一、介绍
自然语言处理(NLP)是计算方法的应用,不仅可以从文本中提取信息,还可以在其上对不同的应用程序进行建模。所有基于语言的文本都有系统的结构或规则,通常被称为形态学,例如“跳跃”的过去时总是“跳跃”。对于人类来说,这种形态学的理解是显而易见的。
在这篇介绍性的NLP博客中,我们将看到不同的方法来确定语言的形态结构和规则。
二、 标记化和分词
将文本分割成相关单词的任务称为标记化。
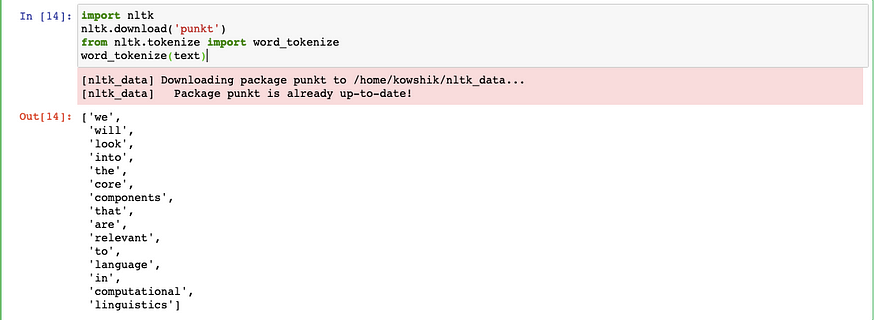
在最简单的形式中,可以通过使用空格拆分文本来实现标记化。NLTK 提供了一个名为 word_tokenize() 的函数,用于将字符串拆分为标记。
text = 'we will look into the core components that are relevant to language in computational linguistics'
但是简单的标记化并不是一直有效。对于涉及单词之间标点符号的复杂单词(例如:是什么)