Dev-C++分辨率低-解决办法



本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/7723.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
![[VSCode] vscode下载安装及安装中文插件详解(附下载链接)](https://i-blog.csdnimg.cn/direct/0156d22a822c43a79de3edd08d55e450.png)
[VSCode] vscode下载安装及安装中文插件详解(附下载链接)
VSCode 是一款由微软开发且跨平台的免费源代码编辑器;该软件支持语法高亮、代码自动补全、代码重构、查看定义功能,并且内置了命令行工具和Git版本控制系统。 下载链接:https://pan.quark.cn/s/3a90aef4b645 提取码:NFy5
通过上面…

javascript-es6 (一)
作用域(scope) 规定了变量能够被访问的“范围”,离开了这个“范围”变量便不能被访问 局部作用域 函数作用域: 在函数内部声明的变量只能在函数内部被访问,外部无法直接访问 function getSum(){
//函数内部是函数作用…

c语言中的数组(上)
数组的概念 数组是⼀组相同类型元素的集合; 数组中存放的是1个或者多个数据,但是数组元素个数不能为0。 数组中存放的多个数据,类型是相同的。 数组分为⼀维数组和多维数组,多维数组⼀般⽐较多⻅的是⼆维数组。 数组创建
在C语言…
C#,入门教程(05)——Visual Studio 2022源程序(源代码)自动排版的功能动画图示
上一篇:
C#,入门教程(04)——Visual Studio 2022 数据编程实例:随机数与组合https://blog.csdn.net/beijinghorn/article/details/123533838https://blog.csdn.net/beijinghorn/article/details/123533838 新来的徒弟们交上来的C#代码&#…

用Python和PyQt5打造一个股票涨幅统计工具
在当今的金融市场中,股票数据的实时获取和分析是投资者和金融从业者的核心需求之一。无论是个人投资者还是专业机构,都需要一个高效的工具来帮助他们快速获取股票数据并进行分析。本文将带你一步步用Python和PyQt5打造一个股票涨幅统计工具,不…

为什么IDEA提示不推荐@Autowired❓️如果使用@Resource呢❓️
前言
在使用 Spring 框架时,依赖注入(DI)是一个非常重要的概念。通过注解,我们可以方便地将类的实例注入到其他类中,提升开发效率。Autowired又是被大家最为熟知的方式,但很多开发者在使用 IntelliJ IDEA …

C# OpenCV机器视觉:利用CNN实现快速模板匹配
在一个阳光灿烂的周末,阿强正瘫在沙发上,百无聊赖地换着电视频道。突然,一则新闻吸引了他的注意:某博物馆里一幅珍贵的古画离奇失踪,警方怀疑是被一伙狡猾的盗贼偷走了,现场只留下一些模糊不清的监控画面&a…

iOS 集成ffmpeg
前言
本来打算用flutter去实现一个ffmpeg的项目的,不过仔细分析了一下,我后期需要集成OpenGL ES做视频渲染处理,OpenGL ES的使用目前在flutter上面还不是很成熟,所以最后还是选择用原生来开发
ffmpeg集成到iOS工程
iOS对于ffmp…

tmux 介绍与使用
tmux有什么用
1.关闭终端时,在终端运行着的程序不会一起被关闭。
比如,我在终端命令行执行htop。当我关闭这个终端时,htop进程也随着这个终端的关闭而结束。我在终端运行着一个程序,它应该一直运行着。我一不小心把终端关闭了&a…

独立开发者常见开发的应用有哪些
1. 工具类应用
工具类应用旨在解决用户的特定问题或提高效率,通常功能简单,但实用性强。这类应用开发周期较短,适合独立开发者。
常见例子:
生产力工具:待办事项管理(如 Todoist)、日历同步工…

Linux Futex学习笔记
Futex
简介
概述: Futex(Fast Userspace Mutex)是linux的一种特有机制,设计目标是避免传统的线程同步原语(如mutex、条件变量等)在用户空间和内核空间之间频繁的上下文切换。Futex允许在用户空间处理锁定和等待的操作࿰…

Neural networks 神经网络
发展时间线 基础概念
多层神经网络结构 神经网络中一个网络层的数学表达 TensorFlow实践
创建网络层 神经网络的创建、训练与推理 推理
推理可以理解为执行一次前向传播
前向传播
前向传播直观数学表达 前向传播直观数学表达的Python实现 前向传播向量化实现 相关数学知识…


在Qt中实现点击一个界面上的按钮弹窗到另一个界面
文章目录 步骤 1:创建新窗口类步骤 2:设计窗口的 UI步骤 3:设计响应函数 以下是一个完整的示例,展示在Qt中如何实现在一个窗口中通过点击按钮弹出一个新窗口。 步骤 1:创建新窗口类
假设你要创建一个名为 WelcomeWidg…

【大数据】机器学习----------强化学习机器学习阶段尾声
一、强化学习的基本概念 注: 圈图与折线图引用知乎博主斜杠青年 1. 任务与奖赏
任务:强化学习的目标是让智能体(agent)在一个环境(environment)中采取一系列行动(actions)以完成一个…

攻防世界bad_python
文件名pyre.cpython-36.pyc,说明是在python3.6环境下编译的,要把pyc反编译成py
但是显示失败了,结合题的名字文件的应该是文件头部被破坏 把第一行改为33 0D 0D 0A 0C 63 4A 63 61 02 00 00 E3 00 00 00
之后就能反编译了,得到源…
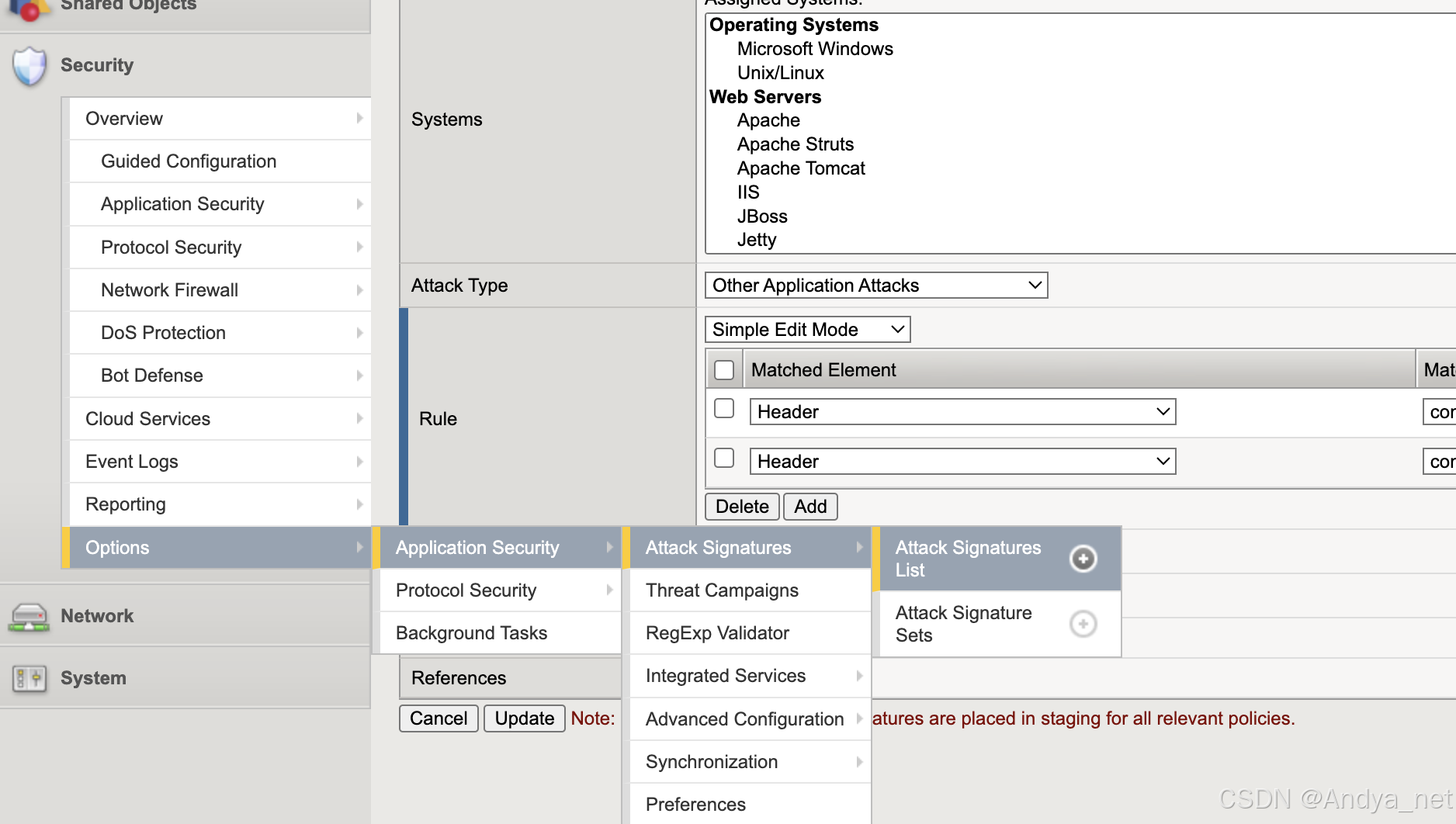
网络安全 | F5-Attack Signatures详解
关注:CodingTechWork
关于攻击签名 攻击签名是用于识别 Web 应用程序及其组件上攻击或攻击类型的规则或模式。安全策略将攻击签名中的模式与请求和响应的内容进行比较,以查找潜在的攻击。有些签名旨在保护特定的操作系统、Web 服务器、数据库、框架或应…
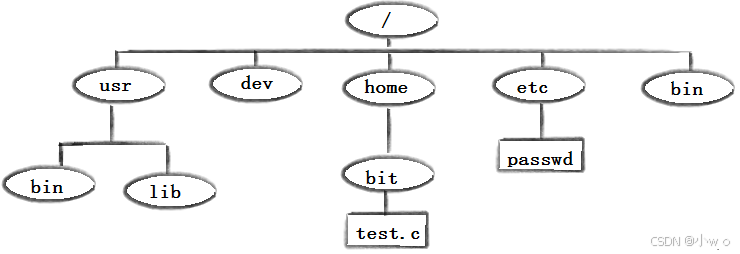
Linux的常用指令的用法
目录 Linux下基本指令
whoami ls指令:
文件:
touch
clear
pwd
cd mkdir
rmdir指令 && rm 指令 man指令 cp
mv
cat
more
less head
tail 管道和重定向
1. 重定向(Redirection)
2. 管道(Pipes&a…

Qt监控系统辅屏预览/可以同时打开4个屏幕预览/支持5x64通道预览/onvif和rtsp接入/性能好
一、前言说明
在监控系统中,一般主界面肯定带了多个通道比如16/64通道的画面预览,随着电脑性能的增强和多屏幕的发展,再加上现在监控摄像头数量的增加,越来越多的用户希望在不同的屏幕预览不同的实时画面,一个办法是打…

【BUUCTF】October 2019 Twice SQL Injection1及知识点整理
打开题目页面,是一个登陆界面 先进行注册,尝试使用SQL注入看看会返回什么
跳转到登陆界面,我们用刚才注册的登录 显示的界面如下 在这个页面输入SQL注入语句,发现将单引号转义为了\,其他关键字并没有过滤 查看给出的源…
推荐文章
- # AI绘图中的Embedding、CLIP、Flux中的Clip与LCM SDXL加速生成解析
- [c语言日寄]越界访问:意外的死循环
- 【LeetCode 刷题】回溯算法-棋盘问题
- 【Rust】控制流
- 【背包问题】二维费用的背包问题
- 【大数据】机器学习------支持向量机(SVM)
- 【华为路由/交换机的ftp文件操作】
- 【精选】基于数据挖掘的招聘信息分析与市场需求预测系统 职位分析、求职者趋势分析 职位匹配、人才趋势、市场需求分析数据挖掘技术 职位需求分析、人才市场趋势预测
- 【漏洞分析】DDOS攻防分析
- 【论文阅读】基于空间相关性与Stacking集成学习的风电功率预测方法
- 【深度学习】1.深度学习解决问题与应用领域
- 10个非常基础的 Javascript 问题