编|桃子 好困
源|新智元
Meta的SAM「分割一切」模型刚发布,国内团队就进行了二创,打造了一个最强的零样本视觉应用Grounded-SAM,不仅能分割一切,还能检测一切,生成一切。
Meta的「分割一切」模型横空出世后,已经让圈内人惊呼CV不存在了。
就在SAM发布后一天,国内团队在此基础上搞出了一个进化版本「Grounded-SAM」。

Grounded-SAM把SAM和BLIP、Stable Diffusion集成在一起,将图片「分割」、「检测」和「生成」三种能力合一,成为最强Zero-Shot视觉应用。
网友纷纷表示,太卷了!

谷歌大脑的研究科学家、滑铁卢大学计算机科学助理教授Wenhu Chen表示「这也太快了」。

AI大佬沈向洋也向大家推荐了这一最新项目:
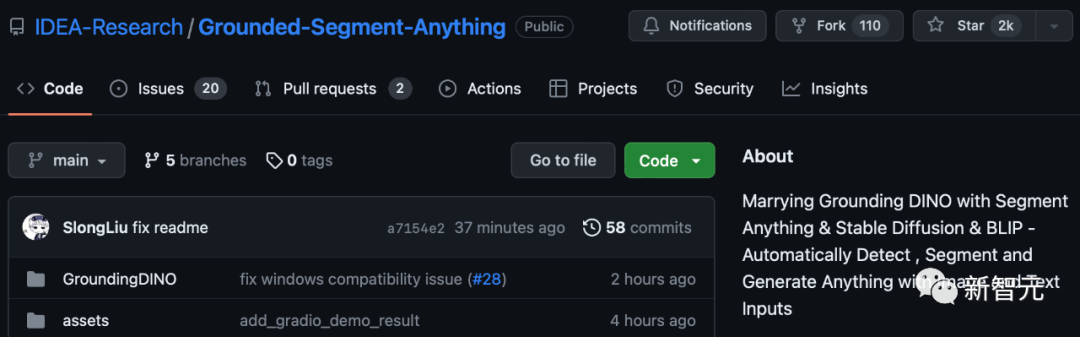
Grounded-Segment-Anything:自动检测、分割和生成任何有图像和文本输入的东西。边缘分割可以进一步改进。

截至目前,这个项目在GitHub上已经狂揽2k星。
检测一切,分割一切,生成一切
上周,SAM的发布让CV迎来了GPT-3时刻。甚至,Meta AI声称这是史上首个图像分割基础模型。
该模型可以在统一的框架prompt encoder内,指定一个点、一个边界框、一句话,直接一键分割出任何物体。

SAM具有广泛的通用性,即具有了零样本迁移的能力,足以涵盖各种用例,不需要额外训练,就可以开箱即用地用于新的图像领域,无论是水下照片,还是细胞显微镜。

由此可见,SAM可以说是强到发指。
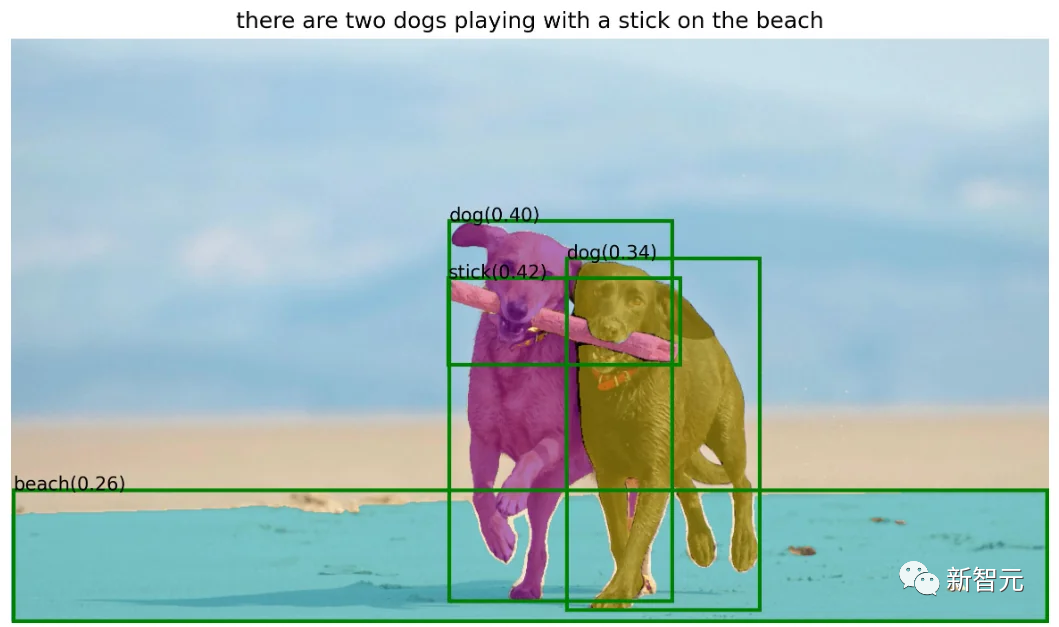
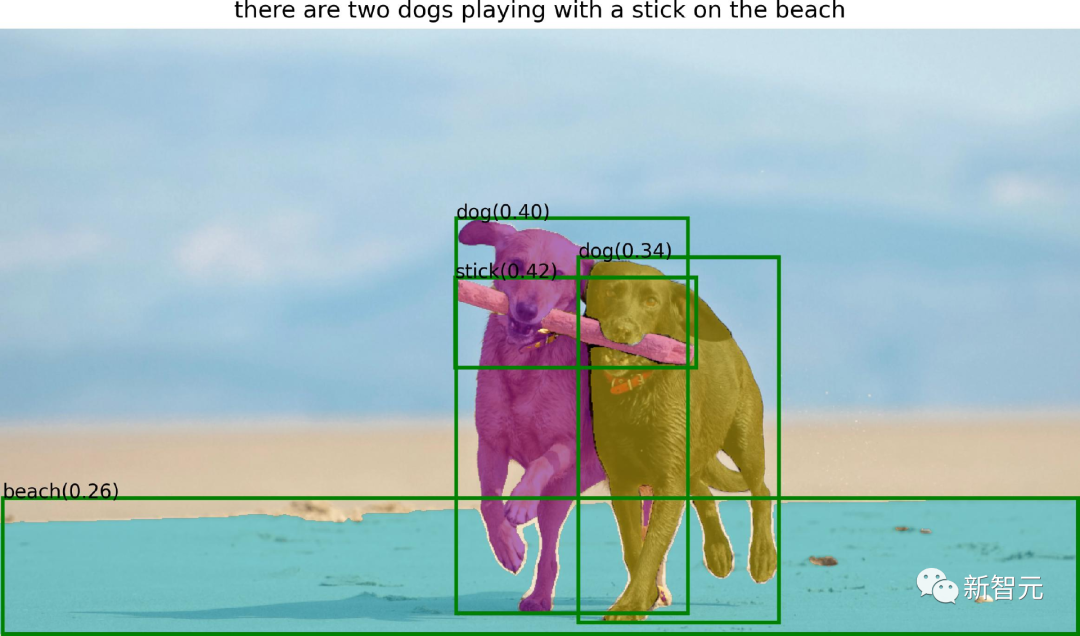
而现在,国内研究者基于这个模型想到了新的点子,将强大的零样本目标检测器Grounding DINO与之结合,便能通过文本输入,检测和分割一切。
借助Grounding DINO强大的零样本检测能力,Grounded SAM可以通过文本描述就可以找到图片中的任意物体,然后通过SAM强大的分割能力,细粒度的分割出mas。
最后,还可以利用Stable Diffusion对分割出来的区域做可控的文图生成。

再Grounded-SAM具体实践中,研究者将Segment-Anything与3个强大的零样本模型相结合,构建了一个自动标注系统的流程,并展示出非常非常令人印象深刻的结果!
这一项目结合了以下模型:
BLIP:强大的图像标注模型
Grounding DINO:最先进的零样本检测器
Segment-Anything:强大的零样本分割模型
Stable-Diffusion:出色的生成模型
所有的模型既可以组合使用,也可以独立使用。组建出强大的视觉工作流模型。整个工作流拥有了检测一切,分割一切,生成一切的能力。
该系统的功能包括:
BLIP+Grounded-SAM=自动标注器
使用BLIP模型生成标题,提取标签,并使用Ground-SAM生成框和掩码:
半自动标注系统:检测输入的文本,并提供精确的框标注和掩码标注。

全自动标注系统:
首先使用BLIP模型为输入图像生成可靠的标注,然后让Grounding DINO检测标注中的实体,接着使用SAM在其框提示上进行实例分割。
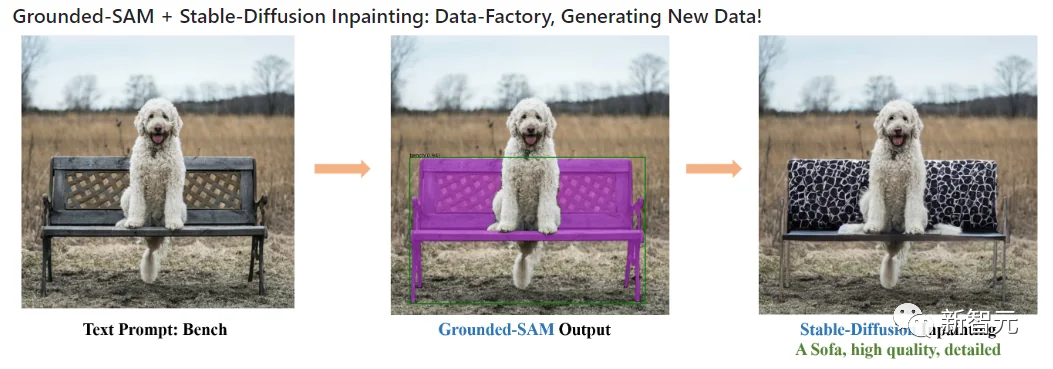
Stable Diffusion+Grounded-SAM=数据工厂
用作数据工厂生成新数据:可以使用扩散修复模型根据掩码生成新数据。
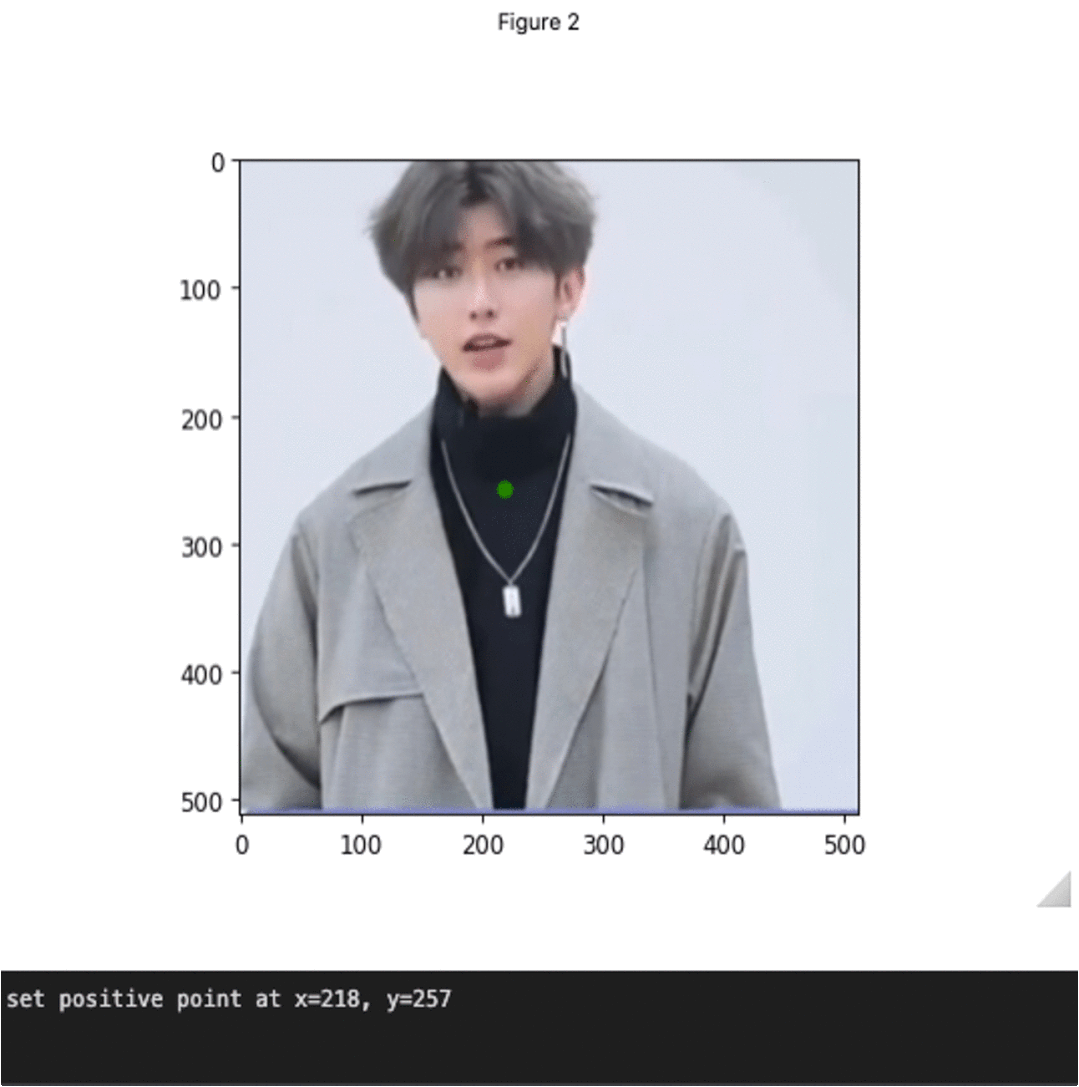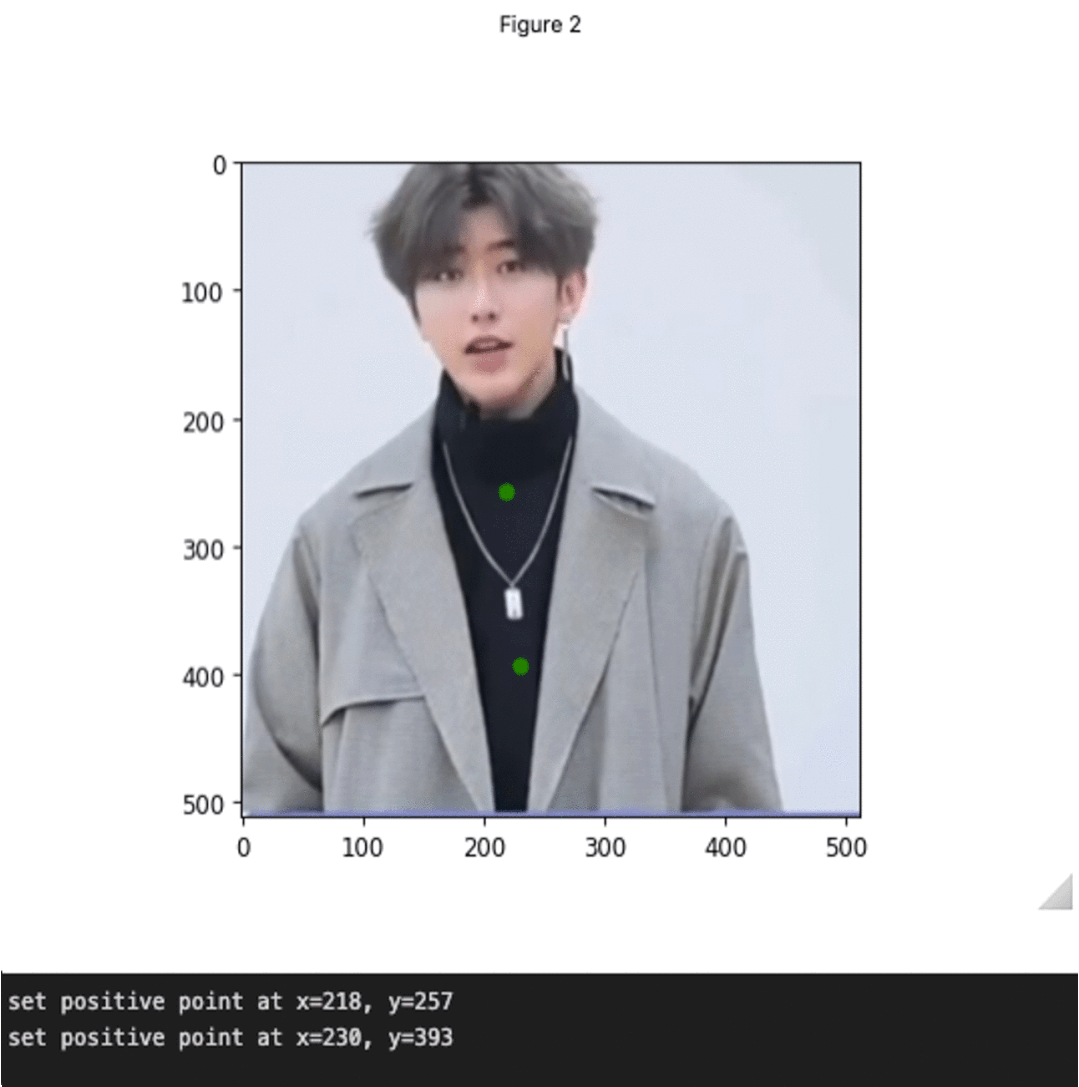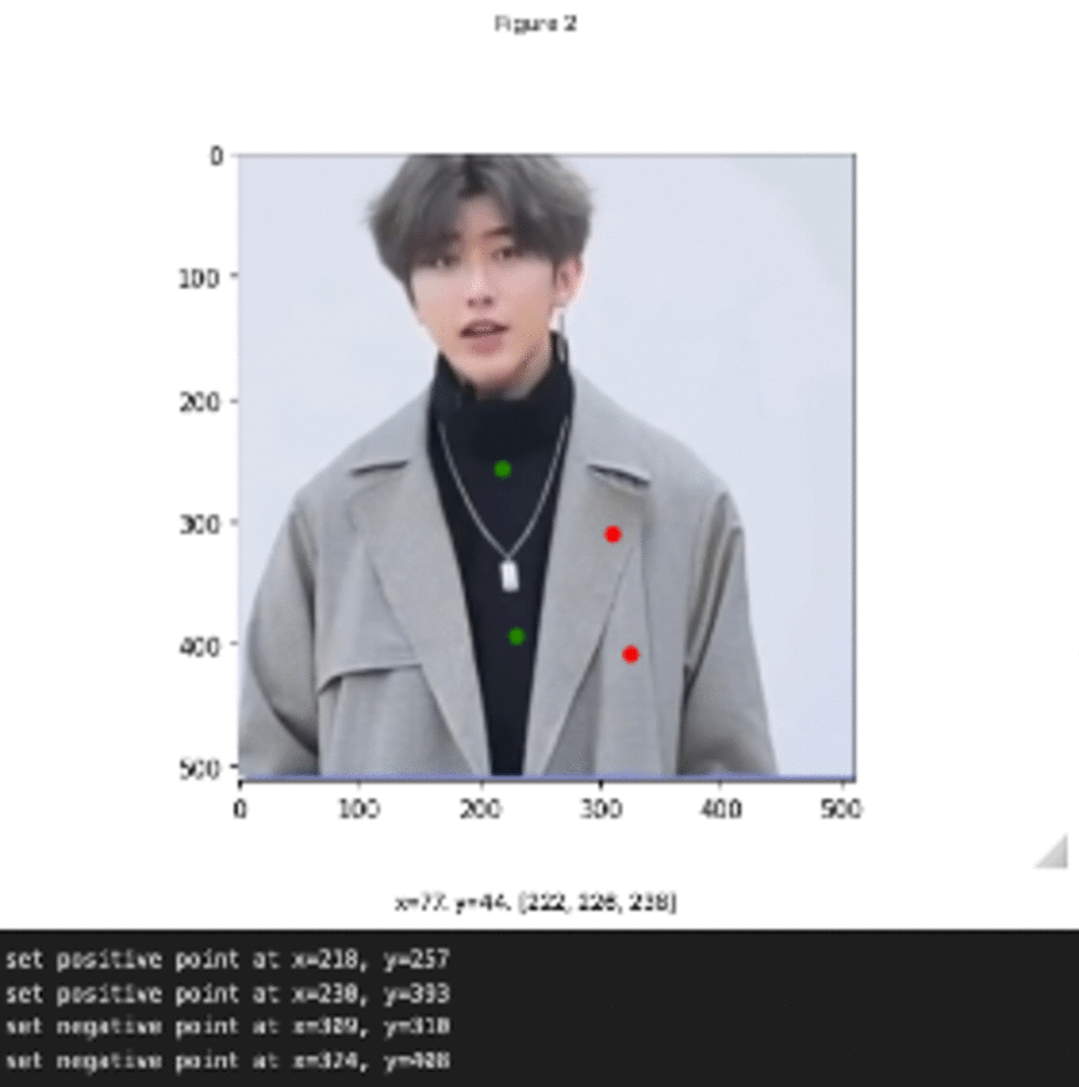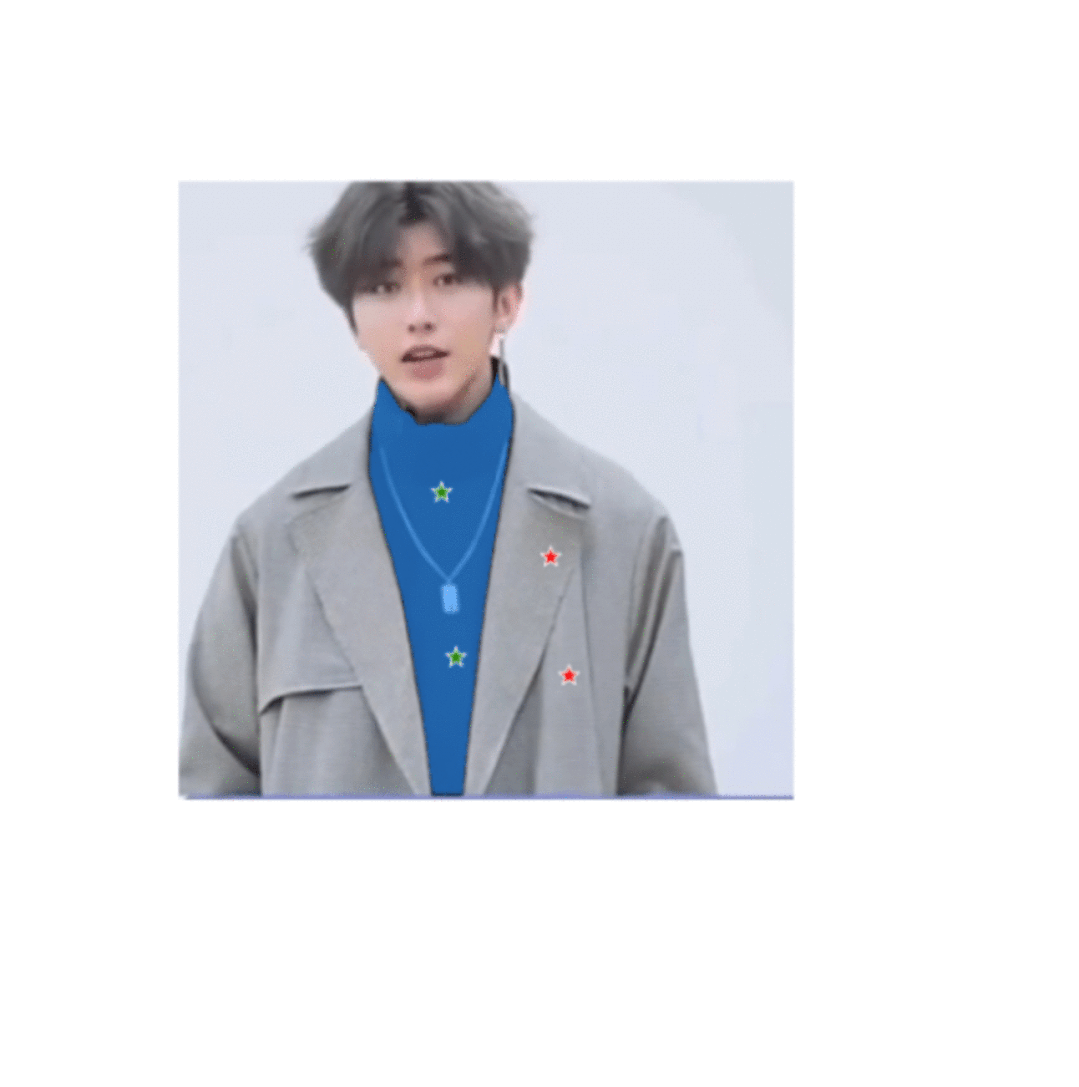
Segment Anything+HumanEditing
在这个分支中,作者使用Segment Anything来编辑人的头发/面部。
SAM+头发编辑


SAM+时尚编辑

作者对于Grounded-SAM模型提出了一些未来可能的研究方向:
自动生成图像以构建新的数据集;分割预训练的更强大的基础模型;与(Chat-)GPT模型的合作;一个完整的管道,用于自动标注图像(包括边界框和掩码),并生成新图像。
作者介绍
Grounded-SAM项目其中的一位研究者是清华大学计算机系的三年级博士生刘世隆。
他近日在GitHub上介绍了自己和团队一起做出的最新项目,并称目前还在完善中。

现在,刘世隆是粤港澳大湾区数字经济研究院(IDEA研究院),计算机视觉与机器人研究中心的实习生,由张磊教授指导,主要研究方向为目标检测,多模态学习。
在此之前,他于2020年获得了清华大学工业工程系的学士学位,并于2019年在旷视实习过一段时间。

个人主页:http://www.lsl.zone/
顺便提一句,刘世隆也是今年3月份发布的目标检测模型Grounding DINO的一作。
此外,他的4篇论文中了CVPR 2023,2篇论文被ICLR 2023接收,1篇论文被AAAI 2023接收。

论文地址:
https://arxiv.org/pdf/2303.05499.pdf
而刘世隆提到的那位大佬——任天和,目前在IDEA研究院担任计算机视觉算法工程师,也由张磊教授指导,主要研究方向为目标检测和多模态。

此外,项目的合作者还有,中国科学院大学博士三年级学生黎昆昌,主要研究方向为视频理解和多模态学习;IDEA研究院计算机视觉与机器人研究中心实习生曹赫,主要研究方向为生成模型;以及阿里云高级算法工程师陈佳禹。

安装运行
项目需要安装python 3.8及以上版本,pytorch 1.7及以上版本和torchvision 0.8及以上版本。此外,作者强烈建议安装支持CUDA的PyTorch和TorchVision。
安装Segment Anything:
python -m pip install -e segment_anything安装GroundingDINO:
python -m pip install -e GroundingDINO安装diffusers:
pip install --upgrade diffusers[torch]安装掩码后处理、以COCO格式保存掩码、example notebook和以ONNX格式导出模型所需的可选依赖。同时,项目还需要jupyter来运行example notebook。
pip install opencv-python pycocotools matplotlib onnxruntime onnx ipykernelGrounding DINO演示
下载groundingdino检查点:
cd Grounded-Segment-Anything
wget https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth运行demo:
export CUDA_VISIBLE_DEVICES=0
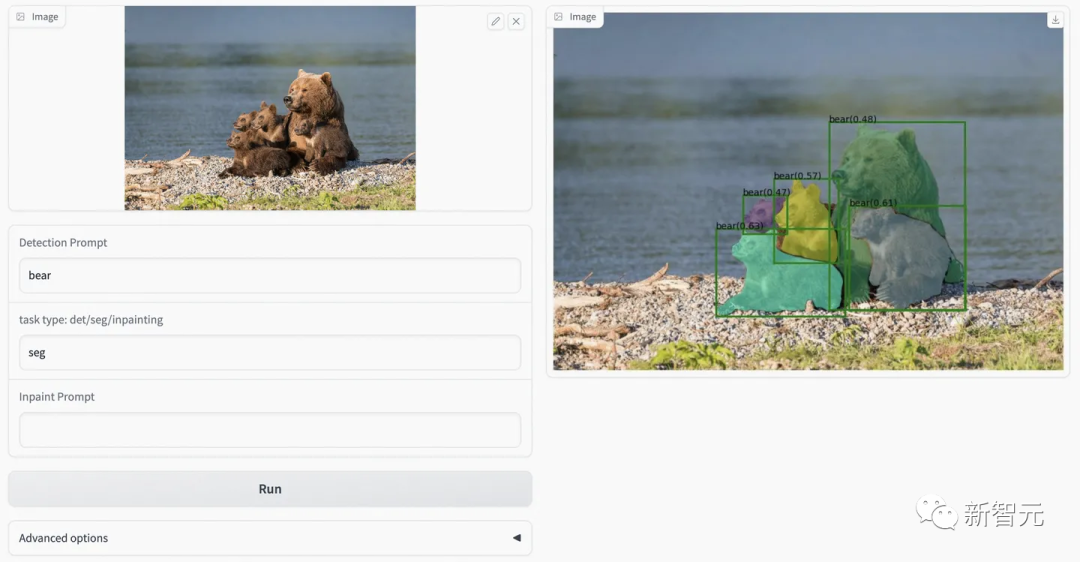
python grounding_dino_demo.py \--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \--grounded_checkpoint groundingdino_swint_ogc.pth \--input_image assets/demo1.jpg \--output_dir "outputs" \--box_threshold 0.3 \--text_threshold 0.25 \--text_prompt "bear" \--device "cuda"模型预测可视化将保存在output_dir中,如下所示:

Grounded-Segment-Anything+BLIP演示
自动生成伪标签很简单:
使用BLIP(或其他标注模型)来生成一个标注。
从标注中提取标签,并使用ChatGPT来处理潜在的复杂句子。
使用Grounded-Segment-Anything来生成框和掩码。
export CUDA_VISIBLE_DEVICES=0
python automatic_label_demo.py \--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \--grounded_checkpoint groundingdino_swint_ogc.pth \--sam_checkpoint sam_vit_h_4b8939.pth \--input_image assets/demo3.jpg \--output_dir "outputs" \--openai_key your_openai_key \--box_threshold 0.25 \--text_threshold 0.2 \--iou_threshold 0.5 \--device "cuda"伪标签和模型预测可视化将保存在output_dir中,如下所示:
Grounded-Segment-Anything+Inpainting演示
CUDA_VISIBLE_DEVICES=0
python grounded_sam_inpainting_demo.py \--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \--grounded_checkpoint groundingdino_swint_ogc.pth \--sam_checkpoint sam_vit_h_4b8939.pth \--input_image assets/inpaint_demo.jpg \--output_dir "outputs" \--box_threshold 0.3 \--text_threshold 0.25 \--det_prompt "bench" \--inpaint_prompt "A sofa, high quality, detailed" \--device "cuda"Grounded-Segment-Anything+Inpainting Gradio APP
python gradio_app.py作者在此提供了可视化网页,可以更方便的尝试各种例子。
网友评论
对于这个项目logo,还有个深层的含义:
一只坐在地上的马赛克风格的熊。坐在地面上是因为ground有地面的含义,然后分割后的图片可以认为是一种马赛克风格,而且马塞克谐音mask,之所以用熊作为logo主体,是因为作者主要示例的图片是熊。

看到Grounded-SAM后,网友表示,知道要来,但没想到来的这么快。

项目作者任天和称,「我们用的Zero-Shot检测器是目前来说最好的。」

未来,还会有web demo上线。
最后,作者表示,这个项目未来还可以基于生成模型做更多的拓展应用,例如多领域精细化编辑、高质量可信的数据工厂的构建等等。欢迎各个领域的人多多参与。
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
[1]https://github.com/IDEA-Research/Grounded-Segment-Anything
[2]https://www.reddit.com/r/MachineLearning/comments/12gnnfs/r_groundedsegmentanything_automatically_detect/
[3]https://zhuanlan.zhihu.com/p/620271321