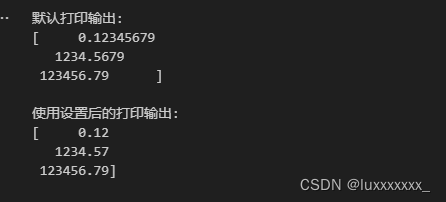
本篇文章主要介绍了Rust中流处理的概念、方法和优化。作者不仅介绍了流处理的基本概念以及Rust中常用的流处理库,还使用这些库实现了一个流处理程序。
最后,作者介绍了如何通过测量空闲和阻塞时间来优化流处理程序的性能,并将这些内容同步至Twitter和blog。
此外,作者还提供了一些其它方面的优化建议,例如:
- 在实际系统中,应考虑将线程固定至CPU内核上或使用一种版本的绿色线程减少上下文切换。
- 在处理流时,通常需要为结果分配内存。内存分配是昂贵的,所以,在以后的文章中,作者将会介绍一些优化内存分配的好方法。
首先,分别介绍下在同步和异步Rust中的流特质。
一、同步和异步Rust中的流特质
在同步Rust中,流核心抽象是Iterator。它提供了在序列中产生项的方法并在它们之间进行阻塞,然后,通过将迭代器传递给其它迭代器的构造函数完成组合。这使我们可以毫不费力地将事物连接在一起。
在异步Rust中,流核心抽象是Stream。它的行为与Iterator非常相似;但是,它并不是在每个项之间产生的阻塞,而是允许其它任务在阻塞等待时运行。
在异步Rust与同步Rust中,Read和Write分别对应AsyncRead和AsyncWrite。这些特质表明:未解析的字节通常直接来自10层(例如,来自套接字或文件)。

Rust流吸收了其它语言所具备的最佳功能;例如,它们能通过利用Rust特质系统回避Node.js的Duplex流中出现的遗留问题,也能同时实施背压和惰性迭代,大大提升了效率。最重要的是,Rust流允许使用相同类型的异步迭代。
未来,关于Rust流还有很多值得关注之处,尽管仍有一些问题亟待解决。
二、总体概括:什么是流处理?
现在,也许你已经了解到了同步和异步Rust中的流特质,下面再来介绍下什么是“流处理”。
“流处理”是一种重要的大数据处理手段,其主要特点是处理的数据是源源不断且实时到来的。
在不同规模的科技公司中,流处理通常被用于分析和处理具体事件,且常被应用于分布式系统。
有些领域确实会大量使用“流处理”手段,包括:视频处理和高频交易。我们也能够借此寻找到新型区块链之中的架构灵感。因为,区块链需要处理交易和元数据流等。
如今,你可以租用具有100多个CPU的内核、100GB内存、多个GPU和100Gbps带宽的AWS实例,还无需拥有一个节点的分布式系统。
现在,让我们了解下流处理在Rust编程中的应用:
三、举个例子:计算10亿个数字的哈希程序
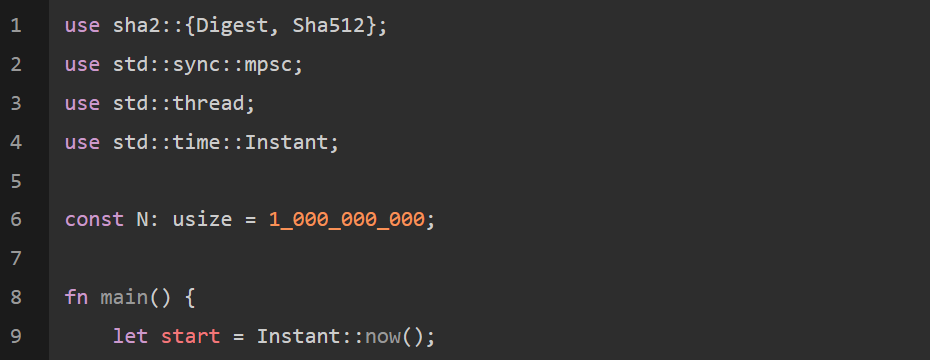
现在,让我们写一个用来计算10亿个数字的SHA512和BLAKE3哈希程序吧!你可以想象:数字代表交易、分析事件或价格信号。散列法可用来表示对这些输入的任意转换。
如下是单线程解决方案程序:
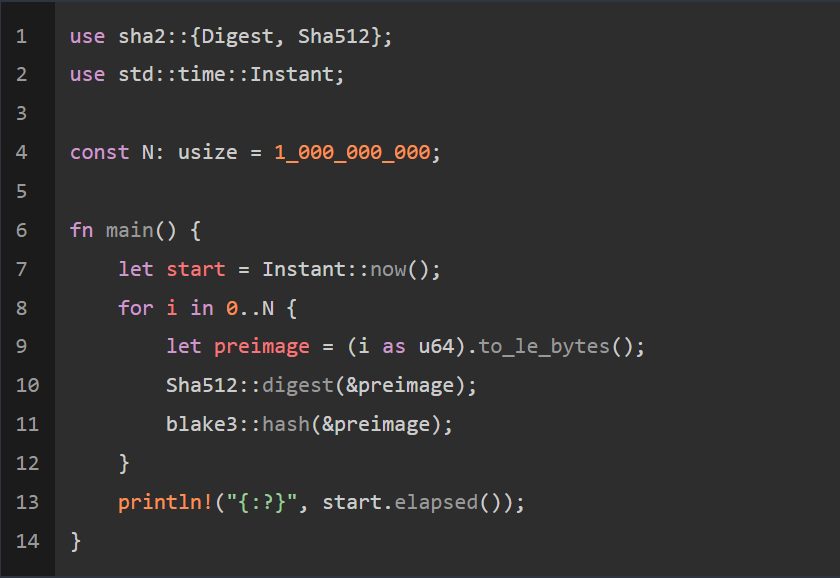
当我在带有专用CPU和16核的Digital Ocean上用发布模式运行此程序时,只需6分钟多一点。

1.通道
现在,让我们用“流处理”来重写这个程序。与在单个循环中执行散列不同,我们将设置一个线程管道并行执行散列,然后收集结果。
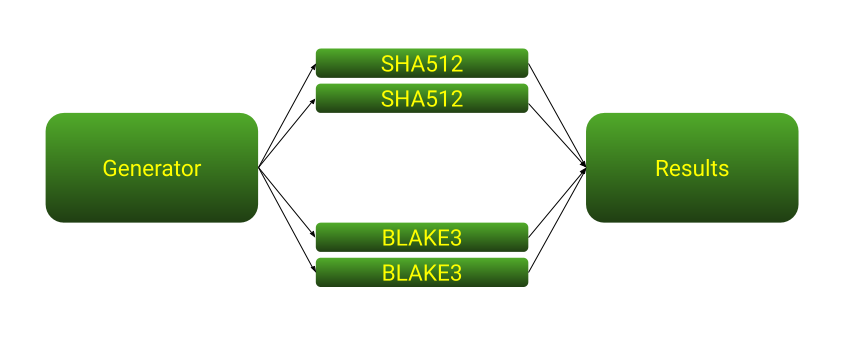
在两个线程之间发送数据的本地流被称为通道。我们的新程序将生成四个线程。生成器线程将生成数字并同时将它们发送至两个不同的哈希线程。散列线程将读取这些数字,分别对它们进行散列,然后将它们的输出发送给结果线程,下图是它的架构:

我们也将使用标准库中的mpsc通道发送和接收数据。mpsc可用来表示“多生产者-单消费者”,代表你可以从多个线程向通道发送数据,但是,只有一个管道能够输出数据。虽然我们不会使用这个多制作人功能,但是了解这一点很重要。
它仍是一个相当简单的程序:
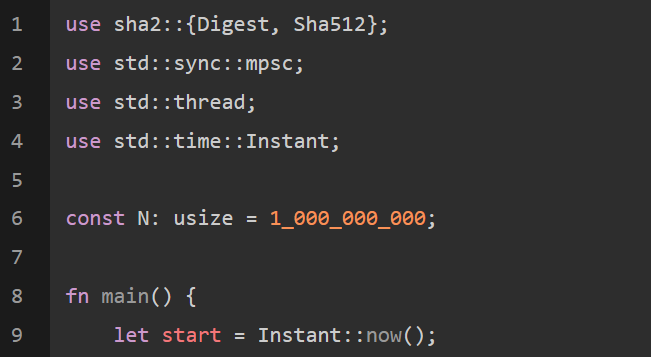
输出结果如下:
![]()
哦!带通道的新版本花费了两倍时间,这是怎么了?
2.环形缓冲器
你可以用火焰图进行测试,但还是省省时间吧!
无论多小,所有通道库的构建都会产生额外的费用,并行化所带来的好处必须大于此种开销,才能保证系统正常运作。这种情况下的瓶颈是通道send()和recv()。由于Rust中的标准库mpsc通道相对缓慢,但仍有其它替代方案,比如,crossbeam-channel。
为此,我们分析了4个不同的通道库,结果如下:
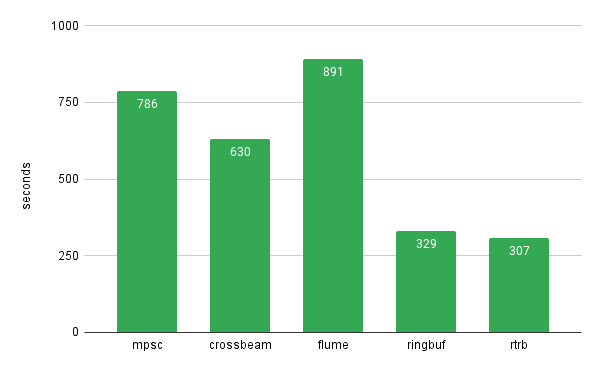
显然,ringbuf和rtrb速度最快。因为它们的环形缓冲区无锁,扮演着“单个生产者-单个消费者”的角色。单个生产者意味着只有一个管道将数据放入队列,另一个管道将负责数据输出,这比“多生产者队列”开销小。
此外,这些程序库也是非阻塞式的。当队列已满时,如果尝试推送,它将提示“error”而不是“block”,“空队列”亦是如此。
为使用这些环形缓冲区库,我添加了自旋锁,以便在通道阻塞时继续重试。事实证明,这也是高频交易架构中所使用的方法。
我还发现,在等待时增加非常短的“休眠”时间整体性能就能提高。这可能是由于当核心使用率达到100%或高于某些温度时,启动CPU就会发生节流的现象。
如下是新的pop()和push(value)帮助器:
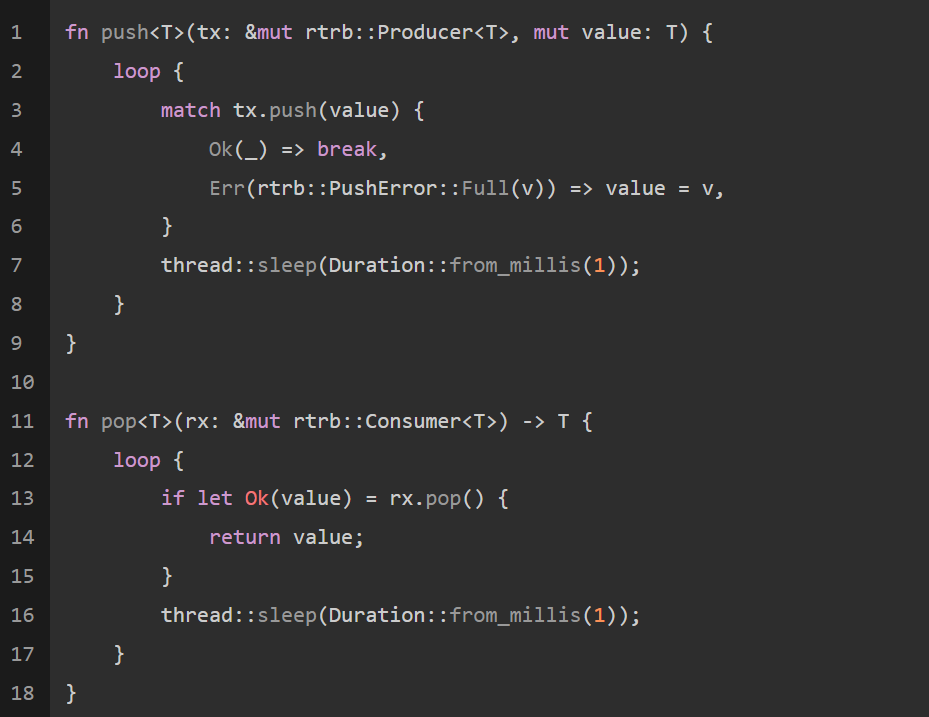
我们将用新方法展示:

速度确实比以前快了,但也快不了多少,现在,就让我们把并行化提升至另一个层次。
3.更多的并行化
目前,我们为哈希创建了两个线程,一个用于SHA512,另一个用于BLAKE3。两者中较慢的那个将成为我们技术发展的瓶颈。为证明这一点,我重新运行了原始的单线程示例,仅使用SHA512哈希,结果如下:

这与并行哈希示例中的性能非常接近,意味着,总体上花在哈希上的大部分时间都是由SHA512产生。
那么,如果我们同时创建更多的线程并将多个数字进行散列排列呢?让我们试一试。我们将创建2个SHA512哈希线程和2个BLAKE3哈希线程来启动。
4.可视化
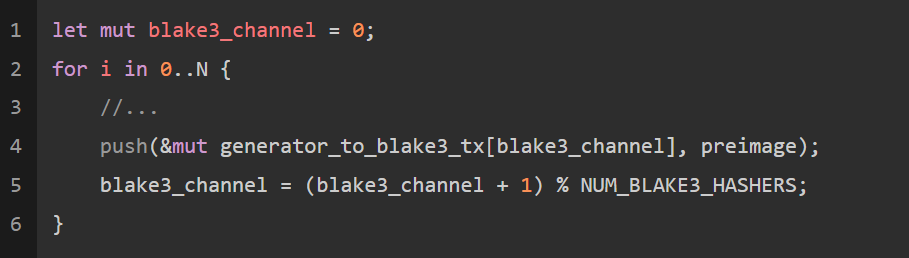
每个线程都拥有自己的输入和输出队列。我们将用循环顺序将生成的数字循环发送至每个线程并用相同的顺序读取结果。
这确保了流的顺序能够在结果线程中维持不变;如果排序不重要或消息处理时间多变,那么,其它的调度机制可能会更好。
如下是循环调度代码:
新的代码更复杂,部分如下:
一起来看看,现在表现如何?输出结果如下:
![]()
确实好多了!
5.测量“闲置”和“阻塞”时间
每个哈希函数应该有多少个线程?在更复杂的系统中,这很难确定,甚至可能是动态的。
实际上,有一种技术对“流处理”很有帮助,即,在某个时间窗口内测量空闲和阻塞时间。
- 空闲时间
等待空队列接收消息所花的时间
- 全程时间
等待满队列发送输出所花费的时间
空闲时间是pop()期间旋转的时间,阻塞时间是push()期间旋转的时间。我修改了这两个函数,用来跟踪花费时间。这段代码使用了开销很小的单元:
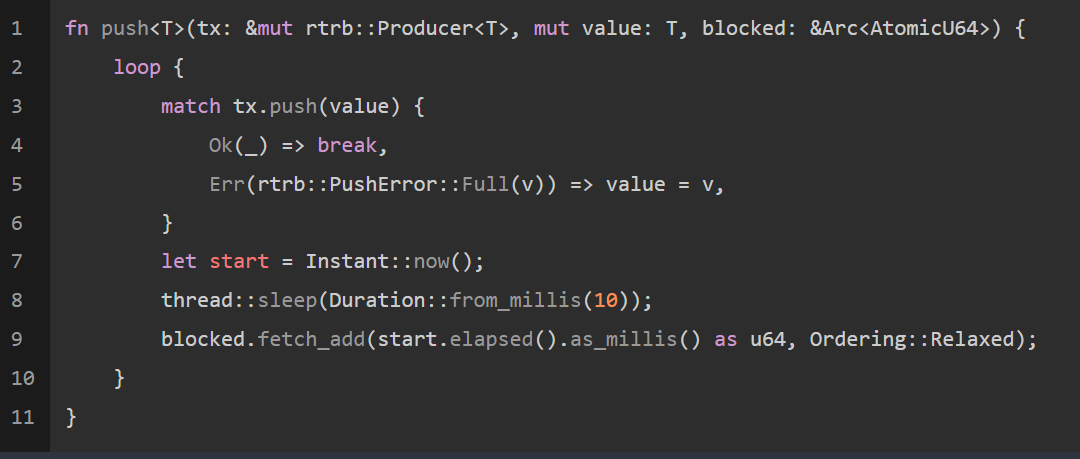
我还创建了一个新的线程统计这些时间,输出结果如下:
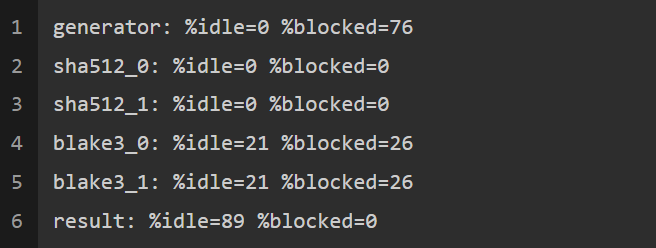
我们可以看到,sha512线程既没有“空闲”也没有“阻塞”,而是100%处于活跃状态;此外,我们还能通过增加sha512线程数量为系统提速。
注:当用测量系统的行为改变其性能时,可能会出现像“海森伯测不准原理”这样的问题。如果遇到此种情况,请查看“粗时间库”;通常,定时测量取近似值就足够了。
我们在Digital Ocean实例中,经过试验和错误数据总结出:最佳数量是8个SHA512线程和4个BLAKE3线程。
![]()
结果:小于初始时间的1/6。
四、下一步:为不同的流处理结果分配内存
在这篇文章中,我们用具体实例介绍了Rust中流处理的概念、方法和优化,但是还有很多细节没有讨论。在实际系统中,我们应该考虑将“线程”固定到CPU内核上,用来减少上下文切换。
此外,在流处理时,你通常需要为不同的结果分配内存。这是昂贵的,所以,在今后的文章中,我们还将讨论这方面的一些策略。
多看看优秀的前沿工具
太空电梯、MOSS、ChatGPT等,都预兆着2023年注定不会是平凡的一年。任何新的技术都值得推敲,我们应要有这种敏感性。
这几年隐约碰过低代码,目前比较热门,很多大厂都相继加入。
低代码平台概念:通过自动代码生成和可视化编程,只需要少量代码,即可快速搭建各种应用。
到底啥是低代码,在我看来就是拖拉拽,呼呼呼,一通操作,搞出一套能跑的系统,前端,后端,数据库,一把完成。当然这可能是最终目标。
链接:www.jnpfsoft.com/?csdn,如果你感兴趣,也体验一下。
JNPF的优势就在于它能生成前后台代码,提供了极大的灵活性,能够创建更复杂、定制化的应用。它的架构设计也让开发者无需担心底层技术细节,能够专注于应用逻辑和用户体验的开发。