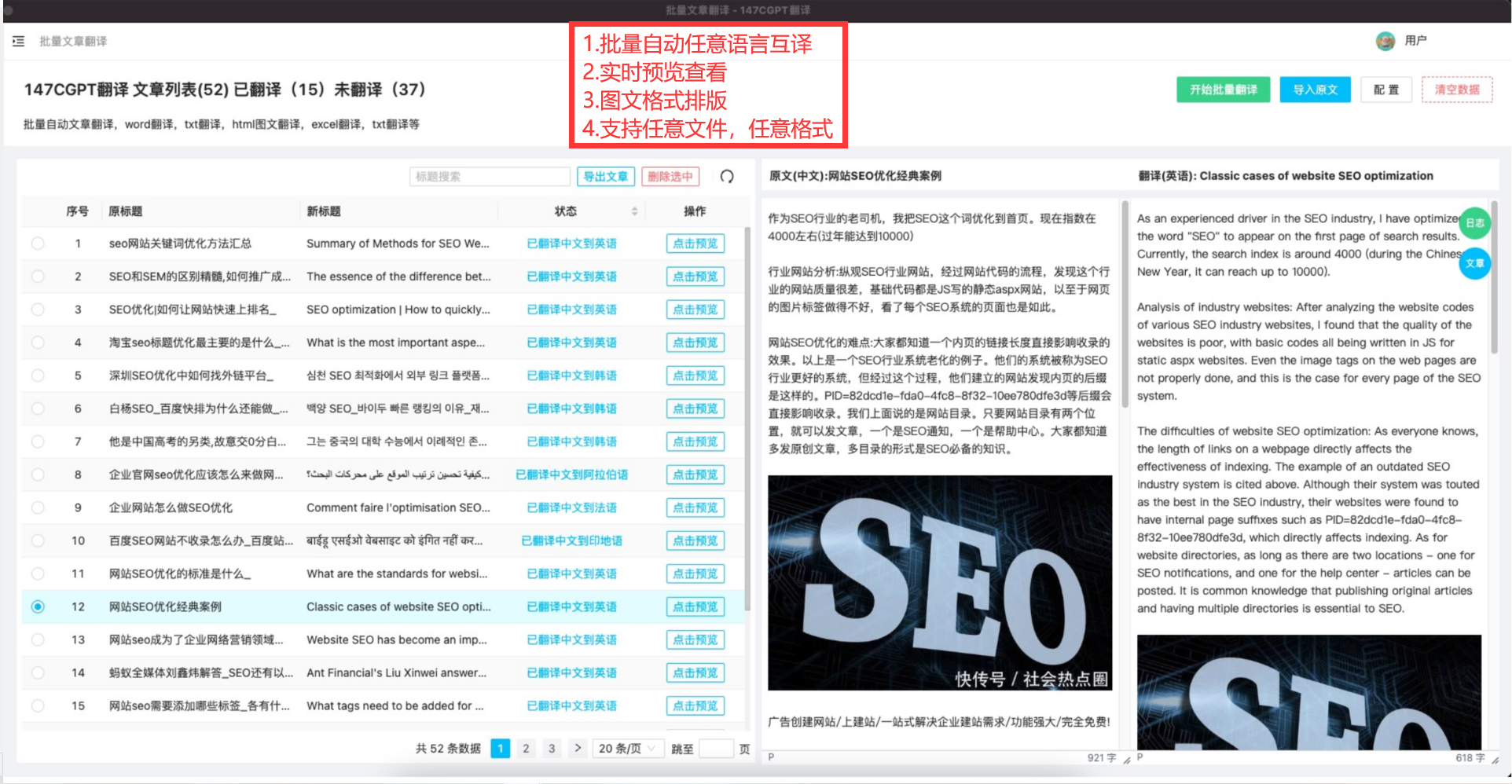
“ 解密 ChatGPT 4的模型架构、训练基础设施、推理基础设施、参数计数、训练数据集组成、令牌计数、层数、并行策略、多模态视觉适应、不同工程权衡背后的思维过程、独特的实施技术。”

01
—
最近偶然看到一份文档《GPT-4 Architecture, Infrastructure, Training Dataset, Costs, Vision, MoE》,内容是国外研究人员根据收集的信息,推测的 ChatGPT 4 的技术细节,应该八九不离十。
原作者认为:OpenAI 拥有令人惊叹的工程技术,他们构建的东西令人难以置信,但他们得出的解决方案并不神奇。这是一个优雅的解决方案,具有许多复杂的权衡。做大只是战略的一部分。OpenAI 最持久的护城河是他们拥有最真实的使用情况、领先的工程人才,并且可以通过未来的模型继续领先于其他人。
我们从许多来源收集了大量有关 GPT-4 的信息,今天我们想分享一下。这包括模型架构、训练基础设施、推理基础设施、参数计数、训练数据集组成、令牌计数、层数、并行策略、多模态视觉适应、不同工程权衡背后的思维过程、独特的实施技术以及它们如何减轻一些问题他们最大的瓶颈与巨型模型的推理有关。
正好前两天 Claude 2 开放了网页版本,还支持阅读 PDF。Claude 2 体验! 免费使用,生成代码,逻辑推理提升,对话记忆更长。
作为 AI 重度患者,这个功能自然要用起来,把 PDF 文档上传上去。

上面的小字提示:“上传一次最多支持5个文件,每个最大10M,接受 pdf,txt, csv,等等”。从上传对话框显示的文件类型显示,这个“等等”里还支持 doc,docx,ppt。
上传图标转了一会儿,上传完成,让 Claude 2 帮助我总结文档中心思想。

GPT-4采用混合专家(MoE)架构,有约180亿参数,120层。每次前向传播只使用约280亿参数,大大减少了推理成本。
训练数据集包含约130万亿个token,其中代码数据有4轮epoch。数据集获取仍是主要瓶颈。
训练成本约为6300万美元,采用了8路tensor并行和15路流水线并行。推理成本比GPT-3大约高3倍。
推理采用了16路混合专家(MoE),每次前向传播选择2个专家。最大批量可达4k+,但利用率较低。多查询注意力机制可降低内存需求。
视觉编码器是单独的,但有交叉注意力。下一代GPT-5将从头训练视觉和音频模块。
主要工程权衡包括混合专家数量、批量大小、推理延迟等。未来可能使用推测性解码加速推理。
多家公司有能力在近期训练类似规模的模型,但OpenAI由于大规模应用拥有持久优势。
文档作者表示:OpenAI 保持 GPT-4 架构的封闭性并不是因为对人类存在一些生存风险,而是因为他们构建的东西是可复制的。事实上, Google、Meta、Anthropic、Inflection、Character、腾讯、字节跳动、百度等在短期内都将拥有与 GPT-4 一样强大的模型。
要想读懂上面的内容,有些名词需要搞清楚,咱们一个一个来。
02
—
Token
Token
在人工智能领域,token是一个非常重要的概念,主要有以下几点含义:
自然语言处理中的词元。一个句子可以被分割成一个一个的词元,每个词元就是一个token。
预训练语言模型中,token通常指字元(character)或者子词(subword)。像BERT和GPT等模型都是以token为基本单位进行预训练的。
token也可以表示任意符号。例如在代码中,一个token可以是一个运算符、标点符号、括号等。
在transformer类模型中,token是嵌入层的基本单位,每个token会被映射为一个向量。
在词向量中,一个词被映射为一个词向量,这个词向量也可以称为该词的token。
在块链中,token代表加密货币中的一个基本单位。
在自然语言生成模型中,token表示每个生成步骤的输出,可以是词也可以是子词。
总结一下,token可以理解为一个符号序列中一个基本的离散的可区分的最小单位。它常用于表示语言和语义的基础元素,是构建预训练语言模型的核心对象。选择恰当的token化方式对提高模型性能非常重要。
在ChatGPT 4 API 的计费中,就是按 token 个数收费。而且不能简单的理解中文一个字、词,英文一个单词就是一个token。API 里有一个免费的接口专门计算一段话的 token 个数。
03
—
epoch
epoch
机器学习中常用的一个概念,指的是训练集上的一次完整遍历。
在训练神经网络模型时,我们通常不会只用训练集训练一遍,而是多次反复训练同一个训练集,每次完整地遍历一遍训练集就称为一个epoch。原因有以下几点:
多轮训练可以使模型更加稳定和收敛,提高 generalization。单轮训练常常会过拟合。
早期epochLoss下降快,后期epochLoss下降慢。多轮训练可以继续优化loss。
每轮参数更新的步长(learning rate)可以不同,早期步长大,后期步长小,这样既保证快速收敛又不会震荡。
多轮训练可以查看loss曲线,判断过拟合或欠拟合并相应调整模型。
数据集较大时,单轮无法载入全部数据,多轮训练可以充分利用数据。
多轮训练还可以进行一些增强技巧,如打乱数据顺序,采样subnet等。
所以在实际训练中,我们一般设置多轮epoch,每个epoch遍历一次全部训练数据。epoch数设置过小会欠拟合,过大又容易过拟合。一般通过观察loss曲线来动态确定epoch数。
generalization 泛化能力
指模型在训练集之外的数据集(通常是验证集和测试集)上的表现。
一个模型在训练集上表现很好(损失很低,准确率很高),但在测试集上表现不佳,就属于过拟合(overfitting),表示模型的 generalization 能力较差。
一个模型希望有好的 generalization 能力,即在训练集以外的数据上也能保持较好的性能。
提高 generalization 的方法有:
增加训练集数据量和多样性
使用正则化技术(L1,L2正则化、Dropout等),减少过拟合
采用批正则化、早停等技术,避免过度训练
使用数据增广,减少过拟合
选择合适的模型大小,不要过大过复杂
多轮训练,早期过拟合,后期提高泛化
采用ensemble技术
在验证集上评估和选择模型
generalization 泛化能力指的是模型能够在训练数据之外的新数据上得到良好表现的能力。这反映了模型真正学习到的数据分布规律,而不是简单地记住训练样本。
具体来说,泛化能力强的模型有以下特点:
不会过度依赖训练数据,不会严重过拟合。
可以推广应用到更广泛的任务上,不会局限在训练任务中。
在不同的测试集上表现稳定,不会出现大幅度波动。
面对新数据时,可以提取关键信息,做出合理预测。
学习到的是真正的数据分布规律,而不是简单记忆训练数据。
在遇到新情况时,可以做出柔性响应,而不是死板应用已学模式。
模型大小合适,既有足够表示能力,又不至于过于复杂。
综上,“泛化能力”体现了一个强AI系统针对新任务、新环境的适应能力,是人工智能追求的重要目标之一。
epoch Loss
指的是机器学习模型在每个epoch(每个训练集轮次)结束时的损失函数值。
通常训练一个神经网络模型要进行多个epoch。在每个epoch中,模型会遍历训练集一次,然后计算一次损失函数,反向传播更新参数。
那么每个epoch结束时计算出的这个损失函数的值,就是epoch Loss。
监测epoch Loss的变化曲线可以判断模型的训练情况,主要可以观察以下几个方面:
epoch Loss是否在持续下降。如果出现明显的上升,可能是出现了过拟合。
下降速度快慢。前期epoch Loss下降明显,后期epoch Loss下降很缓慢,这通常是正常的。
Loss数值的大小。如果Loss数值过大,说明模型仍处于训练初期,效果不佳。
抖动情况。训练初期抖动大,后期抖动小是正常的。过度抖动可能需要调整学习率或者正则化。
观察过拟合。如果验证集上Loss上升,训练集Loss继续下降,说明出现过拟合。
所以观察每个epoch的Loss变化趋势,可以帮助我们判断训练情况,及时优化模型和训练 hyperparameters。
04
—
MoE
MoE:稀疏门控制的专家混合层,又叫混合专家。
Moe,是Mixture-Of-Experts的缩写,可以在保证运算速度的情况下,将模型的容量提升>1000倍。
动机
现在的模型越来越大,训练样本越来越多,每个样本都需要经过模型的全部计算,这就导致了训练成本的平方级增长。
为了解决这个问题,有人提出了一种方式,即将大模型拆分成多个小模型,对于一个样本来说,无需经过所有的小模型去计算,而只是激活一部分小模型进行计算,这样就节省了计算资源。
那么如何决定一个样本去经过哪些小模型呢?这就引入了一个稀疏门机制,即样本输入给这个门,得到要激活的小模型索引,这个门需要确保稀疏性,从而保证计算能力的优化。
在前面的文章中:为什么对ChatGPT、ChatGLM这样的大语言模型说“你是某某领域专家”,它的回答会有效得多?(二),介绍了 ChatGPT 是一个神经网络的数学化版本,上面的细节显示 ChatGPT 采用了 MoE 的架构。
往期热门文章推荐:
AI人工智能大模型失守!ChatGPT、BARD、BING、Claude 相继被"提示攻击"攻陷!
Bard!谷歌对 ChatGPT 的最强反击,悄咪咪的支持中文了!
为什么对ChatGPT、ChatGLM这样的大语言模型说“你是某某领域专家”,它的回答会有效得多?(二)
希望体验ChatGPT 微信机器人的朋友可扫下面的群二维码进群(7月24日前有效): @ ChatGPT智能助手,跟着想的问题即可。

拥抱未来,学习 AI 技能!关注我,免费领取 AI 学习资源。