聊天机器人竞技场排行榜第8周:介绍MT-Bench和Vicuna-33B
| 原文作者:Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Hao Zhang |
|---|
| 日期:2023年6月22日 |
| 以下内容翻译自源英文网址: Chatbot Arena Leaderboard Week 8: Introducing MT-Bench and Vicuna-33B | LMSYS Org |
| 无法保证翻译的正确性 |
文章目录
- 聊天机器人竞技场排行榜第8周:介绍MT-Bench和Vicuna-33B
- 更新后的排行榜和新模型
- 使用MT-bench和Arena评估聊天机器人
- 动机
- 为什么选择MT-Bench?
- 但是,如何评判聊天机器人的回答呢?
- 结果与分析
- MT-Bench有效区分不同聊天机器人
- 多轮对话能力
- LLM评委的解释性
- 如何在MT-Bench上评估新模型
- 后续工作
- 相关工作
- 链接
在本篇博文中,我们分享聊天机器人竞技场排行榜的最新更新,现在包含更多开源模型和三个评估指标:
-
聊天机器人竞技场Elo评分,基于来自聊天机器人竞技场的4.2万匿名用户投票,使用Elo评分系统。
-
MT-Bench评分,基于一套具有挑战性的多轮对话基准测试和GPT-4评分,在我们的判断LLM充当评委论文中提出和验证。
-
MMLU评分,一个广泛采用的基准测试。
此外,我们很高兴推出一系列新的Vicuna-v1.3模型,参数规模从7B到33B,在用户分享对话的扩充数据集上进行了训练。模型权重现已开源。
更新后的排行榜和新模型
表 1. LLM 排行榜(时间范围:2023 年 4 月 24 日至 6 月 19 日)。最新且详细的版本在这里。
| 模型 | MT-bench(分数) | 竞技场Elo评级 | MMLU | 许可 |
|---|---|---|---|---|
| GPT-4 | 8.99 | 1227 | 86.4 | 专有 |
| GPT-3.5-turbo | 7.94 | 1130 | 70.0 | 专有 |
| Claude-v1 | 7.90 | 1178 | 75.6 | 专有 |
| Claude-instant-v1 | 7.85 | 1156 | 61.3 | 专有 |
| Vicuna-33B | 7.12 | - | 59.2 | 非商业用途 |
| WizardLM-30B | 7.01 | - | 58.7 | 非商业用途 |
| Guanaco-33B | 6.53 | 1065 | 57.6 | 非商业用途 |
| Tulu-30B | 6.43 | - | 58.1 | 非商业用途 |
| Guanaco-65B | 6.41 | - | 62.1 | 非商业用途 |
| OpenAssistant-LLaMA-30B | 6.41 | - | 56.0 | 非商业用途 |
| PaLM-Chat-Bison-001 | 6.40 | 1038 | - | 专有 |
| Vicuna-13B | 6.39 | 1061 | 52.1 | 非商业用途 |
| MPT-30B-chat | 6.39 | - | 50.4 | CC-BY-NC-SA-4.0 |
| WizardLM-13B | 6.35 | 1048 | 52.3 | 非商业用途 |
| Vicuna-7B | 6.00 | 1008 | 47.1 | 非商业用途 |
| Baize-v2-13B | 5.75 | - | 48.9 | 非商业用途 |
| Nous-Hermes-13B | 5.51 | - | 49.3 | 非商业用途 |
| MPT-7B-Chat | 5.42 | 956 | 32.0 | CC-BY-NC-SA-4.0 |
| GPT4All-13B-Snoozy | 5.41 | 986 | 43.0 | 非商业用途 |
| Koala-13B | 5.35 | 992 | 44.7 | 非商业用途 |
| MPT-30B-Instruct | 5.22 | - | 47.8 | CC-BY-SA 3.0 |
| Falcon-40B-Instruct | 5.17 | - | 54.7 | Apache 2.0 |
| H2O-Oasst-OpenLLaMA-13B | 4.63 | - | 42.8 | Apache 2.0 |
| Alpaca-13B | 4.53 | 930 | 48.1 | 非商业用途 |
| ChatGLM-6B | 4.50 | 905 | 36.1 | 非商业用途 |
| OpenAssistant-Pythia-12B | 4.32 | 924 | 27.0 | Apache 2.0 |
| RWKV-4-Raven-14B | 3.98 | 950 | 25.6 | Apache 2.0 |
| Dolly-V2-12B | 3.28 | 850 | 25.7 | MIT |
| FastChat-T5-3B | 3.04 | 897 | 47.7 | Apache 2.0 |
| StableLM-Tuned-Alpha-7B | 2.75 | 871 | 24.4 | CC-BY-NC-SA-4.0 |
| LLaMA-13B | 2.61 | 826 | 47.0 | 非商业用途 |
使用MT-bench和Arena评估聊天机器人
动机
尽管已经存在几个大语言模型的基准测试,比如MMLU、HellaSwag和HumanEval,我们注意到这些基准测试在评估语言模型的人类偏好时可能存在不足。传统的基准测试通常针对选择题等封闭性问题进行测试,这与语言模型聊天助手的典型用例不符。
为弥补这一空白,在本次排行榜更新中,除了聊天机器人竞技场Elo系统,我们还新增了一个基准测试:MT-Bench。
-
MT-bench是一个精心策划的多轮对话质量基准测试,设计用于评估模型在多轮对话中的会话流程和遵循指令的能力。您可以在这里查看MT-bench的示例问题和回答。
-
聊天机器人竞技场是一个众包的对战平台,用户可以在上面询问聊天机器人任意问题并选择自己偏好的回答进行投票。
这两个基准测试都以人类偏好作为主要指标。
为什么选择MT-Bench?
MT-Bench是一个精心策划的基准测试,包含80个高质量的多轮对话问题。这些问题经过精心设计,旨在评估模型在多轮对话中的会话流程和遵循指令的能力。它既包含了常见的用例,也包含了用于区分聊天机器人的挑战性指令。MT-Bench作为我们基于众包的评估方式——聊天机器人竞技场的一个质量控制的补充。
通过运行聊天机器人竞技场两个月并分析用户的提示,我们确定了8个主要的用户提示类别:写作、角色扮演、推理、数学、编码、提取、STEM和人文社科。我们为每个类别设计了10个多轮对话问题,共计160个问题。下图显示了一些示例问题。更多问题可以在这里找到。

图1:MT-Bench的示例问题
但是,如何评判聊天机器人的回答呢?
尽管我们认为人类偏好是黄金标准,但收集人类偏好非常缓慢且昂贵。在我们的第一篇Vicuna博文中,我们探索了一种基于GPT-4的自动化评估流程。这种方法随后在几项同期和后续工作中广泛采用。
在我们最新的论文《判断LLM充当评委》中,我们进行了系统研究,以回答这些LLM评委有多可靠。这里我们简要概述结论,建议阅读全文以了解更多细节。
我们首先承认LLM评委可能存在的局限性:
- 位置偏见,LLM评委可能偏向比较中的第一个回答
- 冗长偏见,LLM评委可能偏向更长的回答,不考虑质量
- 自我增强偏见,LLM评委可能偏向自己的回答
- 有限的推理能力,指LLM评委在评判数学和推理问题时的可能缺陷
然后我们探索了如何通过少射判断、思路评判、基准评判和微调评判来缓解这些局限性。
在实施部分解决方案后,我们发现尽管存在局限性,强大的LLM评委如GPT-4可以与受控和众包的人类偏好实现非常好的一致性,达到80%以上的一致率。这一程度的一致性与两个不同人类评委之间的一致性相当。因此,如果谨慎使用,LLM评委可以作为人类偏好的一个可扩展和可解释的近似。
我们还发现,基于GPT-4的单回答评分,不需要成对比较,也可以有效对模型进行排名并与人类偏好匹配得很好。在表1中,我们以MT-Bench的得分形式呈现排行榜的一列。
结果与分析
MT-Bench有效区分不同聊天机器人
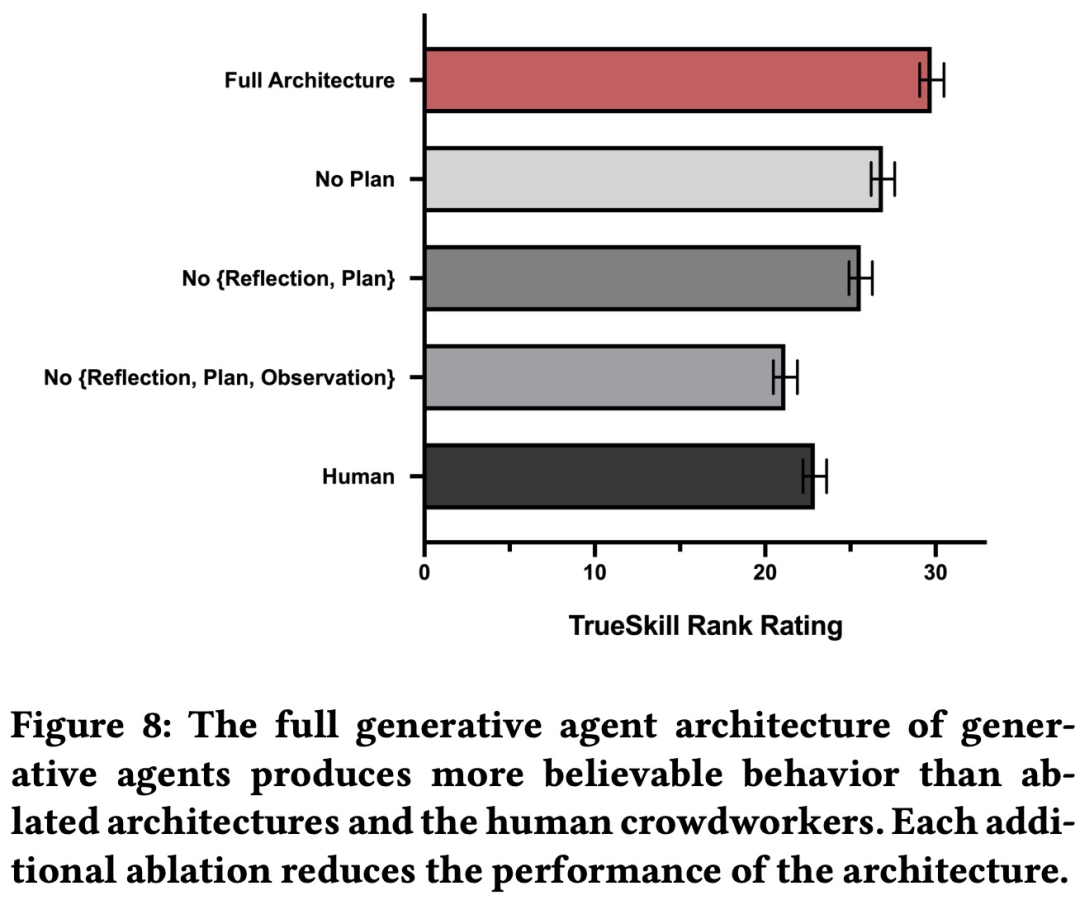
表1详细列出了增强后的基准测试排行榜,我们对28个流行的指令调优模型进行了全面评估。我们观察到聊天机器人具有不同能力的明显区分,分数与聊天机器人竞技场Elo评分高度相关。特别是,MT-Bench揭示了GPT-4与GPT-3.5/Claude之间以及开源和专有模型之间的明显性能差距。
为深入了解聊天机器人之间的区别因素,我们选择了一些代表性聊天机器人,在图2中按类别细分了其表现。与GPT-3.5/Claude相比,GPT-4在编码和推理方面的表现更优,而Vicuna-13B在几个特定类别中表现明显落后:提取、编码和数学。这表明开源模型还有很大的改进空间。
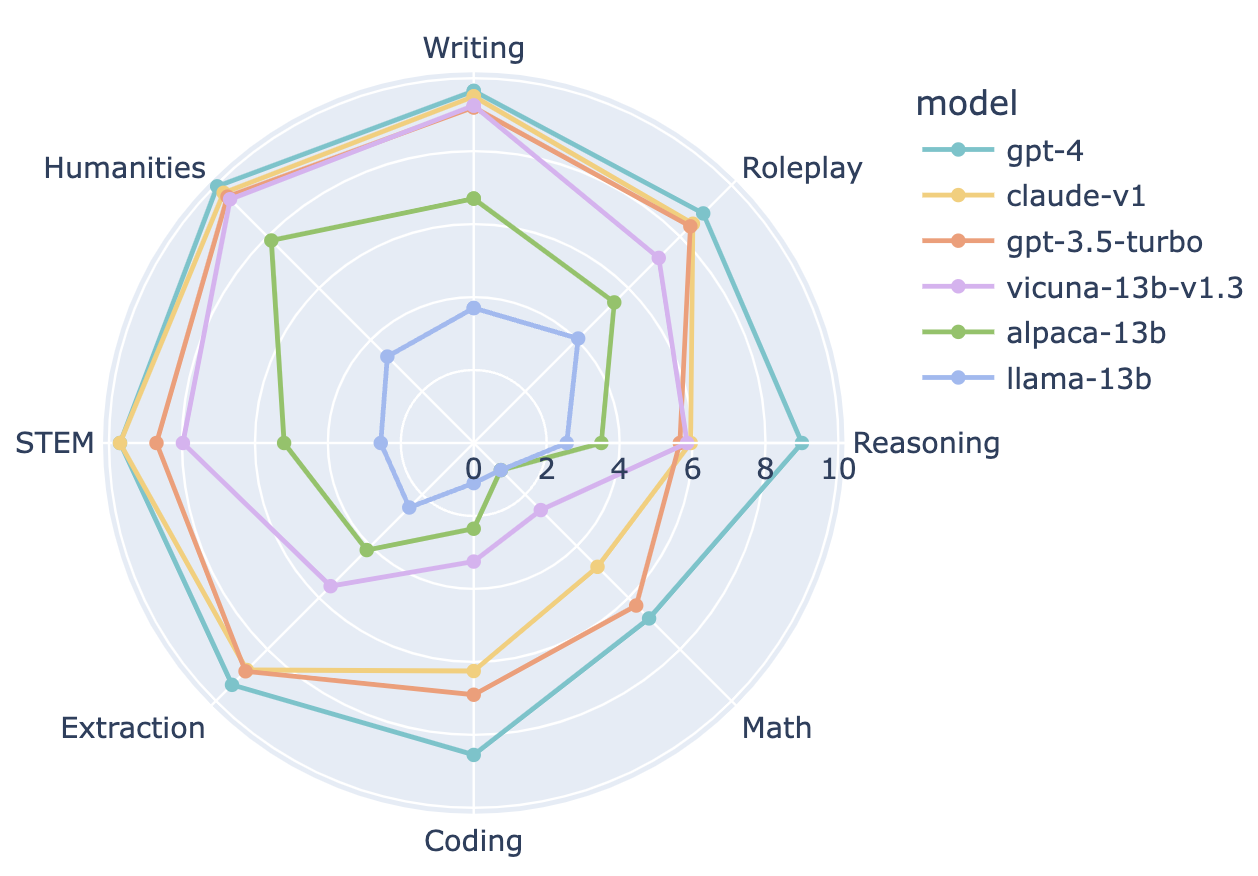
图2: 6个代表性大语言模型在8个类别中的能力比较:写作、角色扮演、推理、数学、编码、提取、客观规律、人文
多轮对话能力
我们接下来分析了选定模型的多轮得分,如表2所示。
表2. 不同LLM在MT-bench中第一轮和第二轮对话的得分明细。满分为10。
| 模型 | 第一轮平均得分 | 第二轮平均得分 | 得分差值 |
|---|---|---|---|
| GPT-4 | 8.96 | 9.03 | 0.07 |
| Claude-v1 | 8.15 | 7.65 | -0.50 |
| GPT-3.5-turbo | 8.08 | 7.81 | -0.26 |
| Vicuna-33B | 7.46 | 6.79 | -0.67 |
| WizardLM-30B | 7.13 | 6.89 | -0.24 |
| WizardLM-13B | 7.12 | 5.59 | -1.53 |
| Guanaco-33B | 6.88 | 6.18 | -0.71 |
| Vicuna-13B | 6.81 | 5.96 | -0.85 |
| PaLM2-Chat-Bison | 6.71 | 6.09 | -0.63 |
| Vicuna-7B | 6.69 | 5.30 | -1.39 |
| Koala-13B | 6.08 | 4.63 | -1.45 |
| MPT-7B-Chat | 5.85 | 4.99 | -0.86 |
| Falcon-40B-instruct | 5.81 | 4.53 | -1.29 |
| H2OGPT-Oasst-Open-LLaMA-13B | 5.51 | 3.74 | -1.78 |
MT-bench在设计中包含了具有挑战性的后续问题。对于开源模型,从第一轮到第二轮表现明显下降(例如Vicuna-7B、WizardLM-13B),而强大的专有模型能够保持一致性。我们还注意到基于LLaMA的模型与许可较宽松的模型(MPT-7B、Falcon-40B和指令调优的Open-LLaMA)之间存在显著的表现差距。
LLM评委的解释性
另一个LLM评委的优势在于它们可以提供可解释的评估。图3展示了GPT-4对MT-bench问题的判断示例,其中alpaca-13b和gpt-3.5-turbo的回答。GPT-4提供了逻辑完整的反馈来支持其判断。我们的研究发现,这些评论有助于引导人类做出更明智的决定(请参阅4.2节了解更多细节)。所有GPT-4判断可以在我们的演示网站上找到。

图3:MT-bench在评估LLM的人类偏好时提供了更多的解释性
总之,我们已经展示了MT-Bench可以有效区分不同能力的聊天机器人。它是可扩展的,通过类别细分提供了有价值的见解,并为人类评委提供解释以核实。但是,LLM评委应谨慎使用。在评判数学/推理问题时,它仍可能出错。
如何在MT-Bench上评估新模型
在MT-bench上评估模型非常简单快速。我们的脚本支持所有huggingface模型,并提供了详细的说明,您可以生成模型对MT-bench问题的回答及其GPT-4判断。您还可以在我们的gradio浏览演示中检查回答和评论。
后续工作
-
发布对话数据
我们正在准备向更广泛的研究社区发布聊天机器人竞技场对话数据。敬请期待更新!
-
MT-bench-1K
MT-Bench目前包含80个精心策划的高质量问题。我们正在积极扩展问题集到MT-Bench-1K,方法是整合来自聊天机器人竞技场的高质量提示并使用LLM自动生成新提示。如果您有任何好的想法,我们很乐意倾听。
-
合作邀请
我们正在与各种组织接洽,探讨在大规模标准化评估人类对LLM偏好的可能性。如果您对此感兴趣,请随时联系我们。
相关工作
在研究如何评估人类偏好和如何利用强大的LLM充当评委进行评估方面,已经进行了大量有趣的工作。欢迎查看他们的作品并了解这个主题的更多观点:
- Judging LLM-as-a-judge with MT-Bench and Chatbot Arena
- Can foundation models label data like humans?
- How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
- The False Promise of Imitating Proprietary LLMs
- AlpacaEval and AlpacaFarm
- Large Language Models are not Fair Evaluators
链接
以下是运行MT-bench和本博文中使用的其他指标的可用工具和代码:
- MT-bench使用fastchat.llm_judge
- 竞技场Elo计算器
- MMLU基于InstructEval和Chain-of-Thought Hub
如果你希望在排行榜上看到更多模型,我们邀请你贡献FastChat或联系我们提供API访问。