作主要是尝试结合 Single Shot NAS + Meta Learning,但是 Meta Learning 本身都很前沿,我个人觉得还有点玄学,不同思路的 Meta Learning 差距也很大,这个估计很长一段时间内还是观望状态吧
黄高:面向快速推理的卷积神经网络设计
黄高教授是 DenseNet 和 CondenseNet 的作者,注意他的讲稿题目是“面向快速推理”,这个跟上一篇祥雨说到的“轻量级模型”不完全是一样的意思。
-
轻量级模型:模型结构简单,运算量少。这就意味着模型牺牲了精度去换取使用时的时间优势。除此之外,轻量级模型的另一个目标是将模型做得更小,能在移动端部署。
-
快速推理模型:尽管轻量级模型必然可以快速推理,但是快速推理的模型却不一定轻量。黄高提出的 dynamic network 机制就是一个能够快速推理的“不轻量”模型。
Quick Overview of Convolution Model
按照黄高