目录
- K8s简介
- 环境搭建和准备工作
- 修改主机名(所有节点)
- 配置静态IP(所有节点)
- 关闭防火墙和seLinux,清除iptables规则(所有节点)
- 关闭交换分区(所有节点)
- 修改/etc/hosts文件(所有节点)
- 配置ssh免密登录(master节点)
- 加载模块br_netfilter(所有节点)
- 修改内核参数以满足k8s的运行需求(所有节点)
- 配置centos7镜像源(所有节点)
- 安装docker(所有节点)
- 安装k8s(所有节点)
- master节点初始化(master节点)
- 在node1和node2节点执行join
- 使用kubectl管理集群(master节点)
- 安装CNI网络插件
- 安装Calico(master节点)
K8s简介
Kubernetes(简称 K8s)是一个开源的容器编排平台。
起源与发展
- K8s 最初由谷歌公司开发,于 2014 年开源。它借鉴了谷歌内部大规模容器管理的经验和技术,旨在为容器化应用提供一个高效、可靠、可扩展的管理平台。
- 随着容器技术的快速发展和广泛应用,K8s 迅速成为容器编排领域的事实标准,被众多企业和组织广泛采用,并且在不断地发展和完善中,社区活跃度极高,持续推动着 K8s 功能的丰富和性能的提升。
主要组件
- Master 节点:是 K8s 集群的控制中心,负责管理和协调整个集群。包含 API Server、Scheduler、Controller Manager 等组件,API Server 提供了 K8s 的 API 接口,用于接收和处理用户请求;Scheduler 负责将 Pod 调度到合适的 Node 节点上;Controller Manager 负责管理和维护集群中各种资源的状态。
- Node 节点:是 K8s 集群中的工作节点,用于运行容器化应用。包含 kubelet、kube-proxy 等组件,kubelet 负责与 Master 节点通信,接收并执行 Master 节点下达的任务,管理本节点上的容器;kube-proxy 负责实现 Pod 的网络代理和负载均衡功能。
环境搭建和准备工作
使用三台一模一样的centos7虚拟机,内存4G,4核,40G磁盘,一台做master,另外两台做node。
[root@localhost ~]# cat /etc/centos-release
CentOS Linux release 7.9.2009 (Core)
[root@localhost ~]# uname -a
Linux localhost.localdomain 3.10.0-1160.el7.x86_64 #1 SMP Mon Oct 19 16:18:59 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
[root@localhost ~]#
修改主机名(所有节点)
分别执行。
hostnamectl set-hostname master
hostnamectl set-hostname node1
hostnamectl set-hostname node2
配置静态IP(所有节点)
vim /etc/sysconfig/network-scripts/ifcfg-ens33
# 将BOOTPROTO从dhcp改为static或none
BOOTPROTO=static
# 若没有ONBOOT添加
ONBOOT=yes
# 下面的都需要添加,如果在桥接模式下ip地址要和实体机相同网段,网关要和实体机网关相同。如果是nat则和nat网段相同。
IPADDR=192.168.3.147
PREFIX=24
GATEWAY=192.168.3.1
#DNS服务器可以只配置一个,当然也可以配置两个
DNS1=114.114.114.114
DNS2=8.8.8.8配置完成后重启网络服务
systemctl restart network
关闭防火墙和seLinux,清除iptables规则(所有节点)
为了防止干扰k8s运行。
# 关闭防火墙并且设置开机不启动
systemctl stop firewalld
systemctl disable firewalld
# 关闭seLinux,getenforce是获取seLinux的状态
# 没有设置过seLinux一般getenforce查询结果为Enforcing,需设置为disable关闭
getenforce
# 直接修改文件,改为SELINUX=disabled,重启之后生效
vim /etc/selinux/config
# 清除iptables规则
iptables -F
关闭交换分区(所有节点)
高版本的k8s要求必须关闭分区。
# 临时关闭
swapoff -a
# 修改/etc/fstab文件永久关闭,将文件中/dev/mapper/centos-swap swap行注释即可,也可以直接运行下面这条命令
sed -i '/swap/ s/^\(.*\)$/#\1/g' /etc/fstab修改/etc/hosts文件(所有节点)
# 直接运行下面的命令,记得将IP地址修改为自己机器的IP地址,主机名字也换成自己的
cat >> /etc/hosts << EOF
192.168.3.147 master
192.168.3.146 node1
192.168.3.145 node2
EOF配置ssh免密登录(master节点)
先生成密钥
ssh-keygen
再复制到所有节点
ssh-copy-id master
ssh-copy-id node1
ssh-copy-id node2
测试连接,免密登录
ssh node1
# 登出
exit
加载模块br_netfilter(所有节点)
# 临时加载
modprobe br_netfilter
# 永久加载,创建文件,在文件中写入模块名字br_netfilter
vim /etc/modules-load.d/k8s.confsystemctl restart systemd-modules-load.service
修改内核参数以满足k8s的运行需求(所有节点)
cat <<EOF >> /etc/sysctl.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.ip_forward = 1
vm.swappiness=0
EOF# 重新加载系统参数配置,让上面的修改生效
sysctl -p配置centos7镜像源(所有节点)
报错:
- Could not retrieve mirrorlist http://mirrorlist.centos.org/?release=7&arch=x86_64&repo=os&infra=stock error was
CentOS 7 仓库已经被归档,当前的镜像地址无法找到所需的文件。CentOS 7 的官方支持已经结束,部分仓库已被移至归档库。导致 yum 命令无法找到所需的元数据文件。
cd /etc/yum.repos.d
mv CentOS-Base.repo CentOS-Base.repo.backup
vim CentOS-Base.repo
添加如下内容
# CentOS-Base.repo
#
# The mirror system uses the connecting IP address of the client and the
# update status of each mirror to pick mirrors that are updated to and
# geographically close to the client. You should use this for CentOS updates
# unless you are manually picking other mirrors.
#
# If the mirrorlist= does not work for you, as a fall back you can try the
# remarked out baseurl= line instead.
#
#[base]
name=CentOS-$releasever - Base
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=os&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/os/$basearch/
#baseurl=http://vault.centos.org/7.9.2009/x86_64/os/
baseurl=http://vault.centos.org/7.9.2009/os/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7#released updates
[updates]
name=CentOS-$releasever - Updates
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=updates&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/updates/$basearch/
#baseurl=http://vault.centos.org/7.9.2009/x86_64/os/
baseurl=http://vault.centos.org/7.9.2009/updates/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7#additional packages that may be useful
[extras]
name=CentOS-$releasever - Extras
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=extras&infra=$infra
#$baseurl=http://mirror.centos.org/centos/$releasever/extras/$basearch/
#baseurl=http://vault.centos.org/7.9.2009/x86_64/os/
baseurl=http://vault.centos.org/7.9.2009/extras/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7#additional packages that extend functionality of existing packages
[centosplus]
name=CentOS-$releasever - Plus
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=centosplus&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/centosplus/$basearch/
#baseurl=http://vault.centos.org/7.9.2009/x86_64/os/
baseurl=http://vault.centos.org/7.9.2009/centosplus/$basearch/
gpgcheck=1
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
再添加阿里镜像源。
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
执行生效。
um clean all
um makecache
安装docker(所有节点)
#安装工具包
yum install -y yum-utils
# 使用工具包自动下载docker,这是官方的源,太卡
#yum-config-manager \
# --add-repo \
# https://download.docker.com/linux/centos/docker-ce.repo#建议使用阿里云镜像替换官方源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo# 指定版本安装docker
yum install -y docker-ce-20.10.0 docker-ce-cli-20.10.0 containerd.io# 开启docker服务
systemctl start docker
# 设置开机启动
systemctl enable docker
- 配置Docker使用systemd作为默认Cgroup驱动。
- 配置docker镜像源。
vim /etc/docker/daemon.json
{"registry-mirrors": ["https://71v143bd.mirror.aliyuncs.com","https://docker.m.daocloud.io"],"exec-opts": ["native.cgroupdriver=systemd"]
}#重启docker
systemctl daemon-reload
systemctl restart docker
安装k8s(所有节点)
添加k8s yum源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF安装kubeadm,kubelet,kubectl(指定版本)
yum install -y kubelet-1.23.6 kubeadm-1.23.6 kubectl-1.23.6设置kubelet开机自启动
systemctl enable kubelet安装CoreDNS容器(k8s集群运行时需要CoreDNS提供DNS解析服务)
docker pull registry.aliyuncs.com/google_containers/coredns:v1.8.4
master节点初始化(master节点)
使用kubeadm init命令进行初始化。
- apiserver-advertise-address修改为master主机IP地址。
- –pod-network-cidr有两个值,打算使用calico网络插件时,最好使用192.168.0.0/16,打算使用flannel网络插件时最好使用10.244.0.0/16;这两个都是相应网络插件的默认IP,否则需要修改对应配置文件。
kubeadm init \
--apiserver-advertise-address=192.168.3.147 \
--image-repository registry.aliyuncs.com/google_containers \
--service-cidr=10.1.0.0/16 \
#--pod-network-cidr=10.244.0.0/16
--pod-network-cidr=192.168.0.0/16
--kubernetes-version=v1.23.6等待几分钟,看到下面的内容说明成功了。
注意红圈中的命令,在节点机器运行kubeadm join部分的命令加入节点。

在node1和node2节点执行join
kubeadm join 192.168.3.147:6443 --token v2q814.ab6aywry0350o52v \--discovery-token-ca-cert-hash sha256:4fe3d2cebdcb34b198e43bfd1453d15bbad5cac7b98c902776a7795bd26214ec
执行成功输出:

使用kubectl管理集群(master节点)
初始化kubectl
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config查看节点状态
kubectl get node

到这里发现所有节点为NotReady状态,这是因为完成互通还需要安装CNI(Container Networking Interface)网络插件。
安装CNI网络插件
CNI 全称是“Container Networking Interface”,即容器网络接口,它提供了一种标准的插件机制,用于连接容器到底层网络中。CNI 插件是一种可执行程序,它将实现容器网络连接的一些逻辑打包在一起,允许容器使用不同的网络模型,并提供了一组网络抽象接口。在 Kubernetes 等容器编排平台中,CNI 插件被广泛使用来实现容器网络。
CNI 插件可以由第三方厂商开发和维护,因此,可以选择最适合自己的插件。CNI 插件通常运行在主机上,并由容器运行时调用,例如 Docker、rkt 等。当容器需要连接到主机网络时,CNI 插件将会为其创建必要的网络接口和路由规则。
一些常用的 CNI 插件包括:
- Flannel:一个简单易用的网络解决方案,支持多种部署模式。
- Calico:一个高度可扩展的容器网络方案,旨在为大规模生产环境提供网络和安全性。
- Weave Net:一个分布式的容器网络方案,具有良好的可扩展性和高度自动化的管理。
- Cilium:一个基于 eBPF 的容器网络和安全解决方案,提供强大的流量控制和安全性。
安装Calico(master节点)
先创建个文件夹,用于存放配置文件:
mkdir -p /work/devops/k8s/config
cd /work/devops/k8s/config
下载calico配置文件
wget https://docs.tigera.io/archive/v3.25/manifests/calico.yaml
修改calico配置文件
vim calico.yaml
原来的配置
# - name: CALICO_IPV4POOL_CIDR
# value: "192.168.0.0/16"
修改后的配置(注意:value与上边kubeadm init的–pod-network-cidr参数保持一致)
- 特别注意:修改的两行一定要注意缩进和上面的内容保持一致,否则会报奇奇怪怪的错误。

启用calico
kubectl apply -f ./calico.yaml
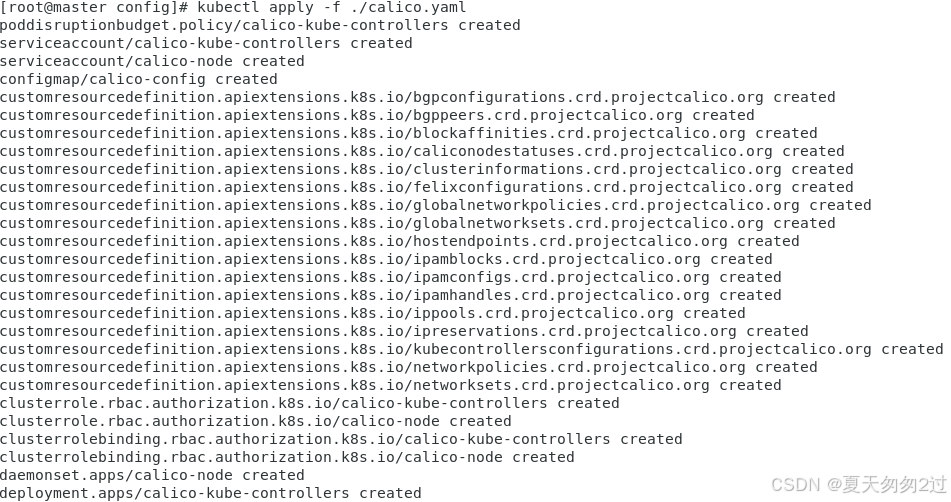
查看pod状态
kubectl get pods -A
Calico的状态错误Init:ImagePullBackOff或Init:ErrImagePull,镜像没有拉取成功。

可以删除失败pod,重新拉取,但通常还是失败,calico-node-bvvhc替换成实际镜像名称。
kubectl get pods -n kube-system | grep calico-node-bvvhc | awk '{print$1}'| xargs kubectl delete -n kube-system pods
可以手动拉取calico,注意这一步所有节点都要执行。
docker pull calico/cni:v3.25.0
上一步完成后,再次查询pod状态,镜像已经在拉取了。
kubectl get pods -A
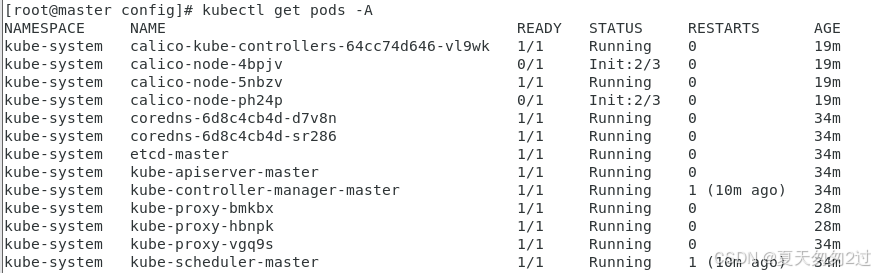
查询节点状态,都是Ready。