Python识别验证码----谷歌reCapture 4*4验证码
- 写在前面
- 数据特点
- 识别思路
- 识别结果
- 改进点
写在前面
近日某众打码平台被跑路的消息一出,脚本圈中一片哗然(我并不是脚本圈的,只是喜欢看群里人吹逼而已 ),仿佛再也听不到那句熟悉的广告语了。这也预示着,第三方打码平台不靠谱了。但打码功能有时候又必不可少,这时候怎么办呢?当然是自己自己动手丰衣足食啦!最近工作不是很忙,准备撸一个用Python识别验证码的系列文章,该系列计划囊括各种时下比较流行的验证码形式,如滑块、四则运算、点选、手势、空间推理、谷歌等。已经跑通了的所有代码都放在了我的知识星球上,需要的话请自取。话不多说,开撸!
数据特点
这类验证码估计大家都碰到过,体验反正有点恶心。

识别思路
1.训练一个deeplab模型来对图片做语义分割,像酱紫:

2.由于打标签实在是太累,以至于我数据没多少,所以光靠语义分割模型来做定位精度肯定是不够的,
于是想了个法子。之前做了个yolo的模型用来定位物体,那么干脆就用yolo模型先大致确定物体的位置,然后再在大致位置内来做语义分割,这样能够减少干扰。实际上这样做确实能提升精度!当然,如果你的数据够多,可以无视这个曲线救国的方式,直接一把梭。
3.根据语义分割的结果来判断要查询的物体临幸了哪些格子,这样就能得出需要点击的格子的编号。
识别结果
大概标注了3000张图的样子,做了个demo(支持的物体有:公交车、小汽车、桥、停车计价器、棕榈树、人行横道、摩托车、消防栓、红绿灯、出租车、自行车、拖拉机、楼梯、烟囱、船、山),效果还凑合。数据越多,泛化性会越强。
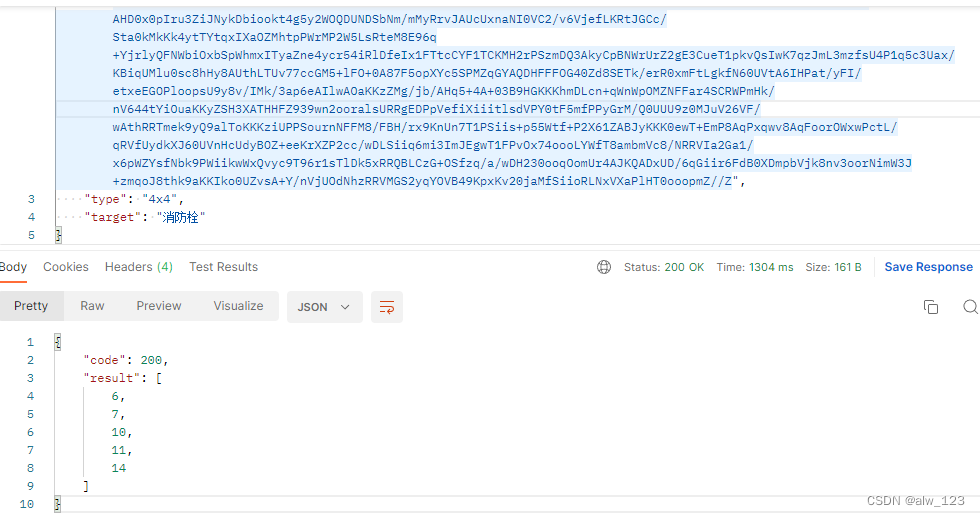
原图(找哪里有消防栓):

结果(result里的数字代表十六宫格的序号,1表示第1行第1列,2表示第1行第2列,以此类推):
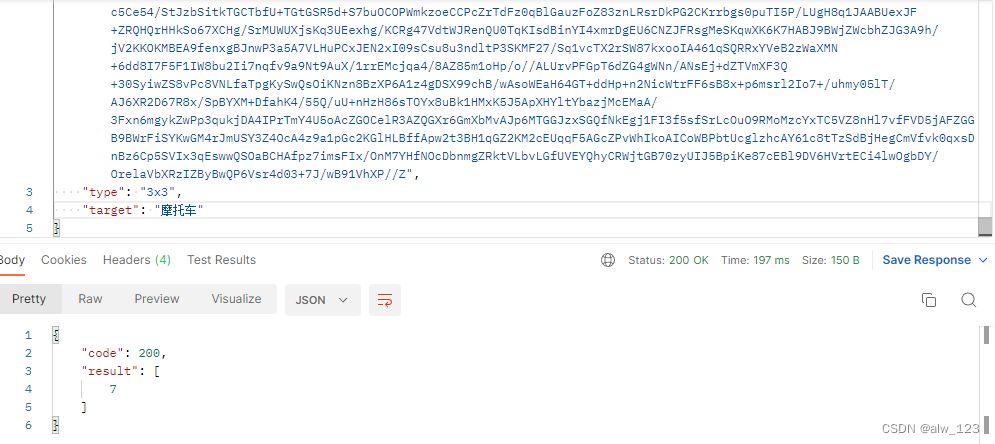
原图(找哪里有摩托车):

结果(result里的数字代表九宫格的序号,1表示第1行第1列,2表示第1行第2列,以此类推):
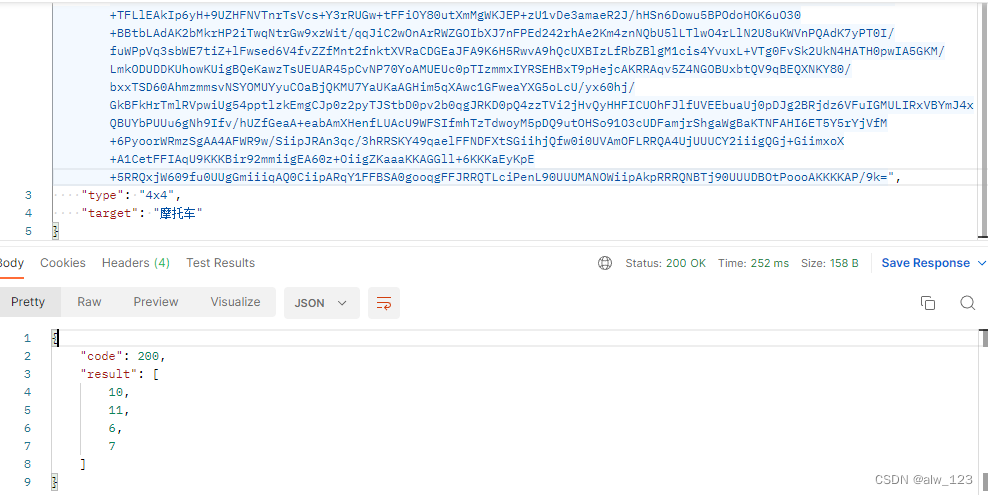
改进点
1.数据太少,因为打标签是真的累。。。如果不怕累就多打标签,或者花钱雇人打标签。毕竟没有人工就没有智能。
2.因为数据少,所以才用了曲线救国的方式。如果对精度要求比较高,还是建议多搞数据。